SNESIM和FILTERSIM算法在礦體建模中的比較研究
2021-06-06 09:51:36高路萍劉曉明王濤王雨鄧磊
采礦技術 2021年3期
關鍵詞:模型
高路萍,劉曉明,王濤,王雨,鄧磊
(1.武鋼資源集團大冶鐵礦有限公司, 湖北 黃石市 435006;2.長沙迪邁數碼科技股份有限公司, 湖南 長沙 410025)
0 引言
現有的礦體建模軟件多是基于人工交互的方式,并遵循以下流程:手動繪制地質剖面圖;通過人機交互的方式生成線框模型[1]。對于復雜的地質模型,步驟二需要花費地質人員大量的時間和精力,同時易出現退化三角形、開口、自相交等問題[2?3]。而自動建模方法可以通過隱式函數插值自動重建三維地質模型。因此,各類隱式建模方法備受地質人員的廣泛關注,其中油氣藏領域的多點地質統計學隨機建模方法是隱式建模研究的熱點方向之一[4]。
GUARDIANO and SRIVASTAVA等人最先提出使用訓練圖像的高階統計量進行三維空間模擬[5]。此后經過30年的發展,學者們提出了多種不同的多點地質統計學(MPS)模擬算法,總體上可劃分為數理統計算法和計算機圖形學算法等[6?8]。STREBELLE[9]提出了SNESIM算法,使用搜索樹來存儲訓練圖像的掃描結果;在此基礎上,MARIETHOZ[10]提出了一種直接采樣DS算法,大大提高了模擬效率。ARPAT等[11]基于計算機圖形學中模式識別方法提出了SIMPAT算法,但只能應用于分類變量模擬。ZHANG等[12?13]提出了FILTERSIM算法,該方法使用多種二維過濾器來分辨空間模式。CHATTERJEE[14]提出了WAVESIM算法,使用小波濾波對訓練模式進行分類。MPS模擬核心為3部分:訓練圖像、數據事件、多點概率,其中訓練圖像應包含模擬區域完整的地質特征[15]。因此,MPS模擬通常需要構建龐大的訓練圖像庫,以便數據事件掃描提取多點概率[16]。對于金屬礦床建模,圈定地質剖面圖、平面圖是既定的工作流程,這些包含地質學家認識和認知的二維圖像是構建訓練圖像庫最好的數據來源[17]。
目前MPS方法大多應用于油氣藏領域建模,鮮有學者將其應用于礦體建模。為了研究MPS算法在金屬礦床建模中的適用性,本文使用地質統計學軟件(SGeMS)中的SNESIM和FILTERSIM算法來模擬一個合成的礦體模型,最后將這兩種算法的模擬結果與地質學家人機交互的建模結果進行比較,以此來判定兩種算法的適用性。
1 多點地質統計學原理及關鍵算法
