基于備選候補機制的PBFT改進研究
2021-06-16 06:30:46惠二鑫趙鵬彭俊霞
電子技術與軟件工程 2021年8期
惠二鑫 趙鵬 彭俊霞
(太原師范學院 山西省晉中市 030619)
區塊鏈技術隨著比特幣的出現而問世,其并非一種新的技術,而是將分布式存儲、對等網絡、非對稱加密、共識機制等計算機技術整合起來的新型應用模式[1]。具有去中心化、公開透明、共同維護及不可篡改等特性。
最為區塊鏈核心技術的共識算法,是近年來分布式系統研究的熱點。是保證分布式系統中各節點數據一致性的關鍵,目前,區塊鏈系統中所使用的經典共識算法有PoW 算法,PoS 算法、BFT 算法、PBFT 算法等,不同的算法有各自的優缺點。許多學者在共識策略、一致性協議以及區塊結構等方面對PBFT 算法進行了改進,但是該算法應用在一些需要不斷擴張的領域中,依舊存在節點網絡靜態不可變的問題[2],因此解決PBFT 算法動態性差成為一個急需解決的問題。
1 實用拜占庭容錯算法
實用拜占庭容錯算法(Practical Byzantine Fault Tolerance, PBFT)[3]是在1999年由Miguel Castro 和Barbara Liskov 提出的。能夠在失效節點不超過(n-1)/3(n 為集群節點總數)的情況下確保共識系統的安全性和一致性[4]。PBFT 共識機制中所有節點需要保證數據達成最終一致性,為此PBFT 需進行一致性協議、檢查點協議和視圖更換協議[5]來確保各個節點的行動一致。
一致性協議是PBFT 共識算法的核心部分,主要通過預準備、準備和確認三個階段來保證數據的一致性。在集群中每一次共識都是在某一個視圖狀態下進行的,且每個視圖狀態下只存在唯一的主節點,共識集群中的其他節點都是副本節點。共識的具體過程如圖1 所示,其中C 是客戶端,副本0 是主節點,副本3 是失效節點。
在傳統PBFT 算法的分布式系統中,所有節點相互獨立,且節點發生拜占庭錯誤也相互獨立,共識節點和拜占庭的節點的個數分別為N、f,兩者間的約束條件如公式(1)所示:

從上面公式可以看出,在分布式系統中,共識節點的總數和可接受的拜占庭節點數與密切相關。由于PBFT 共識機制本身沒有動態機制,不能進行動態共識,因此每一輪的共識節點都是固定的。這個特性在聯盟鏈的實際應用中有很多缺點。例如,新的節點無法加入到網絡中;作惡節點也無法從網絡中退出。
