基于改進關節點聯系的ST-GCN行為識別辦法
2021-05-25 08:07:14李圣京李樹斌
通信電源技術 2021年24期
李圣京,李樹斌
(廣州海格通信集團股份有限公司 無人系統技術創新中心,廣東 廣州 510700)
0 引 言
隨著深度學習技術的發展以及硬件設備性能的提升,針對視頻識別的研究越受重視[1]。與目標檢測等任務不同,視頻識別任務不僅需要處理每一幀的特征信息,還需要處理時序上的特征信息,計算量也會更大。
人體行為識別是視頻識別的一個重要任務,主要是從視頻或圖像序列中分析出人體正在進行或即將進行的行為動作,在監控安防、人機交互、體育運動等領域有重要的實用性。利用人體行為識別技術對目標自動識別,對監控區域進行全區域、全天時的實時感知,及時預警,可極大地降低安防成本,減少人工監控可能出現的疲勞、誤報、漏報等問題。
1 現狀分析
基于人體骨骼關節點的行為識別對光照和場景有很好的魯棒性,并且在計算量和存儲空間上都有很大的優勢。人體姿態信息可以通過姿態估計算法或穿戴傳感設備例如Kinect獲取。時空卷積神經網絡(Spatial-Temporal Graph Convolution Networks,STGCN)開創了使用圖卷積神經網絡處理姿態估計信息并其識別的精度超過了之前的大多數算法[2]。STGCN通過圖卷積對同一幀的關節點位置信息特征提取,通過時空卷積對同一關節連續幀提取關節的運動信息。相比于傳統的骨架建模,ST-GCN具有更好的擬合能力和泛化能力。圖1所示為在姿態估計關節點的基礎上建立的單人的ST-GCN連接示意圖。
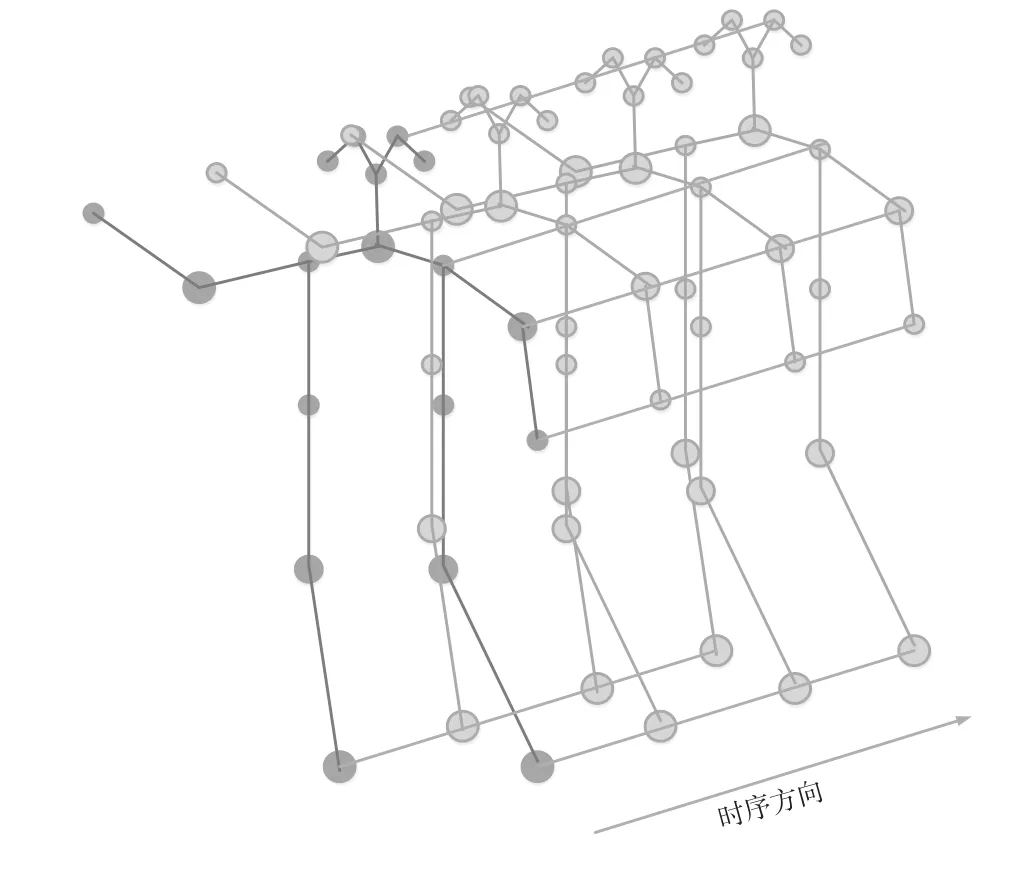
圖1 ST-GCN的連接示意圖
