基于Spark的自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)研究
2021-06-27 14:11:00劉黎志鄧開巍
武漢工程大學(xué)學(xué)報(bào) 2021年3期
關(guān)鍵詞:結(jié)構(gòu)實(shí)驗(yàn)
楊 敏,劉黎志,鄧開巍,劉 杰
智能機(jī)器人湖北省重點(diǎn)實(shí)驗(yàn)室(武漢工程大學(xué)),湖北 武漢430205
自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)(self-adaptive differential evolution extreme learning machine,SaDE-ELM)[1]是由Cao等在2012年提出的一種使用群智能計(jì)算改進(jìn)的極限學(xué)習(xí)機(jī)算法,它將自適應(yīng)差分進(jìn)化算法(self-adaptive differential evolution,SaDE)與標(biāo)準(zhǔn)極限學(xué)習(xí)機(jī)算法相結(jié)合,從很大程度上解決了標(biāo)準(zhǔn)極限學(xué)習(xí)機(jī)算法中由于隨機(jī)初始化隱藏層輸入權(quán)重和偏置導(dǎo)致的算法穩(wěn)定性不高、預(yù)測準(zhǔn)確度波動(dòng)較大的問題,目前已被廣泛應(yīng)用到分類識(shí)別[2-4]和回歸預(yù)測領(lǐng)域[5-7]。隨著大數(shù)據(jù)時(shí)代的到來,一個(gè)算法能否高效地處理大規(guī)模數(shù)據(jù)集也成為了衡量算法普適性的一個(gè)重要指標(biāo),為了提升很多傳統(tǒng)的機(jī)器學(xué)習(xí)算法的運(yùn)行效率,如何利用現(xiàn)有的大數(shù)據(jù)處理框架對(duì)其進(jìn)行并行化也成為目前研究的熱點(diǎn)問題[8-10]。SaDE-ELM算法在計(jì)算過程中,由于需要多次迭代計(jì)算來更新輸入層到隱藏層的連接權(quán)重和隱藏層偏置,不可避免地增加了算法的運(yùn)行時(shí)間,在數(shù)據(jù)集規(guī)模較大時(shí)算法的運(yùn)行效率十分低下。本文根據(jù)SaDE-ELM算法需要迭代計(jì)算的特性,采用了基于內(nèi)存計(jì)算的大數(shù)據(jù)框架Spark對(duì)其進(jìn)行并行化[11-13],將原本在單機(jī)上的計(jì)算合理地分布到集群的各臺(tái)機(jī)器中,提出了并行自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)(parallel self-adaptive differential evolution extreme learning machine,PSaDE-ELM),最后通過實(shí)驗(yàn)驗(yàn)證了在數(shù)據(jù)集樣本數(shù)較大時(shí),PSaDE-ELM算法能夠在保證預(yù)測準(zhǔn)確率基本不損失的基礎(chǔ)上,顯著地提升算法的運(yùn)行效率。
1 研究背景
1.1 極限學(xué)習(xí)機(jī)
極限學(xué)習(xí)機(jī)(extreme learning machine,ELM)是2004年黃廣斌等[14]提出的一種單隱藏層前饋神經(jīng)網(wǎng)絡(luò)(single-hidden-layer feedforward neural networks,SLFNs)機(jī)器學(xué)習(xí)算法。ELM與傳統(tǒng)基于反向傳播的神經(jīng)網(wǎng)絡(luò)算法的不同之處在于,它隨機(jī)初始化輸入層到隱藏層的連接權(quán)重和隱藏層節(jié)點(diǎn)的偏置,然后使用Moore-Penrose偽逆方法求解隱藏層到輸出層的權(quán)重,具有學(xué)習(xí)速度快、泛化能力強(qiáng)的特點(diǎn)。