多點地質統計學方法[18]是模擬空間多個點(>2)聯合分布的地質統計學方法,具體思路為:根據地勘數據構建多點搜索樣板掃描訓練圖像,獲得相應的多點概率密度函數或相似訓練模式,最后用模擬結果填充建模空間。
如圖1所示,當數據樣板中條件數據dn與訓練圖像中模式相同時,將其記為有效模擬。因此,多點概率計算公式為:
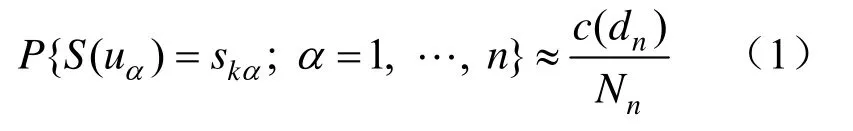
式中,Nn為訓練圖像中樣板數目;c(dn)為數據樣板在訓練圖像中有效重復次數。

圖1 數據樣板、訓練圖像對應關系
當模擬空間中存在K種不同物質時,空間任意位置的條件概率分布函數為P{S(u)=sk|dn},其中dn為鉆孔采樣數據。

未知節點為屬性1的數目有1個,即c1(dn)=1;未知點為屬性2的數目有2個,即c2(dn)=2。因此,未知點為屬性1的概率可定為1/3,屬性2的概率為2/3。
1.1 SNESIM算法
STREBELLE在ENESIM算法的基礎上提出了一種非迭代的SNESIM算法[19]。為了提高解算效率,STREBELLE提出用數據樣板一次性整體掃描訓練圖像,然后將結果保存在搜索樹中,在之后的未知點模擬時只需要從搜索樹中提取相應統計結果。REMY等[20]在SGeMS軟件中開發了SNESIM仿真算法,詳細算法流程如圖2所示。
VRIES等[21]認為搜索樹結構能夠大幅減少MPS模擬的時間,因MPS單次模擬過程中,數據樣板尺寸是恒定的,因此僅需特定數據樣板在訓練圖像中掃描一次即可提取所有有效的訓練模式。圖3為訓練圖像與搜索樣板示意圖。搜索樣板掃描訓練圖像后生成的搜索樹結構如圖4所示。搜索樹的第一個節點對應位置u,相應的搜索樹的級數對應ui(0≤i≤4)。搜索樹的每個節點在下一級中均會被分為K個新節點,其中K是模擬空間中可能的類別總數。搜索樹每個節點的值代表當前樣板結構在訓練圖像中搜索到的有效模式數目。顯然,搜索樣板模型越復雜,搜索樹的層級就越多,對應的模擬結果也就越準確。
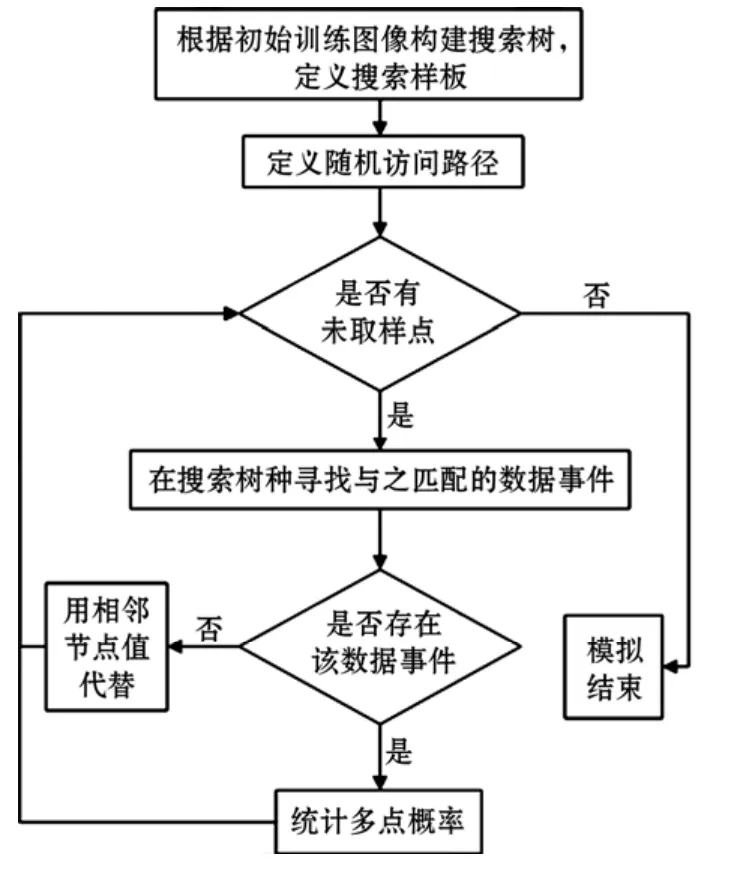
圖2 SNESIM算法流程
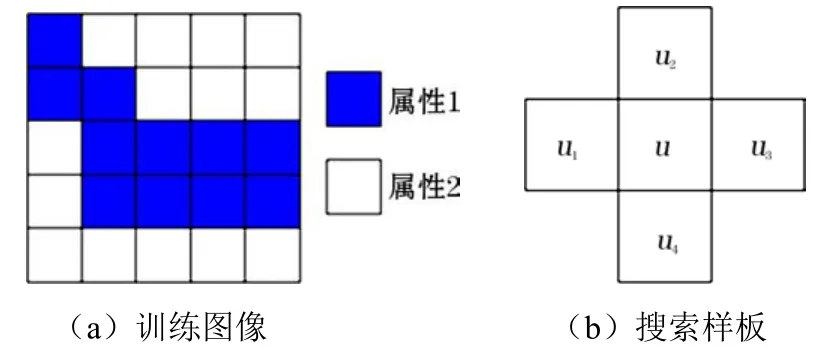
圖3 訓練圖像與搜索樣板
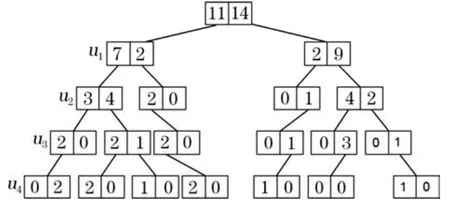
圖4 搜索樹結構
1.2 FILTERSIM算法
