基于Hadoop的視頻網站推薦算法研究
2021-06-29 02:08:38張文澤
科學技術創新 2021年17期
張文澤
(長江大學電子信息學院,湖北 荊州434000)
隨著當今互聯網的快速發展,每天會有海量信息產生,互聯網用戶容易迷失在信息海洋中無法找到目標內容。為了解決這種問題,推薦系統孕育而生。推薦系統是解決在“信息過載”下,用戶如何高效獲得自己感興趣目標信息的問題。從工程的角度來推薦系統可以分為兩大部分:數據部分和模型部分。數據部分主要指推薦系統所需數據流的工程實現。大數據優于好算法是指基于小數據的推薦效果不如擁有大量可用數據的推薦效果理想。而模型部分指的是推薦模型的相關工程實現,根據應用階段的不同,可進一步劃分。
1 Ha doop平臺與系統設計
1.1 Hadoop平臺架構
Hadoop是能夠對海量數據進行分布式計算處理的框架,它的核心是分布式文件系統(HDFS)和MapReduce。HDFS支持處理超大規模的文件,采用了主從結構模型,通常一個HDFS集群包括一個名稱節點和若干個數據節點。名稱節點它負責管理文件系統的命名空間以及客戶端的訪問請求。而數據節點它負責處理文件系統客戶端的讀寫請求。MapReduce它將復雜的并行計算的過程抽象到兩個函數:Map和Reduce。通過Map對數據進行分割,然后shuffle過程會對Map的輸出進行排序和合并,最后交給Reduce處理。
1.2 批處理大數據架構
批處理大數據架構采用了分布式文件處理系統,MapReduce代替了原來傳統文件系統和數據庫的存儲和處理方式,批處理大數據架構示意圖如圖1所示。
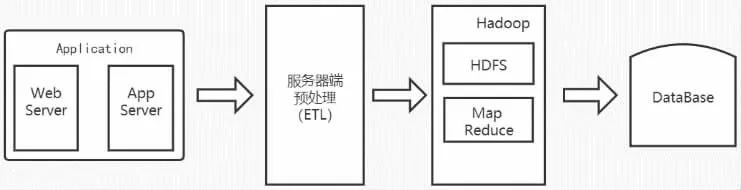
圖1 批處理大數據架構示意圖
2 推薦系統
2.1 推薦系統概述
推薦系統在獲知“用戶信息”“物品信息”“場景信息”的基礎上,通過構建好的函數模型,預測用戶對候選物品的喜好程度,再根據喜好程度對候選物品進行排序生成TOP-N列表。圖2是根據推薦系統的定義,抽象得到的邏輯框架圖。

圖2 推薦系統邏輯框架圖
2.2 協同過濾算法
協同過濾是協同所有的反饋對海量的信息進行過濾,從中篩選出目標用戶可能感興趣信息的推薦過程。按照推薦內容劃分,主要有基于用戶的協同過濾(UserCF)和基于物品的協同過濾(ItemCF)。UserCF主要是用戶相似度的計算,目標用戶的相似用戶對目標物品的評價是正面的,則可以預測目標用戶對物品的評價也是正面的。而ItemCF主要是計算物品的相似度,找到目標用戶的歷史正反饋的物品,通過與正反饋物品相似度進一步排序和推薦。兩者應用場景也有不同,UserCF具有社交特效,不會集中在固定的內容范圍。因此適用于新聞推薦等場景。ItemCF更適用于興趣變化較為穩定的推薦場景,因此用它來推薦視頻是更好的選擇。
2.3 基于物品的協同過濾算法流程
ItemCF是通過計算共現矩陣中物品向量的相似度得到相似矩陣,再通過與歷史正反饋物品的相似度,進一步得到推薦物品的列表。具體步驟如下所示:
(1)根據用戶的所有歷史數據,構建用戶為行坐標,物品為列坐標的共現矩陣。
(2)計算共現矩陣兩兩列向量的相似性,構建n*n維的物品相似性矩陣。
兩個向量之間通常采用的相似度計算是余弦相似度來衡量,計算兩個物品向量之間的夾角大小,夾角越小,余弦相似度越大,兩個用戶越相似。

