基于LMD-PE與神經網絡的刀具故障診斷方法
2021-06-30 12:44:26楊瑞元何建樑王禹林
計算機測量與控制 2021年6期
楊瑞元,尹 晨,何建樑,王禹林
(南京理工大學 機械工程學院,南京 210094)
0 引言
機械加工離不開機床的使用,在使用機床進行加工機械加工時,需要對對刀具的磨損狀態進行精確地預測,以便在機械加工過程中提高機械加工的質量和效率。
在現有研究中,文獻[1]采用BP神經網絡融合多特征信息對刀具的狀態進行監測,雖然提高了監測的效率,但是BP神經網絡收斂速度慢,監測準度不高;文獻[2]采用了長短期記憶神經網絡對刀具的磨損狀態進行監測,雖然提高了監測的準確度,但是采用小波包變化和濾波器來提取特征能量值,會丟失部分關鍵特征。
基于以上內容,本研究采用局域均值分解排列熵(LMD-PE)刀具狀態的特征向量,輸入到訓練好的長短期記憶神經網絡(LSTM)中進行預測,使刀具的故障診斷效率和準確性均得到大幅度的提高。
1 基于LMD-PE和LSTM的刀具故障診斷
刀具出現的故障形式通常有破損和磨損。破損大部分都是錯誤使用刀具造成的,磨損是正常使用中不可避免的[3]。產生故障的刀具在加工過程會產生不同的振動信號,因為產生的振動信號噪聲大、信噪比低[4],采用LMD-PE對振動信號的處理和LSTM模型的訓練對刀具的故障類型進行預測。下面對LMD、PE、LSTM的原理進行介紹。
1.1 局域均值分解LMD原理
LMD可以根據刀具振動信號的局部極值點,采用波動不大的迭代循環方法進行迭代循環,便能夠將純調頻信號和包絡小信號從原始的振動信號中分離出來[5],然后對純調頻信號和包絡信號進行乘積得到PF分量,對于一個振動信號x(t),進行LMD分解的過程如下[6]:
1)x(t)是一個時間序列的振動信號,根據LMD原理首先要找出x(t)的所有局部極值點ni,計算極大值和極小值的均值以及包絡估計值:
(1)
(2)
式(1)中,mi為兩個極值的均值,式(2)中,ai為兩個極值的包絡估計值。
計算完成后,用直線將所有的mi,ai連接,然后采用移動平均法對連接后完成后的折線進行平滑處理[7],得到局域均值函數和包絡估計函數。
2)分離局域均值函數:
h11(t)=x(t)-m11(t)
(3)
式(3)中,x(t)為原始振動信號的時間序列,m11(t)為局域均值函數,h11(t)為分離后得到的函數。
3)對分離后的h11(t)進行降調:
(4)
式(4)中,h11(t)為原始振動信號的時間序列分離局域均值函數后得到的函數,a11(t)為包絡估計函數,s11(t)為h11(t)降調后的函數。
4)判斷s11(t)是否為純調頻信號,當a12(t)=1時,則認為s11(t)是一個純調頻信號,如果s11(t)不是一個純調頻信號,則計算進行步驟1)~3),直至a1n(t)=1為止,需要強調的是,在實際的運算中,a1n(t)≈1即可停止迭代[8]。
5)計算第一個分量的包絡信號:
(5)
式(5)中,a1n(t)為上述迭代運算產生的包絡估計函數,p為迭代次數。
6)計算原始振動信號的第一個PF分量[9]:
PF1(t)=a1(t)s1n(t)
(6)
式(6)中,a1(t)為第一個分量的包絡信號,s1n(t)為得到的純調頻信號。
