基于編解碼器結構從圖像生成文本的研究進展
2021-05-28 06:04:06吳越
現代計算機 2021年11期
吳越
(四川大學計算機學院,成都610065)
0 引言
隨著日常生活的數字化程度的逐步加深,數字圖像的數量也在飛速增長,而人們利用圖像的能力與圖像的增長速度卻不匹配,從圖像生成文本即圖像標注旨在為計算機賦能,使其具備“看圖說話”的能力,能夠自動地從圖像獲得描述性的文本,可以幫助人們從海量的圖像數據中獲取所需要的信息,在視覺問答系統、以圖搜圖、視頻內容理解等任務場景都有著重要的應用,在商業、軍事、教育、生物醫學、數字圖書館等領域都有良好的發展前景。
近年來,隨著人工智能浪潮的翻涌,越來越多的專家和學者投入到神經網絡的研究中來,其中以文本方向的自然語言處理(NLP)和圖像方向的計算機視覺(CV)最為火熱,而從圖像生成文本即圖像標注作為這兩個方向的結合,得益于兩者的快速發展也取得了堅實而長足的進步。從圖像生成文本的方法大致可以分為基于模板、基于檢索和自動生成三種,目前效果最好的模型幾乎都是采用自動生成的方法,本文的主要關注點在自動生成中基于神經網絡的編碼器和解碼器結構的算法,這也是目前主流的方法,以下分別從三個方面進行闡述:基于編解碼器從圖像生成文本的神經網絡模型、生成過程中的重要研究點以及網絡模型的性能評價。
1 基于編解碼器從圖像生成文本的神經網絡模型
基于編解碼器[1]從圖像生成文本的神經網絡模型包括三個主要部分:骨架網絡、編碼器和解碼器。其中骨架網絡采用卷積神經網絡(CNN),用來提取圖像的視覺特征表示,生成高維的視覺特征圖;編碼器利用骨架網絡產生的視覺特征圖編碼成一個上下文向量;解碼器根據上下文向量來生成最終的描述性文本。
主流的神經網絡模型大致可以分為三類:CNN +RNN、CNN+CNN、CNN+Transformer。
1.1 CNN+RNN
CNN+RNN 模型使用卷積神經網絡(CNN)作為骨架網絡,循環神經網絡(RNN)作為編碼器和解碼器,如圖1 所示。
CNN 模型以AlexNet[2]、VGG[3]、GoogLeNet[4]、ResNet[5]等為主要代表,這些模型已經在大規模的圖像數據集如ImageNet[6]、COCO[7]等中表現出了極其優越的性能,通過卷積、池化、激活函數、歸一化等操作能夠從圖像數據中提取出有效的特征信息,這些特征信息可以直接作為編碼器的輸入,而不再需要機器翻譯的做法(將輸入的語句序列通過詞嵌入變成向量空間中的高維向量,然后再送入編碼器進行上下文向量的編碼),不過需要額外對特征信息進行位置編碼,因為圖像特征可以看作一個二維向量,通用做法是按行或者按列展開成一個序列,所以需要對序列中加入行或者列的信息。
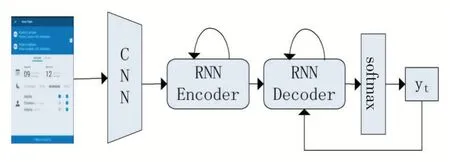
圖1 CNN+RNN模型結構
現有研究不僅僅是使用CNN 模型來提取視覺特征圖,更多的是采用目標檢測網絡(以R-CNN[8]、Faster R-CNN[9]為代表,已經在計算機視覺領域下的目標檢測中證明了其優越性)提取出感興趣的區域,然后將這些區域作為編碼器的輸入信息。
RNN 主要采用長短期記憶神經網絡(LSTM)[10]及其變種雙向LSTM(BiLSTM)[11]和門控循環單元(GRU)[12],這些模型也已經在語言模型上表現出了極其優秀的性能,采用自回歸的方式逐字的生成描述性文本。模型按照時間片一步一步的向前推進,每一個時間片的輸入包括上一個時間片的隱狀態和生成的單詞,然后經過運算產生當前時間片的隱狀態和單詞,循環往復的執行下去,直到輸出結束標記停止,每一步得到的單詞串起來就是完整的輸出序列。模型將
由于RNN 模型在機器翻譯領域表現良好,故而在圖像生成文本中也較常采用RNN 類的模型,且基于自回歸特性,能夠生成不定長的描述性文本,恰好滿足任務需求。但是因為它的逐字的訓練方式,導致模型并行運算程度低,不能較好地發揮GPU 的并行計算能力,故而另有一部分研究著重關注并行計算。
1.2 CNN+CNN
