基于一種文件緩沖方式操作大數據量數據研究
2021-06-16 05:29:24鄭士芹
電子制作 2021年4期
鄭士芹
(北京信息職業技術學院,北京,100081)
0 引言
大數據作為人們普遍認知的概念,帶給整個社會發展一種前所未有的便利。當前大數據的發展速度取決于人類對于數據需求的一種反應,人類需求量越大,對數據處理速度的要求也越高,隨著信息技術的高速發展,人類通過不斷的探索,對數據的收集和處理有了前所未有的進步,也研究出了多種高效的方式來存儲和讀取數據,來更好地滿足人們和社會的需要。一般來說,其常用的方式如下:一是表緩沖,將大數據中記錄數據進行集中讀取,存儲至內存后再對數據進行集中處理;二是行緩沖,將大數據中所需要的數據進行逐一讀取并立即處理,再存儲至內存中。但通過現有研究發現上述方法存在一定不足,因此本文針對大數據的特點和一種文件緩沖方式的數據處理方式進行闡述。
1 大數據量數據特點
當前,大數據技術正在引導著這個社會的發展,從大數據的發展情況來講,可從數據本身和數據處理兩個方面來進行理解,將大數據分為狹義和廣義之分,狹義的大數據僅僅從字面理解,表征為數據的規模和形式,表征計量至少為PB、EB和ZB的數據規模,包括結構和非結構化數據,對于大數據量數據我們通過兩個方面進行理解,在橫向方面表征為數據量的大小,在這一角度來說,大數據是表示廣泛的數據量,表征為數據過多,規模巨大。在縱向方面進行理解表征為結構化數據,可分為結構和非結構化數據,表示為數據的多樣性和不確定性。而廣義的大數據不但包含數據的規模和形式,還要將數據的處理方式納入其中。
根據在前文中對于大數據的歷史發展和大數據時代背景所述,對于大數據的實質涵義我們有了更深的理解。因此,對數據進行合理的分類顯得尤為重要,將有價值的數據資源進行累計,而將不重要的數據進行驅替,可大大減少數據庫服務所帶來的高額成本,避免出現由于不必要的資源占用有限的數據庫空間,造成資源的浪費,導致系統出現緩慢的情況。不論從哪種角度出發,大數據的核心研究是數據的積累和處理,基于此項目的,高效的處理方式的研究將成為行業發展的關鍵。
2 大型關系數據庫適應領域及技術原理
隨著信息化建設的不斷發展,大型關系數據庫在各行各業中得到深度的推廣和應用,定制功能和專項服務使得這一技術更好的在各個領域中發揮著不可或缺的力量,進而使得用戶數量和業務不斷提升,導致人們對數字信息化服務需求不斷上升,大數據量數據也不斷上升。進而引發的結果導致在數據的采集、響應的速度、計算的速度和存儲能力方面出現了一定的壓力。在以上所述的方面中,數據模塊的研發者通常對數據模型關系、數據的表現方式、數據的管理、編寫的方法、數據的存儲位置以及數據的存儲大小采用文件緩沖方式進行結構設計。2001年,高德納咨詢公司將大數據進行歸納總結為巨量、速度和多樣性,由此可以看出,早在大數據發展之初,人們早已意識到數據的數量之大。
在大數據提供了豐富數據的同時,人們對于數據響應的要求也越來越高,這也為數據存儲方式提出了更為苛刻的要求,不再僅僅滿足存儲數量的同時,還對反應速度有了一定的要求。這也就要求國內外學者在對大數據量數據處理方式的研究上提出了更高的挑戰,以滿足人們對于數據反應時間控制在可接受的范圍之內,通過對大數據量數據的處理方式和存儲方式進行同時擴展,達到在高速增長的數據量的同時保證響應的目的。另外,大數據可應用于不同的服務對象,來自設備的大量數據進行實時分析成為重要的需要,不同的用戶在數據倉庫方面存在多維分析處理的問題。
大數據管理架構如圖1所示,通過對大數據管理架構分析來可進一步了解大數據存儲的方式和處理技術。在圖1左側可以看到,原始數據通過數據抽取和預處理,將用戶需要數據進行必要的分析處理后的數據從原始文件中進行抽取提供給用戶,對于大數據中頻繁使用的數據進行分析處理,將這些必要的數據抽取至上一層數據庫中以便更快的分析和供用戶使用,達到提高效率的目的。圖1右側則表示為由上向下的存儲方式,在響應各行各業大數據的應用中,需提供大量的數據支持,進行存儲和處理,在自上而下的過程中內存數據庫中的數據進行抽取并分析處理,然后將超過分析時間的數據下移至磁盤存儲引擎以便更好地對歷史數據進行訪問和分析,當數據量超過存儲量時,將多余的數據量轉存至底層存儲系統中。在當前這種存儲結構下,分析數據所采用的是順序訪問的分析方法,內存數據庫成為高性能存儲和處理引擎從而保證將導入的數據進行快速的分析和處理,以滿足所需。
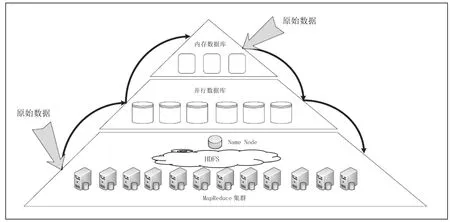
圖1 大數據管理架構
如圖2所示,表現出數據庫是一個數據共享訪問平臺,包含完整的用戶信息管理、用戶訪問權限、數據管理等,為結構化數據的處理提供了良好的基礎,但缺乏對非結構化數據的管理和處理能力,數據存儲沒有進行有效的分類,因此針對數據庫的自身特點,分析數據量的大小、訪問的頻率、數據增長的速度、數據的流向等特點,對數據進行及時有效的分類,進而根據數據的不同設計所對應的存儲方式和處理方式,可更快地提高訪問效率。
圖2 數據共享訪問順序圖
3 操作大數據量數據分析應用
大數據的有效應用暴露出了對于傳統數據庫分析和管理方式在某些領域存在的種種問題,如缺少針對行業所存在問題所提出的針對性的數據處理方式,缺少對大規模數據量的計算保障,缺少對于用戶需求的靈活選取等問題。針對在數據處理方面出現的問題,在對所獲取的數據進行挖掘和關聯分析的時候采用文件緩沖的方式進行數據量的數據研究,其基本操作過程是,先將所需要處理的數據庫中的記錄進行讀取存儲在臨時文件中,通過將所存儲的數據庫在臨時文件中進行合理的處理,處理結束后將臨時文件進行刪除,將有效的數據進行逐一記錄至內存中。通過采用計算機對文件緩沖方式進行數據處理,其部分程序如下:

通過此方法,在數據挖掘和處理上取得了良好的效果,主要是由于在整個數據處理過程中,需要多次進行計算,僅僅只要讀取數據而不會對數據進行更改、刪除和插入等操作。
4 結論
大數據作為當前時代發展的重要趨勢之一,對于數據庫的管理以及大數據量數據的處理方式的研究尤為重要。針對當前大數據的發展中所提出的問題,本文所采用的處理方法也達到了一定的優化效果,希望為后期大數據量數據處理研究方面提供一定的經驗參考。
猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