但是,ST-GCN網絡只關注物理連接近的關鍵點,也未考慮物理連接遠的關節點的影響。針對上述的問題,本文借鑒了ST-GCN的思想,創新性提出以下3種辦法,進一步提升了人體行為識別任務的準確率:(1)通過對特征圖轉置,關節點放置到通道的維度,利用3層卷積聚集關節點的全局信息,提升行為識別的準確率;(2)提出新的注意力結構,通過學習的方式獲取兩個節點聯系的強弱;(3)提出使用不平衡多網絡集成學習分支在線監督蒸餾行為識別算法,提高模型的精度。
2 算法設計
2.1 時空圖卷積模型
ST-GCN是基于圖卷積神經網絡(GCN)同時增加對時間維度信息的擬合。圖卷積提取關節點之間的相對位置信息,時空卷積對相同關節點不同時間進行連接和信息融合,保證關節點在時序過程中動作的連續性。
以常見的圖像二維卷積為例,輸出特征圖上任意位置x可以表示為:
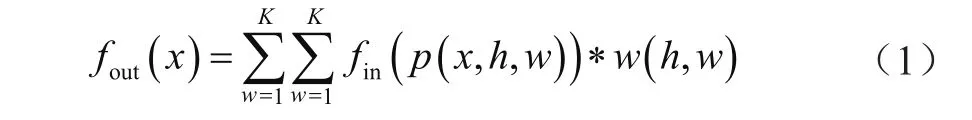
式中,fm大小為h*w*c的特征圖;K為卷積核的大小;采樣函數p是指以像素x為中心,區域大小與卷積核大小相同的矩陣特征;w為二維卷積核的權重值。
在同一幀姿態估計結果數據中,以關節點vti為中心點,其他關節點vtj到vti的最短距離表示為d(vtj,vti)。其中,相鄰的關節點間的距離為1。距離越遠代表兩點之間的物理緊密程度越小。
設定距離閾值D,到根節點vti的最短距離小于的集合為:
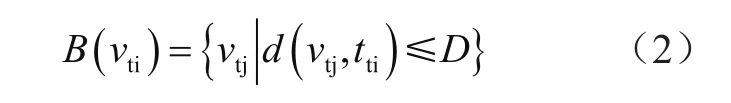
假定采樣函數p使用D=2的相鄰區域B(vti),則采樣函數p(vti,vtj)為:
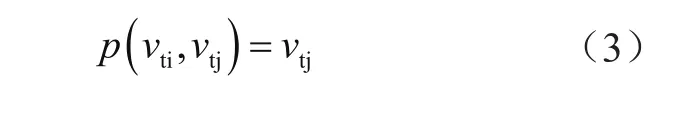

2.2 注意力機制的共現特征學習時空圖卷積模型
