DFAN:一種基于深度反饋注意力網(wǎng)絡(luò)的圖像超分辨率方法
2021-05-24 09:01:14施舉鵬陸正嘉
小型微型計算機系統(tǒng) 2021年6期
施舉鵬,李 靜,陳 琰,陸正嘉
1(南京航空航天大學(xué) 計算機科學(xué)與技術(shù)學(xué)院,南京 211106)2(國網(wǎng)上海市電力公司信息通信公司,上海 200000)
E-mail:sjp.seasonsy@gmail.com
1 引 言
一直以來,圖像超分辨率(Super-Resolution,SR)被廣泛應(yīng)用于諸如醫(yī)學(xué)影像、人臉識別等對圖像質(zhì)量有較高需求的場景.同時在深度學(xué)習(xí)領(lǐng)域,作為底層的計算機視覺問題,超分辨率還可以通過產(chǎn)生高質(zhì)量圖像為其他高級視覺任務(wù)提供優(yōu)質(zhì)數(shù)據(jù)集來提升相應(yīng)模型性能.圖像超分辨率旨在實現(xiàn)低維圖像空間向高維圖像空間的映射,即低分辨率圖像(Low-Resolution,LR)向高分辨率圖像(High-Resolution,HR)的轉(zhuǎn)換.
傳統(tǒng)的圖像超分辨率方法主要是使用插值算法[1]對需要填補的像素值進行計算,該類方法簡單高效,可應(yīng)用于實時快速的圖像上采樣,但因其過于依賴人為定義的映射關(guān)系以及先驗假設(shè),導(dǎo)致基于插值算法的圖像重建質(zhì)量往往難以保證.為了解決傳統(tǒng)插值方法的問題,基于機器學(xué)習(xí)的超分辨率方法[2-4]逐漸發(fā)展起來,該類方法主要通過在大量帶標(biāo)注的圖像數(shù)據(jù)集中通過一定的算法學(xué)習(xí)低分辨率到高分辨率的映射來擬合LR-HR映射關(guān)系.2014年,Dong[5]等人首次將深度學(xué)習(xí)方法應(yīng)用到超分辨率領(lǐng)域,作為超分辨率在深度領(lǐng)域的開山之作,作者提出了一種使用3層卷積神經(jīng)網(wǎng)絡(luò)的方法,實現(xiàn)了優(yōu)于傳統(tǒng)方法的圖像超分辨率重建效果,后來的深度學(xué)習(xí)模型基本上延用了該模型的基本結(jié)構(gòu),即由特征提取和圖像重建兩部分組成.為了改進SRCNN[5]中仍然基于插值的圖像重建方式,Zeiler[6]和Shi[7]相繼提出了基于反卷積和亞像素卷積的上采樣方法,將圖像重建部分的參數(shù)也納入到模型訓(xùn)練的過程中.
隨著深度學(xué)習(xí)模型的不斷發(fā)展,超分辨率領(lǐng)域也提出了許多新的網(wǎng)絡(luò)模型.SRResnet[8]引入了殘差結(jié)構(gòu),通過在線性網(wǎng)絡(luò)的基礎(chǔ)上添加跳躍連接來緩解梯度信息在多層傳播過程中的損失.得益于此,超分辨率網(wǎng)絡(luò)可以設(shè)計得更深,這大大增強了模型的學(xué)習(xí)與表征能力.為了更好地利用深度卷積網(wǎng)絡(luò)各層的梯度信息,MemNet[9]引入了稠密連接的結(jié)構(gòu).RDN[10]結(jié)合了殘差與稠密連接結(jié)構(gòu)的優(yōu)點,提出了殘差稠密塊,進一步提升了圖像超分辨率的質(zhì)量.