ELM的算法描述為,給定N個(gè)任意不同已知訓(xùn)練集()x i,y i,i=1,…,N,其中x i∈RD,y i∈Rm,L為隱藏層節(jié)點(diǎn)個(gè)數(shù),g()x為激活函數(shù)。如果這個(gè)前饋神經(jīng)網(wǎng)絡(luò)能以零誤差逼近這N個(gè)樣本,則存在βi,w i,bi使得:
其中,βi∈Rm表示第i個(gè)隱藏層節(jié)點(diǎn)與所有輸出層節(jié)點(diǎn)之間的權(quán)重向量,w i∈RD表示第i個(gè)隱藏層節(jié)點(diǎn)與所有輸入層節(jié)點(diǎn)之間的權(quán)重向量,bi∈R表示第i個(gè)隱藏層節(jié)點(diǎn)的偏置。式(1)可以化簡為:
其中H表示ELM的隱含層輸出矩陣,當(dāng)網(wǎng)絡(luò)中的輸入權(quán)重和偏置隨機(jī)確定后,輸出矩陣H就唯一確定下來,這樣對(duì)SLFN的訓(xùn)練就可以轉(zhuǎn)化為一個(gè)求解輸出權(quán)重矩陣的最小二乘解的問題,輸出權(quán)重矩陣β可以由式(2)得到:

其中H?表示隱含層輸出矩陣H的Moorepenrose廣義逆。
1.2 自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)
SaDE-ELM算法將極限學(xué)習(xí)機(jī)中的輸入層到隱藏層的連接權(quán)重和隱藏層的偏置作為種群中一個(gè)個(gè)體,在自適應(yīng)差分進(jìn)化算法中進(jìn)行迭代優(yōu)化,對(duì)每個(gè)個(gè)體使用極限學(xué)習(xí)機(jī)算法進(jìn)行解析計(jì)算,以預(yù)測值與實(shí)際值的根均方誤差(root mean square error,RMSE)作為對(duì)應(yīng)個(gè)體的適應(yīng)度,在每次迭代中將保留適應(yīng)度更優(yōu)個(gè)體進(jìn)入下一次迭代,直至滿足結(jié)束條件后,輸出當(dāng)前種群中的最優(yōu)個(gè)體。其相比于差分進(jìn)化極限學(xué)習(xí)機(jī)(differential evolution extreme learning machine,DE-ELM)和支持向量機(jī)(support vector machine,SVM)具有更好的穩(wěn)定性和更高的運(yùn)行效率。
對(duì)于一個(gè)給定的訓(xùn)練數(shù)據(jù)集,L個(gè)隱藏節(jié)點(diǎn)的ELM,SaDE-ELM算法流程如下:
1)初始化種群,種群中每個(gè)個(gè)體的維度為(D+1)×L,其中D為特征個(gè)數(shù);
2)計(jì)算ELM的輸出權(quán)重矩陣和RMSE,然后將RMSE作為對(duì)應(yīng)個(gè)體的適應(yīng)度;
3)使用SaDE算法對(duì)種群中的每一個(gè)個(gè)體進(jìn)行變異和交叉操作;
4)使用適應(yīng)度評(píng)判標(biāo)準(zhǔn)來選擇進(jìn)入下一代的個(gè)體,如果當(dāng)前迭代次數(shù)未達(dá)到最大迭代次數(shù),則重復(fù)步驟2和3,進(jìn)入下一次迭代。
1.3 Spark平臺(tái)
