支撐機器學習的數據管理技術綜述?
2021-05-23 13:16:26崔建偉杜小勇
軟件學報 2021年3期
崔建偉,趙 哲,杜小勇
1(數據工程與知識工程教育部重點實驗室(中國人民大學),北京 100872)
2(中國人民大學 信息學院,北京 100872)
人工智能技術的目標是讓機器在某些方面具備人類的智能能力,從而輔助人類完成各項復雜任務.數據、算力和模型是公認的人工智能三要素.近年來,數據規模的快速增長,GPU 等計算設備迭代迅速,計算能力快速提升;機器學習模型、尤其是基于神經網絡的深度學習技術不斷演進.人工智能在圖像識別[1]、語音識別[2]以及智能問答[3]等領域的多項任務效果已經超過真實人類水平;與此同時,多家科技企業也將人工智能作為公司重要戰略.
機器學習是目前實現人工智能的主要途徑,是通過對數據進行建模而提取知識的過程.傳統的數據管理技術主要支持結構化數據交易型應用OLTP(online transaction processing)、結構化和半結構化數據的分析型應用OLAP(online analytics processing)等;非結化數據因為4V[4]的特點,目前尚未形成統一的數據管理方案.目前,通過機器學習技術對非結構化數據建模而構建具備預測能力的模型,是非結構化數據分析的重要手段,因而,機器學習技術可以理解為是OLTP、OLAP 等之后的自然延伸,思考支持機器學習的數據庫技術正當其時.
另一方面,機器學習任務的一次訓練過程包括數據選擇、特征抽取、算法選擇、超參數調優、效果評測等多個子過程;而在訓練結束獲得效果評測后,通常需要人工對模型效果進行分析,挖掘模型效果與數據、特征和算法之間關聯,并基于數據分析或者人工經驗對訓練子過程進行調整,重新訓練以提升模型效果;這個過程通常會多次循環迭代進行,直到模型效果達到應用要求.顯然,相比與數據庫系統的查詢與分析任務,機器學習任務要復雜得多.由于機器學習訓練子過程和迭代調整次數較多,且許多子過程需要人工參與,機器學習的訓練過程目前仍然采取以任務為中心的做法,根據任務的特點對訓練子過程進行定制化優化.這種做法人工參與成本較高,且無法在多任務之間實現數據、特征、模型等資源的復用,因而存在成本高、效率低、能耗大[5]的問題.如何降低機器學習過程的成本,提高機器學習建模的效率,就成為一個重要的需求.
數據管理技術,尤其是數據庫和數據倉庫系統經過多年的發展,形成了一套獨特的方法論,包括以數據模型為核心、以層次化結構實現數據與應用之間的獨立性、提供面向任務的描述性語言、通過查詢優化技術提升任務執行效率等.從數據管理的角度看,機器學習各個子過程均涉及不同類型的數據讀寫、轉化和計算,具有顯著的數據管理與分析需求.將數據庫和數據倉庫的關鍵技術和系統構建經驗應用于機器學習訓練過程,有助于對機器學習形成系統的管理方案,從而提升整體效率.本文對支撐機器學習的主要數據管理技術進行整理和歸納,并提出若干研究課題.
本文第1 節概述人工智能與機器學習的發展歷史、機器學習主要類別.第2 節從數據管理和系統構建的視角對機器學習訓練過程進行解構,提出研究框架.第3 節~第7 節將具體介紹支撐機器學習的數據管理關鍵技術,包括數據選擇、數據存儲、數據存取、自動優化、以及系統構建的若干模式.最后,展望支撐機器學習的數據庫系統的挑戰與未來研究方向.
1 機器學習的建模過程
1.1 機器學習發展歷史
人工智能的歷史可以回溯到上世紀60 年代,早期實現人工智能主要是基于規則的方法,對特定領域建立專家系統.比如:ELIZIA[6]通過情緒疏導領域的對話規則總結,最早實現了人機對話;早期的機器翻譯系統也主要是語言學專家通過總結不同語言之間的映射規則而建立.這一時期,人工智能技術尚缺乏主流的應用,主要有兩方面的原因:一是基于規則的方法通常只能處理已出現的請求,不具備通用預測能力,對新請求的預測效果較差;二是基于規則的方法需要人工總結大量規則,其構建成本高且難以維護.
進入20 世紀90 年代,隨著數據不斷積累以及統計模型持續改進,機器學習,也就是通過從已有的數據和經驗中構建具備預測能力的模型,成為實現人工智能的主要途徑,并在許多領域逐漸實現了效果突破.比較有代表性的工作包括基于統計模型的語音識別系統的識別錯誤率顯著降低、基于統計機器翻譯的效果有了顯著提升.相對于基于規則的方法,機器學習方法優勢顯著:一方面,機器學習模型的通用預測能力較強,能夠從數據中學習到隱藏的模式,更好地響應未出現的新請求;另一方面,機器學習通過從數據中直接學習知識,相對于人工總結規則,維護成本大大降低;通過不斷的積累和清洗數據,通常能持續維護和提升機器學習模型的效果.這一時期,數據逐漸成為決定機器學習和人工智能效果的核心要素,在數據資源豐富的領域,語音識別和機器翻譯已經逐漸實用.
進入20 世紀,互聯網快速發展,搜索引擎、社交網絡等互聯網應用快速推廣,文本、圖片、語音、用戶行為等數據快速積累;與此同時,機器學習模型也進一步改進,兩者相互促進,推動機器學習成為搜索、社交網絡等重要應用的核心技術.以文本理解為例,SVM[7],CRF[8],LDA[9]等模型成為互聯網內容理解的主要工具,幫助用戶快速找到需要的文檔.這一時期,支撐機器的訓練數據已經極大豐富,從數據中抽取和選擇能夠表達數據特性的特征,通常稱為特征抽取或特征工程,成為決定機器學習效果的另一重要要素.以搜索引擎排序為例,通常需要從原數據抽取千級別以上的特征數量,并通過Learning to rank[10]等方法決定不同特征對于排序任務的重要程度.對于文本數據,tfidf,ngram 等特征能夠一定程度表達文本潛在語義,對各類下游任務,如分類、聚類等任務都能起到較好的數據區分作用;而對于語音、圖片等類型的數據,當時特征抽取的方法還不足夠表達數據的潛在語義,因而語音識別和圖片理解任務效果尚未進一步取得顯著突破.
2010 年以來,隨著計算密集型硬件GPU,FPGA 等的快速迭代,基于神經網絡的深度學習技術在人機對弈、語音、圖像處理等領域效果取得了顯著提升.以圖像識別為例,通過在海量圖片數據ImageNet[1]上進行學習,深度卷積網絡在某些圖片分類的效果已經超越人類水平.深度學習通過神經網絡對數據進行端到端的特征抽取和建模,將兩者統一到神經網絡的計算中,通過神經網絡逐層計算,形成對原數據不同粒度的特征抽象.實際表現證明:這種端到端的建模方式在許多任務上都能帶來效果提升,尤其是對語音、圖片等原始數據輸入的任務,人工設計特征通常難以表達潛在的語義,深度學習的方法會帶來顯著提升.深度學習算法因為表達能力更強、自動進行特征抽取和選擇,最近幾年推動了人工智能技術廣泛應用.通常來講,深度學習算法依賴的訓練數據規模更大,訓練周期更長.比如近期快速發展的預訓練技術[3,11],預訓練階段可能需要在T 級別的數據上訓練,即使在多臺GPU 機器上也需要數周的訓練時間.
總之,機器學習訓練是通過對已有數據進行抽象,構建具有預測能力模型的過程.數據、特征、算法是影響訓練效果的重要因素.從發展趨勢上看,機器學習算法復雜度不斷增加,依賴的數據規模不斷增大,提升效率、降低成本,將成為決定機器學習廣泛應用的關鍵因素.
1.2 機器學習訓練過程
通常來講,可以將機器學習算法分為監督學習、非監督學習、強化學習等主要類別,機器學習訓練過程可以表達為基于訓練數據最小化損失函數的過程.對于監督學習,訓練數據同時包含輸入數據和數據標簽,通過學習輸入數據和數據標簽之間的映射關系來優化目標;對于非監督學習,訓練數據不包含數據標簽,通常是通過學習數據潛在結構來優化訓練目標;強化學習則通過數據構建代理與模擬環境,通過代理與環境的交互獲得反饋來實現目標優化.
