
基于人臉識別的車輛安全系統*
2021-06-24 08:18:50黃原有張楊志
機電工程技術 2021年5期
黃原有,陽 韜,張楊志
(華南理工大學廣州學院,廣州 510800)
0 引言
基于人臉識別的車輛安全系統主要通過Jetson Nano人工智能處理器驅動攝像頭,采集駕駛位司機的圖片,通過4G模組將圖片信息上傳到云服務器端。服務器端將接收到的圖片采用Mctnn模型進行人臉的檢測,并將其轉化為灰度圖,保存圖片。最后,將司機的圖片導入訓練精度達到90%的模型進行圖片的預測,如若圖片的相似度為大于80%,識別為司機,否則將識別為陌生人。與此同時,服務器端將識別的記錄保存,并發出警報消息給車主的手機App和關閉汽車的能源電池,以提高車輛的安全性。目前發展的車輛安全系統[1],主要是采用一些傳感器監測車輛的駕駛狀態,反饋給后臺管理系統。而人臉識別[2]車輛安全系統,主要是基于卷積神經網絡對采集到的司機圖片進行模型的訓練,每一輪將預測訓練集圖片的值和圖片的標簽值進行比較,差值越小,模型的訓練精度越高,訓練好模型后保存。在實際應用中,則放入采集的司機圖片導入模型,進行匹配,識別司機是否為陌生人。因此,可用人臉識別安全系統來提高車輛的安全性,也可應用于一些大客車,識別駕駛司機是否為公司聘請的專業司機,以此來保證乘車人員的安全。
1 整體設計

圖1 系統整體設計
如圖1所示,基于人臉識別的安全系統,主要是通過Jetson Nano智能處理器驅動攝像頭,采集駕駛位司機的圖片,并通過處理器上的4G模組將圖片信息上傳到服務器,并保存原圖像,以便當識別司機為陌生人時,能獲取犯罪嫌疑人的證據。云服務端并將采集到的圖片信息導入模型進行圖片的匹配,當預測圖片的相似度小于80%,則認為是陌生人。服務器將通過4G模組發送識別失敗的信息給Jetson Nano智能處理器,Jetson Nano則通過GPIO串口將識別的結果發送給Stm32單片機。Stm32接收到識別的信息后將發送語音信號給語音模塊使其發出識別失敗的語音提示和報警聲,并發送控制信號給繼電器[3]關閉能源電池。除此之外,服務器端還會推送汽車被盜或者非法人員駕駛的預警信息給手機App,通知車主其車輛處于報警狀態。當預測照片的相似度大于80%,則識別為司機,服務器端發送識別成功信息給Jetson Nano智能處理器,隨后Jetson Nano將識別信息傳給Stm32單片機,單片機將使汽車的電源開啟,并發出識別成功的語音信號。
2 硬件設計
系統的硬件部分主要包括Stm32f407、Jetson Nano人工智能處理器、攝像頭、4G模塊、語音模塊、繼電器等。硬件系統只需用Jetson Nano人工智能處理器驅動攝像頭獲取駕駛位圖像信息,并將圖像的信息通過4G模塊上傳到云服務器進行人臉識別模型的訓練,最終用訓練好的模型來識別人臉圖片,輸出識別結果,并將信息回傳給Jetson Nano人工智能處理器。Jetson Nano則將識別結果信息轉發給底層的Stm32f407單片機。Stm32f407收到識別的結果后,將根據識別的結果來控制語音模塊和繼電器。若識別為司機,Stm32f407則通過GPIO發送語音信號給語音模塊使其發出識別成功語音提示,并且通過GPIO發送控制信號控制繼電器進而開啟控制能源電池。若識別失敗,Stm32f407則發送報警的語音信號給語音模塊,并發送控制信號給繼電器,關閉能源電池。
