基于相似度匹配的微服務故障診斷方法①
2021-05-21 07:21:58許源佳張文博
計算機系統應用 2021年5期
陳 皓,許源佳,2,王 燾,3,張文博,3
1(中國科學院 軟件研究所,北京 100190)
2(中國科學院大學,北京 100049)
3(中國科學院 軟件研究所 計算機科學國家重點實驗室,100190)
1 引言
面對互聯網時代的海量請求,短時間內的服務失效會導致用戶體驗和評價的下降,而長時間的服務失效甚至會使企業面臨嚴重的經濟損失.隨著云計算數據量的迅速增長,集群規模的不斷膨脹,如何對集群內海量的微服務進行高效、準確的故障檢測,保障集群的高可靠性成為了越來越重要的技術.服務的監測與故障技術幫助運維人員監測分布式服務的運行情況,進行資源的調配,保證整個服務系統的可靠運行.
微服務故障診斷方法主要包括分析度量信息、日志文件和執行追蹤等3 種方法.首先,基于度量信息分析的方法收集某個邏輯計量單元或某時間段內的計量值,可以通過設定固定的指標或是通過一系列運算設定動態變化的指標,以此作為系統異常的報警規則,向運維人員發送異常警告,或是作為集群任務的調度規則[1-3].這類方法對于系統內部服務的結構和關系不需要進行了解,但需要事先知道異常類型和異常特征,靈活性較差.其次,基于日志文件分析的方法收集離散日志文件中的元數據信息,日志文件記錄了系統運行中海量零散事件或請求信息,通過設定檢索模式,可以找到運行中的錯誤報告,有效排查系統的異常原因[4-7].這類方法需要收集大量零散的日志文件,并從中提取出關鍵的故障信息,日志收集和信息提取存在滯后性,難以實時分析系統存在的故障.最后,基于執行追蹤的方法收集單次請求內的全部信息,構建系統內部的結構特征,當系統異常發生時會引起請求處理軌跡發生偏移,通過對處理軌跡分析以達到異常定位和故障原因診斷的目的[8-10].這類方法可用于排查系統性能問題,但是監測粒度過細會帶來巨大的監測和分析資源開銷,存在監測粒度與監測開銷之間難以平衡的問題.
綜上所述,現有微服務故障診斷方法存在以下問題:(1)現有微服務故障診斷方法存在多種監控方式,其中基于度量信息分析的方法和基于日志文件分析的方法需要預先知道異常的特征信息,難以應對突發異常,而基于執行追蹤的方法缺少對系統運行指標(如CPU、內存、磁盤、網絡等)的監測.(2)相同請求的執行追蹤具有相似性,缺少衡量執行追蹤間的相似度指標,因此現有技術難以通過分析執行追蹤間的相似程度來發現服務異常,從而造成不能夠快速發現和診斷故障的結果.(3)故障原因的診斷依賴系統歷史故障的特征信息,缺乏對未知故障的可能原因的診斷方法,因此現有技術需要不斷迭代故障特征診斷規則,對未知故障的診斷依賴運維人員的技術和經驗,從而造成可靠性保障方法靈活性差,難以應對罕見的系統故障.
針對以上問題,本文提供一種基于故障相似度的微服務故障診斷方法,采用預先向系統注入故障的方式,收集故障的執行追蹤,并通過采用字符串編輯距離表示執行追蹤間相似度,比較已知故障與異常請求間的相似度,報告可能的故障原因.相較于現有方法,本文提出的方法存在以下優點:(1)基于系統歷史運行追蹤數據制定故障發生的判斷條件,對于復雜多變的微服務系統,能夠更為靈活準確的判斷系統狀態;(2)基于對系統注入故障的表現的真實記錄,因此當生產環境中,相似的故障再次發生時,能夠通過對系統行為與注入故障的表現進行評估,快速準確的判斷故障原因;(3)對于系統中罕見故障發生的情況,本文所提出的方法會將其與已知故障進行比對,通過對于已知故障原因的分析,提出可能的相似故障,運維人員可以此為輔助快速找到系統中真正的故障.同時,通過與相關微服務監測方法的結合,可以減少排除故障所需的時間,減少實際損失.
2 故障診斷方法
本文提出一種基于故障相似度的微服務故障診斷方法(圖1),采用預先向系統注入故障的方式,收集故障的執行軌跡,并通過采用字符串編輯距離表示執行軌跡間相似度,比較已知故障與異常請求間的相似度,報告可能的故障原因,具體包括以下3 個環節:
(1)執行軌跡建模:對于分布式系統內服務之間的調用,采用注入代理的方式攔截和轉發流量,借由分布式追蹤系統收集請求信息.通過收集請求的執行ID,父請求ID,執行時間,調用服務等信息,可以獲得原始的請求信息.通過對追蹤信息進行規范化處理和建立調用關系模型,可以將請求刻畫為相應的有向帶權圖的形式進行存儲.同時,對于每一個請求的有向帶權圖,都可以通過對于頂點進行映射,從而轉化為一個標識該請求的調用關系的調用字符串.
