基于LMD信號重構和支持向量機的柱塞泵故障診斷分析
2021-06-16 00:27:12洪曉藝翟東媛喬慶鵬
液壓與氣動 2021年6期
洪曉藝, 翟東媛,喬慶鵬
(1.新鄉職業技術學院,電子信息系,河南 新鄉 453006;2.湖南大學,電子信息工程系,湖南 長沙 410082;3.河南財政金融學院,人工智能學院,河南 鄭州 450046)
引言
柱塞泵屬于當前工業生產領域獲得廣泛使用的輸送泵,具備運行過程穩定并可以達到高壓高效率的性能[1-3]。但考慮到柱塞泵的組成結構較復雜,并且通常都是處于長期高速運轉的狀態,較易發生表面磨損與松靴磨損的問題,從而引起安全事故[4-5]。最初對柱塞泵開展故障診斷時通常需要通過技術人員根據之前經驗進行判斷,之后升級為可以通過參數測試的方法完成診斷過程,現在已能實現智能診斷的功能。其中,智能診斷是從柱塞泵殼體與端蓋位置獲取振動信號,之后通過系統分析柱塞泵的工作狀態[6-8]。目前,對這方面開展研究的學者也較多,任立通等[9]采用隨機共振方法處理振動信號,對振動信號頻率進行增強后獲得更高的信噪比,由此提升了準確度,采用上述方法診斷非線性特征時獲得了理想的診斷效果,不過需要較長計算時間,算法處理過程太復雜。胡晉偉等[10]利用超限學習機對柱塞泵進行滑靴磨損故障診斷,先對振動信號實施預處理,再提取得到特征向量,將其輸入到超限學習機并診斷滑靴磨損程度。袁兵等[11]綜合運用集合經驗模態分解和SVM的方法,準確診斷得到滑靴耳軸磨損、柱塞泵滑靴磨損以及球頭松動情況。張華等[12]同時采用SVM和符號動力學信息熵的方法構建得到信息熵特征集,實現了對液壓泵的不同類型故障識別功能,但采用此方法需要經過復雜的診斷過程,花費較長的學習時間,并且整體流程太復雜,由此降低了診斷效率。
本研究用LMD對診斷流程進行了簡化處理。為了對重構信號特征提取優勢進行分析,在SVM中輸入原始信號與重構信號特征數據集,之后比較了訓練和診斷所得結果。
1 局部均值分解(LMD)原理
