基于高階變異的多錯誤定位實證研究①
2021-05-21 07:22:06王海峰
計算機系統應用 2021年5期
婁 琨,尚 穎,王海峰
(北京化工大學 信息科學與技術學院,北京 100029)
1 引言
錯誤定位是識別程序執行過程中導致程序失敗的元素的過程[1].在軟件調試的眾多活動中,錯誤定位是其中最復雜耗時的活動之一,尤其在大規模復雜程序中.為了減小定位錯誤位置的人工成本,研究人員提出了眾多錯誤定位方法,例如基于切片的方法[2],基于頻譜的方法[3,4],基于變異的方法等[5].
在眾多自動化錯誤定位方法中,基于頻譜的錯誤定位(Spectrum-Based Fault Localization,SBFL)方法[3,4,6]是一種被廣泛應用的方法.SBFL 考慮到程序元素的二元覆蓋矩陣,但局限于其錯誤定位精度不高.目前的研究顯示基于變異的錯誤定位方法比最新的基于頻譜的方法有更高的錯誤定位精度[7,8].MBFL是一種基于變異測試[7]的方法[9].截止目前,MBFL 分為兩種技術:Metallaxis-FL[5]和MUSE[9].研究表明[10,11],Metallaxis-FL的錯誤定位效率和效果都要優于MUSE,因此本文選擇Metallaxis-FL 作為MBFL 原始方法.
在MBFL 中,將一個程序p通過簡單的語法變化生成一系列錯誤程序p'(也就是變異體),生成變異體的規則被稱為變異算子.根據變異算子使用的次數,變異體可以分成兩類:一階變異體(First-Order-Mutants,FOMs)和高階變異體(Higher-Order-Mutants,HOMs),其中FOMs是只使用一次變異算子生成,HOMs 則是通過多次使用變異算子生成[12].
在之前的MBFL 研究中,只有FOMs 用于定位單錯誤程序[5,13].但Xue 等[14]發現定位多錯誤更有困難,耗時且成本巨大,同時多錯誤之間存在錯誤干擾現象,導致現有錯誤定位技術的定位效果較差.另一方面,Offutt 等[15]發現殺死HOMs是否能檢測出復雜錯誤是不確定的.為填補這項研究內容,我們進行了一項大規模的實證研究,研究HOMs是否能提升錯誤定位的精度,同時分析不同類別的HOMs 與多錯誤之間的關系.
本文中,我們著力研究FOMs和HOMs 在多錯誤上的表現.然后我們將HOMs 分成三類研究不同HOMs分類的錯誤定位效果.在我們的實驗設置中,首先應用Agrawal 等[16]提出的變異算子生成FOMs,然后根據FOMs 構建HOMs.特別地,針對多錯誤定位場景,我們組合63 個單錯誤程序生成100 個多錯誤程序,錯誤個數從2 個至5 個.最后,我們將HOMs 分成3 類用于比較不同類別HOMs的表現.
2 背景與動機
2.1 基于變異的錯誤定位技術
基于變異的錯誤定位技術是一種基于變異分析[8]的錯誤定位方法.變異分析通過對被測程序進行簡單的語義改變,生成與原始程序不同的版本.這些人為植入錯誤的程序被稱為變異體.生成變異體的規則被稱為變異算子.本文采用Agrawal 等[16]提出的C 語言的變異算子.
在變異分析中,依據變異體和原始程序不同的輸出,使用變異體來評估測試用例的質量.如果一個測試用例的執行結果不同于原始程序的結果,那么這個變異體就被殺死,記為killed 或detected,反之稱這些變異體沒有被殺死,即not killed 或live.
傳統基于變異的錯誤定位技術主要包含以下4 個步驟:
(1)獲得失敗測試用例覆蓋的語句:將測試用例T執行被測程序P,獲得覆蓋信息和執行結果(pass 或fail).然后測試用例就可以區分為通過測試用例集合Tp和失敗測試用例集合Tf.被失敗測試用例覆蓋的語句集合記為covf.
(2)生成和執行變異體:采用不同變異算子,對失敗測試用例覆蓋的語句植入錯誤生成變異體.對某一條語句s生成的變異體集合記為M(s).然后將所有測試用例執行某一個變異體m,依據執行結果,Tk(m)為殺死變異體m的測試用例集合,Tn(m)為未殺死變異體m的測試用例集合.
(3)計算程序語句懷疑度:變異體的懷疑度可以用不同的MBFL 公式計算得到,這些公式都基于以下4 個參數:anp=|Tn∩Tp|,akp=|Tk∩Tp|,anf=|Tn∩Tf|,akf=|Tk∩Tf|.其中,anp表示通過測試用例中未殺死變異體的數量,akp表示通過測試用例中殺死變異體的數量,anf表示失敗測試用例中未殺死變異體的數量,akf表示失敗測試用例中殺死變異體的數量.表1列舉了3 個研究人員常用的懷疑度計算公式(Ochiai[17],Tarantula[18],Dstar[19]).本文的實驗中使用Ochiai 作為MBFL 公式,因為其在MBFL 研究中被廣泛使用[5,9],且效果好于其他公式[13].計算完變異體的懷疑度,將某條語句對應的變異體集合的懷疑度最大值賦值為該條語句的懷疑度.
(4)生成錯誤定位報告:依據程序語句的懷疑度大小,降序排列生成程序語句排名表.開發人員可以根據排名表從上至下查找并修正程序錯誤.
