基于深度學習的管道紗線及其顏色檢測①
2021-06-28 06:28:28李進飛李建強段玉堂任國棟史偉民
計算機系統應用 2021年6期
李進飛,李建強,段玉堂,任國棟,史偉民
(浙江理工大學 機械與自動控制學院,杭州 310018)
隨著工業4.0 的快速推進,機器代替工人的趨勢不可逆轉,因此為了提高紡紗[1]效率、降低人工成本,采用機器代替人工進行紗線打結大勢所趨.自動換筒系統中的紗線自動打結機通過管道吸取紗線,機械機構利用管道中的紗線進行打結完成人工打結的任務,大大降低人工成本,提高了打結可靠性.但是紗線打結機正常運行的前提是管道吸取了所需的紗線,因此檢測管道是否成功吸取紗線以及該紗線是否是所需顏色的紗線至關重要.
傳感器方法如紅外開關傳感器[2]利用物體阻隔發射器與接收器通路的信號接收來判斷是否有物體.由于紗線纖細,激光或者紅外容易穿透紗線,所以難以對紗線進行檢測.相比之下,采用攝像頭對管道進行拍攝,利用圖像處理的方法進行檢測較為容易.傳統的圖像處理方法可以使用OpenCV 對圖像進行HSV 顏色分離從而對圖片中紗線進行提取,最終確定紗線及其顏色.但是對于一些紗線顏色與背景顏色相差不多以及各種各樣的紗線進行檢測時,該方法就顯得較為復雜,且魯棒性較差.
近年來,深度學習[3,4]的卷積神經網絡在圖像處理領域發展迅速贏得了廣泛的關注.相比傳統的圖像處理方式,深度學習具有諸多優點,如模型具有可遷移性、無需手動設計特征、檢測準確度高等特性.從卷積網絡的出現到現在,已經出現了非常優秀的網絡,例如LeNet[5]、VGG[6]、AlexNet[7]、GoogLeNet[8]等,但是這些網絡要么就是檢測尺度單一,要么就是計算量以及參數量較大.
本文針對紗線粗細不一、種類繁多、檢測困難等問題,提出了一種多尺度的深度分離卷積[9,10]網絡,結合ResNet[11,12]網絡的特點,解決紗線檢測特征尺度單一、檢測效果低、特征丟失、模型計算量與參數量大等問題,使得檢測精度能滿足一定的應用要求.
1 管道紗線圖像采集與處理
1.1 圖像采集與整理
利用海康MV-CE050-30UC 攝像頭對管道進行拍照采集1200 張圖片,經過去除重復以及有缺陷的圖片后制作成數據集,其中包括無紗線、黑色紗線、藍色紗線、粉色紗線、白色紗線、黃色紗線6 種情況.該數據集在程序運行時,以4:1 的比例隨機劃分為訓練集和驗證集,并將每張圖片裁剪成224×224 像素.
1.2 圖像數據增強
由于采集的數據量較少,在訓練過程中需要對圖像進行數據增強來提高數據集的多樣性,從而有效地降低過擬合現象.圖像增強的方法很多,本論文對樣本進行增強采用的方法主要包括:上下翻轉、左右翻轉、亮度變化等,具體效果如圖1所示.