盡管許多深度學(xué)習(xí)模型取得了較好的重建效果,但是較深的網(wǎng)絡(luò)也帶來了諸如過擬合以及收斂速度較慢等問題,這類問題屬于深度神經(jīng)網(wǎng)絡(luò)的通病,許多質(zhì)量較高的超分辨率結(jié)果大多依賴于網(wǎng)絡(luò)的反復(fù)調(diào)參嘗試,最終的模型在實際應(yīng)用場景中難以復(fù)現(xiàn).因此,許多網(wǎng)絡(luò)模型設(shè)計的重點開始從增加網(wǎng)絡(luò)的深度轉(zhuǎn)移到低分辨率圖像到高分辨率圖像(LR-HR)映射的學(xué)習(xí)上.為了更準(zhǔn)確地學(xué)習(xí)LR-HR映射,RED[11]提出了卷積-反卷積的對稱結(jié)構(gòu),DBPN[12]引入了反射單元,這些結(jié)構(gòu)已被證明能夠使模型更好地學(xué)習(xí)LR-HR重構(gòu)映射,從而獲得更好的重建效果.同時伴隨著模型的參數(shù)量不斷增加,為了降低模型計算上的負擔(dān),DRCN[13]與DRRN[14]引入了遞歸結(jié)構(gòu).通過共享一些層的參數(shù)來控制模型的規(guī)模.為了實現(xiàn)特征信息的前饋及反饋傳播,SRFBN[15]引入了反饋連接結(jié)構(gòu),實現(xiàn)了參數(shù)的充分復(fù)用.遞歸和反饋結(jié)構(gòu)確實對模型參數(shù)的利用產(chǎn)生了好的影響,但由于這類結(jié)構(gòu)都是通過在訓(xùn)練過程中以循環(huán)迭代的形式傳遞特征信息,冗余的特征信息以及一些噪聲可能會在迭代中產(chǎn)生疊加效應(yīng),并影響到網(wǎng)絡(luò)的收斂以及最終效果.
為了抑制基于反饋結(jié)構(gòu)的超分辨率網(wǎng)絡(luò)中由于深度迭代產(chǎn)生的副作用,本文提出了一種基于深度反饋注意力的超分辨率網(wǎng)絡(luò)(DFAN),該網(wǎng)絡(luò)可以有效抑制冗余信息在反饋迭代中的疊加,提高參數(shù)共享及特征傳播的質(zhì)量,同時提升模型的收斂速度.DFAN中基本的反饋模塊由上采樣和下采樣層交替組成,模型中利用通道注意力機制學(xué)習(xí)圖像特征的權(quán)重,將注意力學(xué)習(xí)到的權(quán)重,通過反饋結(jié)構(gòu)共享到每一輪迭代當(dāng)中,進而形成基于迭代的殘差注意力,實現(xiàn)對冗余特征的過濾機制.不同于其他基于迭代的超分辨率網(wǎng)絡(luò),本文方法的深度反饋注意力實現(xiàn)了一種面向迭代過程的特征過濾機制,從而在迭代過程中使模型有效區(qū)分有效信息和冗余信息,增強對有效信息的學(xué)習(xí)并抑制冗余信息的進一步傳播.
本文的主要貢獻包括:
1)提出了一種基于反饋機制的迭代反饋注意力超分辨率網(wǎng)絡(luò),實現(xiàn)了參數(shù)復(fù)用以及冗余特征過濾機制,與同類超分辨率模型相比,該模型具有更少的參數(shù)量以及更快的執(zhí)行速度,同時也能獲得較高質(zhì)量的超分辨率重建水平.
2)提出了一種新的迭代反饋注意力結(jié)構(gòu),引入了注意力機制,在特征的反饋傳播中學(xué)習(xí)注意力權(quán)重以實現(xiàn)通道層次的過濾,提高了模型學(xué)習(xí)的效率,同時該結(jié)構(gòu)可以應(yīng)用到任何基于反饋結(jié)構(gòu)的模型中.
3)本文提出的模型在公開標(biāo)準(zhǔn)數(shù)據(jù)集上取得了優(yōu)于大部分同類方法的重建效果,在單張?zhí)幚頃r間秒級以內(nèi)的情況下達到了最高38db以上的峰值信噪比.同時在實驗中分析了迭代反饋注意力結(jié)構(gòu)對于網(wǎng)絡(luò)訓(xùn)練速度及收斂過程的影響.
本文后續(xù)章節(jié)安排如下:第2節(jié)主要介紹了基于深度學(xué)習(xí)的超分辨率模型的相關(guān)工作;第3節(jié)介紹本文提出的基于深度反饋注意力的超分辨率網(wǎng)絡(luò)DFAN;第4節(jié)通過DFAN模型的參數(shù)對比實驗以及與同類方法的超分辨率重建對比實驗來驗證本文方法的有效性;第5節(jié)對本文方法進行總結(jié),并探討進一步的研究方向.
2 相關(guān)工作
自SRCNN[5]超分辨模型開始,卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)被廣泛地應(yīng)用于圖像超分辨率領(lǐng)域,本文的DFAN模型主要是基于卷積神經(jīng)網(wǎng)絡(luò)中的注意力機制與反饋機制實現(xiàn)的,因此本部分將介紹與這部分內(nèi)容相關(guān)的國內(nèi)外相關(guān)工作.