圖1 抽象了主要機器學習類別通用訓練過程.對于特定任務和給定原始訓練數據情況下,訓練過程通常首先進行數據選擇和特征抽取,選擇出任務相關的數據、并抽取具備區分能力的特征.接下來,由于同一任務可以使用多種算法,需要根據任務、數據和特征選擇適合的算法.之后開始模型訓練,許多算法需要在數據上多次迭代逐漸優化目標函數.在得到訓練模型后,需要做效果評測,監督學習通常在對訓練不可見的測試數據上進行,計算出準確率、召回率等指標;非監督學習可以通過先驗指標或人工的方式評測.上述整個過程可以稱為一次訓練嘗試,之后分析評測發現的問題,通常會調整數據選擇、特征抽取、算法選擇等步驟,進行下一次嘗試,如此循環,直到評測效果滿足要求.

Fig.1 Training process of machine learning圖1 機器學習訓練過程
2 支撐機器學習的數據管理技術研究框架
首先,從數據的視角分析機器學習訓練過程,討論子過程的數據存取與計算,梳理數據管理與分析需求;其次,將機器學習任務看作訓練數據上的一類查詢請求,討論在任務與數據之間構建機器學習系統的必要性,以及系統需要具備的功能;最后,基于上述分析,從數據管理、自動優化和系統設計與實現這3 個方面歸納支撐機器學習的數據管理與技術,提出本文研究框架.
2.1 從數據的視角對機器學習訓練解構
基于圖1 所示的機器學習訓練過程,圖2 給出了各個子過程的數據處理流程.從各個子過程看,數據選擇對于同一份原始數據可以針對任務形成不同的選擇結果,輸出多份中間數據;數據選擇之后,特征抽取需要抽取各種類型的候選特征供后續算法嘗試;算法選擇需要基于任務需求、數據和特征的統計信息選擇算法并確定超參數,比如對輸入文本抽樣分析確定聚類算法和聚類個數等超參數;模型訓練在迭代優化過程中會產生多個中間結果模型以及最終模型;效果評測則需要依賴最終模型和評測數據,產出準確率、召回率等測試結果;而問題發現與分析除了參考測試結果,也需要分析每個子過程輸入輸出數據之間的關聯.可以看出,機器學習過程涉及多種類型、多個步驟的數據讀寫和分析,具有顯著的數據管理與分析需求.
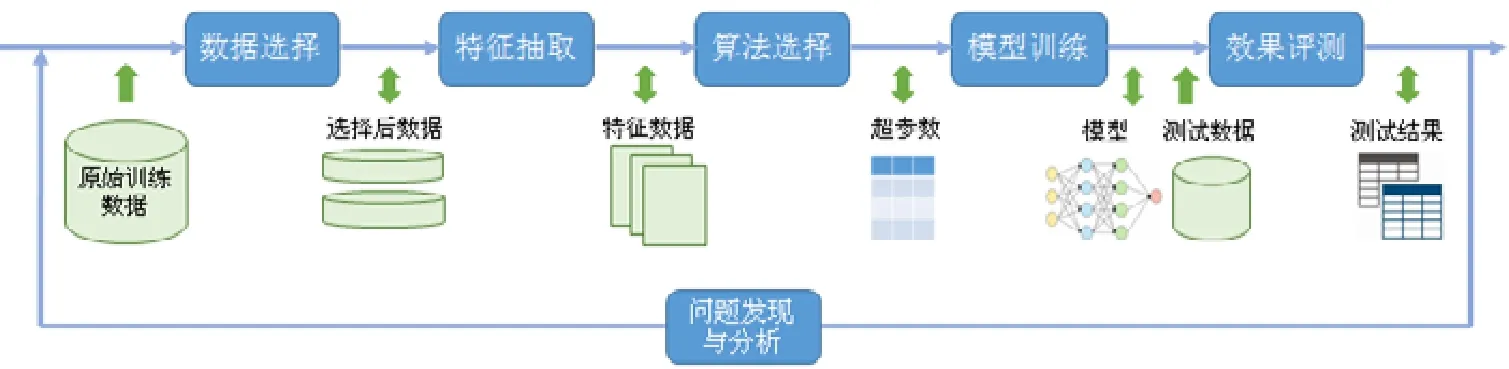
Fig.2 Data flow for training process of machine learning圖2 機器學習訓練數據處理
圖2 所示的訓練過程需要多輪嘗試,以獲得優化的模型效果.通常來說,下輪訓練嘗試會基于當前模型效果對相關步驟進行一些調整,比如根據評測結果新選擇一些相關的訓練數據、增加或減少一些特征,之后進入新一輪訓練.這個過程會進行多次,直到模型效果達到要求.同一任務的多輪訓練,為數據復用提供了潛在機會.比如在當前特征集合,相對于上一輪如果只減少某個特征,那么可以較大比例地復用上一輪特征,避免重復特征抽取;比如當前輪只調整了超參數,則可以完全復用上一輪的數據和特征.
總結而言,從數據的視角看,機器學習可以看作是一個循環進行的多步數據處理與分析過程,具有顯著的數據管理與分析需求和數據復用潛力.因此,數據管理與分析技術在機器學習中有重要應用.
2.2 從系統的視角對機器訓練解構
從系統的視角看,機器學習訓練可以看作是輸入數據上的一類查詢操作.如圖3 所示:訓練請求的描述作為硬件環境和訓練數據之上的查詢條件,模型作為查詢結果.與數據庫統計查詢相比,機器學習通過算法挖掘數據潛在模式并形成預測功能,因而查詢的計算邏輯更加復雜.訓練請求的描述通常是算法的邏輯表達,映射為訓練數據和硬件環境上的物理執行需要較多的轉化和優化工作;比如,需要考慮多種類型的數據存儲和讀取方式、以及考慮硬件的計算能力和內存限制合理調度計算.人工進行上述轉化和優化需要較多的系統優化經驗,工作量較大且優化的方法難以在不同任務間復用.因此,在訓練任務和數據與硬件環境之間構建通用的機器學習系統,對各類機器學習算法效率進行整體優化,有利于提升模型構建和訓練的效率.
基于機器學習訓練過程的計算特點,機器學習系統需要包含3 項重要功能.
? 語言處理功能.使用機器學習領域描述性語言進行建模,比如矩陣運算等;描述性語言建模過程較快、新算法支持靈活,構建過程只需要關注任務和算法本身而忽略執行細節;系統需要完成描述性語言向實際數據的讀寫和硬件上計算的轉換;
? 查詢優化功能.訓練環境通常存在異構硬件,描述語言指定的訓練過程通常有多種物理實現方式;系統通過自動優化技術,為任務自動生成優化的物理實現,減少人工參與優化過程,整體提升訓練效率,也能夠實現上層語言構建的模型在不同硬件環境執行;
? 數據存儲與存取功能.基于數據自身結構特點,實現任務無關的存儲和讀取優化,整體優化存儲成本的存取效率;同時,通過對多任務數據的系統管理,挖掘數據復用機會.
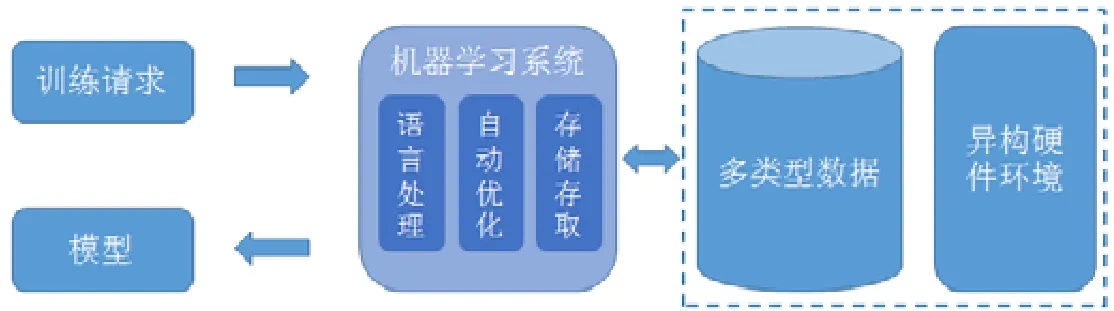
Fig.3 Machine learning as query request and system support圖3 機器學習查詢請求與系統支持
總結而言,從系統角度看,機器學習訓練可以看作一類復雜分析的數據查詢請求.通過系統支撐訓練過程,能夠提升建模速度、挖掘多任務之間的語義關聯,通過任務間數據復用提升整體存儲和計算效率.