圖1 圖像增強效果圖
2 改進的多尺度深度可分離卷積模型
2.1 改進的多尺度深度可分離卷積塊
改進的多尺度深度可分離卷積塊是基于Inception v4[13–15]中的Inception-ResNet-A 塊提出并改進的,從圖2可知,輸入特征圖x分別經過1×1 卷積核卷積、一個3×3 的深度可分離卷積核卷積以及兩個3×3 的深度可分離卷積核卷積,得到輸出特征圖后,再經過1×1 卷積核進行多尺度特征融合得到F(x),從而保證輸出特征圖的通道數.經過最后的1×1 卷積核卷積后,采用ResNet 的短接線方式,進行輸出F(x)與輸入特征圖之間的特征融合,解決特征梯度消失問題,其中輸入特征與輸出特征之間的關系如式(1)所示:

與Inception-ResNet-A 塊相比,在結構上改進的多尺度深度可分離卷積塊少了兩個1×1 的卷積核,因為Inception-ResNet-A 塊在設計上希望通過1×1 卷積核減少輸入通道數量,但是本論文所需的模型不大,所以去除這兩個卷積核,從而降低網絡的計算量以及參數量.其次,因為深度可分離卷積與傳統卷積相比計算量和參數量更少,所以改進的多尺度深度可分離卷積塊采用3×3 卷積核的深度可分離卷積代替傳統的3×3 卷積核卷積,從而使得該塊的計算量和參數量更少,網絡更輕量化.其中,深度可分離卷積與傳統卷積的比較[16]如下所示.
設輸入與輸出特征圖大小相同時,傳統卷積的計算量以及參數量如下:
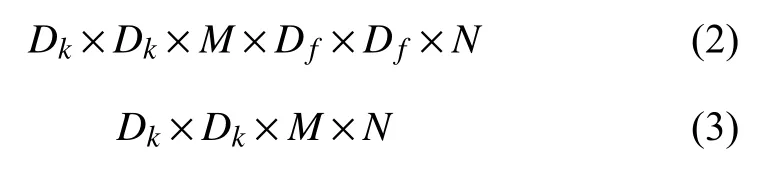
式中,式(2)為傳統卷積計算量的計算公式,式(3)為傳統卷積參數量的計算公式.其中卷積核大小為Dk×Dk,輸出特征圖大小為Df×Df,M為輸入特征圖數量,N為輸出特征圖數量.
與之相比,深度可分離卷積計算量與參數量為逐通道卷積和逐點卷積的兩者之和,如式(4)、式(5)所示:
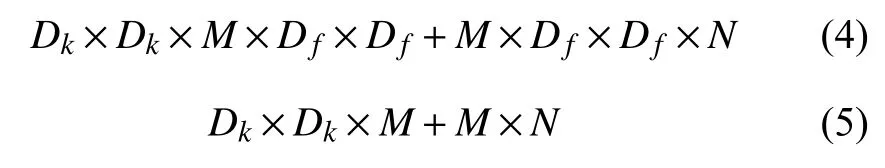
其中,式(4)和式(5)前相乘部分為逐通道卷積計算量和參數量的計算,后面相乘部分為逐點卷積計算量與參數量的計算.深度可分離卷積與傳統卷積計算量與參數量的比值如式(6)和式(7)所示.
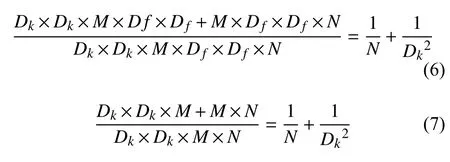
從式(6)和式(7)可以看出深度可分離卷積與傳統卷積的計算量以及參數量的差異.當采用5×5 卷積核時,則Dk2為1/25,則深度可分離卷積與傳統卷積相比計算量以及參數量的比值接近1/25.從中可以看出,深度可分離卷積更輕量化.
從上可知,本文的多尺度深度可分離卷積塊采用3×3 卷積核的深度可分離卷積代替3×3 卷積核的傳統卷積,從計算量以及參數量上看,更優于Inception-ResNet-A 塊.
2.2 多尺度深度可分離卷積網絡的構建
考慮到本次研究所用的數據集并不大以及檢測并非復雜,所以構建結構較小的網絡,如圖3所示.該網絡輸入圖片大小為224×224,經過傳統卷積層卷積,得到32 通道的特征圖,經過5 次多尺度深度可分離卷積塊的特征提取(其中步長均為2),得到特征圖的輸出為7×7×512.緊接著該特征圖輸入到全局平均池化層,得到的輸出經過Dropout 層后再輸入到全鏈接層,最后經過Softmax 函數計算得到各類輸出的概率,具體結構如表1所示.其中網絡結構中涉及到的卷積層包括多尺度深度可分離卷積塊中的卷積層均會使用歸一化層以及將ReLU 函數作為激活函數.從圖2中可知,該網絡并不大,足夠處理紗線檢測的問題.