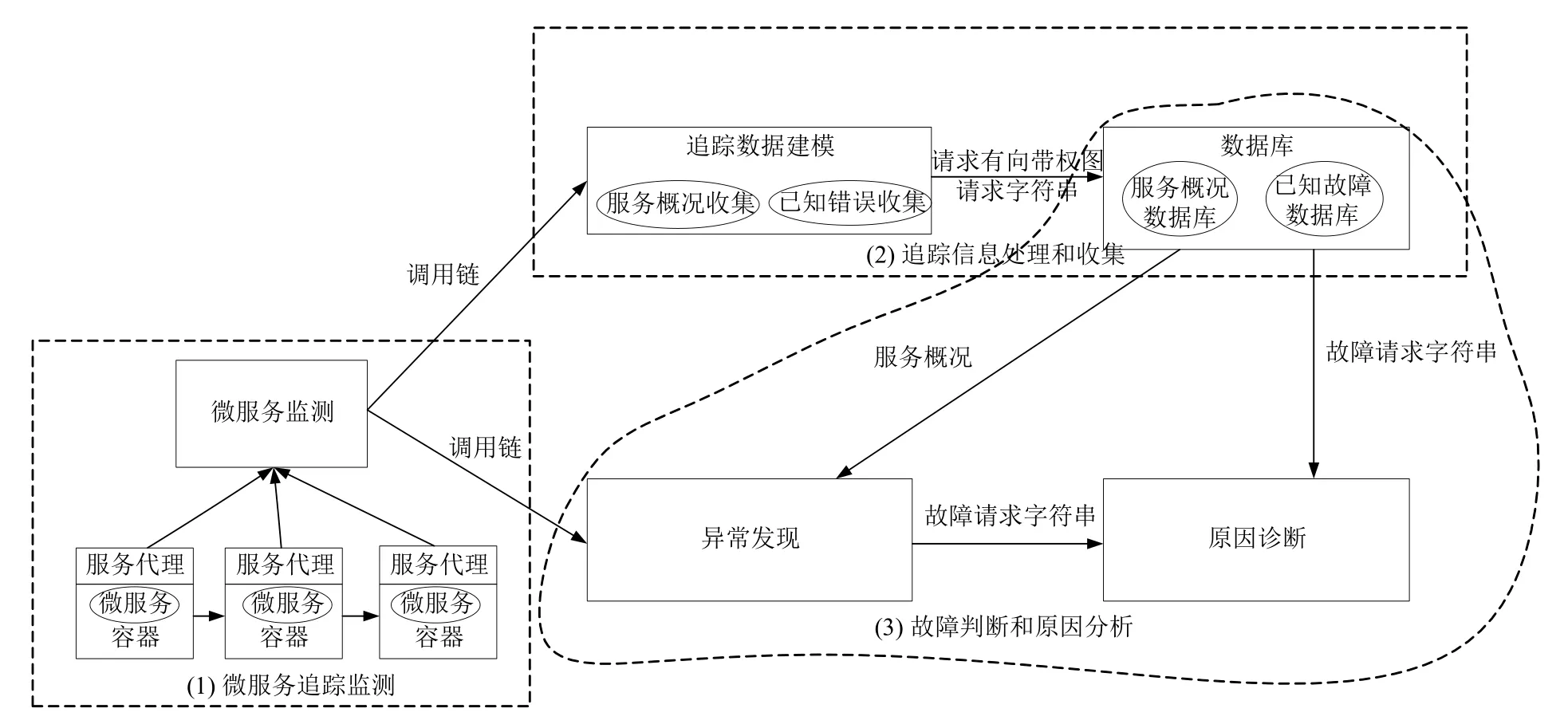
圖1 故障診斷方法總體設計
(2)系統運行與故障概況統計:對于被檢測系統,對系統服務正常運行時應用的追蹤信息進行收集,構建正常運行下請求的有向帶權圖信息進行存儲,作為系統正常運行的參考依據,設定正常服務間調用請求的正常執行時間區間,以服務間請求是否超出執行時間區間作為判斷請求是否出現異常的標準.此后,通過注入已知原因的故障引發系統出現異常,觀察系統應用間執行軌跡的變化關系,將出現故障后系統內執行軌跡的有向帶權圖進行收集,并且對于請求內服務間的調用關系,通過映射關系轉化為請求字符串,作為系統故障原因的參考依據進行存儲.
(3)未知原因故障發現與原因診斷:對于運行時的系統,通過對系統服務間的執行軌跡的不斷監測.一旦系統內出現執行時間異常的請求,將請求追蹤信息作為分析該異常請求的數據來源.通過對于未知原因故障的請求的有向帶權圖模型的建立和將請求內服務調用關系轉化為調用請求字符串的方式,通過計算與已知故障的請求字符串之間的編輯距離來衡量未知故障請求與已知故障請求間的相似度,從而找到能夠產生最為相似的調用請求的已知故障,作為本文判斷異常原因結果.
3 關鍵技術
3.1 執行軌跡建模
對于一條執行軌跡T,本文采用有向帶權圖的結構來表示發送和接收事件的調用關系,其中:每一個頂點S都對應應用依賴關系中的某一個服務;對于應用中存在服務A和服務B,并且服務A 對服務B 產生了調用請求,那么在有向帶權圖中,服務A和服務B 對應的頂點a和頂點b之間建立有向邊,其權值為調用請求被接受所消耗的時間t;根據請求的內容和應用的功能,對同一服務的多次調用可能會產生不同的調用關系,因此請求的執行軌跡T和對應的帶權有向圖D可能不唯一.