2.1 基于卷積神經(jīng)網(wǎng)絡(luò)的超分辨率
最早將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用于SR問題的是SRCNN[5],作者提出了3層的卷積神經(jīng)網(wǎng)絡(luò),取得了優(yōu)于傳統(tǒng)方法的效果.隨后,更深更復(fù)雜的網(wǎng)絡(luò)開始出現(xiàn),VDSR[17]提出了一種基于20層卷積神經(jīng)網(wǎng)絡(luò)的超分辨率模型.實踐表明,越深的網(wǎng)絡(luò)表達能力越強,也越易于出現(xiàn)過擬合和梯度爆炸等問題.為了解決這些問題,SRResNet[8]和MemNet[9]分別引入了殘差結(jié)構(gòu)以及稠密結(jié)構(gòu),相較于線性網(wǎng)絡(luò),這些結(jié)構(gòu)通過跳躍連接可以更好地傳播梯度信息.RDN[10]同時結(jié)合了上述兩種結(jié)構(gòu)的優(yōu)勢,并引入了Residual in Residual結(jié)構(gòu),進一步提升了重建質(zhì)量.隨著網(wǎng)絡(luò)結(jié)構(gòu)的進一步加深,超分辨率重建的效果逐漸趨于飽和,而網(wǎng)絡(luò)參數(shù)的規(guī)模以及計算消耗越來越大,基于基本卷積塊疊加的卷積神經(jīng)網(wǎng)絡(luò)在超分辨率的效率上很難進一步提升.
2.2 基于反饋網(wǎng)絡(luò)的超分辨率
為了解決參數(shù)規(guī)模日益龐大以及卷積層的大量堆疊導(dǎo)致的網(wǎng)絡(luò)難以訓(xùn)練的問題,受到RNN[16]的啟發(fā),DRCN[13]首次在超分辨率領(lǐng)域引入了遞歸結(jié)構(gòu).該方法在訓(xùn)練過程中,將某些卷積層的參數(shù)進行遞歸復(fù)用,將每一個卷積層的參數(shù)合并到后面的參數(shù)中一起訓(xùn)練,從而可在較少參數(shù)量的情況下取得較好的重建效果.DRRN[14]結(jié)合了殘差結(jié)構(gòu)將遞歸網(wǎng)絡(luò)模型的深度進一步加深.雖然遞歸結(jié)構(gòu)可以在不增加過多參數(shù)的情況下增加網(wǎng)絡(luò)深度,但是并沒有改變特征信息的前饋傳播方式,導(dǎo)致參數(shù)仍是單向共享的.為此,SRFBN[15]引入了反饋機制,基于反饋連接的形式復(fù)用參數(shù),將每輪迭代的特征并入下一輪迭代的特征輸入中,實現(xiàn)了特征信息的反饋傳播,并取得了更好的重建效果.遞歸結(jié)構(gòu)與反饋結(jié)構(gòu)形式的不同如圖1所示.

圖1 DRCN [13](a)的遞歸結(jié)構(gòu)以及SRFBN [15](b)的反饋結(jié)構(gòu)的迭代展開形式Fig.1 Expanded form of the recurrent structure of DRCN [13](a)and the feedback structure of SRFBN [15](b)
2.3 基于注意力的超分辨率模型
注意力在人眼視覺機制上起著至關(guān)重要的作用[18],在深度學(xué)習(xí)領(lǐng)域,視覺注意力也被廣泛引用于諸如圖像分割,圖像識別等高級計算機視覺任務(wù)中.注意力機制主要用過在特征提取的過程中,引入響應(yīng)特征強度的權(quán)重矩陣來實現(xiàn)對重要特征的增強.基于空間域、通道域以及混合域等的注意力模型被用來解決不同的計算機視覺問題.在圖像超分辨率領(lǐng)域,RCAN[19]首次引入了通道注意力,對網(wǎng)絡(luò)學(xué)習(xí)的特征信息進行篩選,在添加極少量參數(shù)的條件下,提升了超分辨率重建效果.
為了解決反饋網(wǎng)絡(luò)中冗余特征信息的傳播,實現(xiàn)特征選擇,本文方法在基于反饋連接的圖像超分辨率網(wǎng)絡(luò)中引入了通道注意力模型,同時借鑒了SE-Net[20]中的方法,以全局平均池化代替了注意力模型中的全連接層以進一步減少參數(shù)量,還參考了RAN[21]中的殘差注意力結(jié)構(gòu),并結(jié)合反饋模型,提出了迭代反饋注意力結(jié)構(gòu),以實現(xiàn)循環(huán)過程中對于特征信息的迭代過濾.具體的模型結(jié)構(gòu)與機制將在下面的章節(jié)中介紹.