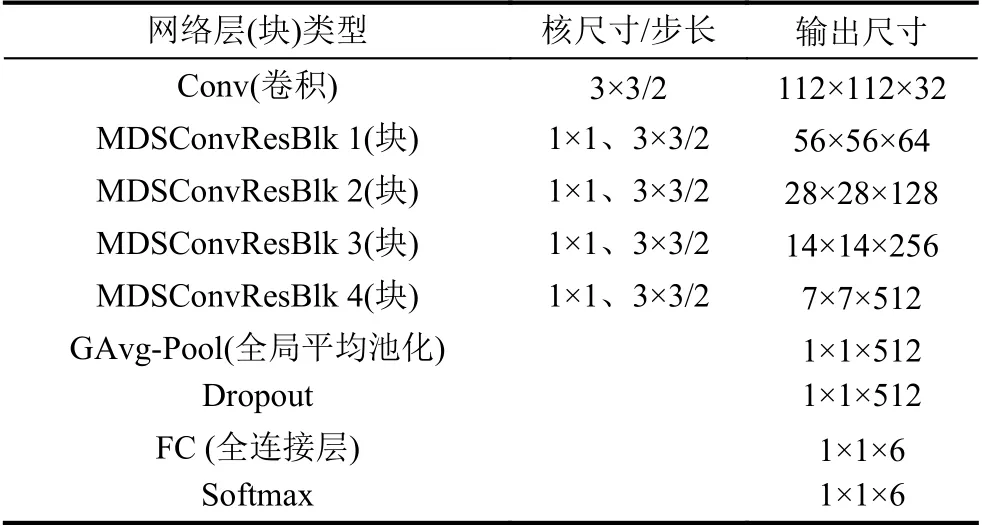
表1 基于多尺度深度可分離卷積網絡結構

圖2 Inception-ResNet-A 塊與多尺度深度可分離卷積塊

圖3 多尺度深度可分離卷積網絡結構
3 實驗
3.1 實驗環境
訓練網絡的過程是基于64 位Windows 10 的系統下進行的,其中計算機的配置為Inter(R) Cele(R) G4900 CPU@3.10 GHz,RAM為8.00 GB,顯卡為NVIDIA GeForce GTX 1060 6 GB.
3.2 實驗設置以及結果分析
網絡訓練過程中采用Adam 優化器,初始學習率設置為3e–4,學習率變化指數設置為0.3.在訓練過程中監視驗證集的準確率,當統計該數值在3 次沒有降低時,學習率以0.7 的倍數進行衰減(其中新的學習率lrnew=0.3?lrold).其次損失評估采用的是交叉熵損失函數來衡量網絡輸出與真實結果的差距,最后網絡模型訓練的30 輪情況如圖4所示.
從圖4中可知,網絡初始化完成時尚未能夠進行紗線檢測,圖片分類能力非常差.隨著網絡訓練的不斷進行,網絡開始快速收斂,在接近25 輪訓練時,網絡開始接近穩定,而此時驗證集的識別精度能夠達到100%.隨著訓練次數的增加,網絡訓練時的驗證集識別精度已經相對穩定,損失值逐漸接近于1.