為了記錄服務間的依賴關系,對執行軌跡T的每一條追蹤信息,都將表示為:
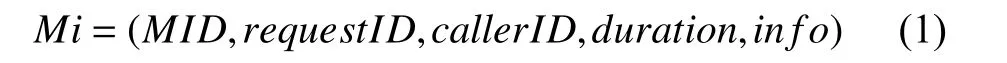
其中,MID是該服務id;requestID為服務請求的id;callerID為調用服務的id;duration為請求消耗時間;info包含方法的其他信息,多元組形式如式(2):
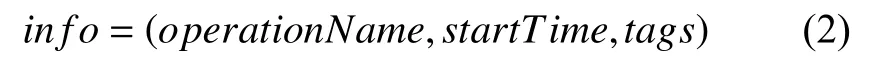
其中,operationName為操作名稱;startTime為開始時間戳;tags為請求所包含的標簽.通過對依賴關系的還原,可以將執行軌跡T轉化為相應的有向帶權圖D={V,E},其中V為頂點S的數組,每一個頂點S表示一個服務;E為鄰接矩陣,被調用的服務間建立權值為消耗時間t的有向邊.此外,對于一條執行軌跡T,其中的每一條追蹤信息都可以按照調用的順序,使用哈希函數將操作名稱轉化為表示該操作的一個定長字符串Cm,根據調用順序將這些字符串依次拼接,可得到表示執行軌跡T的請求字符串C.
3.2 追蹤信息收集
3.2.1 服務概況收集
本文首先統計系統請求的正確執行,收集相應的執行軌跡Ts,轉化為相應的請求有向帶權圖Ds,構建服務概況數據庫(Service Profile DataBase,SPDB),依次對于系統的請求的正確執行的執行軌跡進行存儲.SPDB的建立不僅是對于系統的系統正常請求的一種記錄,更是能作為系統異常的判定標準.微服務故障主要分為性能衰減與服務失效兩大類,其中,性能衰減類的故障是由于資源使用率增高,使得服務處理效率達到瓶頸,微服務處理請求所消耗的時間增長,并且當資源使用率不斷增高,會導致部分微服務處理超時返回錯誤代碼或者微服務間請求處理順序和調用關系出現異常改變,其執行追蹤表現為微服務執行時間的大幅增長和部分調用關系的異常改變;服務失效類的故障主要是由于服務未能正確響應請求或服務未被正確配置所引起,會導致部分請求返回錯誤信息或者長時間未能響應,其執行追蹤表現為微服務執行時間大幅縮短或大幅增長,并且存在服務請求調用流程的提前終止或重復請求.因此,系統異常往往伴隨著執行軌跡中服務執行和調用時間的變化,本文將采用執行時間作為主要判斷的指標.
通過模擬10 000 次相對穩定的運行環境下被正確處理的請求,本文收集了10 000 次相對穩定的運行環境下被正確處理的請求中的追蹤信息,在剔除異常值和缺失值之后,對收集的50 037 個追蹤中的微服務執行時間進行統計和分析,相應執行時間如圖2所示.事實上,由于微服務的運行環境并非是一成不變的,并且會對微服務的運行產生難以預料的影響.對于相同環境下相同服務的多次相同類型的請求進行統計,由于網絡延時等因素造成的隨機性,仍然會使得調用的時間呈現一定的隨機分布,執行時間近似落在某一個區間之內,而統計單一因素在請求仍能被正確處理的情況下的波動對執行時間所造成的影響并非本文研究的方向.然而,我們將執行時間的分布區間獲取的樣本中位數為中心,分成100 個相同大小的執行時間區間,并對處在區間內的追蹤樣本數量進行統計.我們發現,對落在每一區間段上的執行時間數量使用Kolmogorov-Smirnov 檢驗(K-S 檢驗)[11]進行正態性檢驗,相應的p值分別為0.493、0.135、0.259、0.094,均大于0.05,可以認為執行時間的分布區間符合正態分布.因此,對于大多數被正確處理的請求,我們均可以計算得到一個執行時間區間,將這樣的區間端點作為邊界值,落在區間之外的執行軌跡就可以被認為是一種異常.對于一次新的執行請求,本文采用式(1)和式(2)來計算其邊界值:
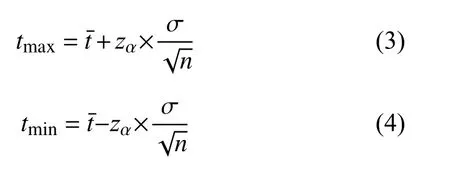
其中,tmax表示正常執行時間的上界,tmin表示正常執行時間的下界,表示服務請求的平均執行時間,σ表示服務請求執行時間的標準差,n表示樣本執行軌跡的數量,zα表示正態分布的α分位點,本文采用95%的置信概率,根據文獻[12]取為1.96.
當請求的執行時間超出這一區間時,將被認為發生了一次異常事件,其執行軌跡的請求字符串C將被保留.
3.2.2 已知錯誤收集
為了對系統出現故障后的表現進行記錄,本文采用定向注入故障的方式,預先收集系統失效時的執行軌跡Tk,將其轉化為相應的請求字符串Ck進行存儲,建立已知故障數據庫(Known Faults DataBase,KFDB).KFDB 中不僅可以存儲由注入的單個服務的失效和多個服務調用之間的所產生的異常事件執行軌跡,還能夠收集由于集群物理資源異常所引發的執行軌跡,并且通過本文的處理,結果利于量化比較相似度.在系統實際出現失效時,將出現的故障執行軌跡與KFDB 中已知故障所產生的所產生的系統執行軌跡進行比較,通過本文3.3.2 節所介紹的算法2 計算出最為相似的故障,以幫助運維人員判斷生產環境中系統失效的實際位置,最大程度的避免損失.