2 算法改進
2.1 算法思想
針對PBFT 算法節點無法動態感知的問題,本文將PBFT 算法進行改進,首先增設一個額外的候補節點集合,在新增的候補節點中進行備選主節點的選取,讓節點可以動態增加或刪除。DPBFT算法思路如圖2 所示。
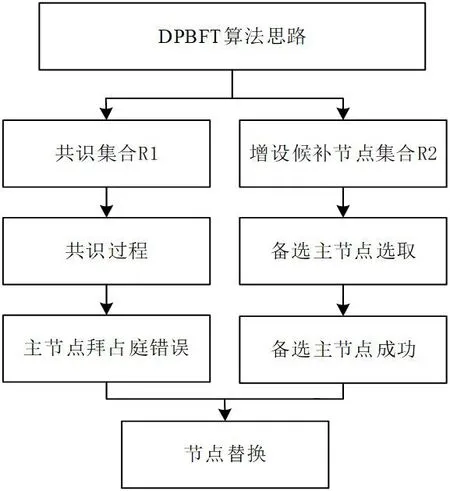
圖2:DPBFT 算法思路
2.2 增加候補節點
將系統中的節點分為兩部分,一部分是共識節點;另一部分是候補節點。共識節點負責系統的共識,候補節點用于備選主節點的選取。在候補節點集合中存放的是新加入系統的節點和共識過程中發生拜占庭錯誤的節點。
共識節點集合和候補節點集合用R1、R2 表示,其定義如下:

當R1 中主節點拜占庭錯誤或其他共識節點退出系統中時,R2中選舉產生的備用主節點將其替換,被替換掉的節點將淘汰到R2集合中,保證了系統中共識節點數量的穩定,實現了節點的動態替換。
在候補節點集合R2中信任節點的選舉方式采用投票選舉機制。為了提升節點替換效率,R1 中節點的共識和R2 中信任節點的選取是同步進行的。主節點發生拜占庭錯誤時,使用R2 中選出備選主節點將其替換,整個過程省去了視圖切換。
此外為預防發生拜占庭問題的主節點重復當選主節點的可能,增加一個參數H,候選主節點的計算公式如(4)所示:

其中h 表示區塊高度,R2 為候補節點集合v,表示當前視圖編號P 為主節點選取結果。
將視圖切換過程和主節點的選舉相結合,可有效減少視圖切換次數,降低了整個共識過程的共識時延。
2.3 候補主節點選取
第一步:在R2 中通過公式(4)計算出候選節點,該向其他節點發送自己將要選舉的消息。
第二步:當R2 中其他節點收到候選節點發送的消息后,進行確認。如果R2 集合中有半數以上的節點同意,候選節點將被選舉為備用主節點,否則重新選舉。
第三步:為防止在選舉的過程中參與投票的節點發生超時而導致惡性循環選舉問題的出現。改進后的算法為每個節點設置唯一的超時值,當參與投票時節點會有序的進行投票。有效避免所有節點的得票都不足一半情況。節點分先后,最終確定一個唯一的備用主節點,用來替換共識集合R1 中的問題節點。選舉過程流程圖如圖3 所示。
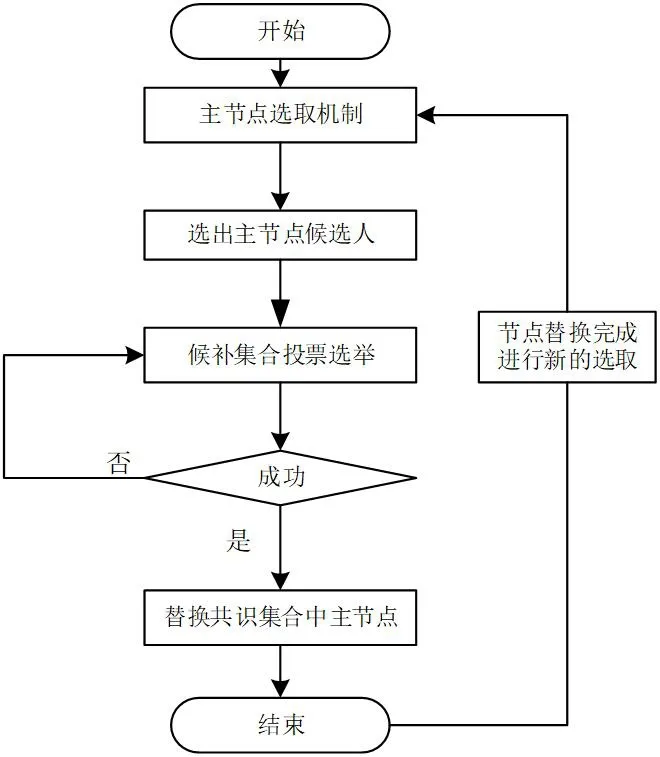
圖3:選舉過程
2.4 算法的整體流程
根據改進算法的設計思想和具體設計,給出DPBFT 算法的整體流程。如圖4 所示。
