基于USRP的調制信號識別系統
2021-07-01 05:21:56王龍龍陶麗偉魯興波馬瑞謙
物聯網技術 2021年6期
關鍵詞:信號
王龍龍,李 佩,陶麗偉,魯興波,馬瑞謙
(中國人民解放軍陸軍工程大學 通信工程學院,江蘇 南京 210007)
0 引 言
在非協同通信中,如何高效準確地識別發送端所發送信號的調制方式對后續信號的解調和處理至關重要。目前自動調制識別方法主要分為兩類:判決理論方法和模式識別方法。
判決理論方法是對碼元同步采樣序列進行處理,數學表達式極為復雜且處理的信號噪聲必須服從高斯分布,而實際環境中噪聲并不服從高斯分布并且存在多徑、信號干擾等問題,導致使用判決理論方法時,調制信號的識別率急速下降,難以在工程中應用。
模式識別方法首先需要提取調制信號的特征參數,然后設計分類器進行分類。常用特征參數的選取主要包括星座圖特征和時域特征等。文獻[1]通過減法類聚算法重構調制信號的星座圖實現低階MQAM識別。文獻[2]采用差分星座圖識別不同階數的正交幅度調制信號,但星座圖特征在信噪比不高的情況下很難判斷調制信號的階數。文獻[3]在高階累積量和分層多項式分類器基礎上識別出MQAM、MPSK和MASK信號。文獻[4]聯合幅度變換矩和線性相位對QPSK、DQPSK、BPSK、64QAM進行分類識別。
以上文獻對調制識別算法的研究只停留在軟件仿真模擬上,并不能很好地研究算法在實際環境中的可行性,故本文選擇將調制信號識別算法與USRP軟件無線電平臺結合,搭建調制信號識別系統,以驗證調制識別算法的可行性并進行性能分析。測試結果表明,時域特征在低信噪比環境下,實際參數與理論參數存在較大偏差,當基于決策樹理論進行信號識別時,識別效果不理想。故在特征提取的基礎上引入BP神經網絡算法,對調制信號的5種特征參數進行訓練并識別調制信號,較大提升了調制信號的識別率。
1 基于USRP的調制信號識別系統設計
1.1 系統設計
系統流程如圖1所示。首先生成隨機二進制序列,然后生成相應的調制信號[5],經USRP上變頻、數模轉換處理后通過TX1通道發射,經RX2接收及USRP模數轉換、下變頻處理后,LabVIEW對接收到的調制信號進行瞬時特征提取并計算特征參數,最后通過決策樹判決識別出調制信號。