2.3 研究框架
當前,機器學習訓練過程以任務為中心的方式進行,為特定任務進行數據存儲和計算優化,尚未形成整體的數據管理和系統性優化方案.基于前文對機器學習訓練過程的數據管理和系統支撐需求分析,提出如圖4 所示的研究框架,對支持人工智能的數據管理與分析技術進行歸納與總結,梳理技術現狀,提出優化方向.
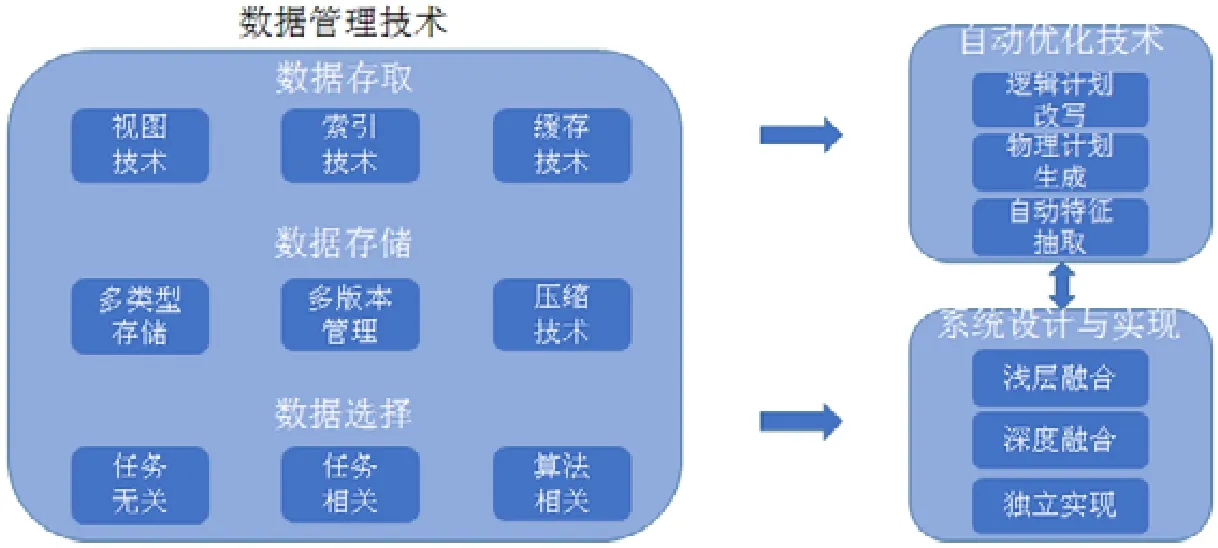
Fig.4 Research framework of data management technologies for maching learning圖4 支撐機器學習的數據管理技術研究框架
數據管理技術以訓練過程中各類數據作為對象,從數據選擇、存儲和存取方面總結和梳理現有技術在選擇任務相關的訓練數據、存儲和讀寫效率優化方面的工作,并提出機器學習數據管理新研究方向.自動優化技術將借鑒數據庫查詢優化經驗,梳理對描述性語言進行邏輯計劃改寫、物理計劃生成和自動模型選擇方面的工作;機器學習計算通常更為復雜,自動優化技術還有較大發展空間,提出后續優化方向.系統設計與實現將討論實現機器學習系統的不同方法,包括基于數據庫系統并進行淺層或深度的融合方法以及基于數據庫設計思想在數據庫之外獨立實現,以最大限度復用系統已有的功能和實現經驗.未來,隨著機器學習技術廣泛應用,在線機器學習需求顯著,提出數據管理與分析技術的挑戰和研究新方向.
3 個維度的關系是:數據管理技術和自動優化技術為在訓練過程可以獨立運用的局部優化,也是機器學習系統的核心功能;機器學習系統的實現則是從全局的角度實現各類技術的合理集成,一方面為機器學習訓練提供完整的系統支持;另一方面,也為各項優化技術持續改進提供平臺支撐.
3 數據選擇技術
數據選擇是從原始輸入數據中選擇與機器學習任務相關訓練數據的過程.原始輸入數據通常規模較大,包含重復或者與訓練任務不相關的數據,直接在原始輸入數據上訓練可能面臨訓練周期長、任務效果不夠優化的問題.因此,自動選擇與任務相關的語料將有助于提升訓練效果與效率.數據選擇的主要挑戰是建立訓練數據之間、訓練數據與訓練任務和算法之間的關聯性,進而選擇出數據規模適中對訓練任務和算法效果幫助最大的訓練數據子集.本節將首先介紹任務無關的方法,通過少量數據能夠覆蓋全量數據的語義空間;其次介紹任務相關的方法,從通用的訓練數據中選擇與任務領域相關的數據;最后介紹算法相關的方法,自動選擇對算法效果影響較大的訓練數據.
3.1 任務無關的數據選擇
數據通常可以表達為高維空間中的向量,訓練數據集可以看成是高維空間中的區域.任務無關的方法通常基于區域覆蓋,假設原始數據包含重復、相似或相關的數據,可以選擇一組規模較小且相互獨立的數據來覆蓋原數據在高維空間中的區域.因此,在選擇后的數據上的訓練效果不會明顯降低,但效率可能顯著提升.常用的任務無關的數據選擇方法包括采樣算法和基于相似度計算.
隨機采樣是常用的采樣算法,隨機抽取一定數量的數據作為采樣集用于后續訓練.當數據在高維空間中分布較均勻時,采樣集通常能夠較好地覆蓋原始數據區域.但對于分布不均勻的情況,比如分類問題中不同類別訓練數據量差異較大,隨機采樣可能會漏掉部分類別的訓練數據,或者需要較多次采樣才能覆蓋.Coresets[12]是一種更復雜的采樣技術,首先通過數據向量表達計算之間的相關性,得到每條數據被選擇的概率以反映所在高維空間的分布,之后按照選擇概率抽樣.Coresets 所需的采樣次數通常與原始數據向量表達的維度有關,與原始數據量無關;對于數據量大但維度較小的情況,能以很少的采樣數量覆蓋原始數據區域.
基于相似度計算的方法通過定義和數據間相似度計算,選擇互相之間相似度較低的子集來表達完整的原始數據集.通常來講,數據可以表達為向量,相似度可以通過余弦計算.比如對于文本數據,可以通過文檔向量模型表達數據.近年來,深度神經網絡被廣泛用于抽取數據的潛在語義的向量表達,比如:可以使用詞向量[13]、句向量[14]來表達文本,可以通過卷積神經網絡的隱層向量來表達圖片,通過遞歸神經網絡的隱層向量來表達語音.獲得相似度后,可以增量添加的進行數據選擇.比如:先隨機選擇一條數據,之后優先選擇并添加與所有已選擇數據均不相似的數據;也可以通過聚類的方法,比如采用k-means 等算法將數據進行分類,之后從個聚類中選擇一定量的數據形成對原始數據的覆蓋.
3.2 任務相關的數據選擇
對于監督學習任務,通常會面臨缺乏任務領域相關的訓練數據的挑戰:一方面,某些領域的訓練數據本身比較稀缺,如低資源語言的機器翻譯任務;另一方面,在實際產品中,機器學習模型的領域數據通常依賴于用戶對產品的請求,在產品被廣泛使用前,通常缺乏領域數據.任務相關的數據選擇技術方法基于少量的領域相關的訓練數據,從海量通用數據中選擇與任務領域相關的數據擴充訓練數據,通常能夠顯著提升數據稀缺的訓練任務.本節將介紹兩類基于領域的數據選擇方法——基于生成的方法和基于判別的方法.