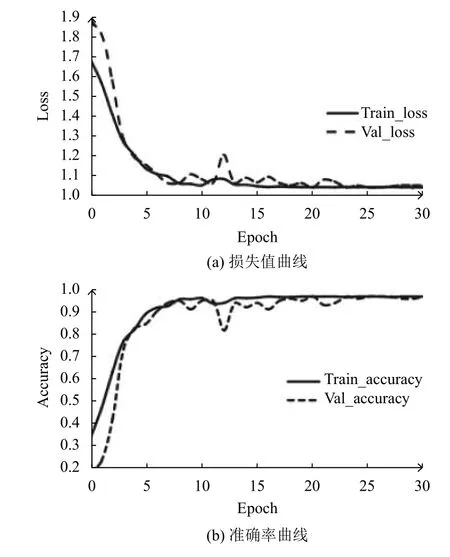
圖4 實驗結果曲線
3.3 模型評估
深度學習網絡分類模型常有的評估方式有精確度、召回率、準確率等,本文進行模型評估采用的是準確率.準確率(Precision)是指正確分類的樣本數與總樣本總數之比,計算公式如式(8)所示.
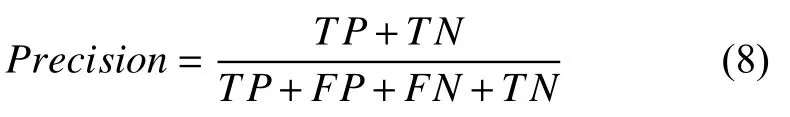
式中,TP指的是實際為正樣本網絡模型檢測結果為正樣本的樣本數量,TN指的是實際為負樣本網絡模型預測結果為負樣本的樣本數量,此外FP指的是實際為負樣本網絡模型預測結果為正樣本的樣本數量,FN指的是實際為正樣本網絡模型檢測結果為負樣本的樣本數量.
模型評估時采用的是另外采集的250 張圖片進行測試,在測試過程中將網絡模型輸出概率最大的類別作為圖片預測的最終結果.經過測試以及計算得到該模型的準確率為99.6%,其具體結果如表2所示.
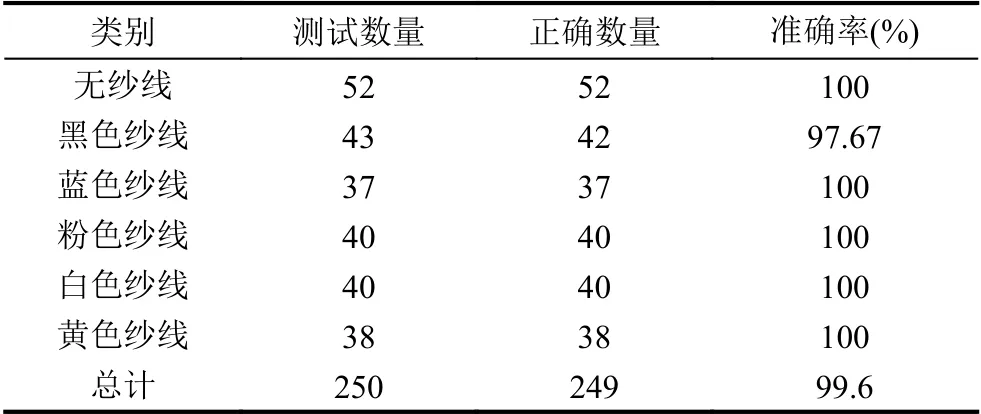
表2 模型測試結果
4 結論
為了實現對管道中的紗線及其顏色進行檢測,使用海康威視的工業攝像頭進行數據采集,經過篩選并去除重復以及有缺陷的圖片后,利用剩余的圖片構建數據集.此外網絡主要是由多尺度深度可分離卷積塊構成的,該結構塊是利用Inception v4 網絡中的Inception-ResNet-A 模塊在結構上進行改進得到的,改進后的多尺度深度可分離卷積塊大大降低網絡的計算量以及參數量.最后在網絡訓練過程中對圖片進行數據增強,擴大數據集的多樣性,從而降低網絡過擬合現象,最終實現管道中的紗線檢測功能.實驗結果表明,檢測準確率高達99.6%,因此該方法可以能夠滿足一定的實際應用需求.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