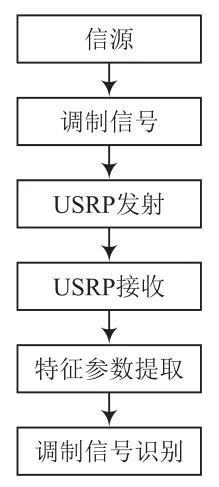
圖1 系統流程
1.2 調制信號的生成
2ASK信號的產生如圖2所示。Random Number.vi產生100個隨機比特,ASK System Parameters.vi輸入參數為每個符號的采樣數和ASK的調制階數,其中符號采樣數為32,M=2。將各種調制參數打包成簇輸出,簇中包括符號采樣數等。Filter Coefficients.vi輸入參數為脈沖成型濾波器、調制類型和脈沖成型濾波器每個符號的采樣數。選擇調制類型為ASK(5),脈沖成型濾波器選擇none(0),脈沖成型濾波器每個符號的采樣數為32。Modulate ASK.vi模塊輸入參數為比特序列、系統參數和符號速率等,返回復基帶信號(IQ數據),最后通過Upconvert Baseband.vi將基帶信號上變頻到帶通信號。
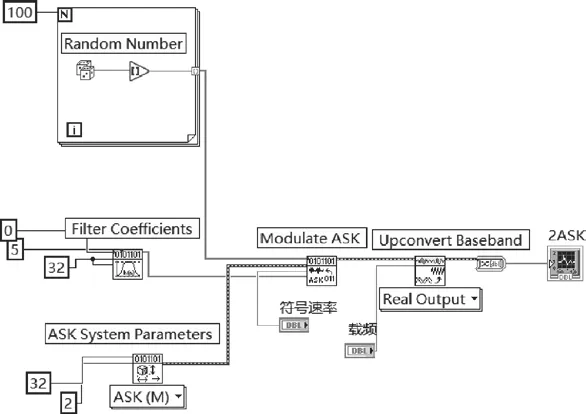
圖2 2ASK信號的產生
1.3 調制信號的發送
發送模塊后面板如圖3所示。通過LabVIEW調用NIUSRP函數庫將調制信號通過USRP發射出去,射頻發送端主 要 用 到 Open Tx Session.vi、Configure Signal.vi、Write Tx Data (poly).vi和Close Session.vi。
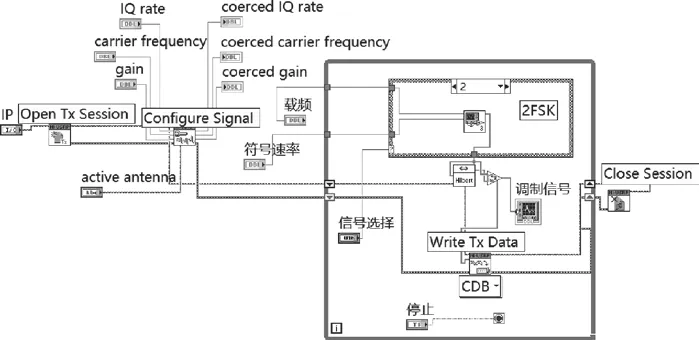
圖3 發送模塊后面板
發送模塊前面板如圖4所示。調制信號符號速率為100 Hz,載 頻 為 200 Hz,USRP設 置 IQ rate為 500 kHz,carrier frequency為900 MHz,gain為15 dB,選擇TX1通道發射,通過下拉框架選擇發送的調制信號。
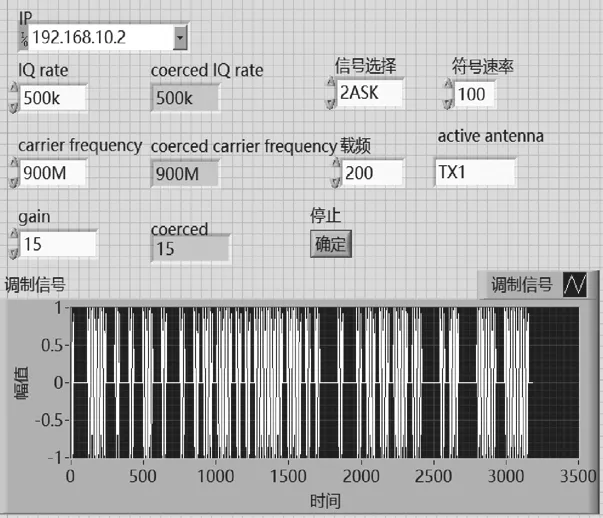
圖4 發送模塊前面板
1.4 調制信號的接收
