核主成分-k近鄰算法在心臟疾病分類中的應用研究
2021-06-23 00:30:48魏毅強
中西醫結合心腦血管病雜志 2021年11期
胡 揚,魏毅強
據世界衛生組織統計,目前全球范圍內包含心血管疾病在內的心臟病導致每年死亡人數將近2 000萬人,由國家心血管病中心組織編撰的《中國心血管病報告 2018》(2019年4月)指出:我國心血管病患病率持續上升,心血管病現患人數推測有2.9億人。心血管病死亡率仍居首位,高于腫瘤及其他疾病,每5例中就有2例死于心血管病,且農村死亡率高于城市。同時更令人擔憂的是發病年齡也呈現出年輕化的趨勢,形勢非常嚴峻。誘發心臟病的風險因素很多,包括心臟病家族史、吸煙、膽固醇、高血壓、肥胖和缺乏鍛煉等,而治療該類疾病最好的方法是預防,關鍵在于早發現、早診斷和早治療。如何有效預防心臟病,對潛在患病人群進行準確檢查診療,具有重要的理論和現實意義。
近年來,隨著信息與大數據技術的應用,使得數理醫學在疾病診斷與預測領域取得了長足的進步和飛速的發展。在數據處理方面,很多學者都采用核主成分分析(KPCA)方法對數據進行核變換及降維,Deng等[1]提出了一種增強的KPCA方法,從而可以更好地挖掘數據的信息;Chen等[2]通過KPCA提取數據主要特征進行降維;Long等[3]通過KPCA提取缺陷的主要特征使得分類效果明顯提升;Xie 等[4]處理高維數據時使用了KPCA來降維。在疾病分類方面,Fan等[5]將KPCA與AdaBoost等算法結合提高了阿爾茨海默病病人的分類正確率;Choi等[6]通過卷積神經網絡對大腦磁共振圖像進行分析,從而對老年癡呆癥病人進行分類;Shankar等[7]用多核向量機提高了甲狀腺疾病分類的準確率和靈敏度;Tufail等[8]構建了多個深度二維卷積神經網絡,從局部大腦圖像中學習不同的特征,并結合這些特征進行最終分類,用于阿爾茨海默病的診斷。Deng等[9]基于改進的Mel-frequency倒譜系數特征和卷積遞歸神經網絡對心音進行分類;Chen等[10]通過改進的頻率小波變換和卷積神經網絡對心音進行高效分類;Yang等[11]通過決策樹、隨機森林和人工神經網絡方法對主動脈狹窄進行分類;Soares等[12]提出了一種新的擴展零階自主學習多模型神經模糊方法,可以通過心音對不同的心臟疾病進行分