3 基于深度反饋注意力網(wǎng)絡(luò)的圖像超分辨率方法
本文結(jié)合了反饋結(jié)構(gòu)與注意力機制,提出了基于深度反饋注意力的圖像超分辨率模型.如圖2所示.在DFAN模型中,核心部分包括參數(shù)的循環(huán)迭代以及殘差注意力.循環(huán)迭代機制通過反饋連接形成的反向傳遞實現(xiàn),其確保了特征信息在迭代過程中的充分利用.注意力模塊通過學(xué)習(xí)對應(yīng)的權(quán)重來對每輪迭代的特征通道進行過濾,并在迭代中不斷對SR特征進行微調(diào).由于注意力模塊本身對于特征信息的傳遞存在抑制作用,為了減少這種對特征的削弱,本文借鑒了RAN[21]中引入殘差的方法來實現(xiàn)注意力模板,通過與上一輪迭代的權(quán)重模板相關(guān)聯(lián),每一輪迭代的注意力模板都學(xué)習(xí)一個基于迭代的更深一層的殘差信息,利用這種迭代,不斷細化圖像的特征.這兩種機制的結(jié)合確保了參數(shù)共享,也使得模型更加精準(zhǔn)地學(xué)習(xí)LR-HR映射.
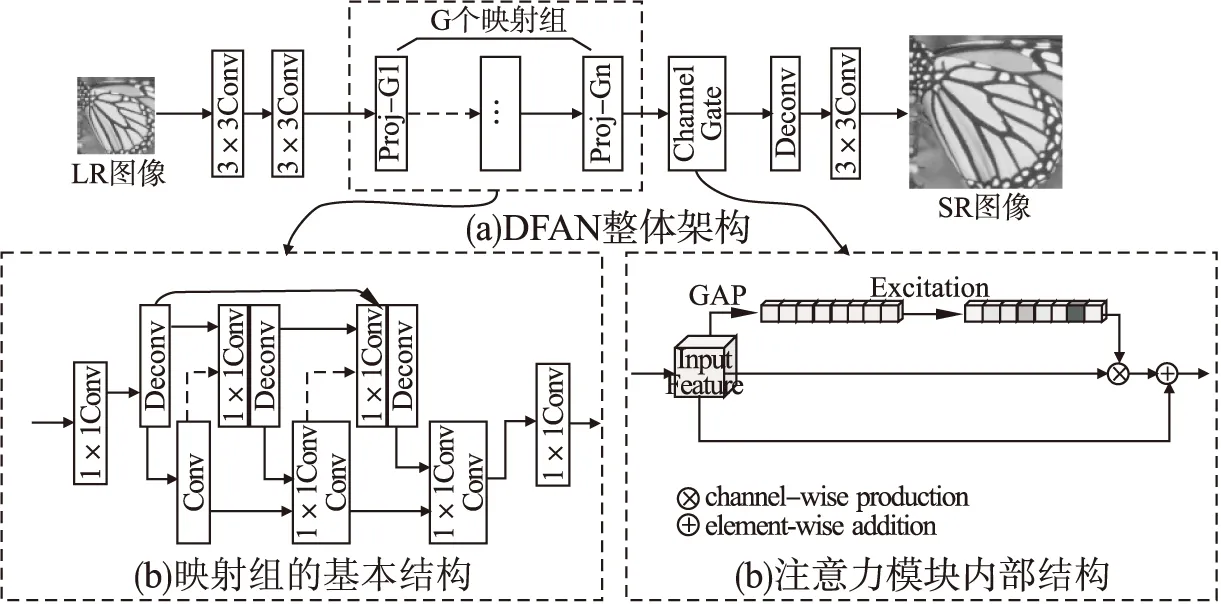
圖2 基于深度反饋注意力的超分辨率網(wǎng)絡(luò)模型框架圖Fig.2 Overall framework of deep feedback attention network for image super-resolution
3.1 網(wǎng)絡(luò)基本結(jié)構(gòu)
圖2所示為DFAN的靜態(tài)結(jié)構(gòu),在實際訓(xùn)練過程中,模型的動態(tài)迭代結(jié)構(gòu)如圖3所示,單幅圖像的訓(xùn)練可被展開為T輪迭代,迭代的序號由1-T表示.圖中下面部分的實線表示特征的反饋復(fù)用,上面部分的虛線表示每輪學(xué)習(xí)的注意力被疊加至下一次循環(huán)以形成迭代殘差學(xué)習(xí).每輪迭代中模型會合并當(dāng)前輸入與之前迭代輸出的所有特征,共同作為當(dāng)前的輸入特征,以實現(xiàn)參數(shù)復(fù)用及特征共享.模型的基本組成模塊主要包含由卷積層和反卷積層構(gòu)成的反饋塊和一個通道注意力門.