? 基于生成的方法首先基于少量領域數據學習領域相關生成式模型,如語言模型、AutoEncoder[15]等,學習領域相關數據的潛在結構;之后,利用生成式模型計算通用數據的生成概率,選擇生成概率較大的數據用于后續訓練[16,17].也可以在領域數據和通用數據上各訓練一個生成式模型,如果數據在兩個生成式模型的生成概率類似,則將通用數據用于后續訓練.以自然語言處理任務為例,可以使用領域相關的數據訓練神經語言模型,之后對通用領域的數據進行解碼,并基于解碼得到的困惑度(perplexity)[18]來表示生成概率,進而選擇困惑度較低的數據加入訓練;
? 基于判別的方法將領域相關的數據作為正樣本,從通用數據中隨機采樣數據作為負樣本,基于正負樣本構建領域數據分類器,學習領域相關和領域無關數據之間分布上的差異,通過分類選擇正向分類概率較高的數據輸入后續訓練使用[19].由于領域相關的數據規模較小,分類器的效果可能較差,可以通過融入半監督特征增強分類器的效果.比如對于文本數據,可以先在海量非監督語料上訓練語言模型,獲得任務無關的通用語言序列和結構表達能力,之后將通用語言模型在正負樣本的隱藏層輸出作為特征,與正負樣本一起訓練領域數據分類器,通常能夠獲得更好的分類效果.
3.3 算法相關的數據選擇
算法相關的方法選擇對具體算法效果提升最大的數據用于訓練.與任務相關的數據選擇方法相比,算法相關的方法更能體現特定算法對訓練數據的區分度差異.比如:對于同一分類任務,通常有邏輯回歸、支持向量積等不同算法,可能會將原始數據映射到不同的高維空間,因此,優化不同算法依賴的數據分布可能不同,需要針對性的選擇.算法相關的方法總體基于主動學習[20]的思路,基于模型當前預測能力計算數據對當前模型的效果提升,選擇提升最大的數據用于后續模型訓練.本節將分別從基于增量選擇的方法和基于數據加權的方法兩個方面介紹.
? 增量選擇的方法首先基于少量的領域相關數據訓練初始模型,之后使用初始模型預測通用數據,選擇最容易預測錯誤的數據加入訓練.如此循環,直到模型效果符合預期[21].判斷預測是否容易發生錯誤,可以基于模型對預測結果的置信度.對于分類任務,置信度可以通過概率最高的類與次高的類之間的差異來評估,差異越小,則置信度越低;也可以根據多個類別上概率的交叉熵來評估,交叉熵越高,置信度越低.對于生成類任務,置信度可以基于模型生成的結果與真實結果的差異來評估.增量選擇方法只在選擇后的數據上訓練,通常效率更高,但可能遺漏部分對模型效果有提升的數據;
? 基于加權的方法首先在全量通用數據上進行一輪訓練得到初始模型,后續迭代過程中,逐步增加當前輪模型容易預測錯誤的數據權重,以快速提升模型在整體數據上的預測效果[22].目標函數的優化通常會在數據上多次迭代進行,比如采用隨機梯度下降等方法,模型每次迭代都學習到訓練數據的部分知識.可以使用當前迭代模型對數據進行預測,如果置信度較高,則說明已經學習到該條數據的知識,后續訓練可以降低該條數據的權重;反之則可以增加該條數據的權重.置信度的計算與任務相關的方法中的介紹類似.基于加權的方法由于首先在全量數據上進行訓練,通過逐漸增加重要訓練數據的權重而避免直接丟棄部分訓練數據,通常可以保留訓練數據的整體知識,模型魯棒性更強;但相對于基于增量的方法,訓練周期可能更長.
3.4 小 結
數據是影響訓練效果的源頭性因素,數據選擇是模型訓練效果和效率重要決定因素.上述3 類數據選擇方法總體是基于單任務的一輪訓練過程,將來優化方向包括:1)在單任務多輪訓練訓練場景下,如何復用前輪的數據選擇結果優化當前輪數據選擇的效率;2)在多任務訓練的場景下,如何復用相關任務的數據選擇結果優化當前任務數據選擇的效率.
4 數據存儲技術
機器學習訓練過程會讀取或產生多種類型的數據,對各類數據進行合理存儲,是后續數據存取與分析的基礎.面向機器學習的數據存儲技術面臨許多挑戰:首先,訓練過程中需要輸入和產生的多種類型的數據,包括結構化數據、半結構和非結構化數據,需要依賴多類型存儲系統形成統一的存儲方案;其次,建模和訓練過程通常需要多次迭代優化模型效果,同一數據會生成多個版本,需要兼顧多版本存儲成本和讀取效率;最后,隨著數據規模增大,壓縮技術能夠提升數據讀寫效率,需要基于數據之間的關聯,探索壓縮比更高且計算開銷更友好的壓縮算法.本節將針對上述挑戰討論和總結相關工作.
4.1 多類型數據存儲
機器學習訓練過程主要涉及的數據類型為訓練數據、特征和模型,同時也涉及訓練日志、評測結果等相關數據.首先介紹主要數據類型的常用存儲方法,其次介紹相關數據存儲,體現數據間關聯、幫助問題分析.
對于結構化的訓練數據,可以采用關系數據庫表存儲;半結構化訓練數據可以存儲在KV 系統中,或者采用JSON,XML 等可以靈活擴展屬性的格式存儲在文件中.TFRecord[23]是一種靈活和緊湊的文件格式,采用Protobuf[24]可以自解析地表達任意類型數據,內部采用二進制存儲,方便分塊壓縮以及機器間網絡傳輸;對于大規模訓練數據,采用TFRecord 格式存儲將有利于進行分布式處理.特征數據通常表達為矩陣:行表示數據,列表示不同維度的特征.列較少的特征矩陣可以存儲在關系表中,以表屬性存儲列;較大規模的特征矩陣可以采用TFRecord 等文件格式分塊或者整體存儲.模型一般表達為參數矩陣之間的有向無環圖,可以用通用的格式ONNX[25]來存儲,不同類型機器學習框架的模型存儲格式可能不同.
除了數據、特征和模型,訓練過程還包括任務描述、超參數、損失函數變化等多類信息,需要形成統一存儲方案來體現數據之間的關聯.ModelDB[26]以模型為中心,關聯存儲依賴的訓練數據、特征、超參數、評測結等數據,支持查看和追蹤訓練過程數據流.同時,為方便訓練過程問題發現與分析,可以基于數據沿襲[27]技術存儲數據選擇、特征抽取等過程細粒度數據變換的映射關系,方便正向和反向的溯源查找.
4.2 多版本數據存儲
機器學習訓練過程迭代進行,同一份數據可能產生多個版本.首先,同一任務的一輪訓練過程通常需要在輸入數據上迭代優化目標函數,每次迭代都會產生一個模型版本;其次,機器學習模型調優的過程通常需要多輪訓練嘗試,每輪訓練可能會對數據、特征和模型進行調整,形成多個版本.本節介紹首先介紹多版本數據通用存儲方法,接下來分別介紹針對訓練數據和模型的優化存儲方案.
對于多版本存儲需求,數據庫和文件系統已經有成熟的解決方案.HBase[28]等數據庫系統以及AWS S3[29]等文件系統均原生支持多版本存儲,可以分別存儲訓練過程中的結構化、半結構化和非結構化數據.可以配置同一數據允許存儲的最大版本數,避免存儲過多版本;也可以通過設置最長過期時間(time-to-service)來清理長期未適用的版本.
對于訓練數據,同一任務多次迭代訓練形成的多個版本之間通常有較大比例的數據重復,可以采用全量存儲和增量存儲結合的方式優化存儲成本.DataHub[30,31]借用Github 的思想對連續改變的多版本數據進行管理,支持修改后添加新版本,從多個已有版本數據合并形成新版本等操作.對于某個版本的數據,可以全量存儲,也可以增量存儲相對某個已有版本的增量變化.通過構建數據版本圖,以數據版本為節點,邊表達版本之間增量存儲的存儲成本和重構成本,成本最優的存儲方案可以通過基于數據版本圖上邊的存儲成本來搜索最小生成樹.實際應用中,在最小化存儲成本的同時,也需要限制重構成本的上限,實現兩者之間的平衡.
ModelHub[32]提出針對模型的多版本存儲方案,由于模型主要由浮點類型參數矩陣構成,尚難有清晰的語義解釋;即使是同一輪訓練得到的不同版本模型,在整體參數值上也可能表現出較大的差異,不利于增量存儲.因此,ModelHub 對模型進行更細粒度拆分,構建類似DataHub 的數據版本圖,將參數矩陣作為數據版本圖的節點.對于同一輪訓練產生的多個中間結果模型,其對應的參數矩陣數值通常變化不大,通過增量存儲可以帶來存儲空間收益;而同一訓練任務多輪訓練產生多個模型,其浮點參數的尾數高位部分可能變化較小,可以截取高位尾數進行連續存儲,降低該部分的存儲空間.與DataHub 不同的是,讀取模型時需要同時讀取其所包含的所有矩陣,因此在數據版本圖搜索最小生成樹時,需要考慮多節點共同讀取的要求.