類;Tang等[13]使用旋轉線性核支持向量機分類器對心律失常進行分類;Wang等[14]提出了對偶全連接神經網絡模型來對心律進行精確分類;Wang等[15]對心律失常的分類也提出了一種改進的卷積神經網絡模型并得到了很好的結果;Bzl等[16]不僅提出了一種新的基于深度剩余網絡的心律失常深度學習分類方法,還使用二聯導心電信號結合深度學習方法來自動識別5種不同類型的心跳。以上研究雖然對心臟疾病的診斷和分類有不少幫助,但由于心臟數據的復雜性、特殊性、高度非線性等因素導致對于疾病的準確判斷比較困難。
本研究以描述心臟單質子發射計算機斷層掃描數據集為基礎,該數據集有267個病人樣本,每個樣本有44個連續特征模式并被分為正常和異常。但由于數據非線性而且維數較高,給正確分類造成很大困難和影響。本研究通過核主成分將數據集進行核變換和降維,從而去掉非線性影響并降低分類難度,經過核變換后的數據集進行正態分布檢驗。由于高斯徑向基的參數難以選定,本研究采用非參數統計中的Friedman秩方差分析法對參數的取值進行了檢驗,并最終選擇了最合適的參數值。選定參數值后,在此基礎上選用k近鄰(KNN)分類方法對267例病人進行分類,并與未進行核變換的主成分分析-k近鄰(PCA-KNN)方法比較結果,可以看出本研究提出的方法得到了較好的性能提升。
1 核主成分分析
1.1 主成分分析 信息維數過高是處理多特征數據最大的挑戰之一,多數情況下不同特征變量之間都具有一定的相關性。主成分分析是一種最為常見的數據降維方法,它可以將大量具有相關性的變量線性組合成一些不相關的新變量,同時還能盡可能保留原始數據集的大部分信息,這些新變量就叫做主成分。主成分分析的應用十分廣泛,比如人臉識別、聲音識別、綜合評價等。通過主成分分析,可以簡化問題的處理難度,并且提高工作效率。

1.2 核主成分分析 主成分分析僅僅是原始特征變量的線性組合,適用于具有線性特征的數據集,在處理非線性問題時往往不能達到很好的效果,而核主成分分析可以較好地對非線性問題進行線性化并降維。KPCA將輸入空間中的數據通過映射φ映射到高維特征空間中,使映射后的數據集在高維特征空間中是線性可分的。核主成分犧牲的是維度,通過不同的核函數進行映射,再對特征降維,進行主成分分析。
常用的核函數有以下3種:
①q階多項式核函數