3 軟件系統設計
軟件系統的設計如圖2所示,系統正式投用之前需要錄入司機的人臉信息,進行模型的訓練[4]。首先攝像頭會以視頻的方式采集上萬張司機的照片,進行人臉檢測,并轉化成灰度圖,使得圖像的維度下降但能保留圖像的關鍵信息,這可以減少程序的計算量,提升運算速度。將其保存好后,則采用卷積神經網絡對圖片信息進行卷積、池化、全連接輸出、并與訓練集的標簽值進行差值比較,最后調整學習速率,再進行下一輪的學習,當預測值和標簽值接近時,則訓練停止。即模型訓練的精確度提高到85%時,則停止訓練,并保存模型。
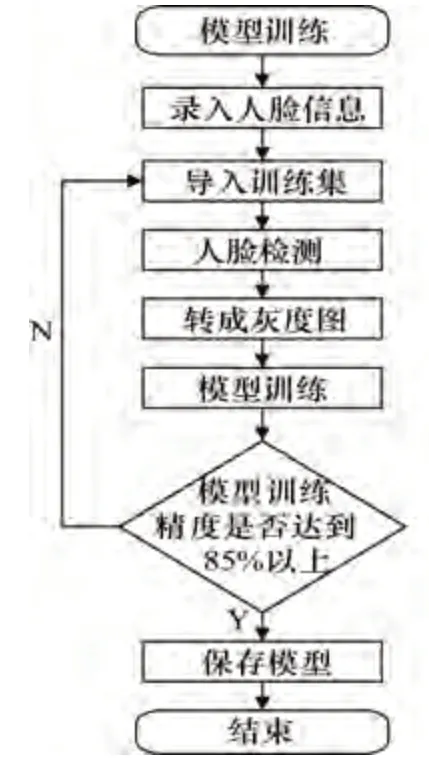
圖2 模型訓練流程
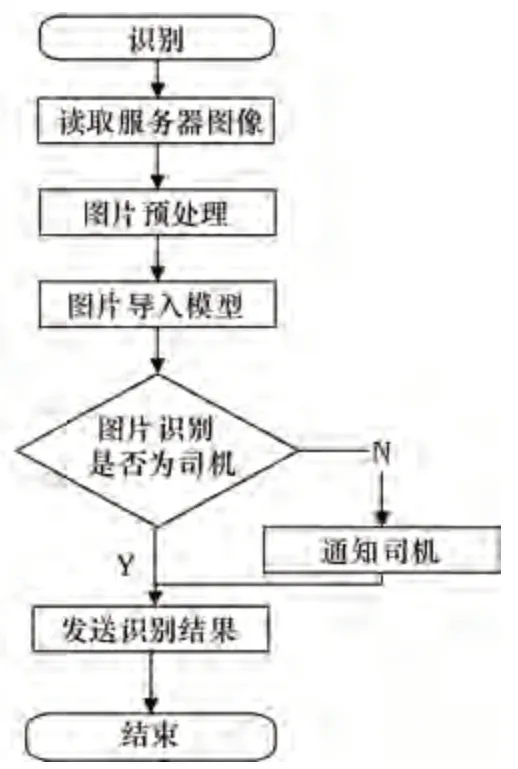
圖3 人臉識別流程
訓練完模型之后將進行人臉識別的過程如圖3所示,攝像頭會采集駕駛位的人臉圖片,并上傳到云服務器。程序則將讀取服務器上的圖像,采用Mtcnn模型進行人臉的檢測,并對圖片做進一步的處理后,并作為模型的測試集導入模型,進行圖片的人臉識別。若圖片中的人臉與司機相似度達到80%以上,認為識別成功,將識別結果發送給Jetson Nano人工智能處理器,使得底層的語音模塊發出識別成功的語音提示和開啟汽車電源,汽車啟動。否則識別為陌生人,推送消息通知司機陌生人進入車輛,并將識別的信息發送給Jetson Nano人工智能處理器,使系統發出識別失敗的警報聲并且關閉汽車的能源電池。
4 人臉檢測
對采集的圖片進行人臉檢測處理,采用了Mtcnn模型,最后輸出人臉的邊框位置。對于Mtcnn模型進行人臉檢測的過程如圖4所示。首先,將原圖片縮放成多個大小不同的圖片構成一個圖像金字塔。隨后將圖像金字塔的圖片傳入到P-net層,生成多個人臉候選框,并截取候選框的圖片傳入到R-net。R-net對接收到的每個分散圖片進行人臉的檢測和評分,并且修正人臉框。得到修正的人臉框后,則將人臉框的圖像截取出來,傳入到O-net進行再次的人臉檢測和評分,得到最終的人臉框位置。最后將人臉框截取出來,并轉化成灰度圖,用于接下來的模型訓練。
5 模型的建立
人臉識別的模型采用的是卷積神經網絡,對圖片信息就行卷積、池化、全連接輸出、并與訓練集的標簽值進行差值比較,最后得到模型訓練精度的過程。
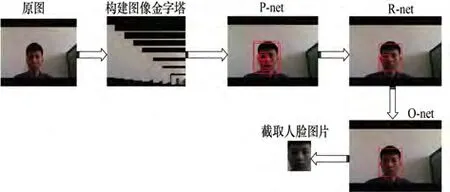
圖4 人臉檢測過程
5.1 卷積
如圖5所示,卷積[5]就是對預處理后的人臉圖片信息用一個卷積[7]核Filter依次掃描圖片的矩陣信息并與Filter矩陣對應位置的數值相乘[6],作為下一層的一個節點。當掃描完圖片的所有信息后,將會得到一個Maps矩陣即為第一次卷積的輸出值。
5.2 池化