但是對于式(1)來說,為了消除熱門因素帶來的影響,使用平均分因素對各評分進行修正,減小了用戶評分偏置的影響,采用皮爾遜相關系數對其修改完善。

其中,Ri,p代表用戶i對物品p的評分。Ri代表用戶i對所有物品的平均評分,P代表所有物品的集合。
僅僅針對用戶評分進行相似度計算,而忽視了實際當中每個人打分習慣的不同,通過引入物品平均分的方式,減少評分偏執的影響,如式(3)所式。

其中,Rp代表物品p得到所有評分的平均分。
3 實驗與分析
3.1 推薦系統的評價標準
推薦算法的評價指標主要分為在線評價和離線評價,在線評價是通過實時點擊率得到推薦算法的性能衡量。但是在線評價不利于實驗的開展,因此我們采用離線的方式。離線的方式是將訓練集的信息作為算法的輸入進行推薦,再將最后推薦的結果與測試集的結果作為對比。
在離線實驗中,在對單個物品的評分預測任務中,我們一般會采用計算預測評分與真實評分之間的絕對誤差(MAE)或者均方根誤差(RMSE)進行評估。
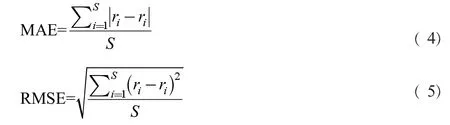
其中ri是第i個樣本點的真實值,ri是第i個樣本點的預測值,s是樣本點的個數。
3.2 數據集
本文使用的數據集是Netflix比賽的,整個數據集只有600MB,而實際的業務會達到GB,TB。數據集每行包含三個標簽字段,分別是用戶的ID,電影的ID,用戶對電影的評分。
3.3 環境配置
本文集群搭建是利用VMware搭建的,有一個Master節點和兩個Slave節點。系統使用的環境是Linux CentOS 7.0 ,配置如表1所示。

表1 分布式集群配置表
3.4 實驗分析
(1)測試MapReduce的運行速度(圖3)
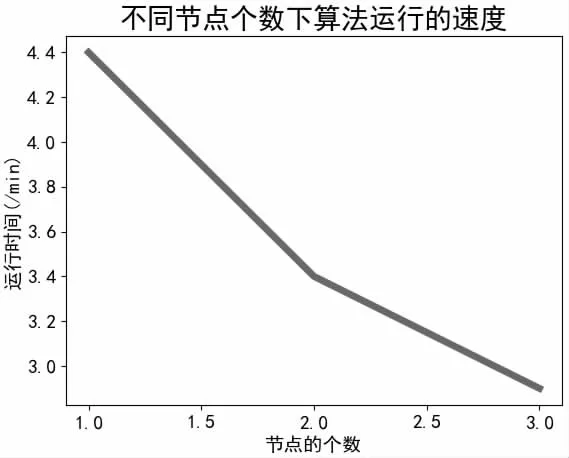
圖3 Ha doop平臺運行效率
結果表明,MapReduce會把一個存儲在HDFS中的數據集切分成許多獨立的小數據塊處理,節點的個數越多,運行效率會越高。
(2)為驗證算法的有效性,與傳統的協同過濾進行比較,使用相同數據集,在相同節點下進行RMSE值對比實驗,所得結果如表2所示。

表2 對比實驗結果
結果可以看出,在減少打分偏置和減低個人打分習慣因素下,基于物品的協同過濾比基于余弦相似度的協同過濾具有較低的RMSE值,RMSE值反映了預測值與真實值的偏離程度,即改進后推薦效果更加理想。
4 結論
借助大數據技術的推薦系統能很好地排除了用戶不需要的冗余信息的干擾,改善了用戶平時觀看視頻的體驗,推薦系統的研究是一個重要的研究方向,未來在該領域內擁有更加廣闊的空間。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