LMD可以通過自適應的方式把復雜振動信號分解成不同物理分量的組合結果,獲得信號本質特征,有效克服端點效應,避免發生模態混疊情況,降低迭代次數,獲得更完整信號信息,更適合分解非線性柱塞泵故障信號[13-14]。
算法計算流程如下:
(1) 根據信號x(t)確定各個極值點,之后計算相鄰極值的均值。計算得到信號x(t)包絡估計值,然后通過滑動平均方法處理2條折線,達到平滑的效果,由此得到局部均值函數m11(t)以及包絡估計函數v11(t)。
(2) 將信號x(t)中的m11(t)去除:
d11(t)=x(t)-m11(t)
(3) 以d11(t)和v11(t)相除獲得s11(t)。
s11(t)=d11(t)/v11(t)
從理論層面分析可知,s11(t)屬于純調頻信號,對應的包絡估計函數v12(t)為1,當v12(t)不為1時,則以s11(t)代替信號x(t)再重新執行以上過程,最終獲得純調頻信號s11(t),滿足-1≤s11(t)≤1,對應的包絡估計函數v12(t)為1。
進行實際運算時,通常會設置更寬的迭代終止條件,對于一個微小量Δ,存在以下的迭代終止條件:
1-Δ≤v1n(t)≤1+Δ。
(4) 對上述所有包絡估計函數乘積處理,得到以下包絡信號v1(t):
(5)s1n(t)與v1(t)乘積屬于原始信號分解得到的首個PF分量。
PF1(t)=s11(t)v1(t)
以包絡信號v1(t)表示PF1瞬時幅值,通過處理純調頻信號s1n(t)獲得瞬時頻率。
(6) 將原信號x(t)的第一個PF分量去除,以u1(t)作為輸入信號繼續執行以上過程,經過k次循環處理直到uk成為單調函數停止,得到以下表達式:
圖1給出了LMD計算過程的具體流程。
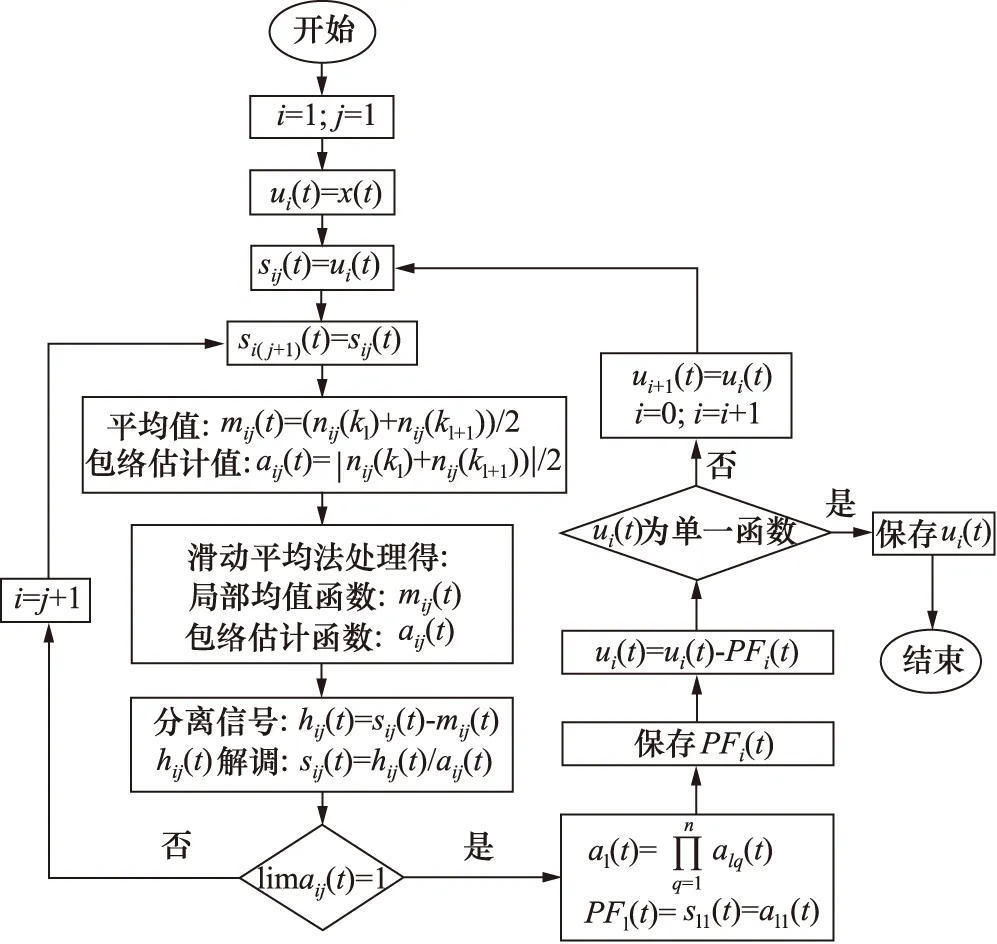
圖1 LMD流程圖
2 柱塞泵故障特征提取
2.1 柱塞泵特征數據集