Spark是加州大學(xué)伯克利分校實(shí)驗(yàn)室基于AMPLab的集群計(jì)算平臺(tái)開發(fā)的一個(gè)基于內(nèi)存計(jì)算的分布式框架,相比于Hadoop分布式框架,Spark將中間計(jì)算過程保存在內(nèi)存中,避免了將中間結(jié)果輸出到硬盤存儲(chǔ),所以Spark更適合于具有迭代計(jì)算的應(yīng)用場景。其最核心的技術(shù)是彈性分布式數(shù)據(jù)集(resilient distributed datasets,RDD)。RDD是一個(gè)不可變的分布式對(duì)象集合,對(duì)數(shù)據(jù)的所有操作最終會(huì)轉(zhuǎn)換成對(duì)RDD的操作,即RDD是數(shù)據(jù)操作的基本單位。對(duì)于RDD的操作,分為transformation(轉(zhuǎn)換)和action(執(zhí)行)。Spark對(duì)于兩種操作采取不同機(jī)制,對(duì)于所有的轉(zhuǎn)換操作都是惰性操作,即從一個(gè)RDD通過轉(zhuǎn)換操作生成另一個(gè)RDD的過程在Spark上并不會(huì)被馬上執(zhí)行,只有在action操作觸發(fā)時(shí),轉(zhuǎn)換操作才會(huì)被真正執(zhí)行。因此,不同RDD之間的轉(zhuǎn)換操作會(huì)形成依賴關(guān)系,可以實(shí)現(xiàn)管道化,從而避免了中間結(jié)果的存儲(chǔ),大大降低了數(shù)據(jù)復(fù)制、磁盤IO和序列化開銷。
1.4 群智能算法并行化相關(guān)研究
近些年來隨著群智能算法的發(fā)展,許多學(xué)者將分布式計(jì)算的思想引入到群智能算法中,提出了多種基于大數(shù)據(jù)計(jì)算平臺(tái)的群智能并行化算法。2016年李婉華等[15]提出了基于改進(jìn)粒子群優(yōu)化的并行極限學(xué)習(xí)機(jī)算法,使用真實(shí)電力負(fù)荷數(shù)據(jù)在Spark平臺(tái)上對(duì)算法有效性進(jìn)行了驗(yàn)證。2017年重慶大學(xué)余相君[16]提出了一種使用改進(jìn)后的布谷鳥搜索算法優(yōu)化的K-means算法,并在Hadoop平臺(tái)上對(duì)該算法進(jìn)行并行化處理,在數(shù)據(jù)集規(guī)模較大時(shí),算法運(yùn)行效率得到了提升。2018年大連理工大學(xué)孫康麗[17]基于Spark平臺(tái)對(duì)分布式差分進(jìn)化算法并行化,提出基于廣播變量和Shuffle操作的兩種遷移算子實(shí)現(xiàn)方式,比較了兩種實(shí)現(xiàn)在不同計(jì)算資源下的加速比。
2 自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)并行化
2.1 算法并行化的思路
自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)算法在迭代過程中,因?yàn)榉N群里的各個(gè)個(gè)體的進(jìn)化都是相互獨(dú)立的,所以可以將原有種群均勻分割為幾個(gè)子種群,每個(gè)子種群并行地獨(dú)立進(jìn)化,然后每隔一定的周期各個(gè)子種群之間按照一定的拓?fù)浣Y(jié)構(gòu)進(jìn)行信息交流,以此來達(dá)到既提高了算法的運(yùn)行效率又保證了種群間多樣性的目的。本文提出的基于Spark的SaDE-ELM并行化算法PSaDE-ELM就是按這一思路來實(shí)現(xiàn)的。