7)將得到的第一個PF分量與原始振動信號的時間序列分離,得到一個新的時間序列,將得到的新的時間序列作為原始時間序列重復上述步驟1)~6),直到得到的新時間序列為一個單調函數為止,這時,原始振動信號的時間序列可以看做n個PF分量與最后的單調函數之和[10]:
(7)
式(7)中,uN(t)為最后得到的單調函數。
1.2 排列熵原理PE
排列熵是一種新的信息熵計算方式,能夠度量一個時間序列的復雜程度,該方法不僅計算速度快,還能夠準確地反映振動信號的微小突變行為[11],非常適合刀具的振動信號的處理和分析。其原理如下:
假設一個振動信號時間序列{X(i),i=1,2,…,N},采用相空間重構可以得到矩陣X[12]:
j=1,2,…k
(8)
式(8)中,τ為時間序列的延遲時間,d為嵌入維數,k為重構分量的數量,X(j)為矩陣X的第j行分量。
將X(j)按從小到大的順序排序,確定每個元素在向量中的位置j1,j2,…,jd。因為重構矩陣的空間維數為d,所以一共會有d!種排列可能,此時排列熵[13]的計算公式為:
(9)
式(9)中,HP為排列熵,Pj為排列的概率。
進行歸一化處理[14]:
(10)
最終得到的HP就是時間序列X(i)的排列熵。
1.3 長短期記憶神經網絡LSTM
在LSTM模型中,該模型的算法特點能夠對時間序列數據進行適當地預測,應用過程中采用了RNN循環神經網絡模型,進行有效地改進,實現數據信息的計算。首先需要構建RNN循環神經網絡,該模型在架構上包括輸入層、隱含層和輸出層[15]。其中隱含層在整個數據模型中具有舉足輕重的作用,是算法的核心部分,該算法的架構如圖1所示。
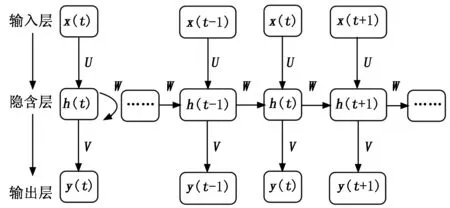
圖1 RNN結構
圖1中,x(t)為輸入序列,h(t)為隱藏層序列,y(t)為輸出序列。U、W、V為權重矩陣,則有:
ht=fa(Uxt+Wht-1+bh)
(11)
yt=fy(Vht+by)
(12)
式(11)、(12)中,fa、fy為激勵函數;bh為隱含層的偏置向量;by為輸出層的偏置向量。
RNN結構的隱含層如圖2所示。
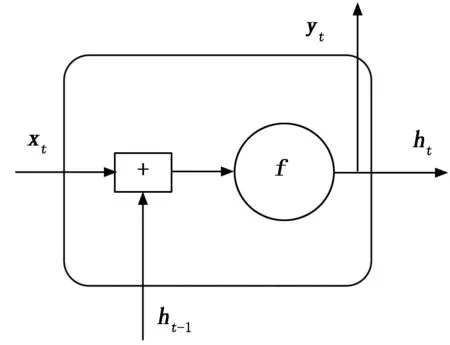
圖2 RNN隱含層結構
采用RNN循環神經網絡的目的在于:該模型具有較強的記憶功能,在處理關于時間序列數方面有突出的技術優勢,但是容易出現梯度消失、梯度紊亂、記憶時間短等技術弊端[16]。
在本研究算法的計算過程中,采用改進型LSTM循環神經網絡的特點在于:對RNN的隱含層的計算功能進行進一步地提升,下面通過模型結構對本研究的創新點進行說明,結構如圖3所示。
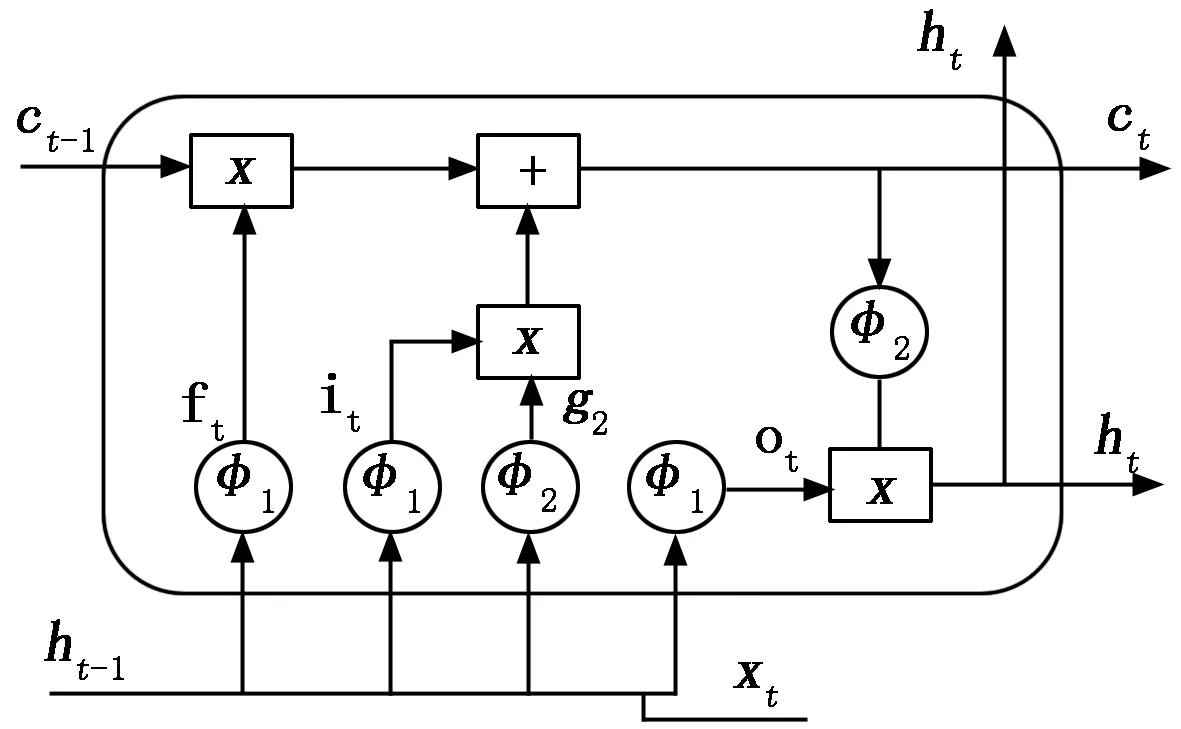
圖3 LSTM隱含層結構
在新型的架構設計中,在LSTM隱含層中融合多種智能控制門的計算,比如輸入門、遺忘門和輸出門等[17],即圖中的ft、it、ot,輸入門的作用是控制信息的輸入,遺忘門的作用是對輸入的數據進行預處理,輸出門的作用則是控制信息的輸出。圖中,t-1時刻的細胞輸出信息ct-1,ht-1經過函數φ1、φ2處理能夠得到t時刻的細胞輸出信息ct,ht,其中,φ1為sigmoid函數,φ2為tanh 函數[18]。