柱塞泵的故障類型主要包括配流盤磨損、柱塞磨損、滑靴磨損等形式[15-16]。采用常規信號處理方式不能精確反饋故障信號特征,無法區分故障類型。本研究采用加速度傳感器處理柱塞泵X軸方向的信號,柱塞泵振動信號采集方式如圖2所示。選取A10VS045型柱塞泵作為試驗對象,通過放置于泵殼體上的加速度傳感器采集振動信號。從中提取得到信號特征,先對采集獲得的5種狀態振動信號實施LMD分解與重構,并以重構信號樣本熵和原始信號標準差構成故障特征向量再從中提出得到特征參數。圖3給出了柱塞泵故障特征的具體提取流程。

1.電動機 2.柱塞泵 3.單向節流閥 4.壓力表5.溢流閥 6.過濾器 7.油箱 8.加速度傳感計圖2 柱塞泵振動信號采集示意圖

圖3 特征提取基本流程圖
對振動信號采集得到150個樣本,各樣本包含了約3500個數據,一種狀態包含150組特征向量,以隨機方式選擇100組訓練樣本,再對剩余50組樣本進行測試。表1給出了特征數據集。

表1 柱塞泵特征數據集
2.2 故障信號分解與重構
將工作壓力設定為10 MPa情況下,再對去噪處理后的柱塞泵處于正常、柱塞磨損、配流盤磨損、滑靴磨損與松靴磨損狀態下的信號實施LMD分解,對各工況振動信號進行分解得到5~6個PF分量。對松靴磨損故障LMD分解得到如圖4所示的時域,結果顯示,最初幾個PF分量中存在原始信號,只形成了很小的PF5與殘余量,因此可以判斷其屬于噪聲成分。對LMD分解過程進行分析可以發現,PF分量屬于原始振動信號一部分,體現了信號頻率部分。當PF分量中含有原始振動信號有效特征頻率成分時,則存在較強相關性,虛假分量只存在少量有效特征頻率,對應的相關性也較弱。此時可以通過相關系數法處理分解后的PF分量和原始振動信號,以低相關性的分量作為噪聲信號,同時重構高相關性的分量。

圖4 松靴磨損信號LMD分解圖
選擇具備較高有效特征頻率成分的PF分量實施重構,同時以PF分量和原始信號相關系數均值達到0.01的PF分量實施信號重構。按照同樣的方式獲得其余4種狀態對應的重構信號。為確保重構信號滿足有效性,測試了重構信號和原始振動信號的相關性水平,得到表2所示的各狀態重構信號和原始信號之間的相關系數,結果顯示,每種狀態重構信號和原始信號之間的相關系數都達到0.9以上,說明重構信號內已經含有原始信號主要信息。