K(Ai,Aj)=[(Ai,Aj)+1]q
②線性核函數
K(Ai,Aj)=(Ai,Aj)
③高斯徑向基(RBF)核函數
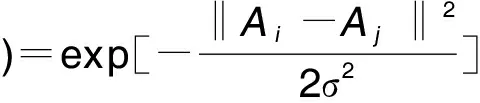
KPCA實現的優良程度取決于核函數的選取。多項式核函數適用于圖像處理,線性核函數適用于線性可分且特征數量較多的情況,高斯核函數是最常用的核函數,具有良好的局部特征提取能力和平滑特性。本研究選取的是高斯徑向基核函數(RBF)。
將原始數據空間變換為特征空間,并在特征空間中對數據進行主成分分析,本研究中僅選取第一次貢獻率達到97%的主成分個數。
2 k近鄰方法
k近鄰方法是有監督的機器學習分類算法之一[17-19]。在k近鄰方法中,事先確定k值、距離度量等并提前準備好訓練集及測試集,通過訓練集把特征空間劃分成一些子空間,訓練集中的每個樣本占據其中一部分空間。當k=1時,是k近鄰的特殊情況,也被稱為最近鄰。在最近鄰中,當測試樣本落在某個訓練樣本的子空間內時,該測試樣本就劃分為這個訓練樣本所屬的類別。 當k>1時,給定訓練數據集X,對于測試數據Y,在X中找到與之距離最近的k個樣本,在這k個樣本中,若大部分樣本屬于某一類S,則將Y歸為S類。最常用的距離度量是歐式距離,也有Manhatan距離,Minkowski距離等。
k值的選擇十分重要,會對其分類結果產生重要影響。k值選擇較小,則整體分類模型就會變得更加復雜,容易產生過擬合現象;k值選擇較大,整體分類模型會過于簡單,分類結果正確率容易降低。k值的選擇一般為奇數,避免出現無法判斷的情況。通過在訓練數據集上的分類結果正確率顯示,k=3時分類效果最好,因此,本研究中選取k=3。
3 Friedman秩方差分析法
設一共有t個處理和b個區組,首先在每1個區組內排秩,得到表1。

表1 完全隨機區組秩排序表(Rij)
其中Rij為第i個處理中第j個區組的秩。
進行假設檢驗:
H0:各個處理中無差異;
H1:各個處理中有差異。Friedman統計量為:
(1)
(2)
Friedman檢驗依賴于每個區組內所排列的秩的大小,對試驗誤差沒有正態分布的要求。
4 實例分析
本研究選取了描述心臟單質子發射計算機斷層掃描的SPECIF數據集,該數據集有267個病人樣本,每個病人有44個連續特征變量,并被分為兩類:正常和異常。從中選取部分作為訓練集,余下的作為測試集,對其進行核主成分-k近鄰分類。