FILTERSIM算法使用一些線性過濾器對訓練模式進行分類,從而實現降維的目的[22]。模擬期間首先確定距離條件數據事件最接近的原型分類,然后選擇與條件數據最相似的訓練模式,將其粘貼回模擬網格。SNESIM算法將所有訓練的重復結果保存在搜索樹中,而FILTERSIM算法只保存了每個訓練模式的中心位置,這樣顯著減少了對內存RAM的需求。FILTERSIM算法主要分為3步:濾波分( filter score)計算、模式分類和模式模擬,詳細算法流程如圖5所示。
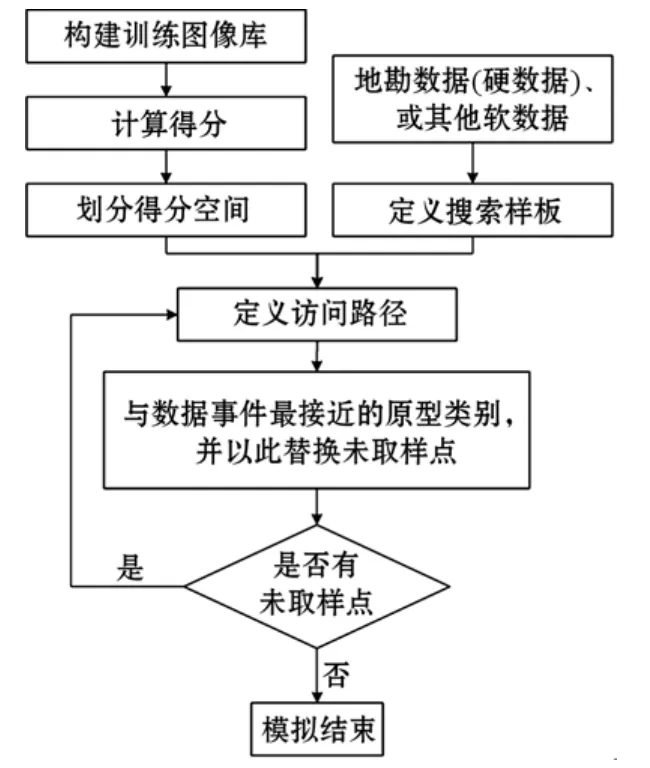
圖5 FILTERSIM算法流程
FILTERSIM算法能夠接受兩種形式的過濾器:默認過濾器和用戶自定義過濾器。默認情況下,FILTERSIM算法為X、Y、Z方向提供了3個過濾器f(均值、梯度和曲率),見式(4)~式(6),其中過濾器結構和搜索樣板完全相同。ni是i方向的模板尺寸(i表示的是X、Y、Z);mi=(ni?1)/2和αi=?mi,…,+mi是過濾器節點在i方向的偏移量。過濾器可以將訓練模式概括為一組分數ST(u),其中u為模板中心節點;pat(u+(αi))為模擬節點值;f=nx*ny*nz,n為某一方向模板尺寸。
2 建立三維礦體模型
本文選擇將SNESIM和FILTERSIM算法的模擬結果與人工圈定的礦體模型進行比較,以此來評價這兩種算法在礦體建模中的適用性。為了便于比較MPS中兩種算法的優越性,本文開發了合成的礦體模型,礦體模型中44個鉆孔數據為MPS模擬硬數據。此外,礦山地質人員在N?S方向繪制了8個地質平面圖作為訓練圖像。圖6為鉆孔數據及人工圈定礦體模型圖,鉆孔數據可以作為MPS模擬的硬數據,圖中包含的3種顏色分別代表不同的屬性(藍色為圍巖,綠色為1號礦體,紅色為2號礦體)。為了保證模擬結果的可比性,SNESIM和FILTERSIM算法參數基本一致且均是較優參數。
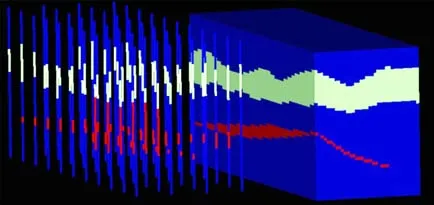
圖6 鉆孔數據及人工圈定礦體模型
2.1 SNESIM算法模擬結果
SGeMS軟件中SNESIM算法計算參數為:模擬實現的數量為3;初始化偽隨機數為211175;分類變量類別為圍巖、1號礦體、2號礦體,比例為0.78:0.17:0.05;搜索模板包含90個節點,最大值為150,中間點為100,最小值為75;伺服系統參數為0.5;多層網格參數為3;每次只輸出最終的模擬結果。