圖3 深度反饋注意力結(jié)構(gòu)的展開形式Fig.3 Expanded form of deep feedback attention structure
令Conv(f,n)和Deconv(f,n)分別表示具有n個大小為f*f的卷積核的卷積層和反卷積層,令I(lǐng)LR為低分辨率圖像,經(jīng)過特征提取后輸入到注意力模塊中的輸入可表示為:
(1)
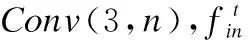
(2)
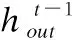
最終每一次迭代的注意力反饋模塊的輸出由重建模塊進行重建,本文采用一個反卷積層Deconv(k,n)對輸出的特征進行上采樣,然后再用一個卷積層Conv(3,c)生成最終的SR殘差圖像.SR殘差圖像和原圖像的上采樣共同生成最終的SR結(jié)果.最終SR結(jié)果可以表示為:
(3)
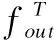
3.2 深度反饋注意力模塊
3.1中介紹了從LR產(chǎn)生SR圖像的整個線性過程,本部分將介紹在卷積-反卷積映射組以及注意力門中的具體迭代過程.
基于深度反饋注意力的映射模塊主要由卷積塊、反卷積塊以及注意力門組成,卷積塊和反卷積塊的疊加可以實現(xiàn)特征重構(gòu)并不斷迭代,在反復(fù)的上下采樣中計算累計的重構(gòu)誤差.這種迭代方式與DBPN[12]中的上反射與下反射單元的堆疊有略微不同,通過直接連接的卷積-反卷積層形成交錯稠密連接的結(jié)構(gòu),這種連接方式可以實現(xiàn)特征的反復(fù)重構(gòu)從而在約束淺層特征的同時保證梯度信息的有效傳播.
(4)
接下來輸入特征將由多個卷積塊和反卷積塊組成的級聯(lián)組進行迭代重構(gòu),同時每一個組的輸出都會與之前所有組的輸出進行合并,在自反饋模塊中,第t輪迭代第n個組的輸入可以表示為:
(5)
其中fproj↑↓表示由卷積和反卷積層構(gòu)成的一個反射組,該式表明了在迭代過程中,每一輪迭代的輸入特征都是由當(dāng)前輸入特征與之前迭代過程產(chǎn)生的所有特征合并而來.輸出特征接下來會通過注意力單元進行特征過濾,本文采用的通道注意力單元包含3個過程:擠壓、激勵以及放縮.
1)擠壓函數(shù)
傳統(tǒng)的注意力機制將特征全部展開并通過全連接層學(xué)習(xí)一個激勵權(quán)重,本文借鑒了SE-Net[20]中的方式,通過計算每一個通道特征的全局平均值來代表整個特征圖的特征值從而大大縮減后續(xù)權(quán)重矩陣所需的參數(shù)數(shù)量,基于全局平均池化的擠壓環(huán)節(jié)可以表示為:
(6)
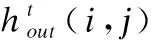
2)激勵函數(shù)
激勵函數(shù)通過學(xué)習(xí)特征值張量對應(yīng)位置的權(quán)重來對各個通道的特征進行增強或抑制,該部分由兩個帶激活函數(shù)的全連層組成,激勵環(huán)節(jié)可以表示為:
mt=σ(w2δ(w1×gt))
(7)
其中w1和w2分別為兩個一維權(quán)重,δ表示ReLU函數(shù),σ表示Sigmoid函數(shù),最終激勵函數(shù)給出一個維數(shù)與輸入特征通道數(shù)相同的一個權(quán)重矩陣.激勵函數(shù)是注意力機制里最核心的部分,通過學(xué)習(xí)的權(quán)重,可以對特征信息中對梯度響應(yīng)較強的特征予以加強,同時對梯度響應(yīng)較弱的無效特征予以抑制,從而增加模型學(xué)習(xí)到特征的準(zhǔn)確性.
3)尺度函數(shù)
尺度函數(shù)利用上面過程學(xué)習(xí)到的通道注意里權(quán)重矩陣對原輸入特征各個通道進行放縮,從而增強有效特征,抑制無用特征,放縮環(huán)節(jié)可以表示為:
(8)
如公式(8)所示,mt-1表示上一輪迭代學(xué)習(xí)的權(quán)重模板,×表示矩陣中各元素一一對應(yīng)相乘,因此公式左邊的部分表示上一輪迭代學(xué)習(xí)到的HR特征表示,mt表示該輪迭代學(xué)習(xí)的權(quán)重模板,其實際上學(xué)習(xí)的是與上一輪學(xué)習(xí)到的特征表示相對應(yīng)的殘差信息.該環(huán)節(jié)將本次迭代的注意力權(quán)重信息與上一輪迭代的權(quán)重相關(guān)聯(lián),從而構(gòu)造迭代形式的殘差注意力,具體而言,基于反饋與注意力機制提出了如下的結(jié)構(gòu).