針對ST-GCN缺少遠距離關節點關聯的不足,本文在ST-GCN的基礎上,提出了一個如圖2所示以圖卷積網絡為基礎、引入新的注意力機制和共現特征學習、在線蒸餾結構的網絡結構[3]。
如圖2主干網絡所示,本網絡結構包含10個圖3所示的ATG結構,ATG結構類似于ST-GCN中的時空卷積單元結構,該結構先通過注意力掩碼與圖卷積的鄰接矩陣相加,使用一個卷積核大小與為5×9圖卷積提取相同一幀的關節點特征,再通過時空卷積對于不同時序同一關節點進行卷積,最后通過殘差的方式與輸入的特征進行融合,實現特征的跨區域提取;注意力機制的改變具體可查看2.2.2節;COF結構即為共現特征單元結構,具體可查看2.2.1節;在第五個ATG結構和第八個AGT結構后使用步長為2的卷積對特征下采樣。本文所述模型的前4個ATG結構的輸出通道均為64,第五個到第七個ATG結構的輸出通道均為128,后面3個ATG結構的輸出通道數均為256;對最后一個ATG的輸出特征圖,通過平均池化操作和全連接層計算,對全連接層輸出的特征圖通過Softmax分類器完成對動作的分類。
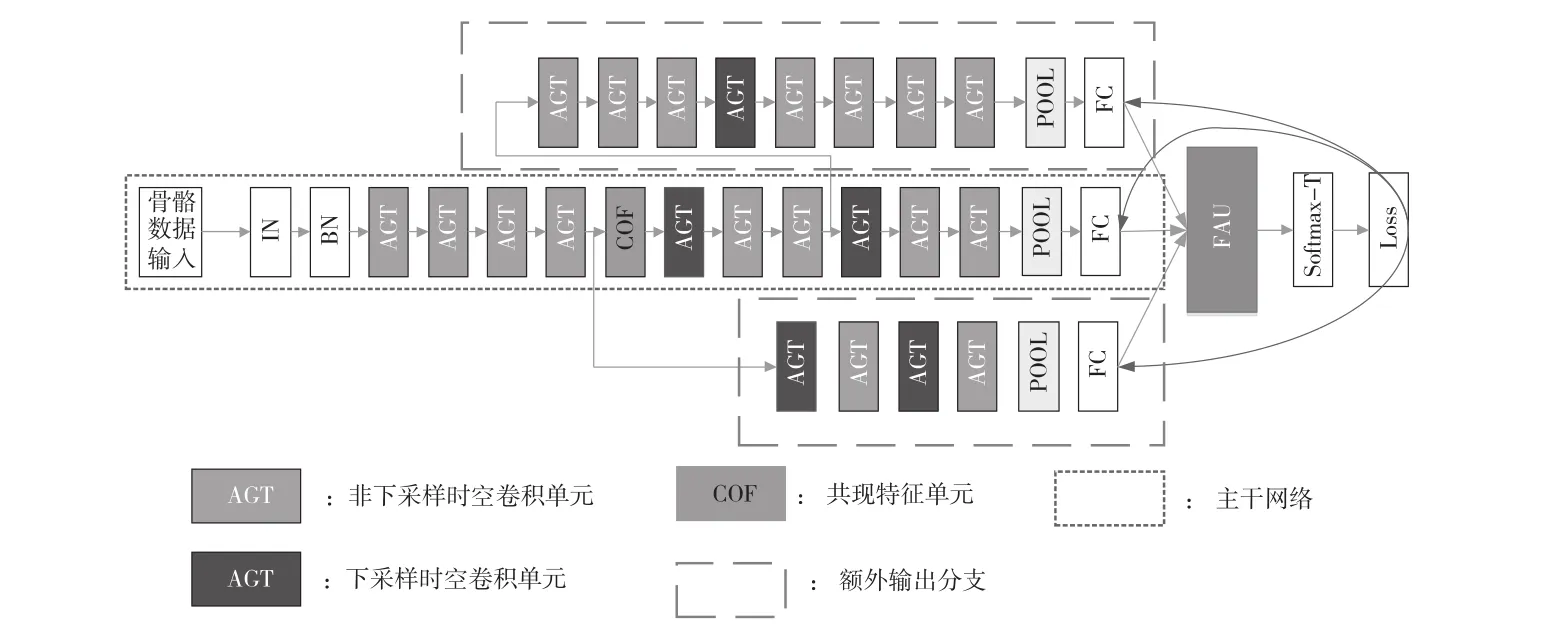
圖2 多任務網絡結構示意圖
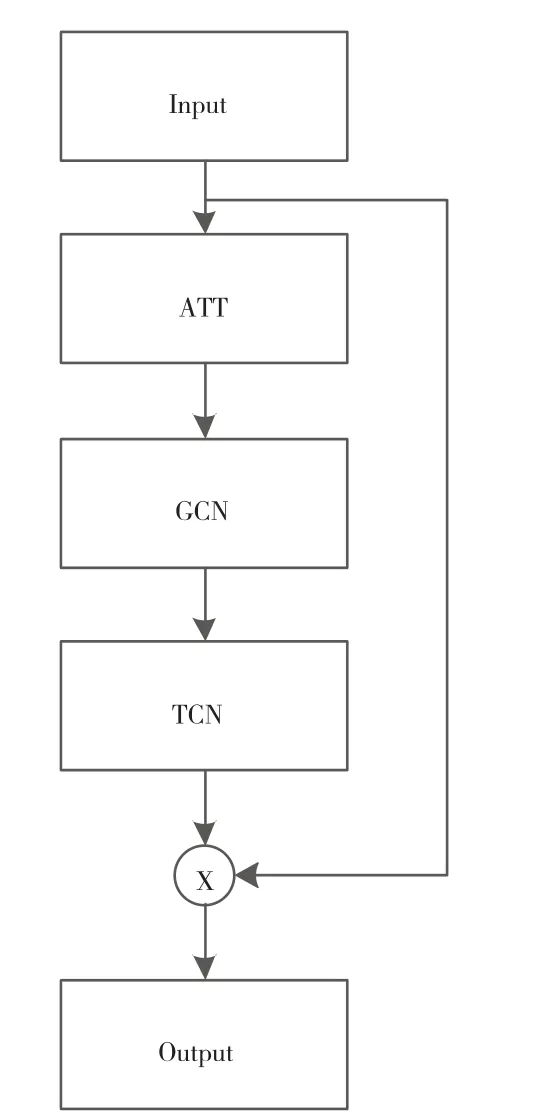
圖3 AGT結構示意圖
2.2.1 共現特征學習結構
一個行為動作不僅僅與物理相鄰的關節點相關,也有可能與其他相鄰很遠的關節點有關系。直覺上,“行走”這個動作,手與腳的聯系比較大;“舉著”這個動作,左手與右手的動作聯系較大。在ST-GCN中,手與腳的距離或者左右手腕的距離較遠,聯系很小,不能學習到很好的協調動作。基于此,本文提出一種如圖4所示共現特征學習(COF)模塊,通過將所有關鍵點信息轉置到同一維度,經過3層2d卷積與Relu激活后,再轉置回原有的輸入形狀,與輸入的特征圖在對應的元素相加作為輸出。