在PSaDE-ELM算法中,每一個(gè)子種群均由一個(gè)子種群序號(hào)和SaDE_ELM對(duì)象組成的元組來表示(i,SaDE_ELMi),每個(gè)SaDE_ELM 對(duì)象中均存儲(chǔ)了當(dāng)前子種群在迭代進(jìn)化中必要的參數(shù)信息,這些參數(shù)信息隨著子種群的進(jìn)化而改變,然后利用Spark中RDD的分區(qū)原理,對(duì)子種群列表使用makeRDD方法轉(zhuǎn)換為RDD,并且將其分區(qū)數(shù)設(shè)置為子種群個(gè)數(shù),來保證將每一個(gè)子種群以及其參數(shù)信息均獨(dú)立地存儲(chǔ)在RDD的一個(gè)分區(qū)中。然后對(duì)當(dāng)前RDD使用map算子,使各個(gè)子種群中的迭代計(jì)算在各個(gè)Task之間并行執(zhí)行,等待所有Executor中的Task均執(zhí)行完畢后,將當(dāng)前迭代周期中各個(gè)子種群所產(chǎn)生的最優(yōu)個(gè)體使用collect算子匯總到Driver端,然后由Driver端將這些最優(yōu)個(gè)體信息廣播到各個(gè)Executor中,以便后續(xù)根據(jù)一定的拓?fù)浣Y(jié)構(gòu)在各個(gè)子種群間進(jìn)行信息交換。當(dāng)各個(gè)子種群進(jìn)行信息交換后,就進(jìn)入下一個(gè)迭代周期,直至滿足結(jié)束條件后,輸出所有子種群中最優(yōu)的個(gè)體,即最優(yōu)的隱藏層輸入權(quán)重和偏置。
2.2 兩種拓?fù)浣Y(jié)構(gòu)
各個(gè)子種群在每次獨(dú)立迭代一個(gè)周期后,會(huì)按照給定的拓?fù)浣Y(jié)構(gòu)來進(jìn)行種群信息交換。子種群間的交流拓?fù)浣Y(jié)構(gòu)主要包括兩種:一種是全連接拓?fù)浣Y(jié)構(gòu),即每一個(gè)子種群可以與其他所有子種群進(jìn)行信息交換;另一種是鄰域拓?fù)浣Y(jié)構(gòu),即每一個(gè)子種群只能與其相鄰的子種群進(jìn)行信息交換。
對(duì)于某一個(gè)子種群而言,在一個(gè)迭代周期結(jié)束以后,全連接拓?fù)浣Y(jié)構(gòu)會(huì)將所有子種群中最優(yōu)的個(gè)體去替換掉當(dāng)前子種群中的最差個(gè)體,每個(gè)子種群在信息交流完之后,其總體進(jìn)化程度都至少為最優(yōu)個(gè)體的適應(yīng)度,所以這種拓?fù)浣Y(jié)構(gòu)具有較強(qiáng)的全局收斂速度能力;而鄰域拓?fù)浣Y(jié)構(gòu)會(huì)將左右相鄰的兩個(gè)子種群中的最優(yōu)個(gè)體去替換掉當(dāng)前子種群中的最差個(gè)體,這種拓?fù)浣Y(jié)構(gòu)收斂速度較慢,但可以避免整個(gè)種群過早陷入局部最優(yōu)。
2.3 PSaDE-ELM算法設(shè)計(jì)
PSaDE-ELM算法在Spark上的實(shí)現(xiàn)主要算法流程如下:
1)將原種群均勻分割為多個(gè)子種群,設(shè)置并行度等于子種群個(gè)數(shù),以便將每個(gè)子種群及其序號(hào)單獨(dú)存儲(chǔ)在種群RDD的一個(gè)分區(qū)中;
2)使用Spark中的廣播變量機(jī)制,將訓(xùn)練數(shù)據(jù)集由Driver端廣播到各個(gè)機(jī)器上的Executor中;
3)在當(dāng)前迭代周期中,對(duì)種群RDD使用map算子,執(zhí)行optime方法來對(duì)各個(gè)子種群迭代一個(gè)周期,計(jì)算并統(tǒng)計(jì)各自最優(yōu)和最壞的個(gè)體,返回進(jìn)化后的子種群對(duì)象;