第1輪迭代中注意力單元學(xué)習(xí)LR-HR的殘差注意力權(quán)重,在后面的每一輪迭代中,注意力權(quán)重產(chǎn)生的特征圖都會與上一輪迭代輸出的特征進行疊加,結(jié)合上一輪的權(quán)重信息共同組成本輪迭代的輸出.因此每一輪迭代模型學(xué)習(xí)到的注意力隨著訓(xùn)練過程也在不斷迭代加深.
4 實驗與分析
4.1 數(shù)據(jù)集介紹
本文實驗性能分析中主要使用DIV2K作為訓(xùn)練集,該數(shù)據(jù)集是NTRIE和PIRM競賽采用的基準(zhǔn)數(shù)據(jù)集,其中包含了900張2K分辨率的高質(zhì)量png圖片.在數(shù)據(jù)預(yù)處理上使用了和EDRN[22]相同的辦法.采用PSNR和SSIM作為SR結(jié)果的評估指標(biāo).基準(zhǔn)的測試集主要包括Set5[23],Set14[24],B100[25],Urban100[26]和Manga109[27].
為了和其他SR模型進行比較,本文和大多數(shù)方法一樣選擇雙3次插值的方法來從HR圖像中下采樣得到LR圖像,得到的LR圖像與原HR圖像共同構(gòu)成了模型訓(xùn)練的標(biāo)注數(shù)據(jù)集.為了適配卷積層的計算,輸入圖像在訓(xùn)練中均被切分成多個圖像塊(patch),塊大小根據(jù)放大倍率設(shè)置為不同的數(shù)值,具體如表1所示.

表1 輸入patch大小的設(shè)置Table 1 Settings of input patch size
本文訓(xùn)練模型時采用16的批處理大小(batch size),網(wǎng)絡(luò)參數(shù)的初始化方法與[28]相同,選擇Adam[29]作為訓(xùn)練優(yōu)化的算法,初始的學(xué)習(xí)率設(shè)置為0.0001,并且每隔200個epochs衰減一半.本文提出的DFAN基于Pytorch框架實現(xiàn),并且在NVIDIA1080Ti GPU上進行訓(xùn)練.
4.2 評價標(biāo)準(zhǔn)和參數(shù)設(shè)置
對于圖像超分辨率的重建結(jié)果質(zhì)量評價,常用的指標(biāo)主要是峰值信噪比(Peak Signal to Noise Ratio,PSNR)和結(jié)構(gòu)相似性(Structural Similarity,SSIM).
1)峰值信噪比
該指標(biāo)主要從信號的角度衡量圖片之間的相似程度,其定義如下:
(9)
其中MSE為圖像之間的均方誤差,n為像素值的位深,在本文的數(shù)據(jù)集中,n的取值為8,即像素值的最大值為28-1=255.PSNR的取值越大,證明兩幅圖像越相似,一般當(dāng)PSNR取值大于38時,人眼便不容易分辨圖像之間的差異.
2)結(jié)構(gòu)相似性
結(jié)構(gòu)相似性從圖像組成的角度將結(jié)構(gòu)信息定義為獨立于亮度、對比度的,反映場景中物體結(jié)構(gòu)的屬性,并將失真建模為亮度、對比度和結(jié)構(gòu)3個不同因素的組合,從而估計兩個圖像之間的相似程度.其定義如下:
(10)

SSIM的取值范圍為0-1,當(dāng)兩幅圖像完全一樣時,SSIM的值為1.
本文的模型采用了基于距離的損失來進行優(yōu)化.損失函數(shù)可表示為:
(11)
其中T表示迭代的輪數(shù),Wt表示每輪迭代的輸出權(quán)重矩陣.由于PSNR與MSE為負相關(guān)關(guān)系,許多模型依照MSE損失來進行優(yōu)化,但以均方損失為基礎(chǔ)的優(yōu)化會導(dǎo)致結(jié)果在像素值上出現(xiàn)均值化的效應(yīng).同時,由于DFAN學(xué)習(xí)了很多深層殘差信息,因此本文選擇使用L1損失在規(guī)避均值化效應(yīng)的同時,對參數(shù)施加一定的稀疏約束從而防止一定的過擬合.
除最后一層采用tanh激活函數(shù)以外,所有卷積層和反卷積層內(nèi)都使用了PReLu[28]作為激活函數(shù),本文按照[12]中的方法對應(yīng)不同的倍率設(shè)置了不同的卷積核大小,步長以及填充量.具體的設(shè)置見表2.最后一輪迭代的輸出將作為最終的超分辨率重建結(jié)果.