首先,將訓練集T標準化以消除量綱帶來的影響,然后進行核變換。由于高斯徑向基的參數難以選定,對核參數分別選取了240,600,1 000參數,分別采用Fisher判別,k近鄰,Logistic回歸3種分類方法進行試運算,將得到的9個心臟疾病分類正確率進行比較。可以看出在同一種分類方法中,心臟疾病分類的正確率對于核參數的選擇是魯棒的[20]。隨機選取18個2σ2的不同取值,分別為240,300,360,400,420,480,500,540,600,660,700,720,780,800,840,900,960,1 000。核變換后進行主成分分析,分別使用了Fisher判別,k近鄰分類,Logistic回歸(臨界概率值選為0.5)對不同參數下的主成分分析的結果進行心臟疾病分類,得到了在18個不同參數下的3種分類方法的正確率。通過表2可以看出k近鄰分類方法的正確率高于其余兩種。
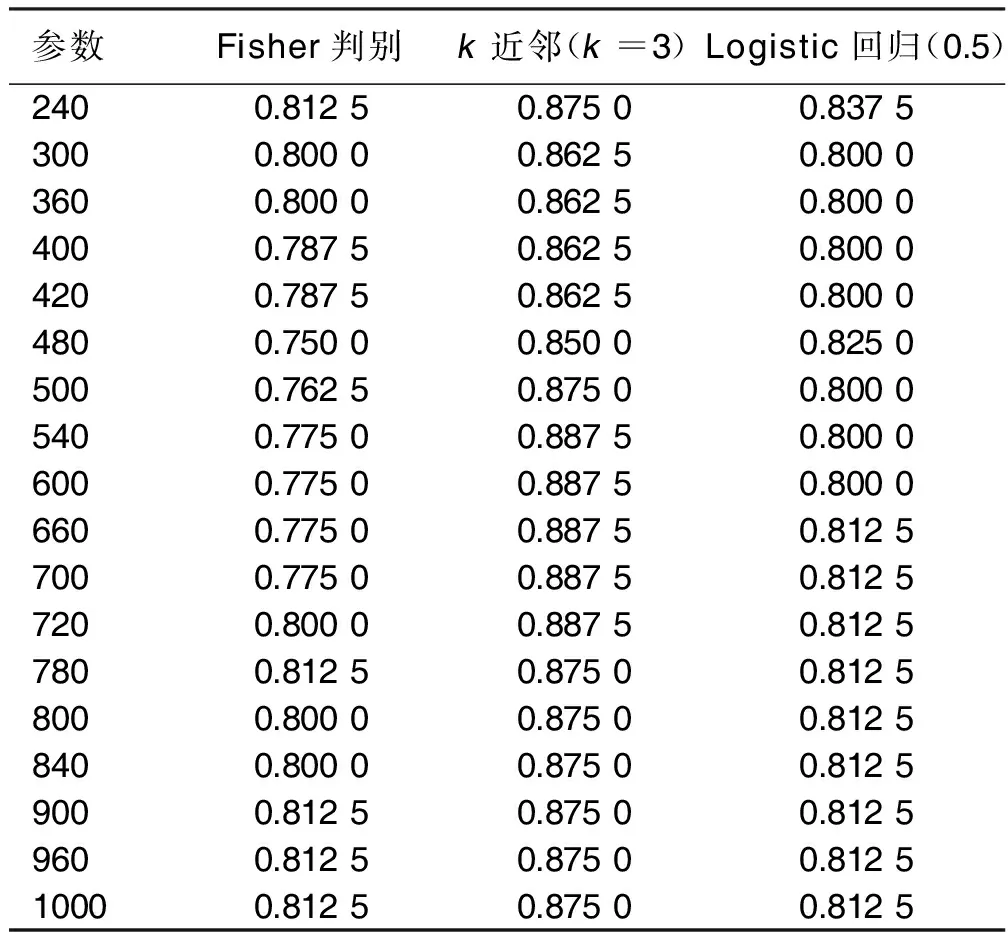
表2 在不同參數下的3種分類方法的正確率
得到表2后對其數值進行排秩,得到表3,從表3中看到有相同秩,因此,Friedman秩方差檢驗中選用c統計量。由表3可以計算得到c27.587。接受H0,即認為各個參數之間的正確率無差異。在k近鄰心臟疾病分類結果中選取正確率最高的且主成分個數最少的參數,即2σ2=720,其中訓練集的主成分個數為5。
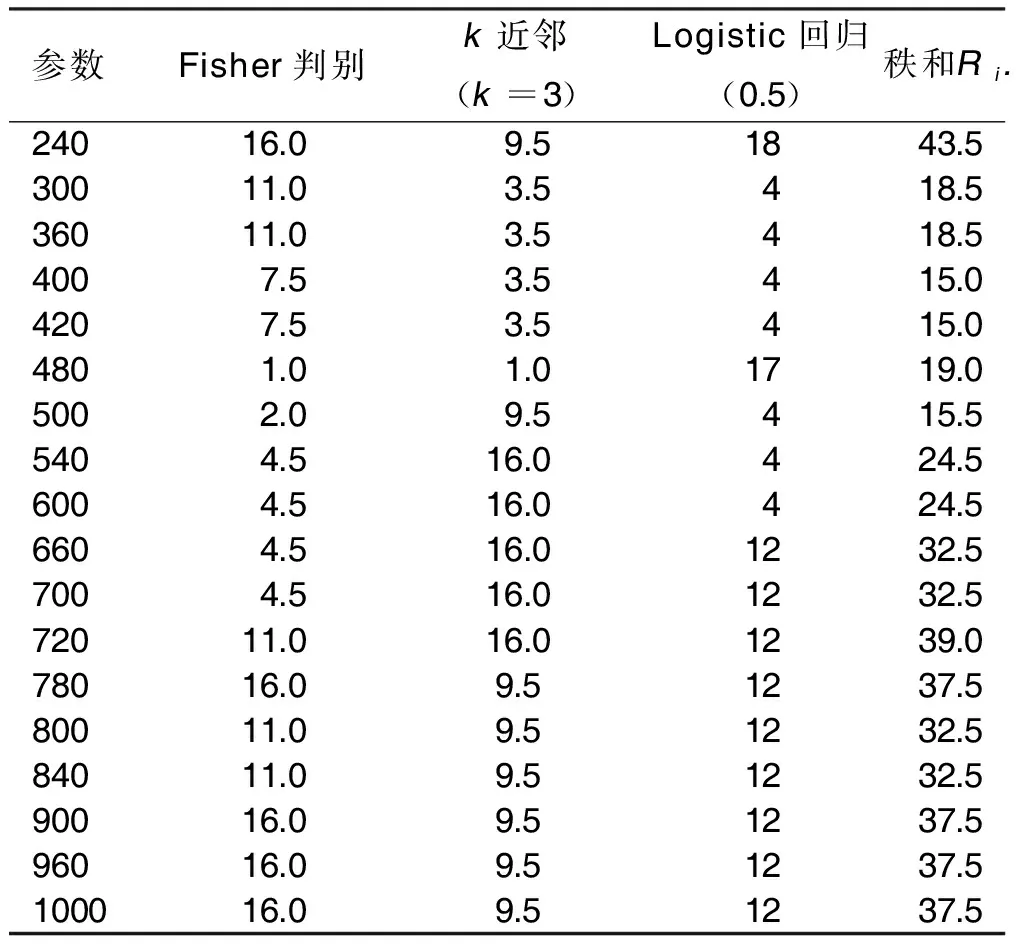
表3 在不同參數下的3種分類方法的心臟疾病分類正確率秩排序
選定參數及分類方法后,將其用于心臟疾病分類測試集M。通過高斯徑向基核函數將M進行變換,并且通過R中MVN包對變換后的心臟疾病測試集M′進行了多元正態性檢驗,如果測試集服從多元正態分布,則這些點應與直線有著較好的擬合。由圖1可以看出,這些點與直線的擬合并不是很好,由此可以說明變換后的測試集并不服從多元正態分布。
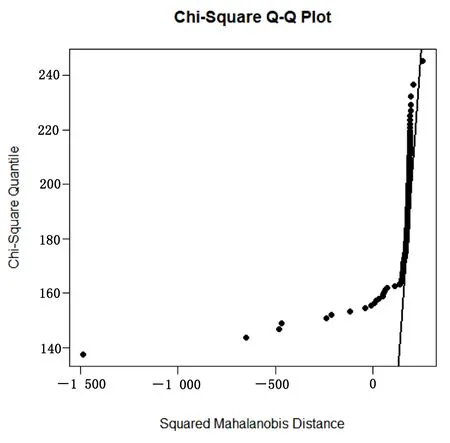
圖1 心臟疾病測試集M′的多元正態性檢驗