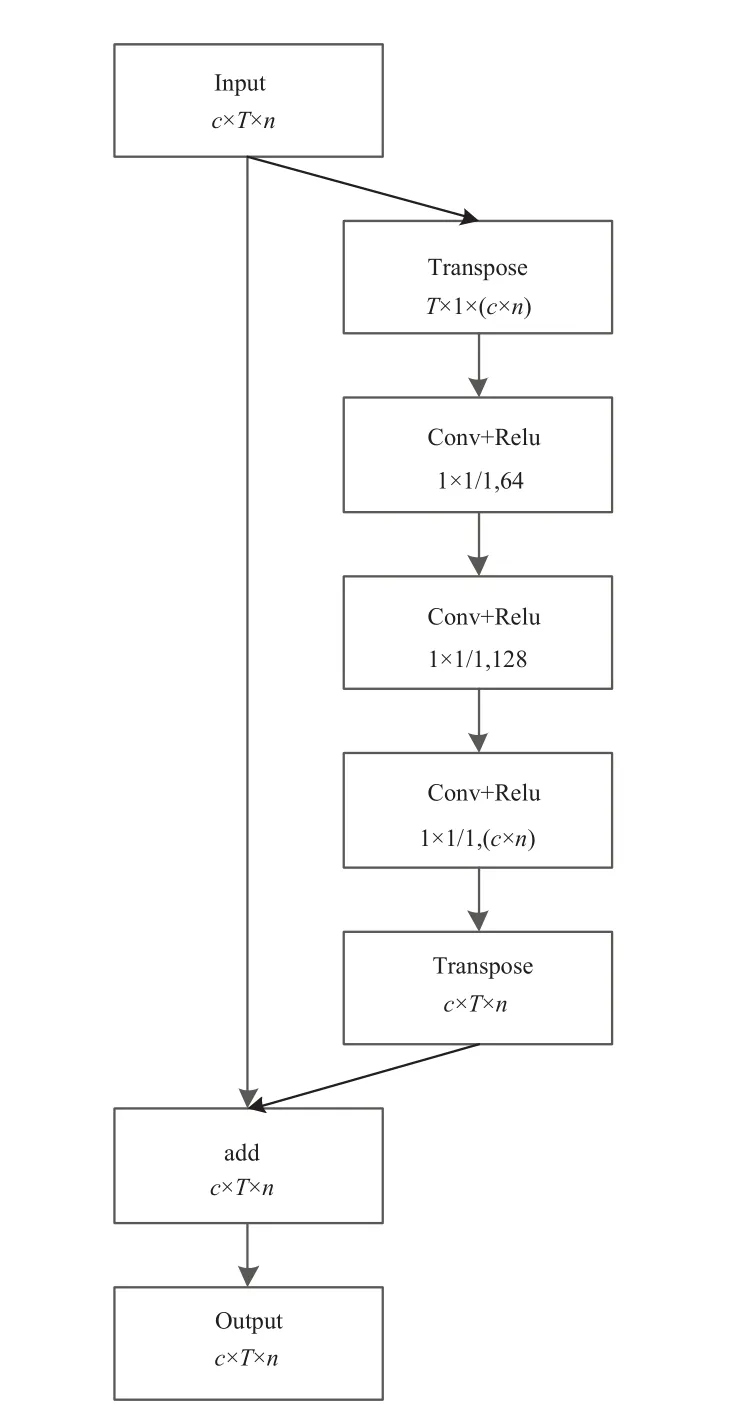
圖4 共現特征學習結構
具體而言,對于同一個人,一個T幀時序范圍,N個骨骼關節點,每個關節點有C種特征的骨骼序列可表示為一個尺寸是C×T×N×1的張量Fin。首先將張量轉置為T×(C×N),通過3層大小均為1*1,步長為1,通道數分別為64、128、(C×N)的卷積核計算,對卷積結果轉置到后與Fin。相同形狀得到F1,通過對應元素相加的方式得到輸出Fout:

2.2.2 注意力模塊
由公式(9)可以看出,在ST-GCN網絡中,時空卷積單元結構首先由一個可學習的注意力掩碼Mk是與鄰接矩陣Ak直接元素相乘,這就意味著,對于某些需要兩個物理連接很遠的關節協調的動作,雖然兩個關節的聯系很大,但是圖上沒有直接相連,鄰接矩陣對應的參數為0。此時注意力掩碼Mk并不能學習到兩者之間的聯系。
針對ST-GCN的注意力機制靈活性不夠的缺點,本文在T-GCN的基礎上,提出另外一種注意力機制方式。
具體而言,與ST-GCN的注意力機制類似,本文構建一個訓練的權重Mk,權重形狀與鄰接矩陣Ak一致。與ST-GCN不同,注意力掩碼Mk并不是直接與鄰接矩陣Ak對應元素點乘,而是對應元素相加。Mk中的參數并不會進行歸一化等任何約束條件,完全是從數據學習過來的參數,因此不僅能學習兩個節點是否存在聯系,還能表示聯系的強弱。
新的圖卷積的表達由公式(9)演變為:

2.2.3 多網絡分支集成在線蒸餾學習
常見的蒸餾學習需要先訓練大網絡,訓練完畢的大型網絡作為教師網絡,讓小網絡學習逼近教師網絡的輸出分布。集成學習是通過訓練若干個基學習器(base learner),通過一定的結合策略,最終形成一個強學習器,達到博采眾長的目的。集成學習的效果往往比基學習器效果好。