信號接收模塊后面板如圖5所示。調制信號的接收通過LabVIEW調用NI-USRP的函數庫。主要用到的USRP函數庫包括 Open Rx Session.vi、Initiate.vi、Fetch Rx Data(poly).vi、Abort.vi和Close Session.vi。信號接收模塊前面板如圖6所示,USRP的 IQ rate、carrier frequency設置與發送端一致。
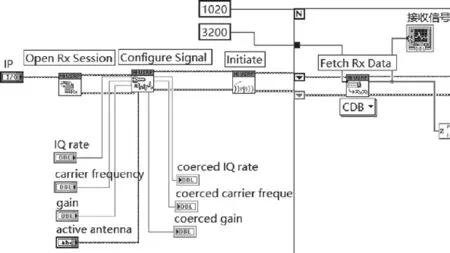
圖5 接收模塊后面板
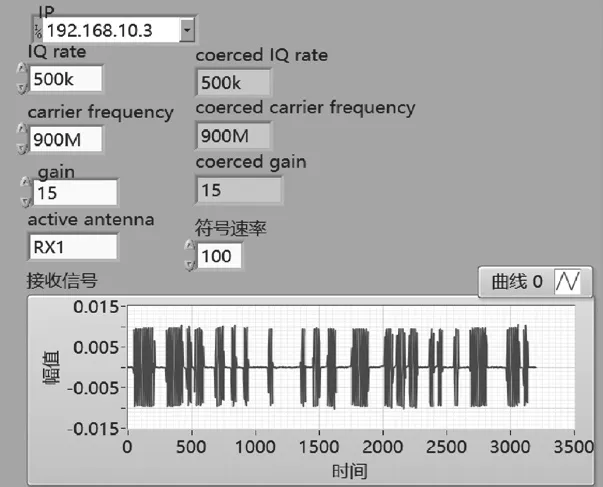
圖6 接收模塊前面板
2 調制信號識別
通過feature extraction.vi提取瞬時幅度、瞬時相位和瞬時頻率[6],然后分別計算瞬時幅度之譜密度的最大值γmax、歸一化中心瞬時頻率絕對值的標準差σaf、瞬時相位非線性分量絕對值的標準差σap、瞬時相位非線性分量的標準差σdp、零中心歸一化瞬時幅度絕對值的標準差σaa。
2.1 零中心歸一化瞬時幅度之譜密度γmax
γmax是對信號瞬時幅值變化的表征,主要識別幅度有變化與幅度恒定不變的調制方式。此外,通過設置合理的閾值,還可以區分無包絡起伏的FSK和包絡微弱起伏的PSK信號,6種調制信號的γmax如圖7所示。MASK、MPSK的γmax大于MFSK的γmax,閾值設置見表1所列,大部分情況下通過設置閾值0.9即可區分MASK、MFSK、MPSK信號。
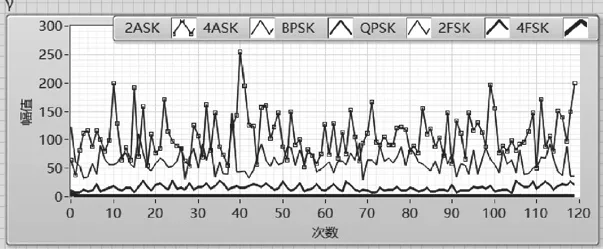
圖7 MASK、MFSK、MPSK信號的γmax

表1 MASK、MFSK、MPSK信號的γmax
2.2 零中心歸一化非弱信號段瞬時頻率絕對值的標準差σaf
σaf表征信號的絕對頻率,用來區分2FSK與4FSK,如圖8所示,4FSK的σaf大于2FSK,通過設置閾值1即可區分兩者,但區分效果一般。
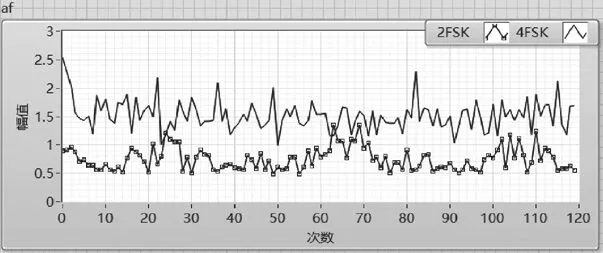
圖8 2FSK、4FSK的σaf
2.3 零中心非弱信號段瞬時相位非線性分量絕對值的標準偏差σap