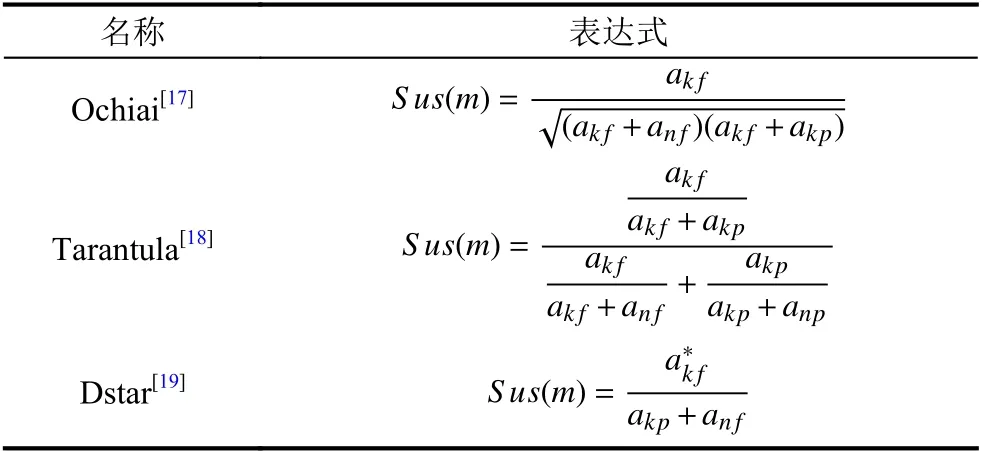
表1 常用懷疑度公式
基于上述過程的描述,我們可以發現MBFL是基于“大部分失敗測試用例殺死的變異體與程序錯誤有關”假設的研究工作,其理論基礎是基于以下兩類假設[20]:(1)將變異體視為是原被測程序的一種潛在修復;(2)將變異體視為原被測錯誤程序的近似版本.變異體執行測試用例后的狀態有兩種:殺死(killed)和未殺死(not killed).其中,殺死狀態分為:被失敗測試用例殺死(akf)和被通過測試用例殺死(akp).在被失敗測試用例殺死的變異體,存在兩種情況:(1)變異體的狀態從失敗變成通過,即程序被修復;(2)變異體仍然為失敗,但輸出與原始程序不同.這兩種情況都有助于揭示錯誤位置,第一種程序修復的情況,可以依據變異的位置來確定程序錯誤的位置.第二種情況,變異體的輸出與原始程序不同,其有可能是對錯誤位置變異而造成的輸出不同,此變異體的行為特征與錯誤程序更加相似.另一方面,被通過測試用例殺死的變異體,其更可能是對正確語句進行變異,造成輸出與原始程序不同.并且,Moon 等[9]的研究發現,錯誤語句生成的變異體在失敗測試用例下更容易通過,而正確語句生成的變異體在通過測試用例下更容易失敗.
同時,從表1變異體懷疑度公式中可以看出,變異體的懷疑度值與akf呈正相關關系,與akp呈負相關關系.本文通過計算變異體m在測試用例上akf與akp的差值來度量該變異體對錯誤定位的影響程度,即貢獻度C(Contribution):
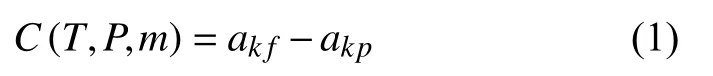
其中,T表示測試用例集,P表示被測程序.C(T,P,m)越高表示該變異體的貢獻度越高.
同理,對變異體集合M的平均貢獻度AC(Average Contribution)的計算公式為:
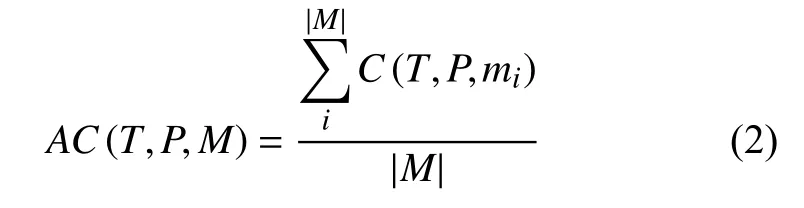
其中,|M|表示集合中變異體的數量.
目前研究人員對FOMs和HOMs 之間的關系進行了研究.如Gopinath 等[21]的研究表明許多HOMs 與它們組成的FOMs 在語義上是不同的.然而,Langdon等[22]的研究表明被測試用例殺死的HOMs 數量高于殺死FOMs的數量,因此HOMs 相對于FOMs,更容易被測試用例檢出.
在早期的研究中,Offutt 等[15]指出:殺死n階變異體是否意味著我們可以檢出復雜錯誤還有待確定.為了回答這個問題,我們是第一個進行關于比較FOMs和HOMs 在定位程序錯誤上的控制實驗的.
2.2 研究動機
在先前的研究中,大部分MBFL 技術基于單錯誤假設[5,9,13,23].然而,實證研究表明[24],單個程序失敗往往是由系統中的多個故障觸發的.Digiuseppe和Jones 發現,多個錯誤對錯誤定位的精度有負面影響[25].
此外,Offutt的研究結果認為,殺死n階變異體是否可以檢測到復雜的錯誤還有待確定[15].在Debory和Wong的研究中[26],他們發現他們所提出的策略不能修復同一個程序中的多個錯誤,是因為他們只考慮了FOMs.換句話說,采用HOMs 來定位或修復程序中的多個缺陷是一種潛在可行的方法.因此,本文主要通過實證研究HOMs 在單錯誤和多錯誤程序上的定位效果,并分析多錯誤與HOMs 之間的關系.