本文創新性地提出多網絡分支集成學習進行蒸餾學習。通過在網絡的不同位置增加兩個結構不一致的額外輸出分支,對不同分支的輸出結果集成,達到蒸餾學習中教師網絡輸出的結果。在訓練過程中,分支的集成結果可以作為教師網絡的輸出結果,對3個分支學生分支輸出的結果分別蒸餾。在推理過程中,通過去掉其余兩個分支,只保留主干結構,減少運算量,加快推理速度。整體網絡結構如圖2所示。
具體而言,本文在第四個、七個AGT模塊之后各增加一個與主干網絡結構不一的分支結構,每個分支單獨計算損失,教師網絡的輸出結果通過3個分支輸出的結果平均加權集成,如表達式(12)。

直接使用Fteacher的輸出結果進行Softmax對于正確的答案會有一個很高的置信度,不利于學習到集成結果的相似信息。本文使用Softmax-T激活函數,通過控制T的大小從而控制網絡的學習能力,公式如(13)所示:
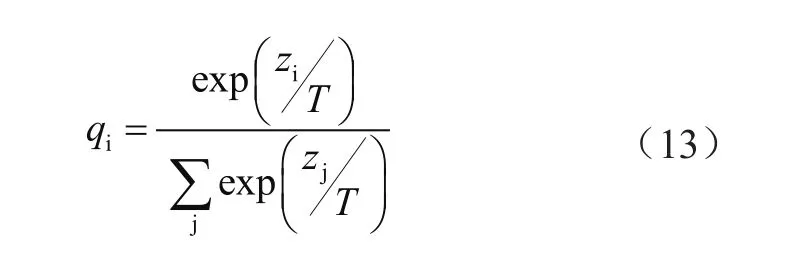
式中,qi是每個分支網絡學習的對象;zi是前的輸出象;T是溫度參數,通過控制T的大小決定蒸餾學習的平滑程度。如果將T取值1,則該公式退化為Softmax函數;T越大,輸出結果的分布越平滑,保留相似信息越多。本文中取值為2。
本模型的損失函數計算公式為:
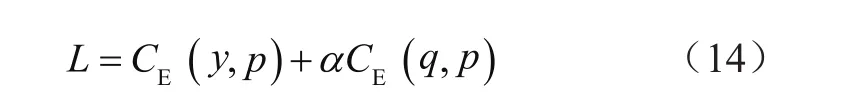
式中,CE是交叉熵(Cross Entropy)函數;y是真實標簽的one-hot編碼;q是集成教師網絡的輸出結果;p是每個學生分支的輸出結果。
通過本文所提供的辦法無需訓練額外的教師網絡也可以達到蒸餾學習的效果,有效提升行為識別模型的準確性。