4)使用Cache方法,緩存上一步中進(jìn)化后的種群RDD;
5)將各個(gè)子種群中的子種群序號(hào)和最優(yōu)個(gè)體以元組的形式收集到Driver端,組成當(dāng)前最優(yōu)個(gè)體列表,并將該列表由Driver端廣播到各臺(tái)機(jī)器上的Executor中;
6)按照一定的拓?fù)浣Y(jié)構(gòu),根據(jù)最優(yōu)個(gè)體列表信息來和其他子種群進(jìn)行信息交換,并返回進(jìn)化后的子種群對(duì)象;
7)判斷當(dāng)前同步次數(shù)是否能夠被10整除,若能夠被10整除,則對(duì)種群RDD進(jìn)行一次CheckPoint操作;否則,進(jìn)入下一步;
8)判斷當(dāng)前同步次數(shù)是否大于設(shè)置的最大同步次數(shù),若小于最大同步次數(shù),則返回算法的第3步;否則,輸出所有子種群中的最優(yōu)個(gè)體,算法流程結(jié)束。
在上述算法流程中,使用了Spark框架中的廣播變量、Cache緩存機(jī)制和CheckPoint操作。之所以使用廣播變量,是因?yàn)槿绻粚?shù)據(jù)集以廣播變量的方式由Driver端發(fā)送給Executor端,那么在每次開啟一個(gè)Task時(shí),都會(huì)產(chǎn)生一個(gè)數(shù)據(jù)集的副本。也就是說,使用廣播變量的方式發(fā)送副本時(shí),副本個(gè)數(shù)等于集群中各臺(tái)機(jī)器上Executor的數(shù)量;而不使用廣播變量的方式,直接在Task中使用數(shù)據(jù)集時(shí),那么每一個(gè)Task中都會(huì)保存一份數(shù)據(jù)集的副本。當(dāng)Task數(shù)大于Executor數(shù)時(shí)就會(huì)產(chǎn)生冗余的數(shù)據(jù)集副本,不僅占用內(nèi)存空間,而且會(huì)導(dǎo)致算法運(yùn)行效率不高的問題。
使用Cache方法緩存種群RDD,可以在下一次對(duì)種群RDD的行動(dòng)算子執(zhí)行完之后將種群RDD緩存在內(nèi)存中,種群RDD中的每個(gè)分區(qū)里的子種群信息也都會(huì)保留下來,這對(duì)于需要在下一個(gè)周期繼續(xù)上次的迭代過程是至關(guān)重要的。如果沒有使用Cache方法,那么在每一次迭代周期中種群RDD都將被重新計(jì)算,將無法承接上一次的進(jìn)化結(jié)果繼續(xù)進(jìn)行種群進(jìn)化,導(dǎo)致算法運(yùn)行效率大大降低。
在算法流程中定期使用CheckPoint操作的原因是由于在每一個(gè)迭代周期中都會(huì)由先前的RDD產(chǎn)生一個(gè)新的RDD,并由此組成一條RDD關(guān)系鏈,當(dāng)這條RDD鏈變得很長時(shí),其依賴關(guān)系也會(huì)變得很長,通過定期使用CheckPoint來將種群RDD保存在磁盤中,從而切斷當(dāng)前種群RDD與先前種群RDD之間的血緣關(guān)系,可以避免在反序列化當(dāng)前種群RDD時(shí)由于過長的血緣關(guān)系而導(dǎo)致性能低下的問題。
PSaDE-ELM算法的核心算法描述如下:


3 實(shí)驗(yàn)及分析
3.1 實(shí)驗(yàn)環(huán)境及數(shù)據(jù)