(1)HOMs 分類
依據變異體在程序中的不同變異位置,我們將HOMs分成3 類.為便于理解這3 類變異體,我們采用帶有兩個錯誤(f1和f2)的程序p作為例子.首先,我們HOMf1為變異了錯誤語句f1的HOMs 集合且HOMf1∈HOMs;HOMf2變異了錯誤語句f2的HOMs 集合且HOMf2∈HOMs.
其次,如圖1所示,我們將HOMs 分為以下3 類:
類A:準確高階變異體(Accurate HOMs).即,同時在錯誤語句f1和f2 上變異生成的HOMs.(HOMf1∩HOMf2).
類B:部分準確高階變異體(Partially accurate HOMs).即,只在錯誤語句f1 或f2 上變異生成的HOMs.(HOMf1HOMf2)∪(HOMf2HOMf1)
類C:不準確高階變異體(Inaccurate HOMs).即,在其他語句上變異生成的HOMs.(HOMs(HOMf1∪HOMf2)
上述3 種HOMs 反映出不同HOMs的生成方法.我們推測這3 類HOMs 在錯誤定位上有不同的表現.基于這種推測,我們進行了一次大規模的實證研究來分析3 類HOMs的特性.
(2)MBFL 例子
為進一步說明我們的研究動機,我們使用圖2中的例子來說明FOMs和HOMs 如何在MBFL 上使用.
在圖2中,從左到右,第1 列為被測程序的源代碼,其中語句s4和s11為錯誤語句.第2 列為對應語句生成的變異體集合,第3 列劃分為6 部分,分別是6 個測試用例在變異體上的執行信息,其中“1”表示測試用例殺死對應的變異體,“0”表示測試用例沒有殺死對應的變異體,第4和第5 列表示計算得到的變異體懷疑度和語句懷疑度,最后一列表示對應語句的排名.在這個例子中,每一個變異體的懷疑度都是用Ochiai 公式計算的.在圖2中有兩個給出的結果,一個是FOMs的結果,另一個是HOMs的結果.
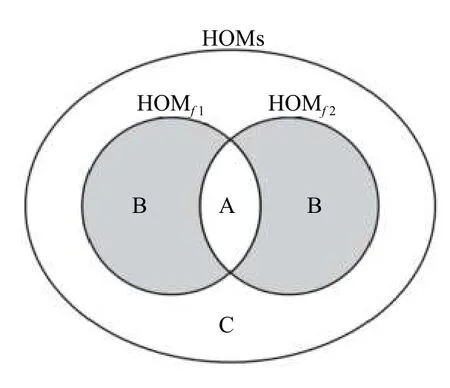
圖1 HOMs 分類
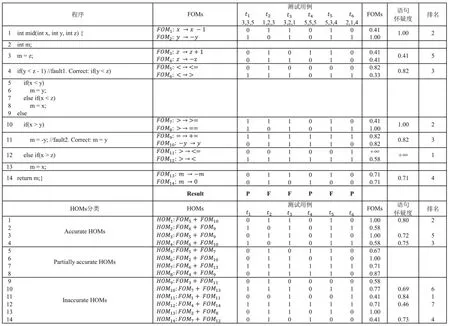
圖2 MBFL 例子
使用FOMs 進行錯誤定位.假設MBFL 技術在失敗測試用例覆蓋的每條語句只生成兩個變異體,該程序下共生成14 個FOMs(列“FOMs”所示).MBFL 首先利用測試用例的殺死信息計算FOMs的懷疑度(列“FOMs 懷疑度”所示).接下來,同一語句生成的變異體中,取最大的懷疑度記為該語句的懷疑度.最后,在“排名”列中,MBFL 將錯誤語句s4和s11都排在第3 位.
使用HOMs 進行錯誤定位.我們首先利用來自不同語句的兩個FOMs 構造HOMs,最后生成3 類共14 條HOMs(列“HOMs”所示).計算得到的HOMs 懷疑度如列“HOMs 懷疑度”所示.接著,為保證公平性,我們通過計算語句相關HOMs 懷疑度的均值作為該語句的懷疑度.以語句s1為例子,與s1相關的HOMs 有3 個(HOM6,HOM11和HOM13),其對應的懷疑度分別為1.00,0.41,和1.00.因此,計算得到的語句s1的懷疑度為Sus(s1)=(1.00+0.41+1.00)/3=0.80.最終,使用HOMs計算得到的語句懷疑度如列“語句懷疑度”所示.最終,HOMs 將錯誤語句s4和s11分別排在第3 名和第2 名.