4.3 數據壓縮
壓縮技術通過避免多次存儲數據中的重復模式,能夠減小數據存儲和讀取成本.隨著機器學習訓練所需要的數據規模不斷增加,壓縮技術可以有效降低訓練中數據讀取規模,也能幫助更多常用數據常駐內存,提升計算效率.輸入數據和特征通常都可以用矩陣表達,本節首先介紹通用數據壓縮技術在矩陣存儲上的應用,接下來介紹基于矩陣列簇的壓縮技術,以及支持在非解壓數據上直接進行訓練的壓縮技術.
稠密矩陣可以連續存儲,如果矩陣規模較大,可以進行分塊劃分存儲,進而應用塊壓縮技術進行壓縮[33].需要考慮一些壓縮選項:一是壓縮算法的選擇,訓練過程本身計算開銷較大,需要考慮解壓算法的計算開銷,可以根據需要選擇如Snappy[34]等輕量級壓縮算法,可以根據每個分塊的數據分布特點選擇不同的壓縮算法;二是如果需要對塊內數據進行多次更新,比如多次更新訓練數據或特征,可以將數據塊在邏輯上劃分成更小的分片,對分片數據進行分別壓縮,避免更新時對整個塊進行解壓.
特征之間通常并會完全獨立,因而特征矩陣的的列之間可能存在相關性.將相關性較強的行或者列進行組成列簇,對列簇進行整體壓縮可能帶來更高的壓縮比[35].具體而言,在矩陣寫入時,可以基于數據抽樣快速計算列之間相關性搜索出列簇劃分.不同列簇可以選擇不同的壓縮算法,比如列簇內重復數字的位置如果較連續,可以采用行程長度壓縮算法[36];而如果列簇內的數據重復度較低,則可以選擇不進行壓縮.通過對列簇的選擇不同壓縮算法,實現更優的局部壓縮,從而在整體矩陣上實現更高壓縮比.
特征矩陣通常每行表示一條訓練數據,列表示不同維度的特征值.塊壓縮技術忽略矩陣行之間的邊界,訓練讀入時必須先對整塊解壓,分離出行數據后才能進行計算.可以用字典記錄每行數據的邊界位置,壓縮算法避免跨行壓縮,進而支持在壓縮數據上直接進行訓練[37].比如:如果使用前綴樹壓縮算法,讀取到行邊界時可以停止繼續查找更長前綴,多行共同具有的重復模式只存儲一次,實現壓縮效果;同時,行內的數據壓縮可以保留訓練算法所需要的列索引信息,這樣對壓縮數據進行順序讀取時,可以獲得數據的行索引和列索引,算法訓練可以直接在壓縮后的數據上計算[38].
4.4 小 結
目前,機器學習數據存儲仍主要以任務為中心為主,尚未形成統一的存儲模式.將來,從不同訓練任務中抽象出統一數據存儲模式、挖掘任務間的數據語義關聯,將成為從數據的視角管理機器學習訓練過程的基礎.以此為基礎實現任務間數據共享與復用,能夠顯著降低工業級機器學習應用的資源成本.
5 數據存取技術
機器學習訓練過程需要對訓練數據、特征、模型等數據進行變換和多次讀寫,數據存取技術,如視圖、索引和緩存等技術,對于提升訓練效率至關重要.面向機器學習的數據存取技術將面臨許多挑戰:首先,數據和特征的變換可能使用較復雜的線性變換,對變換得到的中間結果進行高效增量維護將面臨挑戰;其次,機器學習通常需要處理非結構化數據以及以通常將各類數據表達為矩陣,需要探索針對非結構化數據和矩陣的索引方法以提升數據讀取效率;最后,可以緩存高頻讀取數據以優化效率.由于不同數據的重構計算成本不同,緩存方案需要同時考慮緩存開銷和重構計算成本.本節將介紹針對機器學習訓練過程的視圖、索引和緩存技術.
5.1 視圖技術
在數據庫領域,對于同一關系表,不同應用可能具有相同的數據選擇或轉化需求.數據庫通過視圖技術來管理通用的數據選擇或轉化的邏輯與結果,實現數據與上層應用的邏輯獨立,并通過復用中間結果提升整體讀取效率.視圖通常分為Layzer 和Eager 兩種模式:Layzer 并不實際存儲中間結果,在數據讀取發生時,實時從原數據表讀取數據并計算,實現了數據選擇和轉化邏輯的復用;Eager 模式則實際存儲和維護中間結果,直接從視圖中讀取數據,實現了數據選擇和轉化結果的復用.本節首先介紹基于視圖技術管理數據轉換和特征抽取中間結果的管理,其次介紹針對線性代數變換的增量視圖維護方法.
機器學習訓練通常需要多種類型、多個步驟的數據轉化處理.對于文本為輸入,通常需要進行大小寫歸一化、詞根提取等操作;對于圖片輸入,通常需要對圖片進行旋轉、分辨率變化等操作.特征抽取和選擇可以認為是機器學習特有的數據轉換,同一任務多輪訓練嘗試使用特征集合通常存在重復,同一原數據上不同任務的特征集合通常也不是完全獨立.因此,通過視圖存儲公共的數據處理和特征抽取中間數據,可以在多訓練任務之間實現數據復用,提升讀取效率.具體來講,可以統計每個任務特征集合的訪問頻率,對不同特征集合采取不同的視圖存儲模式(Layzer 或Eager),整體平衡多任務的特征存儲成本和存取效率.COLUMBUS[39]針對相關任務特征集合之間存在重復,提出對特征集合的并集矩陣進行QR分解,Q是正交矩陣,R是上三角矩陣,可以看作多任務特征的公共中間表達,后續數據變換基于Q和R進行計算會更高效,因而可以采用Eager 模式視圖對Q和R進行存儲.
機器學習訓練可能會對數據進行一些復雜的變換,比如插值和線性變換等.原始輸入數據在迭代過程中通常會增量更新,增量更新在這類復雜變換中的傳播模式相對復雜,使用視圖維護變換后的結果并增量維護將面臨挑戰.對于插值計算變換,增量數據只影響局部數據的插值結果,MauveDB[40]提出通過線段樹來索引原始數據,進而快速查找增量數據影響的局部原始數據,進而實現增量更新;對于回歸計算變換,線性變換基函數計算結果通常可以增量更新,MauveDB 提出對基函數變換結果進行物化存儲而實現增量更新.線性代數計算通常可以表達為矩陣乘法,局部增量會通過乘法傳播至全矩陣,使得增量計算的時間復雜度較高;LINVIEW[41]提出:增量矩陣的行和列之間通常不是線性獨立的,可以將增量矩陣分解為兩個低維度的矩陣,降低矩陣乘法增量計算的時間復雜.
5.2 索引技術
在數據系統中,索引是提升數據讀取效率的關鍵技術.常用的索引技術包括Hash 索引、B 樹索引等:Hash索引用于快速執行索引項上的隨機查找,B 樹索引同時支持索引項上的隨機查找和區間查找.對于訓練過程中的結構化數據,可以直接使用數據庫索引提升讀取速度.本節將首先介紹非結構化數據的索引方法;由于訓練過程主要數據類型可以抽象為矩陣,接下來介紹矩陣索引技術.
ZOMBIE[42]提出對數據按照潛在結構劃分成任務無關的不同分組并建立索引,對于特定機器學習任務,可以評估每個分組的數據對模型效果的影響,選擇影響較大的分組數據進行訓練.具體而言:訓練數據可以表達為向量,之后使用聚類算法劃分成k個獨立的分組;訓練過程中,每次從當前對任務效果影響最大的索引組讀取數據加入訓練,索引組對效果的影響可以通過組中已加入訓練的數據來評估.數據聚類通常能夠反映數據潛在特性,有利于模型訓練更快提升效果.比如:如果文檔長度是某個分類任務的重要區分特征,而長文檔可能包含一些共同的詞語,因此,聚類算法可能將長文本聚為一類,訓練過程從長文本所在類中讀取數據可能收斂更快.由于非結構化數據缺乏語義解釋,這種基于數據潛在結構和特征的聚類的分組索引是快速讀取任務相關數據的一種可行方式.