本實(shí)驗(yàn)所用服務(wù)器為戴爾R720服務(wù)器,它配置為兩個(gè)物理CPU(Intel Xeon E5-2620V22.10 GHZ,最大睿頻2.6 GHz,每個(gè)CPU含6個(gè)內(nèi)核,一共12個(gè)內(nèi)核),32 GB內(nèi)存,8 TB硬盤。該服務(wù)器被虛擬劃分為4個(gè)虛擬機(jī),每個(gè)虛擬機(jī)的配置為3個(gè)內(nèi)核CPU,8 GB內(nèi)存,2 TB硬盤。集群使用的主要軟件 有 Hadoop2.7.3、Spark2.4.6、JDK1.8、Scala2.12.2等,操作系統(tǒng)為Ubuntu-16.04.1-Serveramd64。Spark集群包括一個(gè)Master主節(jié)點(diǎn)和4個(gè)Worker數(shù)據(jù)節(jié)點(diǎn)(主節(jié)點(diǎn)也是數(shù)據(jù)節(jié)點(diǎn))。實(shí)驗(yàn)選用4個(gè)UCI公開數(shù)據(jù)集進(jìn)行訓(xùn)練和測試,其中訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集占比均為70%和30%,實(shí)驗(yàn)數(shù)據(jù)集信息如表1所示。
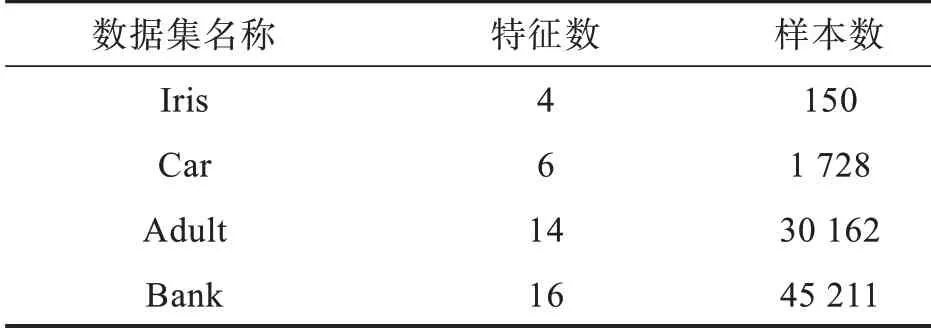
表1 實(shí)驗(yàn)數(shù)據(jù)集信息表Tab.1 Information table of experimental data set
3.2 實(shí)驗(yàn)結(jié)果及分析
從3個(gè)方面對(duì)所提出的PSaDE-ELM算法進(jìn)行了分析,首先是在不同數(shù)據(jù)規(guī)模的數(shù)據(jù)集上串行SaDE-ELM算法與PSaDE-ELM算法各自的運(yùn)行效率與預(yù)測準(zhǔn)確率的對(duì)比;其次,分析了子種群之間采用不同的拓?fù)浣Y(jié)構(gòu)進(jìn)行信息交流對(duì)PSaDE-ELM算法運(yùn)行效率和預(yù)測準(zhǔn)確率的影響;最后分析了在原種群大小不變的前提下,隨著子種群數(shù)量的增多對(duì)PSaDE-ELM算法運(yùn)行效率和預(yù)測準(zhǔn)確率的影響。其中,采用手動(dòng)調(diào)參的方式來選擇最適合當(dāng)前數(shù)據(jù)集的隱藏層節(jié)點(diǎn)個(gè)數(shù),原種群大小為60,同步次數(shù)為20,同步周期為10,每個(gè)實(shí)驗(yàn)結(jié)果均為30次實(shí)驗(yàn)數(shù)據(jù)的平均值。
第一組實(shí)驗(yàn)是對(duì)于在不同規(guī)模數(shù)據(jù)集上串行SaDE-ELM算法和PSaDE-ELM算法各自的運(yùn)行效率與預(yù)測準(zhǔn)確率的對(duì)比。對(duì)于不同的數(shù)據(jù)集,選擇了最適合的隱藏層節(jié)點(diǎn)個(gè)數(shù),且子種群數(shù)量subPopCount均為6。由表2可知,PSaDE-ELM算法在各個(gè)數(shù)據(jù)集上的預(yù)測準(zhǔn)確率基本與SaDEELM算法保持不變(上下誤差不超過1%);在數(shù)據(jù)量較小時(shí)串行SaDE-ELM算法相比PSaDE-ELM算法會(huì)更有優(yōu)勢,這是由于在數(shù)據(jù)量較小時(shí),在Spark集群中讀取數(shù)據(jù)集以及啟動(dòng)集群資源所需時(shí)間占比會(huì)比較大,導(dǎo)致最終的運(yùn)行時(shí)間會(huì)比串行SaDE-ELM算法要長。