基于上述的例子,我們可以發現FOMs 將兩條錯誤語句排在前五名,然而HOMs 將錯誤語句排在前三名,表明HOMs 在這個例子中有更好的錯誤定位效果.更進一步,在高階變異錯誤定位中,三類變異體對錯誤定位有不同的貢獻,結合式(2),準確HOMs的平均貢獻度為:
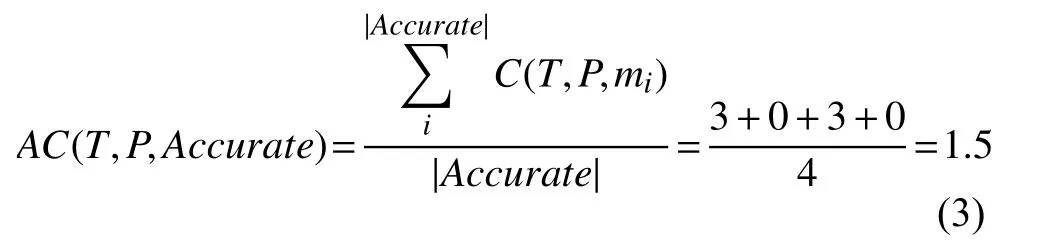
部分準確HOMs的平均貢獻度為:

不準確HOMs的平均貢獻度為:
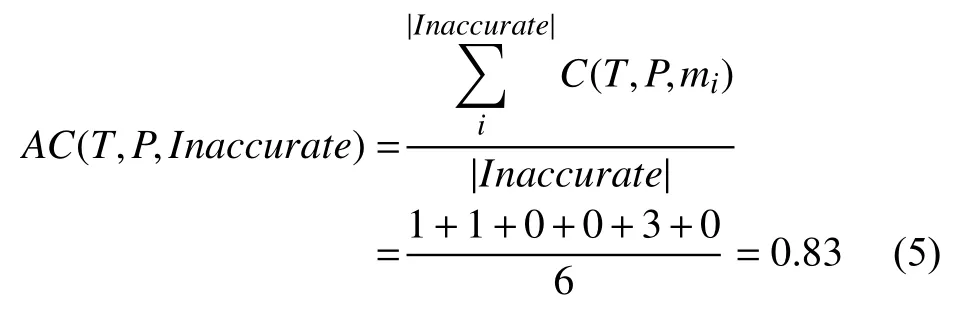
從以上結果可以看出,準確HOMs的平均貢獻度等于部分準確HOMs,不準確HOMs的平均貢獻度最低.據我們所知,本文首次研究FOMs和HOMs 在多錯誤程序上的定位效果.更進一步,我們研究了三類HOMs的錯誤定位效果并分析其差異.
3 實驗設計
本章討論實驗中使用的程序和實驗設計流程,用以解決提出的研究問題.圖3中顯示了實驗研究設計流程.下面將依次介紹設計流程的每個部分.
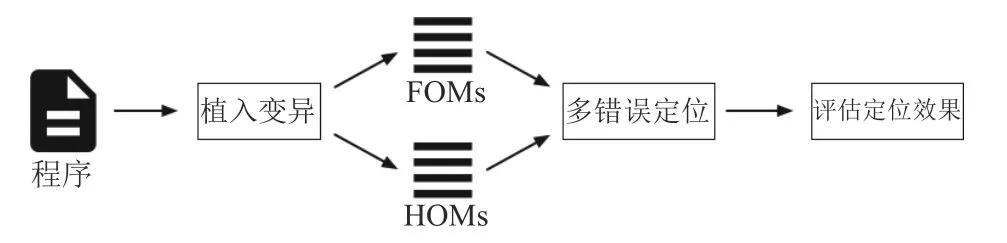
圖3 實驗設計流程
3.1 實驗程序
本文選擇了錯誤定位領域常用的軟件基準程序庫(Subject Infrastructure Repository,SIR)[27]中的5 個程序作為實驗對象,分別為printtokens2,schedule2,totinfo,tcas和sed.這些程序均為開源的C 程序,其中前4 個程序來自西門子套件(Siemens Suite),sed是大型的真實錯誤程序.實驗中使用的錯誤版本和測試用例均可在SIR 庫中下載.這些程序在高階變異測試領域中廣泛使用[12,28-30],同時也經常應用在錯誤定位等相關的研究中[18,19,23,26].因此我們認為本文測試數據集所得出的結論具有一定的普適性.
表2列出了基準程序的具體信息,包括程序名稱,程序所有的版本數量和實驗中使用的數量,程序的平均代碼行以及FOMs和HOMs的數量.其中,FOMs 列的“生成的數量”子列表示對應程序生成的FOMs 總數,而“使用”子列表示實驗中實際運行的FOMs 總數.本文共選擇了63 個單錯誤版本程序作為實驗對象,部分版本因為錯誤語句無法生成有效變異體而導致測試用例無法檢測出該版本的錯誤,或因為執行過程中出現異常,無法收集到完整的執行信息.
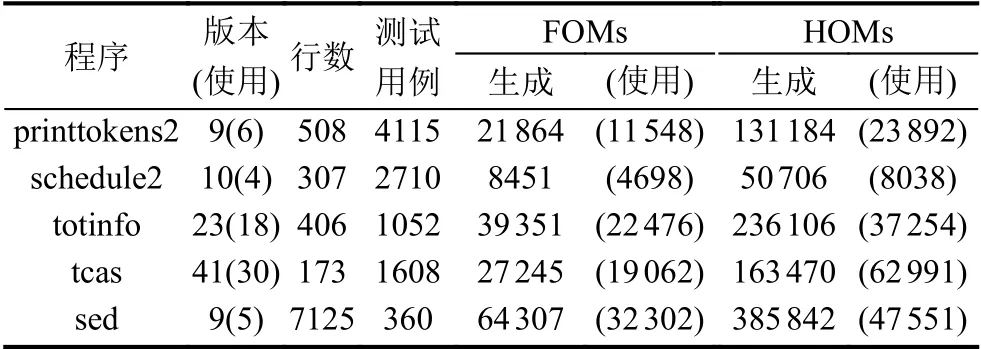
表2 實驗基準程序及變異體信息
3.2 生成變異體
為了研究FOMs和HOMs 在單錯誤和多錯誤程序中的表現,實驗首先需要生成FOMs和HOMs.在這個步驟中,我們收集被失敗測試用例覆蓋的程序語句,通過變異算子植入錯誤到這些語句,進而生成相應的變異體.表3列出了Agrawal 等[16]提出的10 種經典C 語言變異算子.