3.3 故障診斷
系統故障會使請求的執行軌跡的產生可監測的偏移[13],包括執行軌跡內服務調用關系的改變和執行時間的波動兩種形式.對于本文所建立的請求的模型,即請求的有向帶權圖,以上兩種執行軌跡偏移的形式分別對應有向帶權圖頂點的改變和有向邊權值的波動.基于以上原理,提出了故障發現與故障原因診斷的方法.

圖2 執行時間分布區間
3.3.1 故障檢測
對于每一次請求,經過3.1 節所介紹的建模方式,都可以計算出相應的請求有向帶權圖.為了處理有向帶權圖中復雜的調用信息,判斷系統是否發生故障,本文提出了以下算法思想:
(1)對于當前請求所對應的有向帶權圖Du,檢索其開始時間最早的頂點S1,作為起始頂點,表示請求的第一個服務.對于頂點S1,取其服務名稱N1,使用映射函數轉化為定長字符串C1;
(2)讀取該頂點請求的消耗時間dt1和所連接的下一個頂點S2;
(3)根據調用關系,進入下一個頂點S2,取其服務名稱N2,使用與步驟(1)中相同的映射函數轉化為定長字符串C2;
(4)查詢SPDB 中C1與C2間執行請求的正常執行區間,若dt1處于正常執行區間之內,則判斷S1至S2的調用為正常調用,取頂點請求的消耗時間dt2,將C1添加至請求字符串Cr末端;反之則為異常調用,將C1添加至請求字符串Cr末端;
(5)重復步驟(1)~步驟(4),對于T內的每一個頂點進行檢測,直到當前請求的每一次調用均被檢測,且所有頂點的服務名稱均轉化為字符串C并添加至請求字符串Cr中.如果存在異常,則將請求字符串Cr作為結果返回,反之則返回空值.
基于以上算法思想,本文提出故障發現算法如算法1.

算法1.故障發現算法輸入:Du 未知請求有向帶權圖輸出:Cr 請求字符串1.function Judgement(Du)2.Cr,C1,C2 ←“ ”3.S1 ←Du.V.root 4.S2 ←null 5.dt,dtmin,dtmax←0 6.state←0 7.while S1.next is not nulldo

8.S2 ←S1.next 9.C1←Hash(S1.name)10.C2←Hash(S2.name)11.dt←GetArc(Du.E,S1,S2)12.dtmin←GetMinDuration(C1,C2)1,C2)13.dtmax←GetMaxDuration(C 14.if dtmin>dt or dtmax<dt then 15.state←1 16.end if 17.Cr←Cr+C1 18.S1←S2 19.end while 20.if state ==0 then 21.Cr← null 22.else 23.Cr←C +C2 24.end if 25.return Cr 26.end function
算法1 通過以歷史系統正常請求的調用時間區間作為判斷依據,能夠有效設立有針對性的檢測閾值.其中輸入為未知請求有向帶權圖Du={V,E},V為頂點數組,包含該請求所涉及的所有服務,E為鄰接矩陣,包含服務間的調用關系和消耗時間.算法首先從請求開始的頂點,獲取其服務名稱和調用關系(第3 行~第9 行),之后依次將服務名稱轉化為字符串(第9 行、第10 行),查詢調用時間是否在正常范圍之內(第11行~第16 行),然后將服務名稱添加至請求字符串(第17 行)并重復這樣的檢測過程,直至所有頂點均被檢測(第7 行~第19 行).如果存在調用時間超出正常區間,則返回值為調用字符串,反之為空值(第20 行~第25 行).
當算法1 判斷系統出現故障后,將根據所建立的請求模型分析系統可能出現的故障,本節中所生成的請求字符串將作為描述故障請求重要依據而輸入3.3.2節的原因診斷.
3.3.2 原因診斷
故障原因診斷基于對系統注入的已知故障進行相似度的判斷,在3.2.2 節中我們建立了存有已知故障的數據庫KFDB.為了提取和比較KFDB 中執行軌跡與未知原因故障的執行軌跡間的相似程度,我們將故障執行軌跡轉化為相應的調用字符串的形式,采用字符串編輯距離作為相似程度的衡量指標,詳細算法如算法2 所示.
算法2 通過已知故障的執行軌跡與未知故障執行軌跡的對比,返回多個可能的故障原因.其中輸入為請求字符串Cr,輸出為相似故障F.算法對于KFDB 中記錄的每一個故障Fk,依次取出請求字符串Ck,計算未知請求字符串Cr與已知故障請求字符串Ck間的編輯距離(第6 行~第10 行).由于KFDB 內每一個故障記錄了多個已知故障請求字符串,因此計算出的匹配值為編輯距離的平均值(第9 行~第12 行),并且返回值為匹配值最小的KFDB 中已記錄的故障F(第13 行~第18 行).對于有經驗的運維人員,本文所提供的結果可以幫助快速排查系統故障,查找真正的故障原因.

算法2.原因檢測算法輸入:Cr未知請求字符串輸出:F 相似故障1.function SimilarityMatching(Cr)2.Cr,Ck←“”3.Fk,F←null 4.dk,d←0 5.i←0 6.for each Fk ∈ KFDB do 7.for each Ck ∈ Fk do 8.i ++9.dk←dk+GetEditDistance(Ck,Cr)10.end for 11.dk←dk/i 12.i←0 13.if dk<d then 14.F←Fk 15.d←dk 16.end if 17.end for 18.return F 19.end function
4 實驗分析
4.1 實驗環境
為了驗證本文所提出的故障檢測方法,本文采用測試應用的包含4 組微服務,微服務之間存在相互調用的關系,總計包含36 個微服務實例,并且被部署在兩臺應用服務器上,用于驗證本文所提出方法的可行性.實驗平臺基于Kubernetes和Istio 框架,其中Kubernetes提供對底層容器自動部署、擴展和管理的容器編排管理功能[14],而Istio 通過注入sidecar 代理的方式攔截微服務之間的網絡通訊,提供統一的微服務連接、安全保障、管理與監控方式[15],簡化了本文對測試系統的微服務的監控和管理.包括流量管理,實驗測試應用基于Istio 所提供的微服務書店應用Bookinfo[16]進行實現,實驗系統的架構圖如圖3所示.