3 實驗與分析
3.1 公開數據集介紹
Kinetics-skeleton 數據集[4]與 NTU-RGB+D 數據集[5]是基于姿態估計進行行為識別的兩個重要數據集。
Kinetics數據集包含網上收集的約30萬個視頻片段,涵蓋多達700個人類動作,是目前數量最大的無約束動作識別數據集。Yan[6]等使用OpenPose姿態估計算法在該數據集上視頻中獲得每一幀圖像中每個人的關節點坐標與置信度,記錄為(x,y,c),每一幀保留置信度最高2個人的數據。該數據集包含了24萬個訓練集數據與2萬驗證集數據。
NTU-RGB+D數據集是南洋理工大學通過3個Microsoft Kinect v2傳感器的骨骼跟蹤技術與3個不同角度的攝像機采集得到,涵蓋60個種類的動作,包括40類日常行為動作,9類健康相關的行為動作,11類多人行為動作。共計56 880個樣本。NTURGB+D數據集分為X-Sub子數據集與X-View 子數據集。X-Sub子數據集包括40 320個訓練數據和16 560個測試數據,其中訓練集來自同一個演員子集,測試數據來自其余的演員。X-View子數據集包含37 920個訓練數據和18 960個測試數據,訓練數據與測試數據是按照攝影機的ID劃分。
3.2 模型訓練和測試結果
本文在Kinetics-skeleton數據集和數據集上進行模型訓練和測試,本文使用1塊1080ti 的顯卡,顯存大小為11 GB,CPU 為Intel Xeon(R) silver 4210 CPU@2.2GHZ*40,訓練系統環境為ubuntu16.08,CUDA環境為10.2,CUDNN環境為7.6.5,深度學習框架為pytorch1.6,優化器為SGD ,動量設置為0.9,權重衰減為10-5。初始學習率為10-2,使用余弦退火的學習率變化策略。訓練的批次大小為64,一共迭代200 000次。在Kinetics-skeleton 數據集的表現與其他算法對比如表1[5,7]:
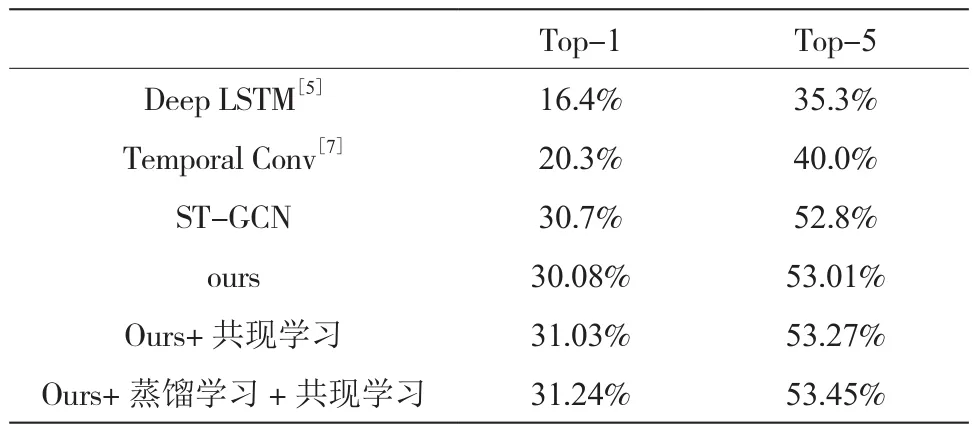
表1 本文算法與其他算法在Kinetics-skeleton 數據集準確率對比
使用相同配置訓練NTU-RGB+D數據集,在NTU-RGB+D數據集表現與其他算法對比如表2[8]。

表2 本文算法與其他算法在NTU-RGB+D 數據集準確率對比
4 結 論
本文提供了一種以時空圖卷積網絡為基礎、引入了注意力機制和共現特征學習結構的網絡結構,通過增強不同關節之間的聯系,提升行為識別模型的精度。同時提供一種在線蒸餾學習的方式增強模型的泛化能力。本文提供的模型在Kinetics-skeleton數據集上取得31.25%的Top-1 精度與53.45%的Top-5性能精度,相比于原版的ST-GCN算法,Top-1和Top-5分別提升了0.44%和0.65%。本文提供的模型在NTU-RGB+D的子數據集X-Sub取得86.7%的Top-1精度,在NTU-RGB+D的子數據集X-View取得94.6%的Top-1精度,對比于原版的ST-GCN算法,提升了5.2%和 6.3%。證明了引入注意力機制和共現特征學習機制增強模型的感受野,以及使用蒸餾學習能增強ST-GCN算法的性能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
哲學評論(2021年2期)2021-08-22 01:53:34
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