矩陣是機器學習重要數據類型,可能需要同時支持連續讀寫和隨機訪問.如果是稠密矩陣,通常連續存儲的讀取效率較高;對于稀疏矩陣,通常可以將矩陣線性變換為一維數組,根據非零數據的下標建立B 樹索引,葉節點存儲對應數據值,以支持高效的隨機讀取和范圍讀取.與通用的B 樹索引不同的是,矩陣的不同區域可能具有不同的稠密程度.LABTree[43]設計了稀疏類型和稠密類型葉節點,稀疏葉節點存儲每個數據的矩陣索引和數據值.稠密節點對一段連續的值只保留一個索引項,包含連續值的起始矩陣坐標以及值本身,存儲格式更緊湊.LABTree 支持根據矩陣的局部稠密程度自動選擇稀疏類型或者稠密類型的葉節點,比如:當一個稀疏類型的葉節點發生插入操作并觸發葉節點分裂,如果檢測到葉節點數據的連續程度較高,會自動轉換了稠密類型葉節點.
5.3 緩存技術
機器學習訓練通常需要在同一份數據上多次迭代,通過將需要多次讀取的數據放入緩存,可以提升迭代過程中的訓練效率.本節首先介紹基于代價估算的緩存策略,對單次訓練生成訪問效率提升最大的緩存策略;接下來介紹在多任務場景下模型緩存方案.
將單次訓練所有依賴的所有數據作為節點,有計算依賴關系的節點之間添加有向邊,可以構建訓練數據流的有向無環圖(direct acyclic graph,簡稱DAG)[44].為DAG 中每個節點定義執行耗時代價估算:如果節點放入緩存,計算耗時為0,但消耗等數據大小的內存資源;否則,內存消耗為0,節點執行耗時則需要綜合考慮從原始輸入數據節點到當前節點的計算時長,以及該節點被后續節點依賴的次數.基于執行耗時的代價估算,在訓練環境限定內存資源條件下,可以搜索最優緩存策略,以最大程度縮短訓練耗時,在內存資源與計算資源之間取得平衡.
在多任務訓練環境中,對于新訓練任務,可以搜索相關歷史任務的訓練結果,使用其進行初始化將有助于新模型快速訓練收斂.因此,可以通過緩存被新任務依賴較多的模型來提升多任務訓練整體效率.這里,計算新任務與歷史任務相關性是關鍵.COLUMBUS[39]提出使用緩存中的模型對新任務的測試數據進行評測,取效果最好的模型作為新任務的初始化模型;之后,基于LRU 算法,可以將不常訪問的模型交換出內存.實際上,這是一種基于遷移學習[45]的訓練方法,最新預訓練技術[3]的進展驗證了其有效性.結合模型緩存優化等技術,遷移學習是實現基于資源復用的實時機器學習的重要途徑.
5.4 小 結
當前,機器學習訓練的數據讀取對象粒度較大,比如對非結構化訓練數據、特征矩陣和模型進行整體讀取.上述緩存技術主要針對整體數據對象的粒度優化存取效率,并考慮到多輪訓練和多任務間數據復用的需求.未來需要進一步探索訓練中數據對象的內部語義,提煉出適合復用的子結構,通過探索細粒度的存取技術來進一步優化數據讀寫整體效率.
6 自動優化技術
機器學習訓練過程通常采用領域描述語言進行靈活而高效的建模,如DSL(domain specific lanaguage)[46]或者DML(declaritive machine learning language)[47])等.DSL 向上提供矩陣運算、統計函數等機器學習領域的邏輯計算操作,由于需要考慮內部數據表達、機器硬件環境等執行細節,無法直接映射為前述數據存取、存儲技術提供的物理操作,需要使用自動優化技術將DSL 描述的邏輯計劃轉化為可執行的物理計劃,在多種可能的物理計劃中自動決策并選擇最優計劃.本節首先介紹邏輯計劃改寫,由于建模過程通常表達為向量和矩陣之間的連續運算,需要考慮維度等信息,將運算序列改寫為代價最優的等價序列;其次將討論物理計劃生成,需要考慮計算在異構硬件上(CPU、GPU 等)的調度方案;最后討論自動模型選擇,也即為訓練任務自動生成效果較優的訓練計劃,需要在限定的訓練時間內綜合考慮特征選擇、算法選擇和超參數調優等多種因素的合理組合.
6.1 邏輯計劃改寫
將DSL 的運算操作和輸入數據作為節點,操作與數據之間的依賴作為邊,DSL 代碼可以轉換為DAG,稱為邏輯計劃.原始的DAG 中可能包含重復計算子圖、操作執行順序可能不是最優,可以通過邏輯改寫技術將原始DAG 改寫邏輯等價、執行效率更優的新計劃.實際上,關系數據對用戶SQL 進行查詢優化時,會廣泛應用改寫技術,比如選擇下推、投影下推等,其思路是:讓縮減數據規模的操作盡早的發生,這對機器學習邏輯計劃改寫也有很大的參考價值.本節將分別介紹靜態改寫和動態改寫技術.
靜態改寫[46]針對編譯時已確定的參數信息,如矩陣維度等,在DAG 運行前進行改寫.常用的方法包括公共子表達式消除、常量折疊以及分支移除等.DAG 中的公共子表達移除可以遞歸進行:首先,從葉子節點開始標識相同子表達式;之后從,父親節點到根節點逐級遞歸標識和消除.分支移除可以幫助提前確定一些維度信息,使得運行前能更多進行靜態改寫.對于機器學習,DAG 中的主要操作是矩陣運算,矩陣運算操作和順序可以基于啟發式規則優化,比如兩次矩陣轉秩不需要計算(XTT=X)、二元操作X+X可以改寫為一元操作2?X而避免兩次讀取X.矩陣乘法順序對計算量有較大影響,比如計算XT?Y?d,d為向量,如果按照(XT?Y)?d的順序,則會產生較大中間矩陣,時間復雜度是O(n3);如果按照XT?(Y?d)進行,則中間結果為向量,時間復雜度為O(n2).實際上,矩陣乘法順序優化與數據庫多表連接順序優化類似,都具有最優子結構和無后效性的特征,可以采用動態規劃方法求解最優乘法順序;與多表連接不同的是,矩陣乘法計算代價需要額外矩陣稀疏性等信息.
動態改寫[46]是在運行過程中進行,其原因是改寫依賴的維度等信息在運行時才能完全確定.一個典型的例子是DAG 中包含if-else 分支,if 分支和else 分支的輸出數據的維度可能不一樣,導致后續計算操作輸入數據的維度不能在運算前確定.在確定完整的維度后,可以繼續對一些運算順序進行改寫.比如對于(?XT)?y,如果向量y的維度小于X的行數,可以改寫為?(XT)?y以較小負號運算計算量.
6.2 物理計劃生成
機器學習的訓練環境通常包括異構硬件,如CPU、GPU、FPGA 以及計算集群等;邏輯改寫后的DAG 可以有多種物理計劃,需要結合計算的資源開銷和硬件環境生成最優物理計劃.數據庫領域通常采用基于代價估算的物理計劃生成,比如根據讀取數據規模的預估確定直接讀取原數據表或者讀取索引.機器學習DAG 的操作通常是密集型計算,運行代價估算需要重點考慮計算復雜度和內存要求兩方面的因素.
計算復雜度通常可以通過矩陣維度來預估,維度較小或者數據稀疏的矩陣運算,可以調度到CPU 中運算;維度較大的稠密矩陣運算,可以調度到GPU 并行計算;操作輸出矩陣的維度信息可以直接由輸入矩陣維度確定.基于計算復雜度預估調度也需要考慮操作融合的影響,比如可以將連續的運算融合成一個算子,調度到同一硬件上執行,避免數據在內存間頻繁拷貝,進而提升計算效率.
操作的內存需求也可以通過矩陣維度來估算[46].如果單機可以滿足操作內存需求,操作計算可以調度到單機CPU,GPU 上進行.對于內存超出單機限制的矩陣,可以使用多機分布式計算,比如采用分布式分塊乘法.矩陣運算的物理執行可以基于矩陣內存估算進一步細化,比如對于矩陣乘法X?Y,如果Y較大無法放入內存,但X較小可以放入內存,則計算過程可以讓X常駐內存,對Y進行一次外存掃描可以得出計算結果,這與數據庫兩表連接算法選擇有相似的地方.同時,確定操作內存需求和機器內存限制后,可以對運算順序進一步改寫.比如計算XT?y,如果向量y的維度小于X的行數,且y可以放入機器內存,計算順序可以改寫為(yT?X)T而避免對數據規模較大的X進行轉秩操作.