表3 經典C 語言變異算子
對于生成FOMs,我們對fail 測試用例覆蓋的每條語句使用所有變異算子進行變異,每次只對一條語句變異,最終生成161 218 個FOMs.表2“FOMs”列的“(使用)”子列中列出了每個程序所使用的FOMs數量.
對于生成高階變異體,在已有高階變異測試的研究中,對變異體階數的研究有所不同,有關注于階數較低(2 至4 階)的研究[15,28,29,31],也有關注階數較高(2 至15 階)的研究[12,32-35].本文首次考慮將高階變異體應用于多錯誤定位,然而在實際程序中錯誤數量是不可知的,因此結合前人的研究成果,我們選擇生成2 至7 階的變異體來模擬多錯誤情況.在此基礎上,為了進一步探究不同變異位置的高階變異體與錯誤定位的關系,我們依據不同的變異位置對變異體進行了劃分,并通過理論和實驗分析發現錯誤語句處生成的變異體(如準確HOMs和部分準確HOMs)具有更優的錯誤定位效果.另一方面,考慮到MBFL 巨大的執行開銷,我們選擇生成每階HOMs的數量與FOMs 數量相同來減少HOMs的數量.假設生成1000 個FOMs,然后2 階變異體和3 階變異體的數量也是1000;因此最終生成的HOMs為6000.在我們的實驗中,采用一階變異算子FOP 構建HOMs.具體來說,首先隨機選擇k條失敗測試用例覆蓋的語句,然后對每條選擇的語句,隨機選擇一個與其相對應的一階變異算子,最終生成一個k階變異體.實驗共生成967 308 個HOMs,其中實際使用的數量如表2所示(“HOMs”列的“(使用)”子列).
3.3 構建多錯誤定位場景
為了構建實驗中的多錯誤定位場景,我們通過隨機組合SIR 庫中的原始單錯誤程序獲得多錯誤程序.每個多錯誤程序中的錯誤數量是2 到5 個.最終生成100 個版本的多錯誤程序.最后,依據多錯誤程序生成的變異體,運行變異體收集測試結果用于效果分析.
3.4 評估MBFL的效果
為了評估FOMs和HOMs 在MBFL 中的定位效果,我們使用了3 種研究人員常用的評估指標[36-39].
(1)EXAM:EXAM[36,37]是錯誤定位領域廣泛使用的評價指標之一,用于評估開發人員找到準確錯誤位置之前需要檢查的程序實體的比例,因此EXAM值越小表明對應的錯誤定位效果越好[36,37].EXAM的公式定義如下:
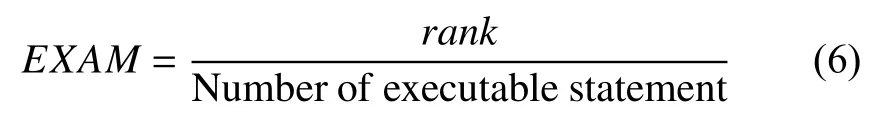
式(6)中,分子是錯誤語句的排名,分母是需要檢查的程序語句數量的總和.rank的計算公式為:

式(7)中,i表示懷疑度值大于錯誤語句的正確語句的數量,j表示懷疑度值等于錯誤語句的正確語句的數量.為更接近真實定位場景,我們選擇第i+1 位排名與第i+j位排名的平均作為錯誤語句的排名.
(2)Top-N:Top-N 用于評估排名前N個程序候選元素中,能定位到真實錯誤的個數[38].在Kochhar 等的研究發現,73.58%的開發者只檢查排名前5的程 序元素,并且幾乎所有的開發者認為檢查排名前10的程序元素是可接受的上限[39].因此,參考之前的研究[36,38],我們將N設定為1,3,5.同時,假設兩條語句有相同的懷疑度,我們同樣計算這些語句排名的平均值(如式(7)所示).Top-N 越大表明對應的錯誤定位技術越好.
(3)MAP:MAP (Mean Average Precision)是信息檢索領域用于評估語句排序質量的指標,是所有錯誤平均精度的平均值[40].AP(Average Precision)的計算公式如下:
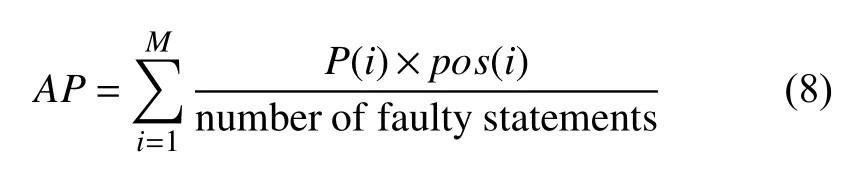
式(8)中,i是程序語句的排名,M是排名列表中語句的總數,pos(i)是布爾函數,pos(i)=1 表示第i條語句是錯誤的,反之pos(i)=0 表示第i條語句是正確的.P(i)是每個排名i的定位精度.
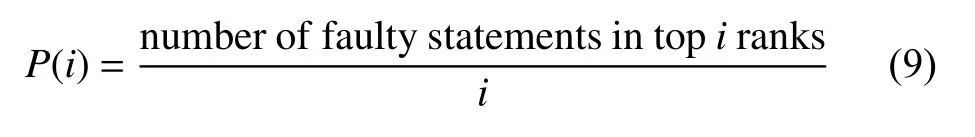
MAP是錯誤集合的AP的平均值,MAP 越大表明對應的錯誤定位技術越好.
4 實驗結果
4.1 研究問題
為了評估HOMs是否能提高錯誤定位的精度,本文從錯誤定位精度角度出發,提出如下研究問題:
(1)RQ1:與FOMs 相比,不同階數的HOMs的多錯誤定位精度如何?