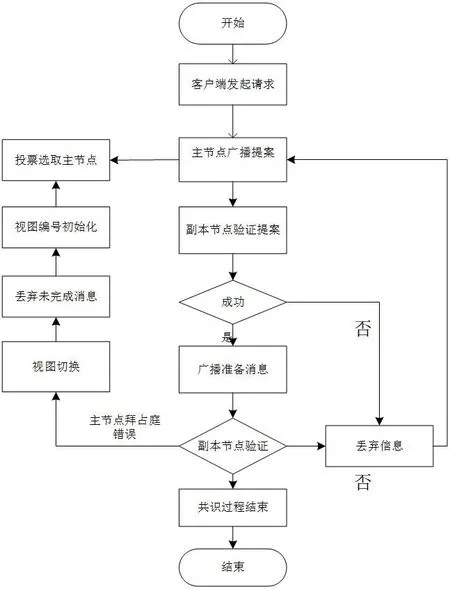
圖4:算法整體流程
DPBFT 算法的總流程如下:
(1)備選主節點成功選舉
(2)request 階段:客戶端向主節點發提案消息。
(3)pre-prepare 階段:在此階段主節點向所有副本節點發送預準備消息;
(4)副本節點驗證收到的提案消息和主節點的狀態。如果接收的提案消息正確,進入階段;否則接受的提案消息被丟棄,轉到(2)。如果主節點發生拜占庭錯誤,視圖將進行切換,轉到(1);
(5)prepare 階段:向所有副本節點發送準備消息;
當某個節點收到超過2f+1 準備消息并且完成驗證,告知客戶端發送共識達成,否則跳轉到(1);
(6)reply 階段:若有f+1 個副本節點向客戶端進行了反饋,則認為系統共識達成。
3 實驗驗證及分析
本次實驗測試的是在系統運行一段時間后觀察PBFT 算法和DPBFT 算法中共識節點和拜占庭節點數。實驗將傳統PBFT 和改進后的算法中共識節點設置為10 個(包含3 個拜占庭節點);另外在候補集合中添加3 個節點,在實驗開始前候補集合中不設置拜占庭節點。實驗結果如圖5 所示。
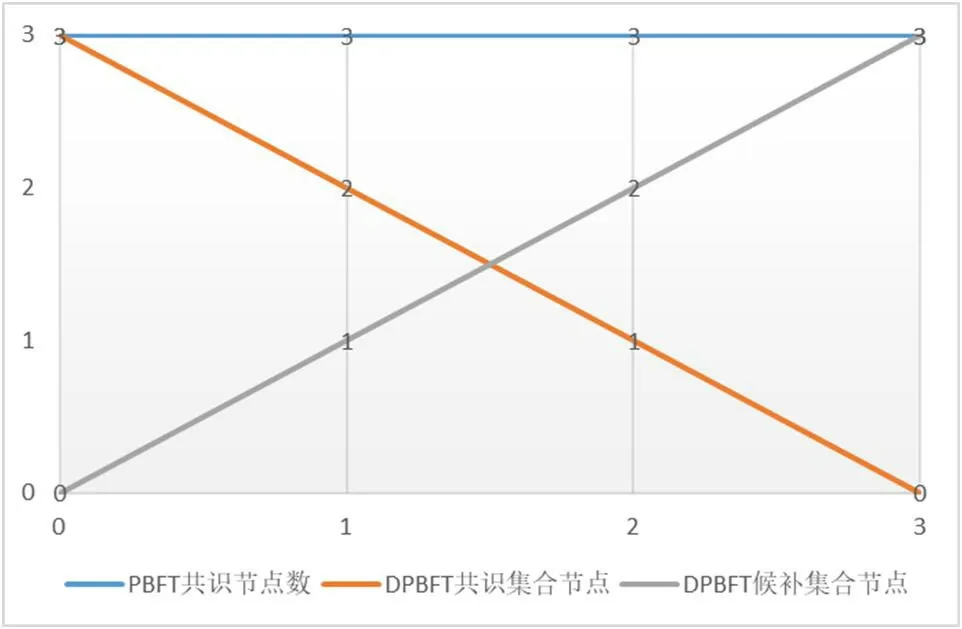
圖5:算法效率對比實驗
分析實驗結果可知,當系統完成3 次視圖切換后,PBFT 算法中拜占庭節點的個數始終為3。而DPBFT 算法共識集合中的拜占庭節點在每次視圖切換完成后都會添加到拜占庭節點候補集合中,此時候補節點中的拜占庭節點會加1。直到三次視圖切換完成,PBFT 算法中的拜占庭節點全部轉移到候補節點中。
4 總結展望
本文針對PBFT 算法中節點網絡無法動態變化,提出一種動態性的共識算法DPBFT( Dynamic Practical Byzantine Fault Tolerance)。改進的算法通過增設額外的候補節點集合,在新增的候補節點中進行備選主節點的選取,當主節點出現拜占庭錯誤時,使用候補節點集合中的備選主節點進行替換,使系統中共識節點的數量可以動態增加或減少。
下一步將在DPBFT 算法的吞吐量上進行研究探索,在不影響系統共識效率的基礎上增加吞吐量,使其可以更好的應用商業領域中。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