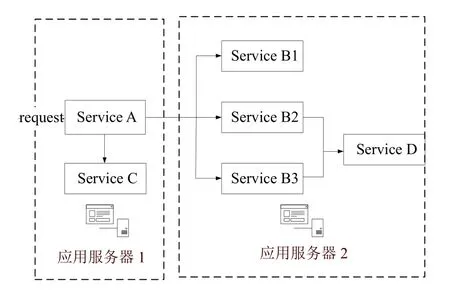
圖3 被測系統架構
當用戶請求發送至測試應用后,首先由Service A處理請求,并且Service A 會調用Service C和隨機版本的Service B 進行處理,而v2和v3 版本的Service B會繼續調用Service D.測試應用內各微服務功能單一,可獨立運行,服務之間基于HTTP/HTTPS 協議的RESTful API 進行通信協作,與微服務應用具有的職責單一,可獨立部署、擴展和測試,通過消息進行交互的特點[17]相契合.測試應用運行在Kubernetes 集群上,經過服務網格Istio[18]對于應用運行和監測的解耦,其中應用鏈路數據經過開源鏈路追蹤工具Jaeger[19]收集并存儲至后端Elasticsearch[20]數據庫內.經過本方法處理的請求的有向帶權圖和相應的調用字符串存儲至數據庫中.運行被測系統并發送請求,收集正常運行時系統的執行軌跡信息,建立SPDB.實驗節點的軟硬件信息見表1.

表1 實驗節點配置信息
4.2 執行追蹤建模
4.2.1 服務執行信息收集
被測系統在正常請求中會首先調用服務A,再由服務A 對服務B和服務C 進行調用.其中服務B 同時有3 個運行中的版本,B2和B3 版本的服務會繼續調用服務D 處理請求.在實驗中,本文將模擬1000 次的用戶請求,收集測試系統的正常追蹤信息以構建SPDB.在經過分布式追蹤系統Jaeger的收集后,得到的服務追蹤中對4 個微服務的調用數量和服務之間調用所耗費的平均執行時間如圖4、圖5所示.
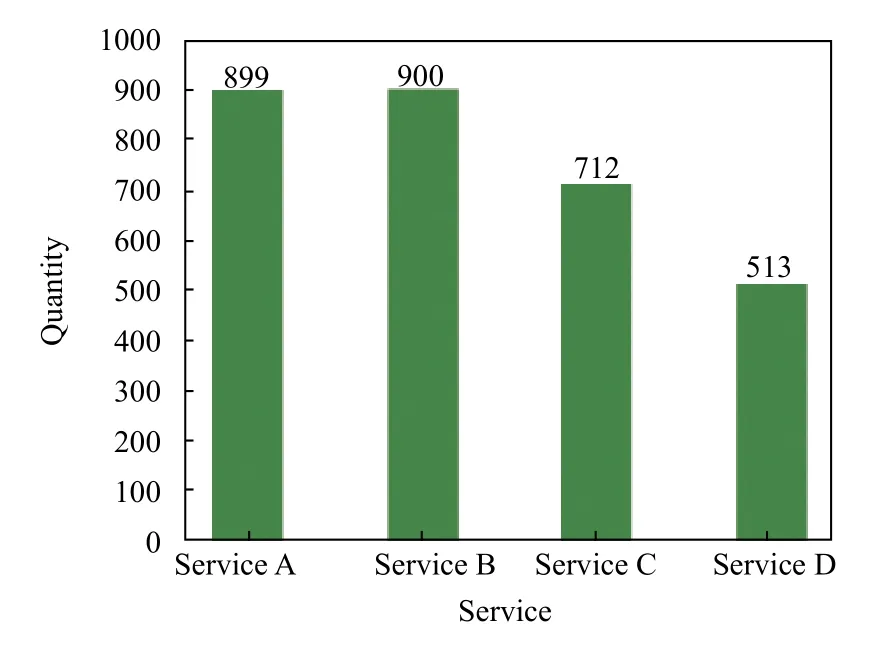
圖4 被測系統收集的微服務追蹤數量

圖5 服務調用的平均執行時間
對于正常請求的執行追蹤,均存在由服務A 開始的調用其他服務的處理流程.如圖6所示,還原了一次正常請求的有向帶權圖.其中,每一次正確請求的均處在相對穩定的區間內,并且服務B 并非每次都需要調用服務D 處理請求.
4.2.2 故障注入
為了建立KFDB,驗證方法的有效性,向被測系統注入了多種故障.對于每一次的故障注入實驗,均向被測系統發送500 次請求,并收集注入故障的系統的追蹤信息.通過對于追蹤信息的收集和處理,對于被測系統的表現進行記錄,建立KFDB.注入故障信息見表2.
其中,注入節點的節點或服務表示注入故障的應用服務器或服務,故障描述簡述了注入的故障,有效故障追蹤數量表示每次實驗所收集到的可處理和分析的追蹤數量.由表2可見,實驗中對此被測系統中單次請求均在8 次調用內處理完成.對于生成的系統正常運行時的追蹤模型進行與系統設計架構中的調用關系進行人工比對,可以確認得到請求的追蹤模型能夠準確的描述每一次的請求信息.