(2)RQ2:與FOMs 相比,不同類型的HOMs的多錯誤定位精度如何?
4.2 實驗結果
為探究RQ1,我們首先針對多錯誤程序生成一階HOMs,然后運行這些變異體計算得到每個程序對應的EXAM,Top-N和MAP.本文使用Metallaxis-FL為原始MBFL 對照組,并生成2 階到7 階的HOMs.
圖4中展示了MBFL 使用FOMs和不同階的HOMs的錯誤檢查比例.x軸表示代碼檢查比例,y軸表示不同程序所有錯誤版本查找到的累積錯誤比例,對應的曲線越接近y軸表明對應的變異體的檢測錯誤數量越多,因此對應的變異體錯誤定位效果更好.
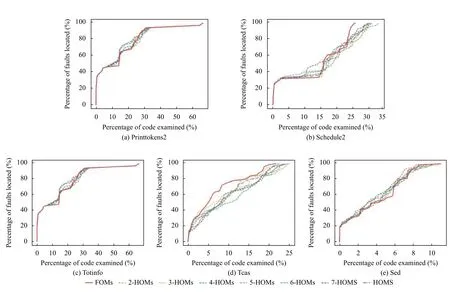
圖4 FOMs 與不同階 HOMs的代碼檢查比例比較
從圖4(a)中可以看出,7-HOMs 檢測20%的程序代碼能檢測到68%的錯誤,而FOMs 只能檢測到55%的錯誤.同理,在schedule2,totinfo和sed 上可以看出,HOMs 檢測更少的代碼能檢測到更多的錯誤,但在tcas 程序上FOMs的檢測效果優于HOMs.
從Top-1,Top-3,Top-5 指標來看,FOMs 在2 錯誤程序上的定位效果比HOMs 更好,而HOMs 在3 錯誤和5 錯誤程序上的表現比FOMs 更好.表4中顯示了FOMs和HOMs 在多錯誤程序定位場景下排在前1,3,5 位錯誤的數量.圖中包括4 種錯誤數量的程序統計結果.對2 錯誤程序,FOMs和各階高階變異體都將19 個錯誤排在第一名.除了7-HOMs,FOMs 比其他階數的HOMs的Top-3,Top-5 要更高.對3 錯誤程序,3-HOMs比FOMs和其他階數的變異體在Top-3和Top-5 上更高.同時FOMs 在4 錯誤程序中,Top-3和Top-5 上的表現略優于HOMs.最后,在5 錯誤程序上,FOMs、6-HOMs和7-HOMs的Top-1 值最高,而6-HOMs和3-HOMs 分別在Top-3和Top-5 上表現最好.