σap表征了信號瞬時絕對相位的變化情況,可以用來區分含有絕對相位信息的信號(如QPSK)和不含絕對相位信息的信號(如BPSK、MASK)。如圖9所示,QPSK的σap大于MASK和BPSK的σap,閾值設置見表2所列,大部分情況下可以通過設置閾值150來區分QPSK、BPSK、MASK。
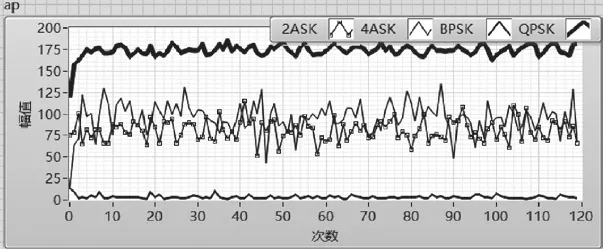
圖9 MPSK、MASK的σap

表2 MPSK、MASK的σap
2.4 零中心非弱信號段瞬時相位非線性分量的標準差σdp
σdp表征了信號直接相位的信息,用以區分含有直接相位信息的信號(如BPSK)和不含直接相位信號的信號(如MASK)。如圖10所示,BPSK的σdp大于 MASK的σdp,但結果表明區分效果并不理想,通過設置閾值2來區分BPSK和MASK。
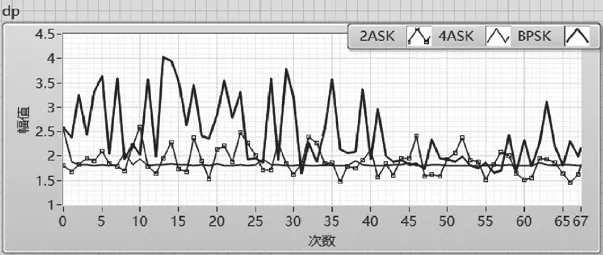
圖10 BPSK、MASK的σdp
2.5 零中心歸一化瞬時幅度絕對值的標準偏差σaa
σaa是對調制信號絕對幅值的表征,可以用來區分像2ASK這種不具備歸一化的絕對幅度的調制方式和MASK(M≥4)具有歸一化的絕對幅度的調制方式。如圖11所示,4ASK的σaa大于2ASK的σaa,大部分情況下設置閾值0.25即可實現區分。
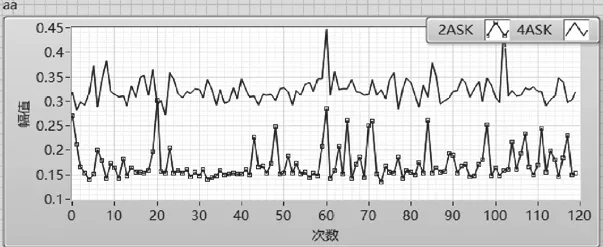
圖11 2ASK、4ASK的σaa
如圖12所示,調制信號識別程序提取調制信號的瞬時特征值并計算5種特征參數。
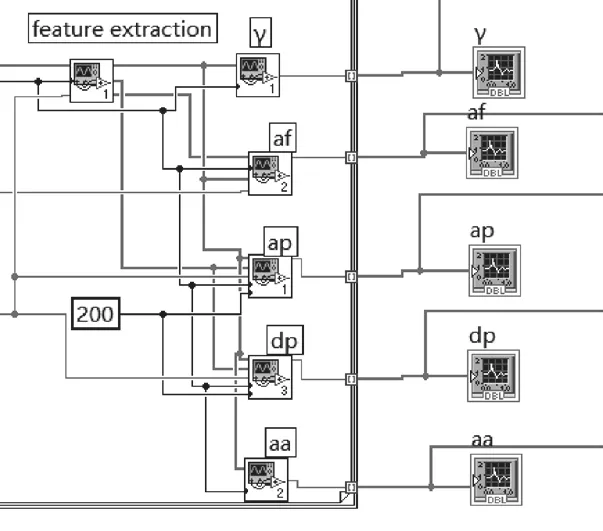
圖12 調制信號識別后面板
提取調制信號的特征參數后,根據決策樹理論進行判決,判決流程如圖13所示,t(*)代表閾值。調制信號識別前面板如圖14所示,經過決策樹判決后,計算調制信號的識別率,并在程序前面板顯示識別出的調制信號類型和信號識別率。
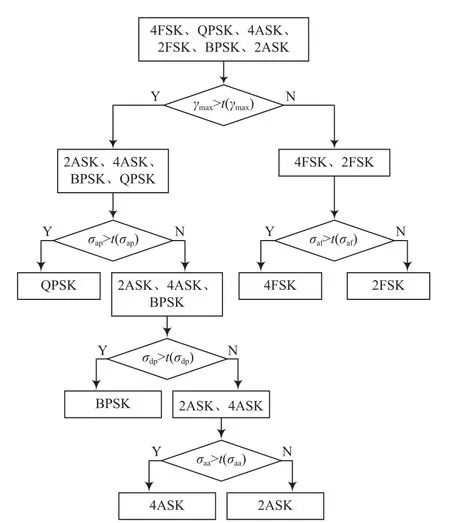
圖13 決策樹[7]
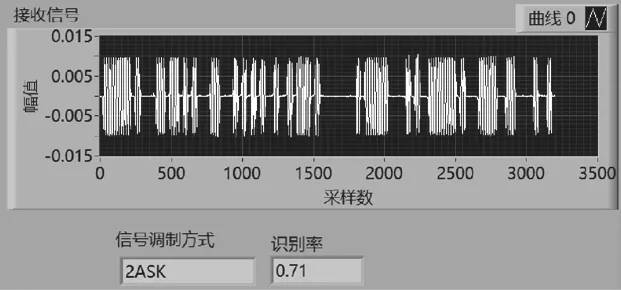
圖14 調制信號識別前面板