6.3 自動模型選擇
上述邏輯計劃改寫和物理計劃生成優化技術主要對單次訓練進行自動優化,避免人工參與.如前文所述,同一任務通常需要多輪訓練嘗試,過程中需要分析評測效果對特征、算法、超參數等進行調整優化訓練效果,迭代嘗試需要大量的人工分析工作.自動模型選擇在用戶不完整指定訓練依賴的情況下,自動搜索出特征、算法等之間的合理組合,訓練得到效果優化的模型.一方面可以減少多次嘗試的人工參與工作量,另一方面也給系統更大的優化空間.
模型選擇可以看作是特征選擇、算法選擇和超參數選擇三者之間的組合,稱為 MST(model selection triple)[48].對于設定的一組候選MST,系統可以自動選擇和訓練出任務效果最優的模型.與上文單次訓練優化技術不同的是,從候選MST 自動選擇最優模型可以基于面向候選集合的優化思路:一方面可以充分利用并行計算,將候選MST 調度到多卡或者多機上并行訓練;另一方面,候選模型之間通常具有較高的數據共享,可以通過復用來提升模型候選的整體執行效率.比如固定特征和算法,指定超參數的搜索條件,候選MST 之間的特征可以完全復用;如果對特征設置了枚舉條件,枚舉得到的特征集合之間并不完全獨立,采用前文所述的視圖技術存儲特征集合的公共表達,可以避免多任務重復計算特征.
對于深度學習,神經網絡模型進行端到端的特征抽取和建模,神經網絡架構搜索技術(NAS)[49?51]是自動模型選擇的重要方法.NAS 通常可以以人工設計的網絡作為搜索起點,將超參數、層數、連接方式等不同維度作為搜索空間,應用強化學習、進化算法、貝葉斯優化等搜索策略,根據效果評測的反饋來搜索新模型.深度神經網絡通常具有可復用子結構[52],可以通過將已訓練好的模型參數遷移到新模型來提升搜索效率.
6.4 小 結
自動優化是系統提升機器學習訓練效率的關鍵技術.當前,自動優化的研究主要針對單任務訓練,針對多任務整體訓練效率的自動優化技術有很大的探索空間.其中,探索模型中可復用子結構、建立任務間的語義關聯、自動識別相關任務模型,將是自動優化技術重要的研究方向.
7 系統實現
數據庫是多種數據管理技術的系統集成,本節從數據庫系統的視角討論對機器學習訓練任務的支持,探討數據管理技術對提升機器學習訓練效率的系統支持.由于數據庫和機器學習系統在數據模型、管理對象與優化目標上存在差異,基于數據庫已有的數據管理技術支撐機器學習訓練需要在數據庫功能復用和建模與訓練靈活性方面進行合理適配,比如對數據模型、存儲與存取功能、查詢優化技術采取不同的復用和適配策略.本節將討論3 種實現方式:與數據庫系統淺層融合、深層融合以及在數據庫系統之外獨立實現[53].
7.1 淺層融合
淺層融合背后的假設是機器學習算法和計算可以使用SQL 語言來表達,實際上,大部分機器學習算法都屬于線性代數運算,可以用矩陣間的計算來表達;如果將矩陣存儲為關系表,矩陣間運算就可以通過表連接操作來計算.如果訓練數據存儲在數據庫中,淺層融合方法可以在數據庫內部完成訓練而避免額外的數據移動,也可以復用數據庫的存儲和讀寫功能以及優化技術[54?58].本節將分兩方面介紹淺層融合的關鍵技術——各類矩陣運算的實現和主要機器學習算法的實現.
矩陣按行存儲為關系表,行下標與表的行號對應,每行的向量可以用數據庫支持的數組類型來存儲.為方便后續計算,同一矩陣可以按行或者列為順序分別存儲為一個表[54,55].基于這個格式,矩陣之間的加減法可以通過表之間的等值連接來計算;矩陣乘法A?B可以表達為以按行存儲的A矩陣表與按列存儲的B矩陣表之間的全連接,并計算連接向量的點積.對于稀疏矩陣,可以按照行下標、列下標、值的三元組形式存儲為關系表,乘法結果可以對相乘兩個表的行下標和列下標進行group by,再對列下標和行下標進行等值連接得到.對于更復雜的矩陣運算,比求矩陣求逆操作,如果數據可以放入內存,可以通過用戶自定義函數(user define function,簡稱UDF)來計算并擴充到SQL 中.如果矩陣的規模較大,可以將矩陣劃分為子矩陣存儲到不同關系表中,乘法先在分塊矩陣表中進行,之后進行聚合.
基于上述矩陣運算,機器學習算法可以分為一趟計算和多趟計算:一趟計算,如最小二乘法算法等,可以直接表達為矩陣運算的序列,因而使用多條SQL 語句就可以實現;多趟計算則針對需要迭代優化的機器學習算法,比如邏輯回歸、梯度下降、k-means 聚類算法等.多趟計算的主要挑戰是,如何使用SQL 表達迭代邏輯、存儲中間結果和判斷迭代終止.可以將迭代內的計算邏輯定義為一個視圖,將視圖與存儲遞增序列的虛表進行鏈接來表達迭代邏輯.更靈活的方式是將算法定義為一個UDF,迭代內的邏輯通過SQL 來實現,迭代生成的中間結果使用一個中間表進行存儲,外層通過腳本語言來控制結束條件.這種方式將中間數據存儲為關系表,其讀寫在數據庫引擎內進行,訪問效率較高;同時,通過將UDF 集成到SQL,不同的用戶也可以復用算法的實現.
7.2 深層融合
機器學習訓練和數據庫的數據模型分別是矩陣和關系表:矩陣適合表達多行多列的并行計算,而關系表更適合表達行和列級別的數據讀寫和計算.使用關系表存儲矩陣,會對后續計算帶來限制.深度融合的方式通過對數據庫內部數據存取和計算流程進行優化和適配,使得數據庫能夠對機器學習計算進行更原生的支持,進而提升模型構建和訓練效率[59?63].本節將從兩個方面介紹深度融合方法:一是對數據庫內部功能進行擴充和適配,二是基于數據庫底層功能構建機器學習系統.
SimSQL[59]提出將矩陣、向量作為數據庫的內置數據類型,同時內置矩陣乘法等計算的實現.這樣,矩陣可以作為元組的屬性,矩陣間的運算表達為元組屬性間的運算,使用SQL 編寫訓練代碼會大大簡化.內置數據類型還有兩點優勢:一是存儲的額外開銷較小,數據頁之內不再需要存儲行的位移、長度等信息;二是方便實現并行計算優化,比如矩陣作為屬性整體讀取到內存后,矩陣乘法可以整體通過Eigen[60]等CPU 并行計算庫實現.另一方面,內置數據類型可以將矩陣的統計信息直接暴露給數據庫查詢優化器,提升代價估算的準確度.比如:如果矩陣A的維度是[100,10000],矩陣B的維度是[10000,100],則A?B的維度是[100,100],數據規模較小;查詢優化器可以基于維度信息讓A與B的乘法盡早發生,使得中間數據的規模更小.
數據庫系統的設計實現了數據管理與應用獨立,具有邏輯獨立的數據存取層.通常來講,數據庫數據存儲層提供面向塊的數據讀寫操作,可以直接在數據存取層之上構建機器學習系統.這樣做有兩方面優勢:一是可以完全復用數據庫成熟的數據存儲和存取技術,比如數據壓縮、緩存管理等;二是直接進行塊讀寫的數據吞吐更大,數據訪問效率更高,與后續并行計算更好地匹配.DAnA[61]提供機器學習領域的描述性語言(DSL),直接使用數據庫塊對訓練數據進行存儲;將DSL 轉換為DAG 后,數據讀取會直接轉換為塊的讀取操作.DAnA 直接從數據庫的緩存管理器中復制整塊數據到并行計算硬件FPGA 的緩存中,之后利用FPGA 的多核能力對塊進行并行解析提取數據字段,避免了在數據庫內部將塊解析為元組時,額外的計算和數據拷貝過程.這種方式實現了存儲和計算在數據模型與硬件資源方面的解耦合,系統靈活性更高.