由于RNN 模型的特性,每一步都是將上一步的輸出當作輸入,從而按時間片展開進行訓練,雖說模型生成文本的效果較好,但是訓練時間比較長,并不能較好地發揮GPU 并行計算的能力,而在計算機視覺領域廣泛采用的CNN 卻能很好地并行計算,如果能夠將CNN用來做不定長文本生成的話,恰好能解決這一問題,基于此,有一些研究專門針對CNN 網絡來模擬RNN效果。
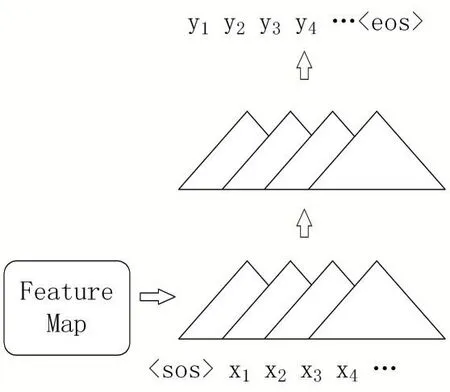
圖2 CNN編解碼器
這種CNN 不同于圖像中采用的2D 的CNN,被稱作因果卷積[14],實質上是堆疊而成的一維卷積,如圖2所示,將提取出的圖像特征與文本的詞嵌入向量一起送入CNN 編碼器提取上下文向量,再采用解碼器進行解碼,實際構建中可能不進行編解碼器的區分,直接堆疊卷積層[15],然后進行計算得出描述性文本,需要注意的是,采用的卷積層為了避免“看到”未來的單詞向量,加入了mask 來進行遮蔽,達到選擇性計算的目的[16]。
利用CNN + CNN 模型進行圖像到文本的生成任務,基本上可以達到3 倍于CNN+RNN 模型的訓練速度,并且可以取得相當的生成效果。
1.3 CNN+Transformer
CNN+Transformer 模型[17]使用CNN 提取圖像特征或者目標檢測器提取感興趣區域,然后送入Transformer encoder 進行上下文向量編碼,之后送入Transformer decoder 進行解碼生成描述性文本,其中encoder 和decoder 都是多層堆疊的[18],層內結構如圖3 所示。其中CNN 模塊的使用和組成同1.1 小節中的描述,但是將編解碼器的RNN 模塊使用Transformer[19]進行替代,這種做法基于以下幾個原因。
(1)RNN 的step by step 的訓練方式導致它的訓練速度過于緩慢,對于具有強大并行計算能力的GPU 來說,這種算法并不高效,需要花費大量的時間。而Transformer 模塊的self-attention 完全可以并行計算,能夠充分發揮GPU 的性能,加快模型的訓練速度。
(2)RNN 天生具有長依賴問題,即對于當前的預測來說,它的輸出雖說是依賴于之前時間片所有的輸出得出來的,但是距離過長的時間片的輸出對于當前時間片的影響可以說是微乎其微,雖然引入了LSTM 可以部分解決長依賴,但是對于過長的序列,依然普遍存在這個問題。而圖片本身又是一個2D 空間,將其從2D 空間展開成1D 空間向量所得到的序列往往都特別長,即使一個200×300 的小圖片展開之后都可以達到60000 的序列長度,這時如果圖片頭和圖片尾存在強依賴的話,LSTM 也會導致錯誤的預測結果。Transformer由于其每一個V 都是采用Q 和所有K 計算得出,即每一個值都是“看過”所有的值計算出來的,所以能夠從根本上解決長依賴問題,就算是圖片頭的輸出,也是可以“看到”圖片尾的。
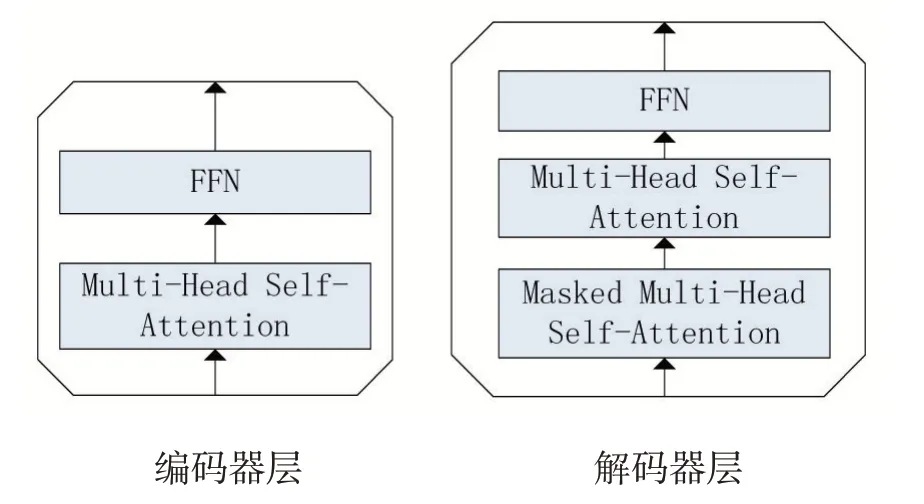
圖3 Transformer編解碼器層
Transformer 的解碼器依然是一步一步的進行解碼的,每一步都是基于之前生成的單詞進行后面的預測,但是在訓練的時候采用teacher-forcing mode 進行訓練,這里是可以并行計算的,即一次性輸入target 的嵌入向量矩陣,然后生成一個mask 向量矩陣,該矩陣特定編碼成按target 單詞長度的mask,從而保證每一次預測都是基于之前的預測的,而不需要一步一步的進行訓練。
2 生成過程中的重要研究點
從圖像生成文本最主要的研究點基本上可以概括為兩個方面:一個是如何從圖像提取特征表示,另一個是生成的文本和圖像中哪些區域相關聯。
2.1 如何從圖像提取特征表示
得益于計算機視覺的高速發展,現在一般采用兩種方法來進行圖像特征提取:
(1)使用CNN 對圖像進行卷積操作,不采用一般CNN 網絡最后的連接層,而提取前面的圖像特征圖,然后將特征圖按行或按列展開,使其成為一個1D 的向量,后續可以采用機器翻譯類的模型,直接作為編碼器的輸入而不需要依照傳統機器翻譯的做法,將輸入文本進行嵌入式操作。