但隨著數(shù)據(jù)集樣本量的逐漸增大,PSaDE-ELM算法并行計(jì)算的優(yōu)勢會(huì)逐漸體現(xiàn)出來,在Car數(shù)據(jù)集上,時(shí)間性能提升了(74.509-29.79)÷29.79≈150%,在Adult數(shù)據(jù)集上,時(shí)間性能提升了(2 652.553-736.908)÷736.908≈260%,在Bank數(shù)據(jù)集上,時(shí)間性能提升了(4 590.235-1 180.954)÷1 180.954≈289%。可以看出,隨著訓(xùn)練數(shù)據(jù)集規(guī)模的增大,集群計(jì)算的優(yōu)勢就愈發(fā)明顯。
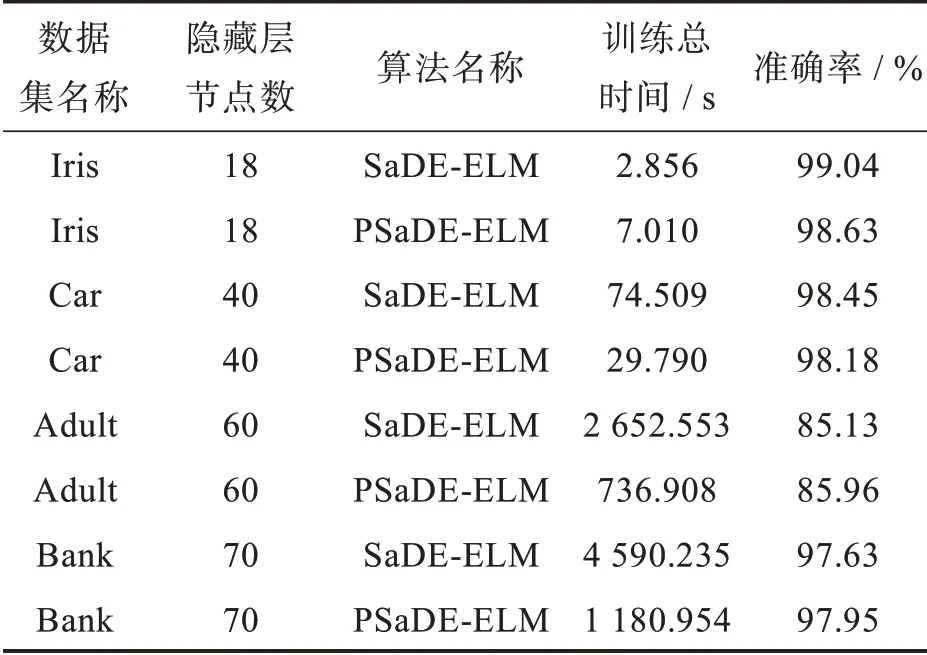
表2 SaDE-ELM與PSaDE-ELM算法運(yùn)行結(jié)果對(duì)比實(shí)驗(yàn)數(shù)據(jù)表Tab.2 Comparison experimental results of SaDE-ELM with PSaDE-ELM algorithm
第二組實(shí)驗(yàn)主要分析了子種群之間采用不同的拓?fù)浣Y(jié)構(gòu)進(jìn)行信息交流對(duì)PSaDE-ELM算法運(yùn)行效率和預(yù)測準(zhǔn)確率的影響。在保持其他參數(shù)不變的前提下,分別使用全連接拓?fù)浣Y(jié)構(gòu)和鄰域拓?fù)浣Y(jié)構(gòu)來進(jìn)行子種群之間信息交流。由表3可知,對(duì)于3個(gè)數(shù)據(jù)集而言,鄰域拓?fù)浣Y(jié)構(gòu)相比全連接拓?fù)浣Y(jié)構(gòu)在算法的運(yùn)行效率上提升并不明顯,其預(yù)測準(zhǔn)確率卻比全連接拓?fù)浣Y(jié)構(gòu)要低1%~2%。這是由于在鄰域拓?fù)浣Y(jié)構(gòu)中,每個(gè)子種群只與其相鄰的兩個(gè)子種群進(jìn)行交流,在算法的全局收斂上會(huì)比較慢,在同步次數(shù)不多的情況下,預(yù)測準(zhǔn)確率會(huì)不如全連接拓?fù)浣Y(jié)構(gòu)。因此,在本次實(shí)驗(yàn)中,采用全連接拓?fù)浣Y(jié)構(gòu)能夠更好地在子種群之間進(jìn)行信息交流。
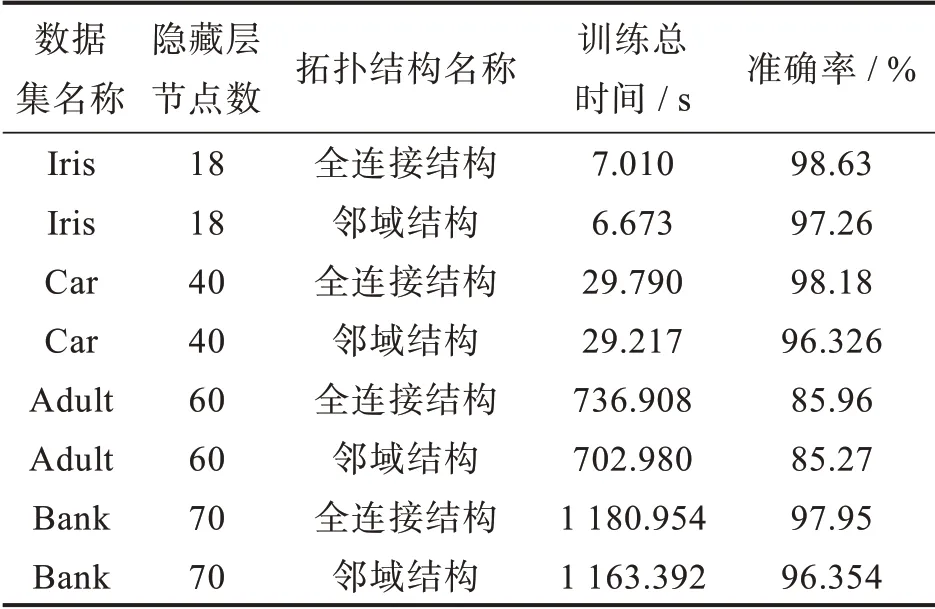
表3 子種群間不同拓?fù)浣Y(jié)構(gòu)運(yùn)行結(jié)果對(duì)比實(shí)驗(yàn)數(shù)據(jù)表Tab.3 Comparison of running results achieved under different topological structures of subpopulations
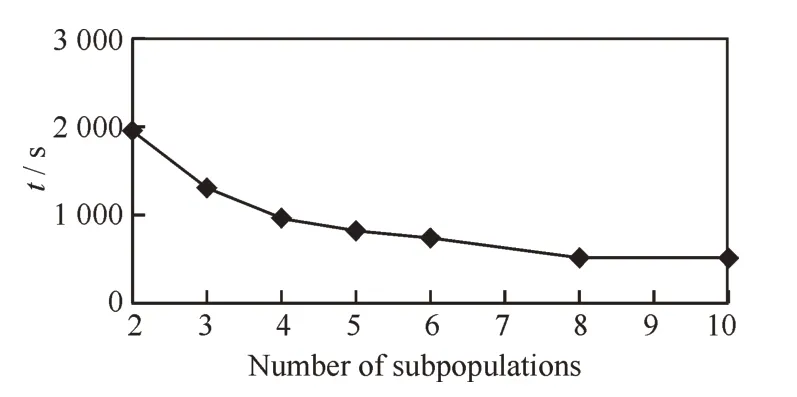
圖1 不同子種群個(gè)數(shù)總運(yùn)行時(shí)間趨勢圖Fig.1 Variation curve of run time with number of subpopulations
第三組實(shí)驗(yàn)主要分析了在原種群大小不變的前提下,隨著子種群數(shù)量的增多對(duì)PSaDE-ELM算法運(yùn)行效率和預(yù)測準(zhǔn)確率的影響。實(shí)驗(yàn)選用Adult數(shù)據(jù)集,設(shè)置隱藏層節(jié)點(diǎn)數(shù)為60,原種群大小為60,然后逐漸增加子種群個(gè)數(shù),并統(tǒng)計(jì)每次實(shí)驗(yàn)的運(yùn)行時(shí)間和預(yù)測準(zhǔn)確率。每次實(shí)驗(yàn)的預(yù)測準(zhǔn)確度波動(dòng)不大,均維持在85%左右。