通過實測發現,在環境低信噪比情況下,基于決策樹理論的信號識別方法效果不理想。σaf、σdp的區分效果不佳,根據決策樹理論,σaf區分效果影響了2FSK、4FSK的識別,σdp的區分結果直接影響BPSK、2ASK、4ASK的識別。調制信號識別率見表3所列,2ASK、BPSK的區分效果并不理想,4ASK、MFSK的識別率也并未達到90%。為提高信號識別率,引入BP神經網絡算法對幾種特征參數進行訓練并識別調制信號。

表3 信號識別率 %
3 采用BP神經網絡的調制信號識別系統
3.1 BP神經算法介紹
BP神經網絡的計算過程由正向傳播過程和反向傳播過程組成。正向傳播過程中,輸入層輸入5種特征參數,然后將其傳輸到隱藏層,隱藏層處理數據后將其傳輸到輸出層。如果輸出的結果與期望值誤差不能滿足設定的最大誤差,則轉入反向傳播,將誤差信號沿原來的連接通路返回,通過修改各神經網絡的權值,最小化誤差信號[8]直到滿足期望值時,輸出識別的調制信號。
3.2 信號識別的實現
因為LabVIEW并未內置神經網絡模塊,所以本文通過LabVIEW中MATLAB腳本調用MATLAB神經網絡庫函數[9]對信號進行識別。BP神經網絡算法如圖15所示,輸入層為5種特征參數,輸出層為6種識別信號,學習效率為0.1,訓練次數為5 000次,最大誤差為10-4。

圖15 BP神經網絡算法
3.3 結果分析
BP算法識別率見表4所列。

表4 BP算法識別率 %
從表4可以看出,6種信號的識別率超過92%,與表3相比,識別率得到大幅提升(尤其受σaf、σdp影響的MFSK、MASK和BPSK信號的識別),驗證了BP神經網絡算法在調制信號識別應用中的可行性。
4 結 語
本文在USRP硬件平臺上實現了基于調制信號特征參數提取的信號識別算法,建立決策樹結構對信號進行分類。結果表明,該算法在環境低信噪比情況下信號識別率并不高,因此,本文進一步引入BP神經網絡算法,對5種參數進行訓練,然后識別出調制信號的調制方式。結果表明,應用神經網絡進行調制信號識別達到了較為理想的識別率。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