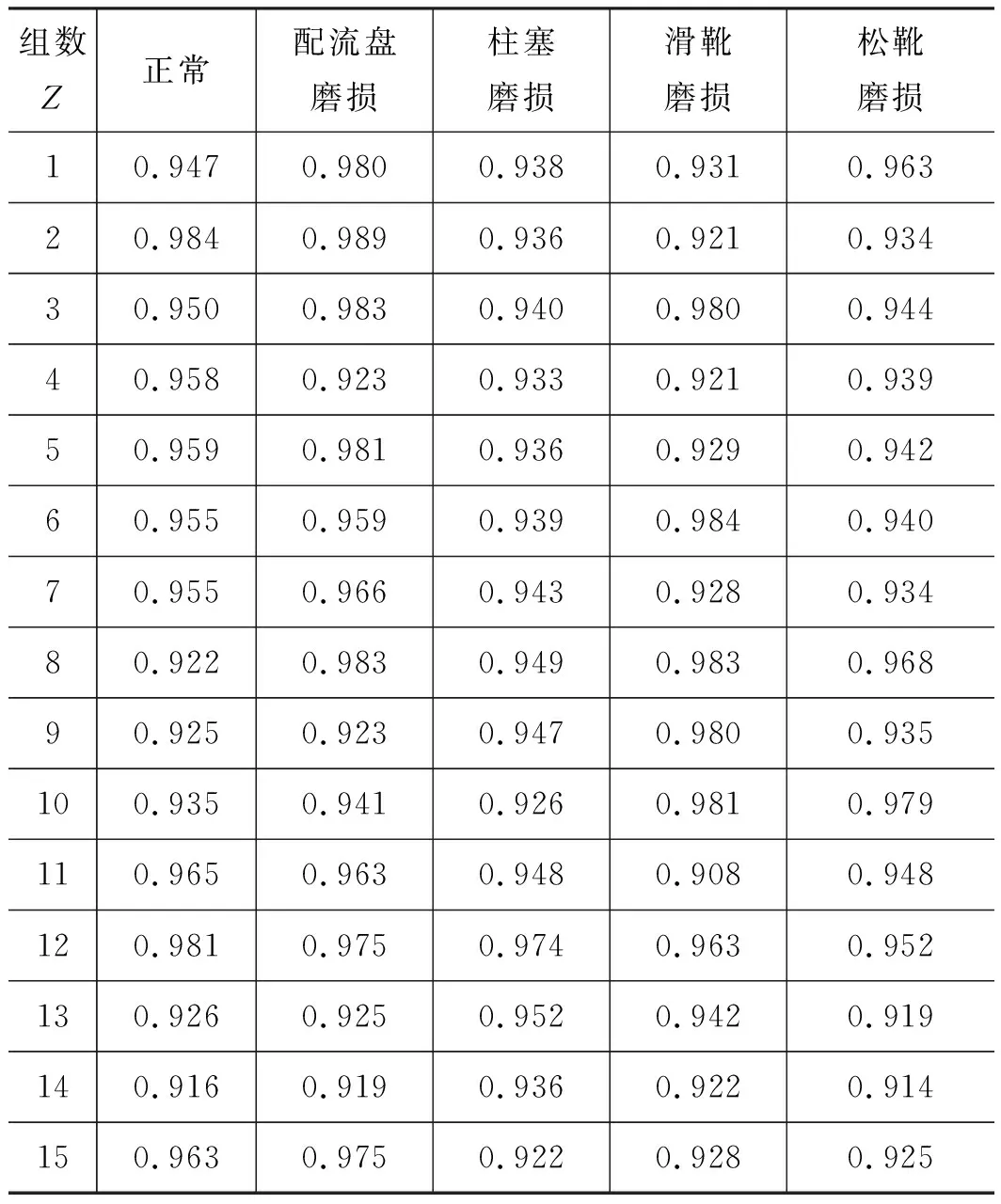
表2 重構信號與原始信號相關性
2.3 故障特征提取
圖5給出了對柱塞泵5種工作狀態下形成的振動信號進行預處理得到的樣本熵值ζ曲線,結果顯示,正常、松靴磨損與滑靴磨損狀態下的原始信號發生了混疊情況。圖6是利用LMD對柱塞泵各工作狀態下形成的振動信號分解重構得到的樣本熵值。通過對比發現,對滑靴磨損、柱塞磨損、正常狀態下的振動信號進行LMD分解與重構處理后獲得了不同的樣本熵值,便于對其快速區分,同時發現配流盤磨損與松靴磨損間發生了輕微混疊。各狀態重構信號樣本熵形成了比原始信號樣本熵更優的分布狀態,說明LMD重構信號可以減弱噪聲對故障特征提取造成的影響。
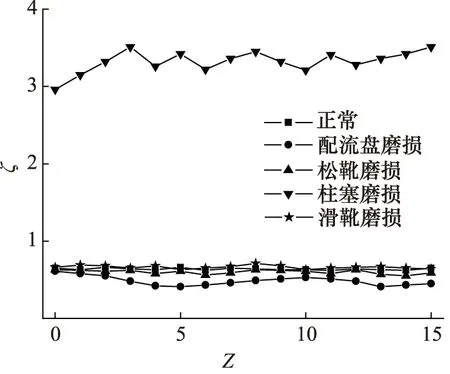
圖5 原始信號樣本熵值
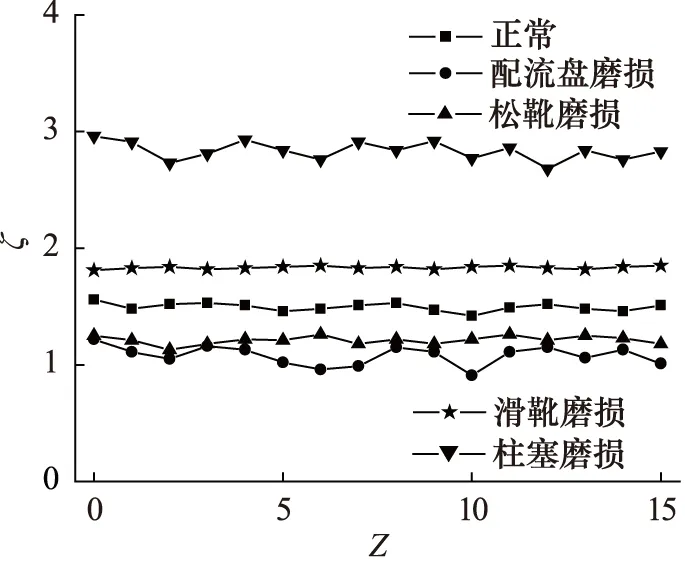
圖6 重構信號樣本熵值
3 故障診斷與對比分析
3.1 SVM多類分類器的構建
選擇柱塞泵的同一種故障樣本組成一類,以1進行表示,以剩余4種狀態樣本組成另一類,將其表示成-1。構建得到4個二分類器,分別為SVM1,SVM2,SVM3,SVM4,通過二叉樹的方式對4個二分類器組合,建立得到能夠對柱塞泵5種狀態進行識別的SVM多類分類器,結果見圖7。
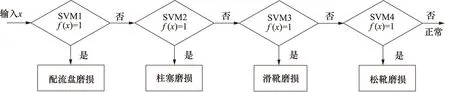
圖7 SVM多類分類器流程圖
3.2 柱塞泵故障診斷
圖8給出了對數據集進行訓練測試所得結果,各組樣本對應的類別B如下:正常狀態包含0~40組,配流盤磨損包含40~80組,柱塞磨損包含80~120組,滑靴磨損2.5 mm包含120~160組,松靴磨損包含160~200組。根據圖8可知,200組樣本中只2個樣本(柱塞磨損和松靴磨損)發生了識別錯誤,準確率高達99%,表明以SVM多類分類器可以獲得較高故障識別診斷準確率。