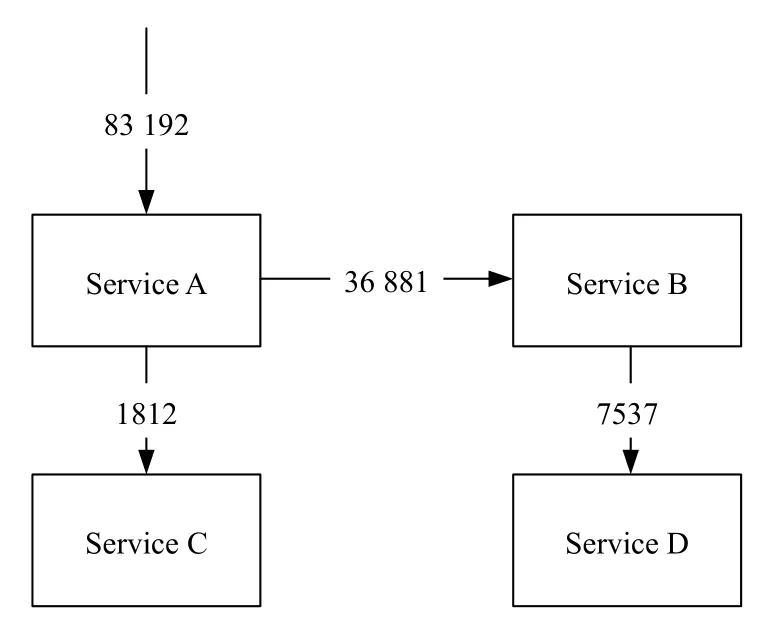
圖6 一次正常請求的有向帶權圖
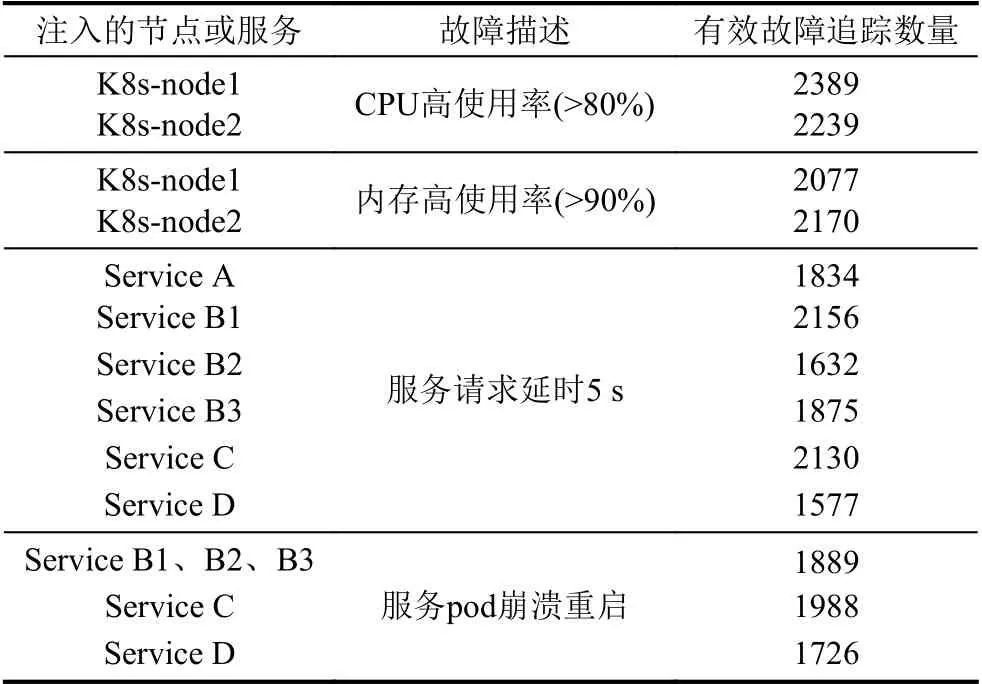
表2 注入故障信息
對于異常請求的執行追蹤,仍然以服務A 作為調用開始的起點調用其他服務的處理流程.如圖7所示,還原了已知故障1 中一次請求的有向帶權圖.其中,我們可以觀察到,同樣的微服務的執行時間有較明顯的變化,并且由于容器所在節點的不同,已知故障對于不同的微服務之間的影響幅度并非完全相同.此外,由于服務A和服務B 中出現部分超時請求,后續的服務不能被正確調用,使得部分執行軌跡出現改變.
4.3 故障診斷
為了檢驗故障檢測方法的有效性,我們分別在系統處理正常請求的過程中,引發待測故障,包含性能衰減與服務失效類型的故障.對于每一次的故障注入實驗,均向被測系統發送20 次請求,并收集注入故障的系統的追蹤信息,待測信息如表3所示.