從MAP 指標來看,FOMs 在4 錯誤程序上表現最優,在其他錯誤程序上與HOMs 有相近的表現.從表5可以看出,FOMs 在4 錯誤程序上的MAP 均值最高.在其他錯誤程序上與HOMs 有相近的表現,例如3 錯誤程序FOMs的MAP 均值與4 階到7 階的變異體的MAP 均值相同.
綜上可以看出,HOMs 在一些程序上的檢錯能力優于FOMs.同時,FOMs 在2 錯誤和4 錯誤程序上的定位效果較好,而HOMs 在3 錯誤和5 錯誤程序上的效果更好.HOMs 在3 錯誤和4 錯誤程序上有更大的Top-N 值,并且在一些階數的HOMs 下,計算的MAP均值都要高于FOMs.
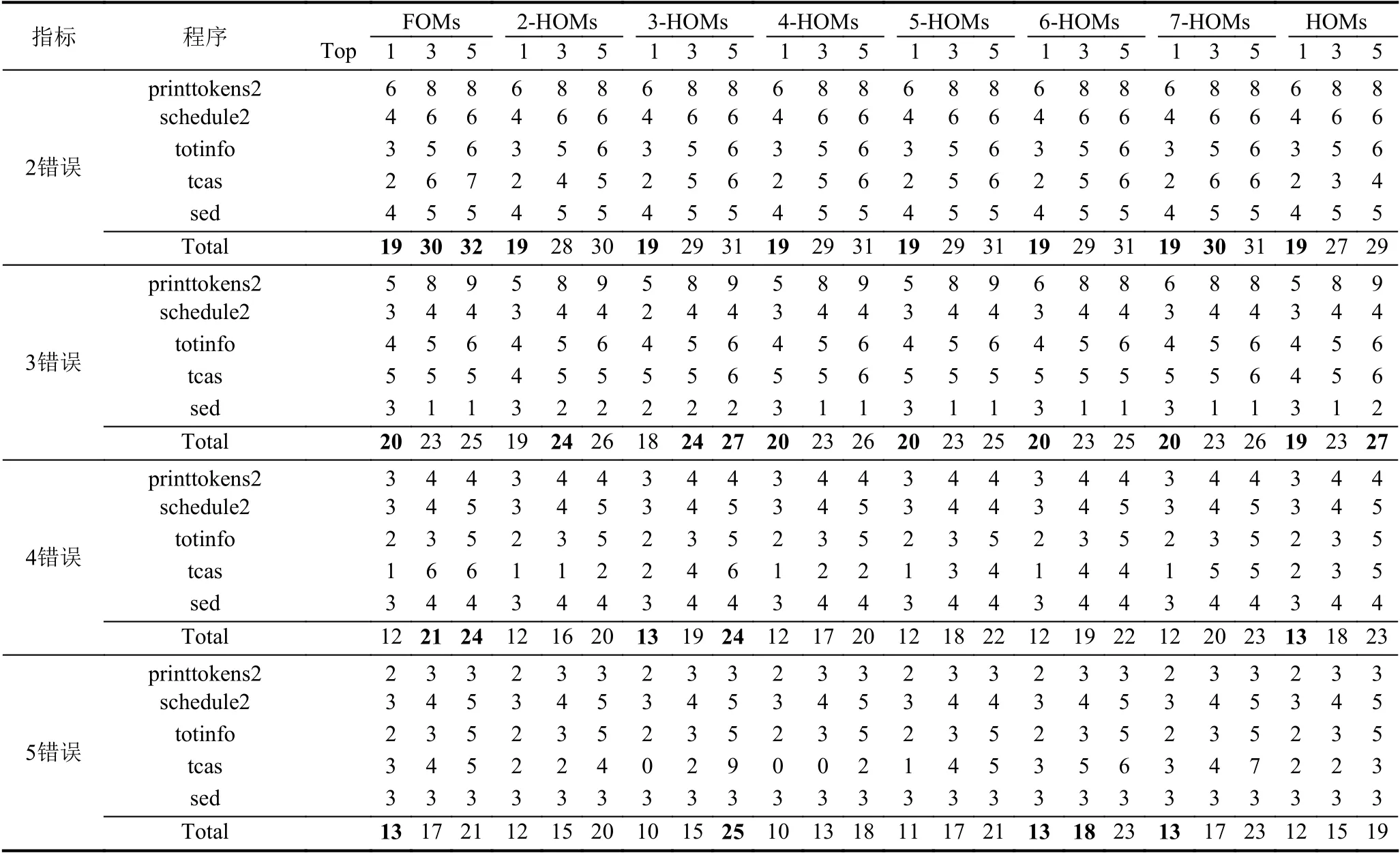
表4 FOMs和不同階HOMs的TOP-N 值比較
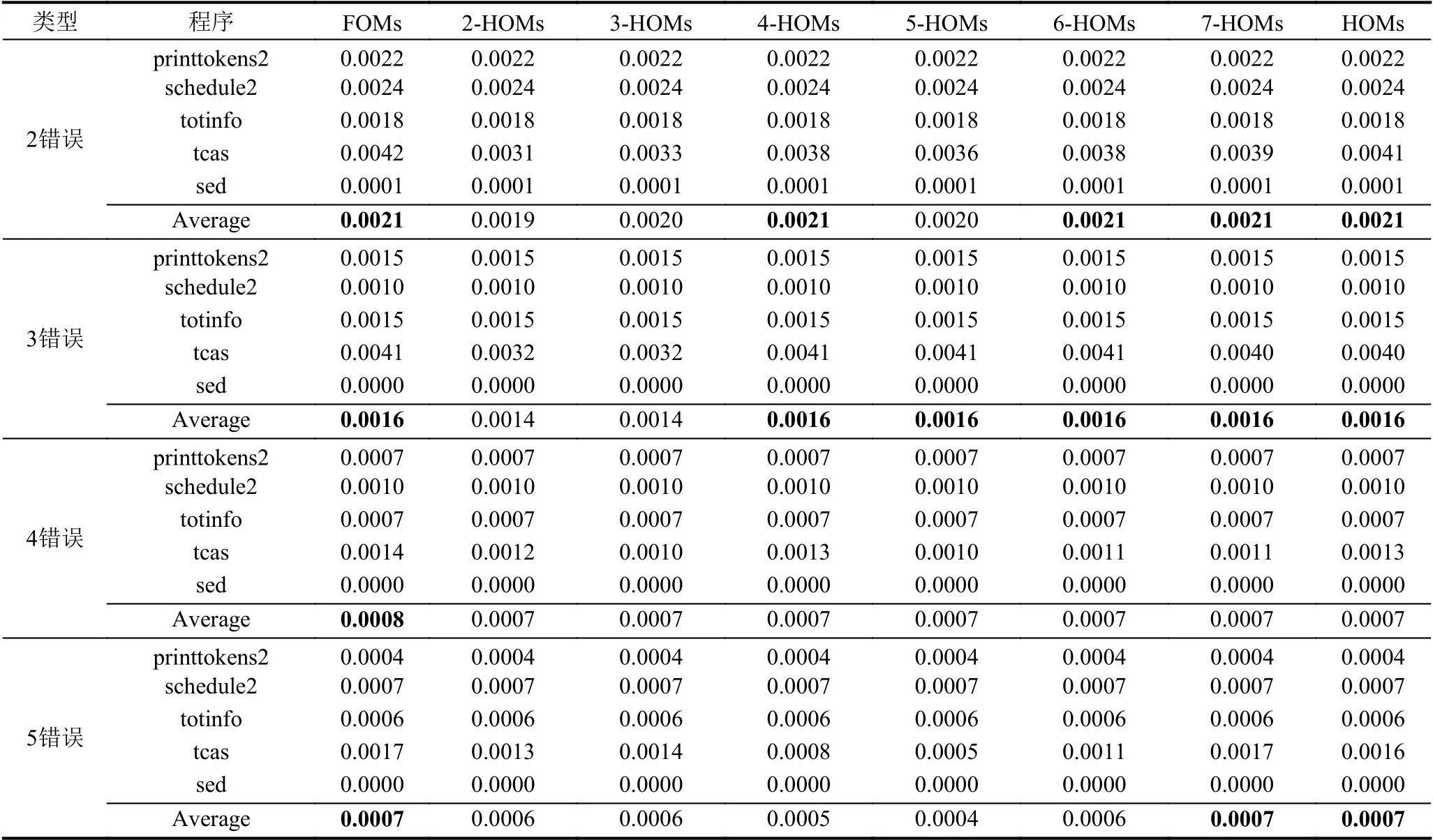
表5 FOMs和不同階HOMs的平均MAP 值比較
由于FOMs 只使用一次變異算子生成而HOMs 使用多次變異算子生成.因此在對同一個程序變異生成等量變異體時,HOMs 有更大的概率變異到錯誤語句,從而增大變異體被殺死的概率,相應akf值也會更高,則變異體懷疑度也越高,最終計算的語句懷疑度也越高,其定位效果也更優(如圖4(a),圖4(c),圖4(e);表4“3 錯誤”行,“5 錯誤”行;表5“3 錯誤”行,“5 錯誤”行).但如果HOMs 中更多變異體是對正確語句變異生成的,那么相應的akp值會更高,計算的語句懷疑度值也更高,錯誤定位效果將更差.(如圖4(d);表4“2 錯誤”行,“4 錯誤”行;表5“2 錯誤”行,“4 錯誤”行).綜合比較可以得出HOMs 在一定程度上能提高多錯誤定位的效果.