7.3 獨立實現
數據庫和機器學習除了數據模型不同,管理與優化的目標也有所不同:數據庫主要管理結構化數據,而機器學習是非結構化數據分析的重要手段.使用數據庫管理非結構化數據不夠靈活,且較難無縫集成到非結構化數據處理流程中.數據庫的優化重點是存取效率,機器學習的優化重點是計算效率,兩者依賴的具體優化技術存在差別.因此,借鑒數據庫系統的設計理念和實現經驗進行獨立的設計和實現,也是機器學習系統構建的重要方式[64?70].本節首先介紹獨立構建機器學習系統的典型工作,之后總結數據庫設計思想對于系統構建的參考價值.
SciDB[33]是獨立實現的機器學習系統.以多維數組作為數據模型,分chunk 連續存儲;支持面向數組的查詢語言(AQL),方便對數組中的數據進行訪問和計算表達,同時也兼容R 語言;計算效率方面,數據組間的運算可以在對齊chunk 劃分邊界后,直接在chunk 間進行;由于存儲和計算完全獨立實現,SciDB 在效率優化方面具有很高的靈活性.SystemML[64,65]在分布式計算系統MapReduce,Spark 的基礎上實現機器學習系統;數據模型為矩陣,使用HDFS 進行存儲,矩陣運算可以轉化Spark 計算任務;對外提供機器學習領域描述性語言(DSL),轉化為DGA后,通過自動優化技術轉化為物理計劃,并根據資源限制調度到單機或者Spark 集群上運行;由于使用Spark作為計算引擎,任務訓練可以無縫集成到Spark 整體數據處理流程中.Cumulon[66]的數據模型也為矩陣,以分塊形式存儲在HDFS 中,并對分塊矩陣運算自主調度,與使用MapReduce 進行矩陣計算相比效率更高;Cumulon 考慮了不同機型在內存資源和計算能力的差異,建立了使用不同機型在訓練成本和時長的預估模型,因而可以在滿足訓練時長的要求下,自動選擇和生成成本最低的物理計劃.
上述系統雖然獨立實現,但數據庫系統的設計理念和實現經驗對其有重要參考意義,總結為3 點.
1)面向領域問題的描述性語言:數據庫系統成功的一個重要因素是提供描述性語言SQL,支持方便的描述數據讀寫需求和較簡單的統計計算,而不必關系執行細節.SciDB 支持面向數組的查詢語言AQL,SystemML 和Cumulon 均支持機器學習領域的描述語言(DSL).描述性語言隱藏了訓練過程的細節,可以靈活而高效地構建機器學習模型;
2)分層設計獨立優化:數據庫的核心設計理念是保持語言處理層、查詢優化層、數據存取層、數據存儲層各層之間接口獨立,可以靈活組合并分別優化.SystemML 可以對相同的訓練任務選擇調度到單機或者Spark 集群,實現了語言處理層與計算存儲層的獨立,Spark 系統在計算效率方面的優化可以直接在SystemML 中生效;
3)自動優化技術:數據庫查詢優化技術對于任意的SQL 請求生成效率優化的執行計劃,是支撐數據庫廣泛應用的核心技術.對于機器學習而言,由于計算更加復雜,異構硬件類型更多,對自動優化技術依賴程度更高.SystemML 和Cumulon 均實現了自動優化技術,將DSL 編寫的訓練代碼自動轉化為高效執行的物理計劃,能夠系統地提升各類機器學習算法的訓練效率.
7.4 小 結
本節從與數據庫系統的關系視角對機器學習系統實現進行了分類歸納,前述數據管理技術在不同類別中具有不同應用方式.在數據庫基礎上,淺層或者深層融合的機器學習系統能夠較大程度復用數據庫已經提供的數據壓縮、視圖、緩存、索引以及自動查詢優化等技術,并根據需要對數據庫數據類型和查詢優化技術進行擴展.數據庫之外獨立實現的機器學習系統通常提供DSL 進行建模,需要獨立實現自動優化技術;數據存儲與存取技術可以獨立實現,也可以復用文件系統已有功能.由于機器學習技術仍在快速發展過程中,前文討論的數據選擇、多版本存儲、數據索引等技術尚未形成完整的系統集成方案,探索各類數據管理技術的統一系統集成方法是未來面臨的重要挑戰.
8 總結及展望
本文分別從數據和系統的視角對機器學習訓練過程進行解構,從數據管理、自動優化、系統設計與實現方面梳理了支撐機器學習的數據管理技術現狀.數據選擇、數據存儲和數據存取技術的優化思路從任務為中心逐漸轉化到數據為中心,通過多版本存儲、視圖、緩存等技術初步實現跨任務數據共享,但尚未形成統一的跨任務數據管理方案.自動優化技術目前主要采取任務為中心的做法,從為訓練過程自動優化效率逐漸發展到為訓練任務自動生成效果優化的訓練過程.自動模型選擇需要搜索大量的候選,效率仍面臨挑戰.機器學習系統需要集成數據管理、自動優化等技術,可以復用已有數據庫功能進行擴充與適配,也可以基于數據庫的設計思想獨立實現.總結而言,數據庫系統長期積累的數據管理技術已經廣泛應用到機器學習訓練的各個環節.隨著更多面向機器學習的工業級應用的出現,構建以數據為中心、支持跨任務數據復用和在線實時建模與訓練的新型數據庫系統,是提升機器學習效率、降低成本的重要途徑.未來的挑戰和研究方向包括:
1)數據庫內支持機器學習完整過程.
數據庫內支持機器學習能夠避免訓練數據在數據庫和機器學習系統間移動,也能夠復用數據完備的安全管理機制保護數據隱私.當前,數據庫內支持機器學習主要關注建模和訓練過程[54,55],對建模前數據處理和完成訓練后在線推理關注相對較少.對于數據處理,結構化和半結構化數據通常抽象為關系表或KV 表,適合采用SQL 進行轉換計算;非結構化數據尚未形成統一的數據模型,數據處理通常根據具體任務而采用不同的語言和模式;而模型構建通常采用多維矩陣作為通用數據表達,適合采用DSL 進行建模.因此,需要探索無縫連接數據處理和模型構建的更有效方式,形成統一融合的數據模型和描述性語言[71],降低數據在兩個階段的轉換成本.對于在線推理,其挑戰包括需要探索模型計算自動優化方式以提升推理效率[72]以及請求量動態變化時,基于異構硬件自適應調度計算以滿足推理延時要求[73]等.
2)跨任務數據與模型的管理與復用.
當前,機器學習數據與模型主要以任務為中心的方式管理,難以實現全局存儲與計算最優.未來,隨著機器學習的廣泛應用,將出現大量訓練目標和過程類似的任務,建立跨任務數據與模型關聯、實現任務間資源復用,是提升多任務整體訓練效率的重要途徑.這方面已經有初步研究[74,75],但仍面臨許多挑戰.
? 首先,需要探索通用的數據語義表示,形成跨任務數據表示基礎.非結構化數據的語義表達仍面臨挑戰,基于深度神經網絡非監督訓練得到的潛在語義向量表達是有希望的方向,需要進一步探索與結構化數據表達方式的融合;
? 其次,需要探索任務間模型的復用方法.由于機器學習模型,尤其是神經網絡模型尚缺乏可解釋性,模型復用仍面臨挑戰.預訓練是有希望的方向,通過海量非監督數據訓練得到能被多任務復用的公共模型,但仍是整體模型的復用,需要進一步探索模型子結構以實現更細粒度的復用;
? 同時,在多用戶、多任務協同的環境中,訓練數據、中間結果和模型的安全訪問機制,也是值得探索的方向.
3)支持在線自動模型構建與訓練.
自動模型構建與訓練將進一步減少機器學習過程的人工參與,提升效率.當前,自動模型構建與訓練主要考慮效果優化,對于效率與實時性方面考慮較少.支持在線自動模型構建與訓練要求在更低資源開銷下達到要求的訓練效果,面臨許多挑戰:首先,需要探索訓練數據、算法、超參數更高效的搜索與組合方法,更早過濾效果次優的訓練方案;其次,需要更準確地預估不同方案的訓練耗時,比如在訓練代價估算中同時考慮數據和模型的元數據信息以及考慮數據和模型復用帶來訓練耗時降低.同時,自動模型構建與訓練需要具備自學習特性,可以將人工建模的過程作為學習對象.隨著人工建模過程和效果評測數據的積累,學習其中潛在的建模和訓練優化策略,持續優化自動模型構建和訓練的效果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