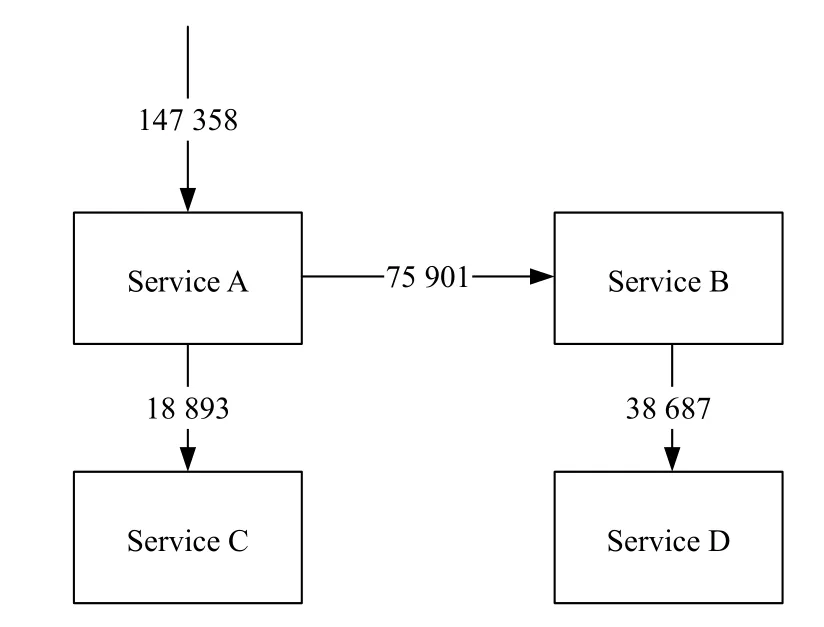
圖7 一次已知故障請求的有向帶權圖

表3 待測故障信息
與表2類似,表3中注入節點的節點或服務表示注入故障的應用服務器或服務,故障描述簡述了注入的故障,有效故障追蹤數量表示每次實驗所收集到的可處理和分析的追蹤數量.
對于收集到的待測故障請求的追蹤數據,其中以待測故障1為例,各服務的追蹤數據數量與所占比例如圖8、圖9所示.

圖8 各服務的追蹤數據數量
注入故障會引發服務的性能衰減與失效,因此由于故障的注入,系統中應用服務的處理請求所消耗的時間會發生改變.以待測故障1為例,各服務平均調用時間的變化如圖10所示.
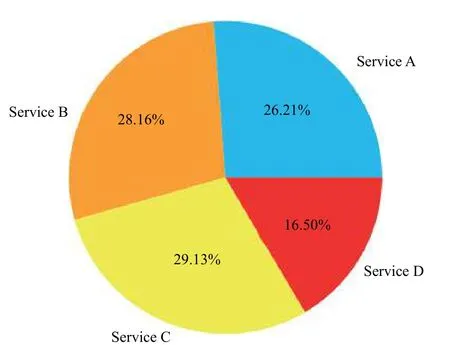
圖9 各服務的追蹤數據所占比
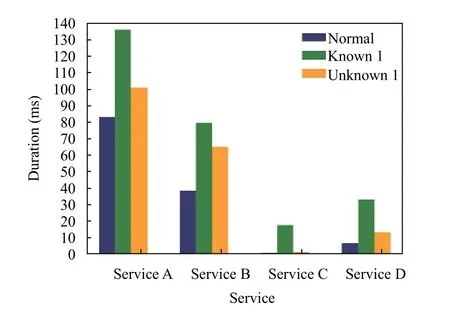
圖10 服務平均執行時間變化
4.4 試驗結果分析
4.4.1 結果展示
本文采用查準率P(precision)、查全率R(recall)和F1 值對本方法的異常發現結果進行評價.其中:

其中,真正例TP(True Positive)表示異常發現算法判斷為故障時系統確實發生故障的次數,假正例FP(False Positive)表示異常發現算法判斷為故障時系統實際未發生故障的次數、假反例FN(False Negative)為異常發現算法判斷為正常時系統確實發生故障的次數.
對于待檢測的故障,將注入故障的請求的追蹤數據和同樣次數的系統正常運行下的請求的追蹤數據使用本文所提出的異常發現方法進行分析,其異常發現結果展示如表4所示.
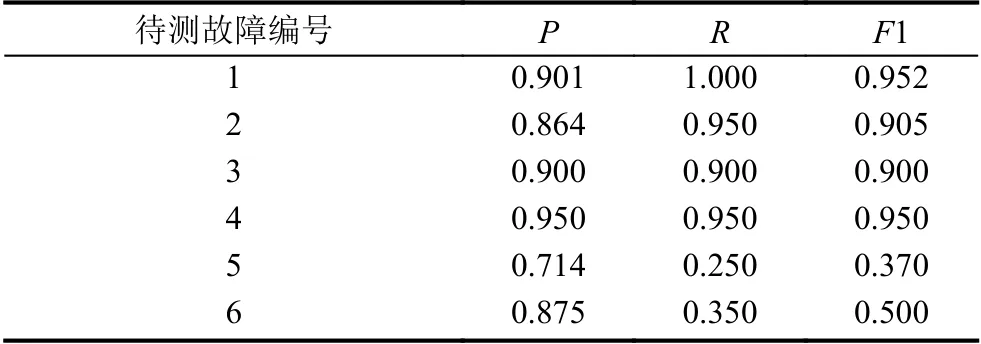
表4 異常發現性能
同樣,對于原因診斷,同樣采用查準率P、查全率R和F1 值對結果進行評價.計算式同式(3)-式(5).其中,真正例TP表示原因診斷算法判斷的最可能的已知故障與待測的未知故障的類型相同的次數,假正例FP與假反例FN均表示原因診斷算法判斷的最可能的已知故障與待測的未知故障的類型不同的次數.原因診斷結果如表5所示.