為探究RQ2,我們首先收集多錯誤程序所有版本下3 類HOMs的EXAM 值,然后分別計算Top-N和MAP 指標.為了便于展示,我們將3 類HOMs 分別表示為“Accurate”(準確HOMs),“Part-accurate”(部分準確HOMs)和“Inaccurate”(不準確HOMs).圖5表示MBFL 使用FOMs和3 類HOMs 在不同程序上所有版本的錯誤檢查比例.從圖5(a)-圖5(c)中可以看出Accurate HOMs 與FOMs 有相近的表現,并且Accurate HOMs的檢測效果優于FOMs.而在tcas和sed (圖5(d)、圖5(e))程序上,Part-accurate的檢測效果更好,檢查更少量的代碼而找到更多的錯誤.同時在所有程序上,Inaccurate的檢測效果最差.
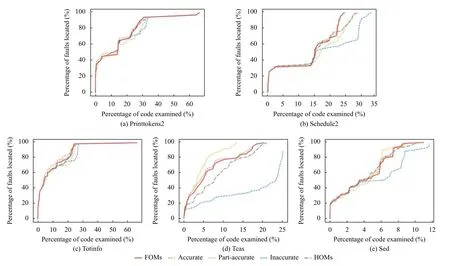
圖5 FOMs 與不同類 HOMs 代碼檢查比例比較
從Top-N 指標來看,準確HOMs 比FOMs和另外兩類變異體能將更多錯誤排在前1,3,5 名.表6中顯示,在2 錯誤程序上,準確變異體與FOMs 能夠排列相同數量的錯誤在Top-1,Top-3和Top-5,而在其他錯誤程序版本中,準確HOMs的Top-N 指標均為最大.同時可以發現,部分準確HOMs 在4 錯誤和5 錯誤程序上,有更高的Top-5 值.然而不準確HOMs的表現最差.
從MAP 指標來看,準確HOMs的表現同樣優于FOMs,部分準確和不準確HOMs.表7中準確HOMs 與FOMs 在2 錯誤程序下有相同MAP 平均值,而在3,4,5錯誤程序下,準確HOMs 仍然比另外兩類變異體的定位效果好,其MAP 平均值分別為0.0017,0.0009,和0.0008.
綜上所述我們可以發現,準確HOMs的錯誤定位精度高于FOMs、部分準確HOMs和不準確HOMs.在一些情況下,部分準確HOMs 有更好的定位效果,但普遍情況下不準確HOMs的表現都很差.

表6 FOMs和不同類HOMs的Top-N 值比較

表7 FOMs和不同類HOMs的MAP 值比較
三類HOMs 由于其不同的生成機制,造成最終定位效果的差異.首先,準確HOMs 準確變異錯誤語句,并且對正確語句不作任何變異,幾乎能夠被所有的失敗測試用例殺死而不被通過測試用例殺死,其akf值高且akp值低,因此最終計算的錯誤語句的懷疑度值會高,其定位效果也就更優(如圖5,表6,表7).其次,部分準確HOMs 同時對錯誤語句和正確語句變異,會被部分失敗測試用例和正確測試用例殺死.其定位效果取決于被失敗測試用例殺死的比例,比例較高則定位精度高,比例較低則定位精度低.因此部分準確HOMs的定位效果存在波動(如圖5,表6“5 錯誤”行,表7).最后,不準確HOMs 只變異正確語句,不對錯誤語句進行變異,那么其更容易被正確測試用例殺死且不易被失敗測試用例殺死,計算的錯誤語句的懷疑度較低,定位效果也就最差(如圖5,表6,表7).因此生成一些特定的HOMs,比如準確HOMs,能有效提升多錯誤定位的精度.
5 結論與展望
為探究HOMs是否能提升多錯誤程序定位,本文進行了大規模的實證研究.研究結果發現,HOMs 在3 錯誤和5 錯誤程序上,有更高的錯誤定位精度.根據不同的變異位置,我們將HOMs 分成3 類.我們發現準確HOMs 比FOMs和其他兩類變異體有更好的多錯誤定位效果.因此,HOMs 在一定程序上能夠提升多錯誤程序定位,并建議研究人員設計方法生成更有效的變異體,比如準確HOMs.在后續的研究中,作者將研究新的策略用于選擇有效提升多錯誤定位精度的變異體.同時考慮擴大實驗數據集來驗證HOMs 對錯誤定位的影響.
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中老年保健(2021年12期)2021-11-30 02:58:01
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
人大建設(2019年12期)2019-05-21 02:55:44
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