池化[7]的目的就是降維,將圖片的特征信息提取出來,去掉無用的信息,最后形成一個維度更低的矩陣。這樣可以防止過擬合,也能減少計算機對數據的處理量。在池化的過程中,大多數采用的是Max poling方法。如圖6所示,Max pooling方法就是對每個2×2的filter區域,取最大值,最終輸出一個降維的矩陣。
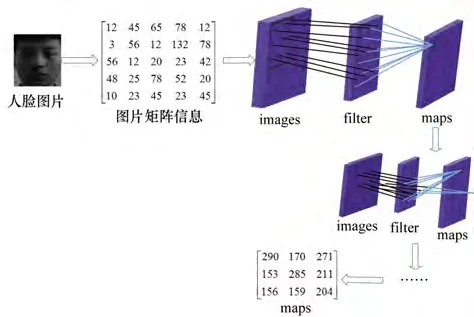
圖5 卷積過程
5.3 全連接
全連接的過程是將池化層的輸出x作為全連接層的輸入,將其乘以權重系數w,再加上偏置項b,得到輸出out的值。最后將輸出的out值,通過Softmax函數傳遞,將會得到一個對圖像屬于各類別的概率值。對于這一輪的全連接得出的分類結果為概率最后的那一類。
6 實驗結果分析
6.1 模型訓練情況分析
基于以上所建立的人臉識別[8-9]模型,本實驗則抽取5位測試人員進行測試。首先將采集這5位測試人員的人臉圖片經過預處理后,進行模型的訓練,并紀錄訓練的情況,如圖7所示。由圖可知,無論是采用0.01、0.02還是0.03的學習率進行訓練,模型的訓練精度都隨著訓練的次數的增加而提高,最后趨向一個穩定的訓練精度。并從圖中可看出,采用0.01的學習速率時,訓練的精確度是最高的,效果也是最好的。因此,保存采用0.01學習的速率訓練的模型。

圖8 測試人員相似度表
6.2 模型識別率分析
采用訓練好的模型依次對5位測試人員,進行人臉識別的測試,輸出識別的相似度,并記錄數據,如圖8所示。由圖可知,測試人員圖片的相似度均在80%以上。由此可看出,該模型的整體識別率比較高。
6.3 實驗效果
以下是后端對采集的圖片進行識別的效果圖,圖9所示為一個人的識別結果,并表示識別出當前司機為hyy,圖10所示為兩個人臉的識別,識別出當前駕駛位的人員是hyy和dsj。圖11所示為測試人員是沒有事先進行信息的采集和訓練的,因此,系統識別出該測試人員為stranger。

圖9 一個人的識別結果
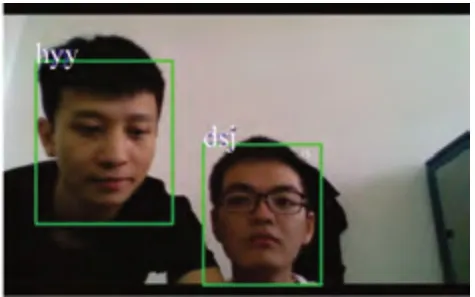
圖10 兩個人臉的識別
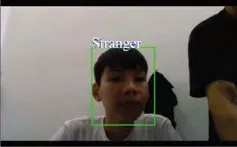
圖11 stranger識別結果
7 結束語
本文研究基于人臉識別的車輛安全系統,主要是運用人臉識別技術,對駕駛司機進行人臉識別,進而控制汽車的啟動電源,以達到控制的汽車啟動。除此之外,識別司機的記錄信息也將存儲在服務器中,以便查詢來訪車內的駕駛人員。當識別出駕駛位不是司機本人時,則將保持汽車電源的關閉,并發出警報給用戶。若識別當前人臉為司機本人,則開啟汽車電源,啟動汽車。這有效提高了車輛的防盜性和車輛駕駛時的安全性,有效避免非法人員駕駛公共汽車,并對乘客造成傷害。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
學生天地(2020年31期)2020-06-01 02:32:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
計算機工程(2015年8期)2015-07-03 12:19:07
中外會展(2014年4期)2014-11-27 07:46:46
電子設計工程(2014年8期)2014-02-27 11:57:26