表5 原因診斷性能
4.4.2 結果分析
實驗結果表明,對于服務性能衰減類型的故障,本文所提出的方法,本文所提出的故障發現算法可以很好地發現故障,查準率、查全率、F1 值分別達到0.886、0.975、0.928,可見由于性能衰減類的故障會引起服務處理請求時間的相應延長,因此本文所提出的故障發現算法可以很好地發現這種類型的故障;而對于服務失效類的異常,本文所提出的原因診斷算法可以較好地診斷原因,查準率、查全率、F1 值均為0.625,可見由于服務失效類的異常會使得調用請求的處理出現較為明顯的變換,因此本文所提出的原因診斷算法能夠較好的發現這種故障的原因.
此外,本文所提出的方法雖然可以發現故障和檢測故障原因,但是仍有一些情況下會存在對于系統狀態和故障原因判斷不準確的情況.經過分析,未能有效發現的故障主要與pod 狀態異常有關,主要包括pod未能正確提供服務功能的情況,在實驗中的判斷準確率.這是因為本文所提出的異常發現方法基于服務的性能表現,但是對于可能出現服務失效的應用,由于請求未能被正確處理而返回,這一過程與部分應用正常請求所消耗的時間相似,因此未能正確反映出故障的發生.而對于未能正確檢測原因的故障,主要與集群節點物理資源異常所導致的故障有關,主要包括CPU 使用率高和內存占用率高等情況.這是因為資源使用異常類的故障發生時,仍有部分請求在性能衰減的系統中完成整個處理流程,返回正確的結果,因此這一部分的請求雖然處理時間異常,但仍能描述正確的調用關系,本文所提出的根據執行追蹤所建立模型并未對于這一類請求進行更為詳細的描述.關于這一類故障,可以結合對于集群節點的物理資源度量和對容器資源的運行時監測進行分析和檢測.
5 相關工作
近年來,微服務軟件架構由于其可控制的復雜性、資源可伸縮性、容錯性、高可用性等優點逐漸受到各大互聯網巨頭的青睞.在服務模型搭建和故障診斷方面,各有其研究的展開.
在服務模型搭建方面,文獻[21]提出了一種評估程序架構信息的方法,基于模糊的開發代碼和不精確的需求,評估基于所提出框架的微服務開發能否契合原本非功能性需求.文獻[22]提出了基于SDN (Software-Defined Networking)和NFV (Network Functions Virtualization)自我診斷框架,該框架基于對物理、邏輯、虛擬和服務層的監督內容進行定義,動態生成診斷模型,逐漸確定故障區域.文獻[23]提出了一種通過分析服務調用鏈以生成關系依賴圖的方法,通過分析服務依賴關系來找到可能存在風險的調用,從而找到目標系統存在的異常.然而,以上幾種方法所建立的模型均沒有對異常請求和正常請求分別進行建模和歸類,同時對于系統出現故障的歷史表現缺乏記錄,從而當相同的故障發生時診斷效率低下.本文通過已有的歷史模型對未知請求的模型進行比對,由于使用系統正確處理請求的歷史數據模型作為故障判別的標準,無需修改現有模型即可判斷當前系統所處的狀態以及可能的產生故障的原因.
在故障診斷方面,文獻[24]提出了一種通過記錄Netfiix的網關Zuul[25]活動,從微服務的請求中收集指標的方法,這種方法的開銷很小,但是存在著缺乏對于服務之間調用的因果關系計算的過程,因此會對后續原因診斷造成一定的困擾.文獻[26]提出了一種非侵入式的方法,收集追蹤信息和生成日志,幫助運維人員排除相關故障的方法.該方法通過捕獲網絡數據包的形式分析其中的HTTP 標頭,判斷請求的類型并計算跟蹤信息.這種方法由于只依賴網絡獲取數據包,不需要對應用進行修改,但是存在一定的性能消耗,并且在高負載情況下會減少日志文件的生成.本文所提出的方法通過預先記錄系統正確請求處理的概況和注入故障后系統的行為,當未知狀態請求產生時,只需將當前請求的追蹤信息進行建模比對,無需對已知請求模型進行修改,具有較小的資源開銷.
6 總結與展望
本文針對微服務監測存在粒度較粗、故障定位不準確等缺點提出一種基于相似度匹配的微服務故障診斷方法.首先,使用注入代理轉發請求流量的方式收集并建模微服務的追蹤信息;然后,收集系統正常運行下的狀態信息,并通過注入已知故障來收集并刻畫故障發生后應用的運行狀態;最后,將未知故障的執行追蹤信息與已知故障的執行追蹤信息相匹配,采用字符串編輯距離衡量相似度以診斷可能的故障原因.相較于現有方法,本文提出的方法存在以下優點:(1)基于系統歷史狀態表現分析,能夠靈活準確的判斷當前系統狀態;(2)對于歷史故障真實還原和記錄,相似故障發生時能夠快速匹配和反饋;(3)對未知故障自動進行相似度匹配,基于已有故障的表現提出可能的故障原因,幫助快速排查故障.同時,通過與相關微服務監測方法的結合,可以減少排除故障所需的時間,減少實際損失.
該方法還存在以下待改進的問題:首先,故障注入可能會造成部分罕見故障和復雜故障的遺漏,后續工作將引入對已檢查故障的追蹤信息補充錄入,增大故障判斷類型的廣度;其次,檢測方法的性能開銷與已記錄的追蹤數量呈正比,我們后續將對故障注入種類數量和注入點的選取進行研究,以較小的性能開銷獲得較高的故障判斷準確性.
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
中華手工(2017年2期)2017-06-06 23:00:31
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
中外會展(2014年4期)2014-11-27 07:46:46