表2 卷積層參數(shù)設(shè)置Table 2 Settings of convolution layers
4.3 注意力模型消融實驗
為了分析引入注意力模型帶來的實際影響,本文對注意力模型在不同的結(jié)構(gòu)下的超分辨率效果進行了比較.實驗使用的模型包括4次迭代和3個卷積組,訓(xùn)練了200個epochs.結(jié)果如表3所示.

表3 不同的注意力結(jié)構(gòu)的效果對比Table 3 Comparison with different organization of attention structure
DFAN-A表示不帶有注意力的模型,DFAN-B表示引入了通道注意力但沒有實現(xiàn)迭代殘差結(jié)構(gòu)的模型,DFAN代表引入了迭代殘差注意力結(jié)構(gòu)的模型.實驗表明,單純的引入注意力盡管略微提升了一點效果,但是網(wǎng)絡(luò)的收斂速度受到了一定程度的影響.這種影響可能是由于多次迭代過程中注意力對特征的抑制作用的疊加效應(yīng),另一方面,在同時引入了結(jié)合反饋連接與注意力的結(jié)構(gòu)后,網(wǎng)絡(luò)的性能得到了進一步提升,這說明了注意力與反饋機制的結(jié)合可以削弱深層注意力帶來的副作用,并強化反饋機制的作用.
我們還比較了引入深度反饋注意力機制的DFAN與其他主流模型之間的參數(shù)量和運行時間對比,如表4所示.所有的數(shù)據(jù)基于Urban100數(shù)據(jù)集上的4倍重建任務(wù),結(jié)果表明相較于其他模型,DFAN能夠在保持較小的參數(shù)量的情況下,達到較高的重建水平.
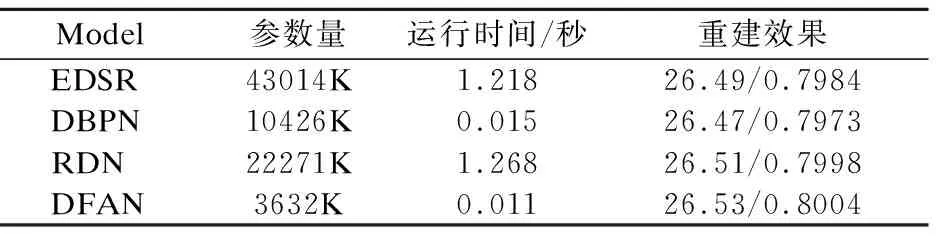
表4 模型規(guī)模與運行效率對比Table 4 Comparison of model size and execution time from different model
4.4 迭代次數(shù)對比實驗
在DFAN中,模型在多輪反饋迭代后,通過迭代殘差注意力不斷學(xué)習(xí)更層次的注意力信息及圖像特征,同時對網(wǎng)絡(luò)參數(shù)不斷地進行微調(diào),并向最優(yōu)解逼近.在迭代次數(shù)增加的同時,DFAN模型中的深度反饋注意力結(jié)構(gòu)不僅僅加深了反饋傳播的深度,同時也增加了注意力權(quán)重的準(zhǔn)確程度.為了研究模型的參數(shù)學(xué)習(xí)與迭代次數(shù)的關(guān)系,通過比較迭代次數(shù)T的變化對重建效果的影響來分析反饋結(jié)構(gòu)下的注意力級別對于模型重建精度的影響.

圖4 關(guān)于T的模型損失與重建指標(biāo)分析Fig.4 Loss and PSNR/SSIM results analysis of different T
如圖4所示,當(dāng)T從2增加至4時,訓(xùn)練損失擴大了,但是驗證集上的損失反而下降了一些,這意味著增加一定的迭代深度可以有效抑制深層網(wǎng)絡(luò)的過擬合情況,并提升一定的網(wǎng)絡(luò)收斂速度.注意到T=3與T=4相比,訓(xùn)練集上的損失不斷增大,但是重建效果相當(dāng)接近.這是由于迭代層次進一步加深時,每輪迭代學(xué)習(xí)的是不斷遞進的殘差信息,因此越往后的迭代學(xué)習(xí)到的參數(shù)會越稀疏.如表5所示的重建結(jié)果也印證了這一點.這表明過深的迭代次數(shù)可能會導(dǎo)致迭代殘差注意力的學(xué)習(xí)陷入局部最優(yōu)解.根據(jù)實驗結(jié)果,最終認為T的取值應(yīng)當(dāng)在4上下浮動,最多不超過6,否則反饋連接帶來的效果提升將會飽和.