由圖1可知,隨著子種群個(gè)數(shù)從2增加至10(由于自適應(yīng)差分進(jìn)化算法使用的一個(gè)變異算子中需要隨機(jī)抽取6個(gè)個(gè)體進(jìn)行變異,所以每個(gè)子種群至少要有6個(gè)個(gè)體),算法的運(yùn)行時(shí)間呈單調(diào)遞減趨勢,且當(dāng)子種群個(gè)數(shù)小于等于4時(shí),運(yùn)行時(shí)間減少的幅度較大,當(dāng)子種群個(gè)數(shù)大于4時(shí),運(yùn)行時(shí)間減少的幅度逐漸減小。由于使用RDD的一個(gè)分區(qū)來單獨(dú)存儲(chǔ)一個(gè)子種群及其參數(shù)信息,對(duì)于每一個(gè)分區(qū)而言,都會(huì)獨(dú)立地占有一個(gè)Task,每一個(gè)子種群之中的計(jì)算都是并行的。當(dāng)子種群個(gè)數(shù)為8時(shí),Spark集群中的4個(gè)Executor中,每一個(gè)Executor里均有2個(gè)Task在并行計(jì)算,此時(shí)集群已達(dá)到負(fù)載均衡狀態(tài),繼續(xù)增加Task的個(gè)數(shù),將不能再明顯地提升算法的性能。
4 結(jié) 論
基于Spark高性能內(nèi)存計(jì)算框架,提出了一種并行化自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)算法PSaDEELM,并從3個(gè)方面進(jìn)行了對(duì)比實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明,本文提出的PSaDE-ELM算法在預(yù)測準(zhǔn)確率上與串行SaDE-ELM算法相比基本沒有差別,但隨著數(shù)據(jù)規(guī)模的增加,PSaDE-ELM算法能夠?qū)⑦\(yùn)行效率提升數(shù)倍,從而證明了PSaDE-ELM算法的有效性;對(duì)于不同的子種群拓?fù)浣Y(jié)構(gòu)而言,全連接拓?fù)浣Y(jié)構(gòu)相比于鄰域拓?fù)浣Y(jié)構(gòu)都能夠更好地適用于本文所選數(shù)據(jù)集;在保持其他參數(shù)不變的前提下,隨著子種群數(shù)量的增加,其預(yù)測準(zhǔn)確率波動(dòng)不大,但其運(yùn)行時(shí)間顯著減少。本文在對(duì)自適應(yīng)差分進(jìn)化極限學(xué)習(xí)機(jī)算法進(jìn)行并行化時(shí)采用的是粗粒度方式,即將一個(gè)種群均勻劃分為多個(gè)子種群來共同進(jìn)化,這種方式對(duì)于數(shù)據(jù)量不是很大的情況下能夠顯著提升算法的運(yùn)行效率。但在數(shù)據(jù)量很大時(shí),計(jì)算各個(gè)個(gè)體的均方根誤差時(shí)會(huì)面臨高維矩陣的計(jì)算,在后續(xù)的實(shí)驗(yàn)和研究過程中,將試圖將高維矩陣的計(jì)算也進(jìn)行并行化,使改進(jìn)后的算法能夠適用于處理更大規(guī)模的數(shù)據(jù)集,在保證預(yù)測準(zhǔn)確率的前提下,盡可能地提升運(yùn)行效率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
哲學(xué)評(píng)論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評(píng)論(2016年0期)2016-11-23 05:26:01
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