應用圖6所示的鉆孔數據以及8個訓練圖像進行SNESIM算法模擬,模擬網格基礎塊尺寸為1m×1m×1m;模型規模為75m×250m×100m。圖7為SNESIM算法模擬結果,其中圖7(a)為三維模擬結果,圖7(b)~(d)分別為X在0,25,75時的剖面圖。顯然圖7的三維模型中重現了1號礦體和2號礦體,但整個建模區域存在較多零散的“噪聲”,并沒有得到地質學家預期的地質模型。
2.2 FILTERSIM算法模擬結果
SGeMS軟件中FILTERSIM算法計算參數為:模擬實現的數量為3;初始化偽隨機數為211175;搜索模板尺寸為41m×41m×3m;粘貼樣板尺寸為3m×3m×1m;多重網格參數為3;模式原型的拆分準則為10×10×10;各類數據的權重指數為0.8:0.2;每次只輸出最終的模擬結果;模式分類算法為K-Means,初始聚類數量為200,之后的聚類數目為2;相似性判斷依據為模式分數差最小。
FILTERSIM算法模擬使用了圖6所示的數據庫,目的是比較兩種方法的結果,模擬網格基礎塊尺寸以及模型規模與SNEISM算法相同。圖8為FILTERSIM算法模擬結果。顯然圖8的三維模型很好地重現了1號礦體和2號礦體,與SNESIM算法相比呈現了更好的連續性,模擬結果中“噪音”較少,得到的模擬結果符合地質學家的預期。
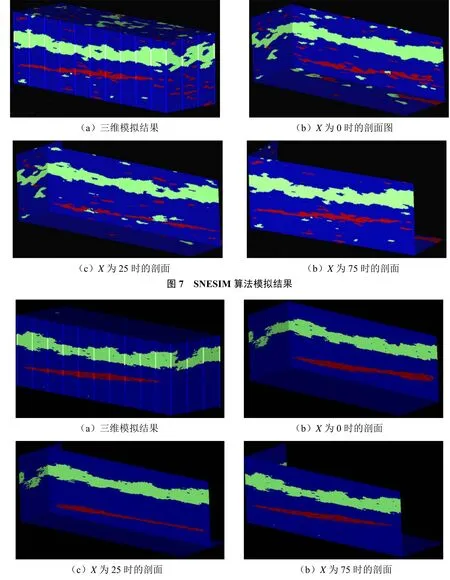
圖8 FILTERSIM算法模擬結果
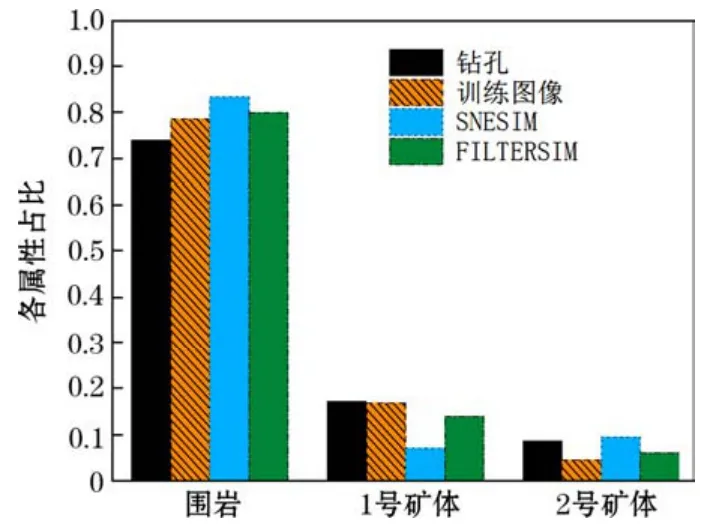
圖9 各數據模型中屬性占比
圖9為各數據模型中屬性占比,比較了鉆孔數據、訓練圖像、SNESIM算法模擬結果以及FILTERSIM算法模擬結果中各類屬性的占比情況。顯然FILTERSIM算法模擬結果中各類屬性的占比與鉆孔數據、訓練圖像中的屬性占比較為吻合,而SNESIM算法模擬結果則與之存在偏差。因此,各屬性占比統計結果與上述視覺對比結論一致。
3 結論
兩種典型的多點地質統計學算法(SNESIM和FILTERSIM算法)均能夠重現礦體模型復雜的空間特征,兩種算法模擬過程均可在90 s內完成。相較于人機交互的顯式建模方法,本文算法自動化程度更高。FILTERSIM算法的模擬結果連續性更好,更具有代表性;而SNESIM算法模擬結構隨機性更強,導致三維模型存在較多“噪音”。多點地質統計學方法仍需要進一步的研究,使其在礦體建模中得到更廣泛的應用。訓練圖像庫越詳細,模擬結果就越準確,而采礦業往往缺乏準確且詳細的地勘信息。目前該方法在礦體建模領域應用的主要難點在于構建合適、準確的訓練圖像庫。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