表5 迭代次數(shù)的分析Table 5 Investigation of T
4.5 超分辨率效果對比
本文在5個基準(zhǔn)數(shù)據(jù)集上用多個其他超分辨率方法與本文方法進行了對比實驗.實驗中圖像特征的通道數(shù)都設(shè)置為64,DFAN中的迭代次數(shù)設(shè)置為4,參與比較的方法包括Bicubic,SRCNN[5],VDSR[17],LapSRN[30],DRRN[14],MemNet[9],EDSR[22],SRFBN[15]和DFAN.結(jié)果分別包括了放大倍率取{2,3,4}的情況,結(jié)果見表6.由于LapSRN不支持3倍的圖像超分辨率,因此結(jié)果中省略了相應(yīng)內(nèi)容.更直觀的視覺重建效果展示圖5可知本文提出的模型能達到更好的重建效果,在細節(jié)上有更高的重建質(zhì)量.

表6 ×2/×3/×4倍率下的超分辨率重建結(jié)果(PSNR/SSIM)Table 6 Average PSNR/SSIM for scale factor ×2/×3/×4 with bicubic interpolation degradation
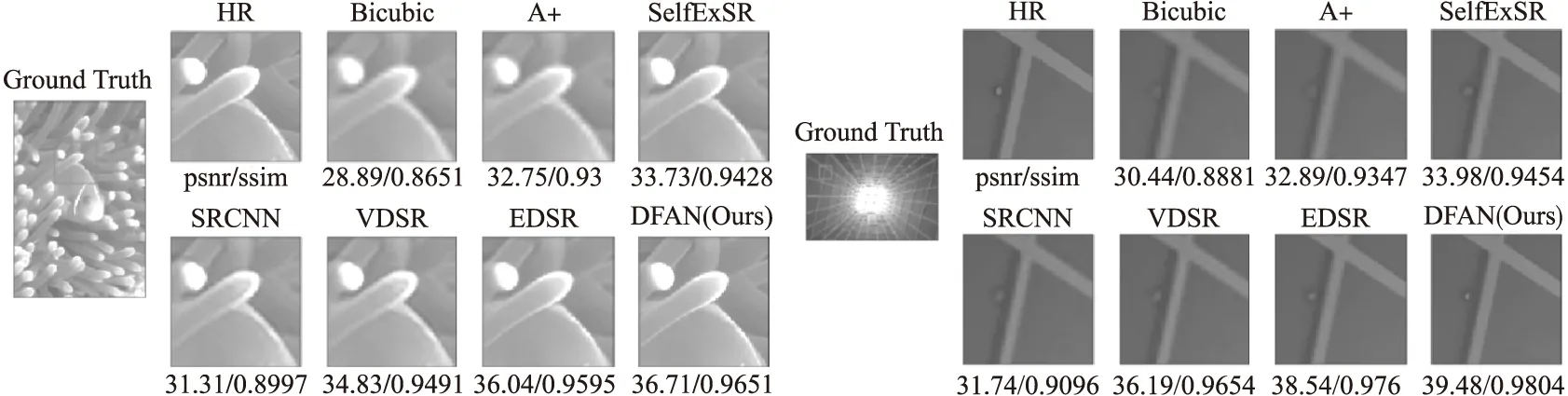

圖5 不同模型在4倍放大下的重建視覺效果對比Fig.5 Visual results of super resolution by different model
5 結(jié) 論
本文提出了一種新的基于深度反饋注意力的圖像超分辨率網(wǎng)絡(luò)(Deep Feedback Attention Network,DFAN),該模型通過在反饋機制中形成迭代的殘差注意以抑制冗余信息的傳播,提高了特征學(xué)習(xí)的效率,并能夠生成高質(zhì)量的超分辨率圖像.該方法通過反饋連接帶來的參數(shù)復(fù)用縮減了模型的參數(shù)量,利用通道注意力建立了對特征學(xué)習(xí)的篩選機制,并在迭代中不斷提升特征映射的準(zhǔn)確度.實驗部分驗證了深度反饋注意力結(jié)構(gòu)的引入確實改善了超分辨率網(wǎng)絡(luò)的特征映射學(xué)習(xí)能力,減輕了過擬合以及收斂慢等問題,本文提出的方法優(yōu)于當(dāng)前同類型的圖像超分辨率方法.下面的研究重點將在反饋注意力的基礎(chǔ)上,結(jié)合人眼視覺的機制,進一步分析注意力機制在卷積神經(jīng)網(wǎng)絡(luò)中的作用,并研究新的注意力結(jié)構(gòu)以實現(xiàn)更好的模型性能.
猜你喜歡
哲學(xué)評論(2021年2期)2021-08-22 01:53:34
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