接下來對變換后的心臟疾病測試集進行主成分分析,主成分的個數為5。之后進行k近鄰分類,其正確率可以達到92%。如果直接使用主成分分析-k近鄰,其主成分個數在心臟疾病訓練集有25個,心臟疾病測試集達到28個,這使得計算代價大大提高。心臟疾病測試集上使用KPCA與PCA的結果(取前5個主成分)比較見表4。由表4可以看出,KPCA方法不僅僅主成分個數更少,僅需要5個主成分即可達到97%的貢獻率,且第一主成分的方差極大,表明KPCA中第一主成分所含信息量極多。而PCA前5個主成分僅僅達到了65%的貢獻率,并且一共需要28個主成分才能夠符合本研究97%的選擇條件,第一主成分所含的信息量也只能與KPCA的第二主成分相當。由此可以看出,KPCA的計算代價與PCA的計算代價相比很小。
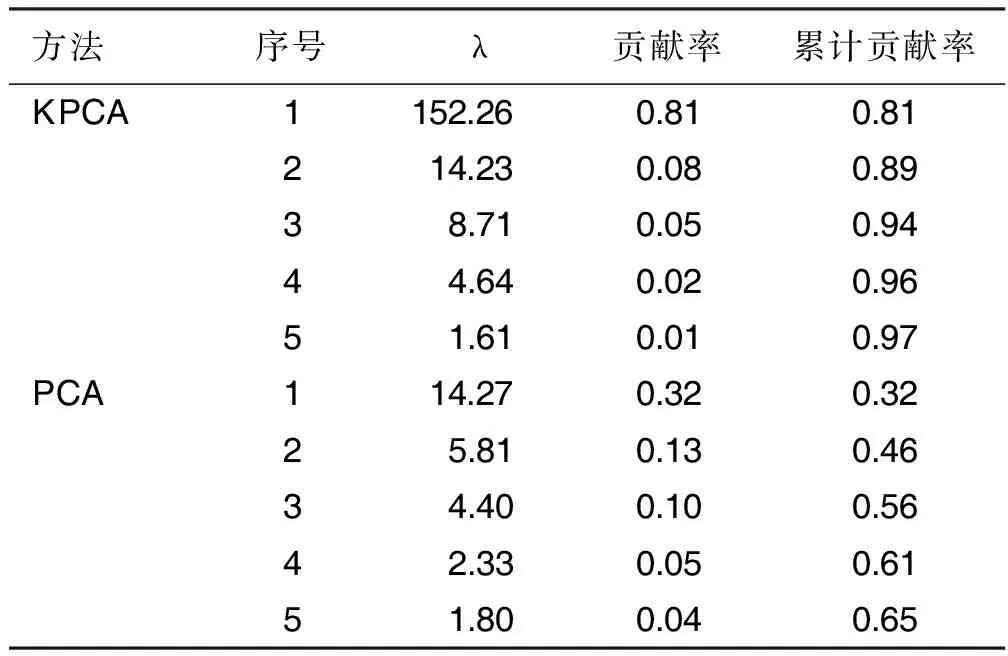
表4 KPCA與PCA結果比較
在心臟疾病訓練集上PCA的降維效果也不理想。心臟疾病訓練集中PCA需要25個主成分,而KPCA僅需要5個。心臟疾病訓練集上PCA的分類正確率僅有81.25%,而KPCA可以達到88.75%。詳見表5。
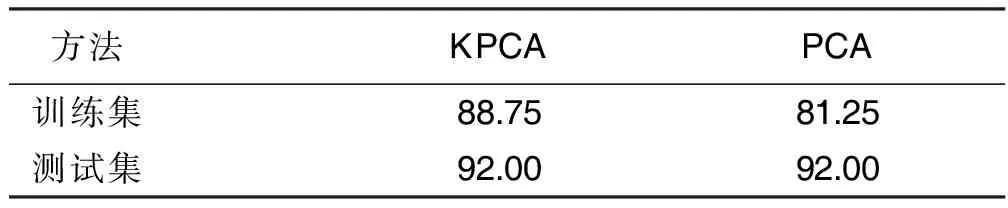
表5 心臟疾病數據集上KPCA與PCA的分類正確率 單位:%
不管是在主成分個數還是所含信息量,相對于PCA來講,KPCA的優勢非常明顯,其降維效果有顯著提升,極大地減小了心臟疾病數據集中非線性因素的影響,從而使后面的數據處理更加簡單快捷。
5 討 論
本研究基于KPCA-KNN方法對心臟疾病分類。
方法上,通過Friedman秩方差檢驗法對高斯徑向基核函數的參數進行了選取,使用了核主成分分析-k近鄰方法對心臟疾病數據集進行分類;理論上,通過Q-Q圖檢驗了核變換后的心臟疾病數據的多元正態性與高斯徑向基核函數參數的魯棒性;最后將KPCA-KNN方法應用于心臟疾病SPECIF數據集上,與PCA-KNN方法相比,可以看出KPCA-KNN方法對心臟疾病數據集分類降維效果較好,在心臟疾病測試集上其分類準確率可達92%,并且分類準確率比原始的CLIP3算法提高了15%。總體看來,在處理心臟疾病數據這一類非線性分類問題時,KPCA-KNN方法使得解決問題又多了一條有效的途徑。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