但是LSTM模型沒有解決RNN模型的預測滯后問題,因此需要對LSTM模型進行改造,卷積神經網絡(CNN)的優勢在于能夠從輸入的信息中提取到更高階的信息,同時把無用信息剔除[19]。基于此,本研究提出用CNN對輸入的時間序列信息進行降維處理,提現更高階的特征,再輸入到LSTM模型中進行訓練[20],這樣訓練速度就會大大加快,從而解決了預測滯后問題,同時CNN和LSTM使用相同的初始權重,不僅能夠增強網絡記憶模塊的性能,還能減輕網絡負載[21],具體結構如圖4所示。

圖4 改進LSTM模型結構
卷積神經網絡和LSTM模型使用相同的全連接層,這樣能夠保證卷積神經網絡提取的高階特征能夠完全傳遞到LSTM模型[22]。
1.4 刀具故障診斷
因為刀具在加工時的振動信號時間序列波動大,不宜直接輸入到LSTM模型進行故障診斷,因此要先對刀具振動信號的時間序列進行LMD-PE運算,然后再輸入到LSTM模型中,診斷的效果更好。
故障診斷的主要步驟:
1)采集刀具加工時的振動信號時間序列。
2)將振動信號發生的時間序列進行預處理,以獲取較為純凈的數據信息,通過LMD算法模型,將振動信號分解輸出多個PF分量,其中在這些PF分量中,能夠提取刀具的故障類型[23]。
3)選取合適的PF分量,剔除與原始刀具振動信號相關系數低的PF分量[24],因為刀具在加工時的振動信號會有噪聲干擾,這些噪聲的振動會影響到故障的診斷結果。
4)將提取出來的PF分量進行空間重構,進而計算出排列熵。
5)選取排列熵特征向量。
6)最后將輸出的刀具特征向量輸入到訓練的LSTM模型中,對提取的數據信息量進行訓練。
7)得到診斷結果。
2 實驗仿真
為了驗證上述刀具故障診斷方法的有效性,通過在CNN數控車床上使用YT-15和YT16兩種型號的硬質合金銑刀進行零件加工,這兩種型號的主軸以1 200 r/min的轉速進行旋轉,刀具進給量以0.02 mm的位移進行,切削深度以1 mm的深度進行。然后通過振動傳感器對刀具加工過程中的振動信號進行信息采集,采集頻率為50 kHz,采集時間為1 s,對上述兩種刀具的開始加工到報廢全加工過程進行振動采集,每切削十分鐘采集1次,將采集結果輸入到電腦進行處理和分析,其中電腦的硬件配置CPU為inter i7-4500 h,運行內存為16 G,硬盤內存1 T。
在刀具工作過程中采集到的刀具信號進行LMD-PE運算,得到7個乘積分量和1個最終的單調函數,刀具的故障特征就包含在這些乘積分量中,但是采集的振動信號會受到噪音的影響,如果直接進行特征提取則最后的故障診斷結果不準確,所以要求取乘積值與原始序列的相關值,求取結果如表1所示。
在表1的數據信息中,可以發現以下數據現象:與原始時間序列的相關系數相比,PF1、PF2、PF5和PF7差距較大,這表明通過LMD模型之后,輸出分解的的PF分量,相比于原始時間序列,存在較大的數據相關性,在這種數據信息中,將特征分量提取出來,其他數據信息分量與開始獲取的時間序列的相關性就顯得比較小,在進行數據分析時,就不將這些信息作為提取的重點來計算。為了提高數據分析的精度,需要將PF3、PF4、PF6和U這幾個分量剔除處理。

表1 乘積值與原始序列的相關系數