圖8 基于SVM的柱塞泵五種狀態預測分類
3.3 對比分析
為了測試重構特征數據集有效性,在SVM多類分類器算法中輸入重構信號特征向量數據集,再將其與原始信號集診斷結果進行對比,結果見表3。由表3可知:相對于原始信號,LMD重構信號達到了更高的訓練準確度與測試準確性,表現出很好的計算精度。表明本研究LMD重構信號特征方法在處理柱塞泵故障診斷方面具有很好的效果。
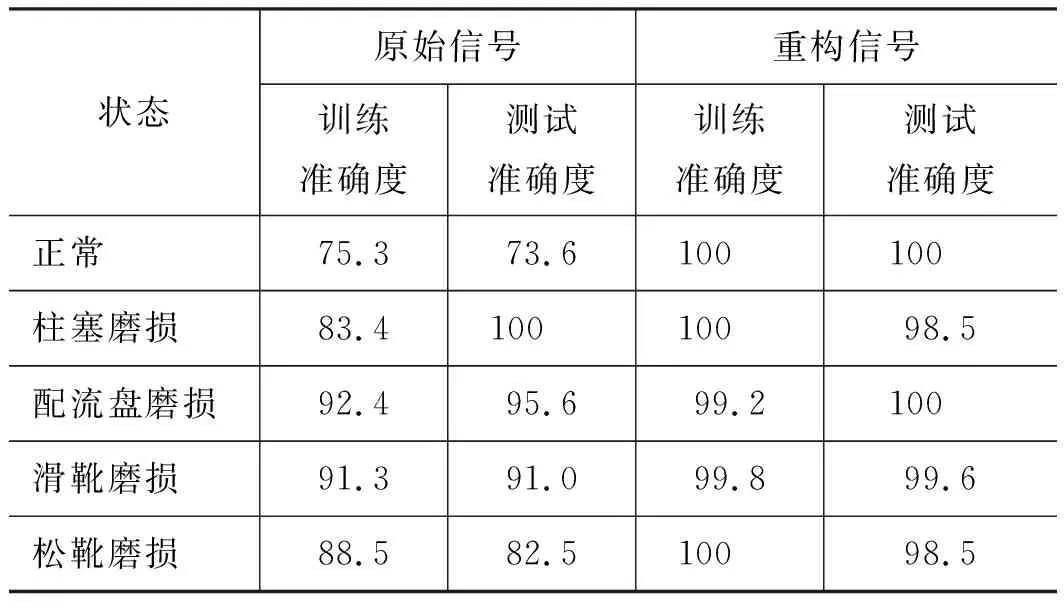
表3 準確度結果對比 %
4 結論
(1) 每種狀態重構信號和原始信號之間的相關系數都達到0.9以上,說明重構信號內已經含有原始信號主要信息。各狀態重構信號樣本熵形成了比原始信號樣本熵更優的分布狀態,說明LMD重構信號可以減弱噪聲對故障特征提取造成的影響。
(2) 200組樣本中只2個樣本(柱塞磨損和松靴磨損)發生了識別錯誤,準確率高達99%,表明以SVM多類分類器可以獲得較高的故障識別診斷準確率。相對于原始信號,LMD重構信號達到了更高的訓練準確度與測試準確性,表現出很好的計算精度。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
天天愛科學(2020年6期)2020-09-10 07:22:44
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年11期)2018-08-04 03:25:42
數學物理學報(2017年6期)2018-01-22 02:26:40
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
汽車維修與保養(2015年6期)2015-04-17 03:31:50