(2)使用R-CNN、Faster R-CNN 等目標檢測頭來進行圖像特征提取,不同于之前的CNN 卷積操作提取,先將目標檢測頭在目標檢測數據集上做預訓練,然后將目標檢測頭用來提取出一個感興趣區域的集合,將這些區域的集合作為編碼器的輸入。
由于檢測頭提取的感興趣圖像區域更利于后續編碼器提出上下文向量,現有state-of-the-art 的方法幾乎都是采用的第二種特征提取方式。
2.2 生成的文本和圖像中哪些區域相關聯
由于網絡的輸出包括兩個部分:圖像和文本。它們之間有一個顯而易見的區別,即圖像具有2D 空間排列且寬高比例多變,而文本是1D 空間排列,那么如何將抽取出的圖像特征和文本特征進行對齊呢?[20]針對這個難點問題,研究者提出了注意力機制,即對不同的向量有不同的得分,從而能夠針對性的關注得分高的區域,從而將文本和目標區域關聯起來[21]。
注意力最早在機器翻譯里面提出來,主要源自于人類觀察事物的時候總是只關注某一個局部,換句話說,一句話的主要意思只和某一些部分相關聯,而和其他部分關聯不大。前面所述的Transformer 模型采用了self-attention 的注意力機制,基于dot-product attention進行的改進,可以完全進行矩陣運算,并行效率高,并且每一個V 的計算都是在所有向量數據的基礎上得出的,是一個優秀的注意力方法。
3 圖像模型的性能評價
3.1 主流評測數據集
主要用來做圖像生成文本任務的數據集包括:Flickr8k、Flickr30k 以及MS COCO。在對目標檢測頭做預訓練的時候常用到的數據集包括:ImageNet、MS COCO 和Visual Genome。Flickr8k 是一個圖像標注數據集,一共有8000 張圖片,每一張圖片都帶有5 個不同的描述性文本;Flickr30k 增大了圖片數量,每張圖片依然是帶有5 個不同的描述性文本,統一放在token 標注文件中,一共有30000 多張圖片;MS COCO 數據集比較龐大,有多個分支,包括目標檢測,分割以及圖像描述等,常用2014 和2017 的版本,有超過16 萬張圖片,每個圖片依然有5 個描述性文本,并且分了80 個類別,且同時包含目標檢測的標注,所以可以同時作為目標檢測頭的預訓練數據集。Visual Genome 有超過10 萬張圖片,對圖片中出現的所有類別都進行了標注,且一張圖片可能有多個描述性文本,主要針對場景和關系。
3.2 主流評價指標
主要用來評估圖像生成文本任務的指標包括:BLEU、METEOR、ROUGE、CIDEr、和SPICE。BLEU 常用在機器翻譯的任務中,用來評價翻譯文本和參考文本的差異性,基于精度來進行相似性度量;METEOR 不僅僅考慮精度,還考慮了召回率,加入了同義詞的考量,基于chunk 來進行得分計算;ROUGE 不同于BLEU,它是基于召回率來進行計算的,只要沒有出現漏掉的詞,得分就會比較高;CIDEr 是專門針對圖像標注任務的指標,通過評價生成文本與其他大部分的參考文本之間的差異性計算得分,通過計算TF-IDF 向量的余弦距離進行度量;SPICE 也是針對圖像標注任務的,與CIDEr 不同的是它是基于圖的語義表示進行計算的,主要考量詞的相似度。
4 結語
本文梳理了近年來在圖像生成文本的任務上提出來的主要的編解碼器模型。提出了3 種主要的編解碼器類型,同時討論了各種類型的主要特點;除此之外,也總結了2 個在圖像生成文本任務中的主要研究點,便于后續深入研究;同時也描述了在圖像生成文本任務中常用到的5 種數據集以及5 種評價指標,討論了各個數據集特點和各種評價指標的特性。未來的研究者可以針對特定場景下的任務選取適用的評價指標,參考前面提出的神經網絡框架進行深入研究,使其更好地適應任務場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