刀具故障產生的根本原因是刀具在高速運轉時與工件產生的摩擦力,即刀具在切削工件時,會受到工件的力[25],排列熵的計算就是捕獲刀具與工件之間的相互作用力的變化,選擇不同的嵌入維數就可以得到信號在不同頻率下的故障特征,這就需要對信息數據中的多個維數中的排列熵進行計算,嵌入維數越多,排列熵值也會隨之增加。不同維數之間的排列熵值區別很大,選取不同維數下的排列熵值沒有交叉耦合的故障特征向量作為輸入到模型中的向量。
為了驗證本研究的技術效果,將相同刀具故障信息的特征向量分別輸入到BP神經網絡和本文的改進LSTM神經網絡,觀察二者之間的處理效果,然后進行故障分析、對比。在采用BP神經網絡和LSTM神經網絡這兩種不同的算法模型進行刀具的磨損程度診斷時,一般會經歷以下階段,比如在進行刀具的磨損診斷時,存在初步磨損階段、正常磨損階段和劇烈磨損階段,每個階段分為前、中、后期,診斷結果如表2所示。
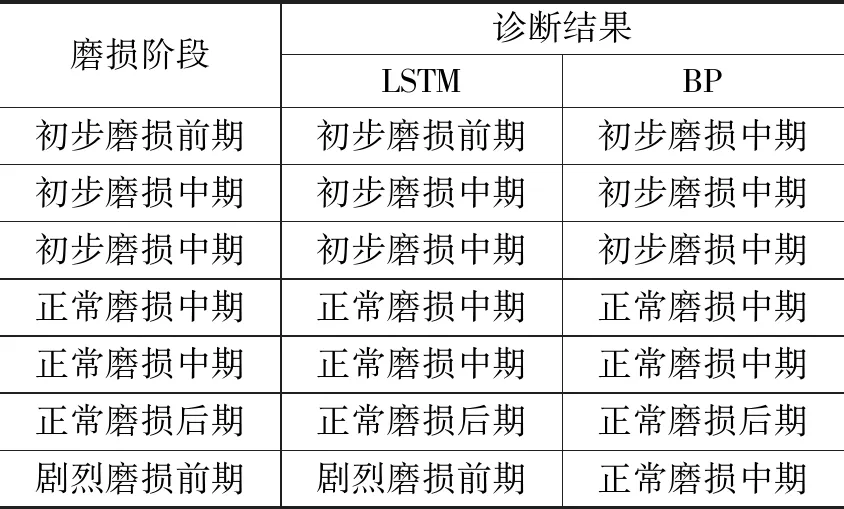
表2 刀具磨損程度診斷結果
通過表2中的數據可知,對于刀具磨損的診斷,LSTM的正確率比BP的正確率高。但是只根據對磨損的診斷結果并不能夠判斷方法對故障診斷的正確性,將兩種神經網絡的正確率進行統計,得到的正確率對比如圖5所示。

圖5 兩種神經網絡的診斷正確率對比
通過圖5可知,當試驗的樣本數量比較小時,利用LSTM模型的診斷時,其正確率在95%以上,BP模型的診斷正確率只有90%,隨著樣本數量的增多,兩種模型的診斷正確率都隨之降低,在樣本數大于200以后,LSTM模型的診斷準確率穩定在92%左右,BP模型穩定在78%左右,提高了12%左右。
下面對上述改進的LSTM模型和傳統LSTM模型的診斷效率進行對比試驗,采用上述數據輸入到兩種模型中進行診斷,不記錄診斷結果,只記錄診斷所需時間,將結果進行整理得到數據,如表3所示。

表3 診斷時間數據
從表中數據可以看出,在相同的樣本數量下,改進后的LSTM診斷時間比傳統的LSTM診斷時間少,通過計算改進LSTM的診斷時間比傳統LSTM診斷時間縮短了50%左右。
綜上所述,上述提到的刀具故障診斷方法的可靠性高。
3 結束語
通過對刀具的振動信號進行LMD-PE處理,選取合適的特征向量輸入到LSTM神經網絡中對刀具的進行故障診斷,通過驗證證明了方案的可行性并得出以下結論:
1)刀具的振動信號會受到噪聲的影響,采集的信號不能直接提取特征向量。
2)排列熵的計算嵌入維數盡量選取大的,有利于特征向量的提取。
3)LSTM神經網絡的診斷效率較慢,結合卷積神經網絡可以提高效率。
上述的方案能夠為刀具的故障診斷提供一定的思路,但是由于試驗樣本較少,故障診斷方法會有很多的不足,需要在實際的診斷中不斷地改進和完善。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
天天愛科學(2020年6期)2020-09-10 07:22:44
電子制作(2018年11期)2018-08-04 03:25:42
數學物理學報(2017年6期)2018-01-22 02:26:40
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
計算物理(2014年2期)2014-03-11 17:01:44
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
