魯棒性協同過濾研究
2021-07-02 01:56:54易喬敏
現代計算機 2021年13期
易喬敏
(四川大學計算機學院,成都610065)
0 引言
大數據時代,推薦系統作為一種重要的信息過濾技術,在幫助用戶快速發現自己感興趣的內容上發揮了重要作用,因而被廣泛部署到各種在線應用中。推薦系統旨在從用戶的歷史交互/反饋中捕捉用戶的興趣或偏好,并提供個性化推薦。例如,網易云音樂根據用戶的聽歌記錄提供歌單推薦;微博根據用戶的興趣推薦相關的博主;淘寶根據用戶的瀏覽足跡在用戶主頁展示其可能感興趣的商品等。
在各種推薦系統中,協同過濾已經成為主流的推薦方法之一,其思想是相似的用戶有相似的偏好,相似的商品具有相似的特征。典型的協同過濾方法主要包括3種類型:基于用戶的協同過濾、基于商品的協同過濾和基于模型的協同過濾。為了提高協同過濾的性能,許多工作開始考慮輔助信息[8,21,32],如社交網絡、商品標簽,等等。盡管如此,大多數現有協同過濾方法仍依賴于一個潛在假設,即用戶歷史反饋可以真實有效地反映用戶的興趣或偏好。然而事實上,用戶歷史反饋往往是有噪音的,當大數據時代尤其如此。例如,用戶在淘寶上的一次商品點擊可能是一個隨機行為導致的自然噪音,其不能代表用戶的真實興趣;豆瓣上某個用戶對某部電影的評分可能因用戶評分時的愉悅心情而高于其對電影本身的滿意度,因此產生噪音評分。又如,某些電商利用畫像注入攻擊產生許多惡意噪音,以此操縱推薦系統來達成某些商業企圖。惡意或非惡意噪音的存在使協同過濾方法難以準確地捕捉用戶的真實偏好,當用戶的歷史交互發生改變時,缺乏魯棒性的協同過濾方法難以產生穩定的推薦結果,甚至推薦性能顯著降低。因此,如何從有噪音的用戶反饋數據中有效捕捉用戶的真實偏好,對提高推薦的魯棒性至關重要。事實上,準確且魯棒的個性化推薦一方面有利于提升用戶對推薦結果的滿意度和信任度,另一方面也有助于提升應用的用戶粘性,帶來經濟利益。
1 魯棒性協同過濾
根據Robust Statistics[1]對算法魯棒性的定義,本文從三個層次來分析協同過濾算法的魯棒性:
第一,魯棒性協同過濾應該具有較高的推薦準確性。為了提高推薦性能,除了考慮用戶的歷史反饋數據,許多協同過濾推薦算法利用輔助信息或混合模型[2-4]來捕獲用戶偏好。諸如社交網絡、用戶/物品屬性、知識圖譜等輔助信息有助于學習更好的用戶和商品表達以提升推薦性能;混合模型組合不同推薦模型的推薦結果,以集成的方式提升推薦準確性。
第二,魯棒性協同過濾應該具有一定的處理用戶反饋中自然噪音的能力。事實上,用戶的交互行為或評分行為常常是不完美的,魯棒性推薦要求推薦模型在面對有自然噪音的用戶反饋時,能夠在一定程度上保持推薦結果的準確性和穩定性。因此,魯棒性協同過濾需要從噪音反饋中挖掘用戶的真實偏好。
第三,魯棒性協同過濾應該具有一定程度的抵抗惡意噪音的能力。受某些經濟利益的驅動,一些惡意用戶有目的地向推薦系統注入大量虛假用戶畫像,從而提升或降低某些物品被推薦的可能性[5]。然而,惡意用戶的推薦目的往往不符合大多數其他用戶的期望,故顯著降低個性化推薦性能。防止惡意噪音對推薦系統產生災難性的影響是魯棒性推薦的一大挑戰。
一些研究已經關注到推薦的魯棒性問題[5-7,9-13]。早期工作[5-7,11-13]主要集中于研究推薦算法抵抗惡意噪音的能力。為了提高推薦系統對惡意攻擊的魯棒性,一些方法[5,12]通過分析真實用戶與可能的惡意用戶之間打分行為的差異識別惡意用戶,從而提前過濾惡意用戶或降低惡意用戶的數據對模型學習的影響。文獻[7]總結了八種不同的注入攻擊策略和惡意噪音環境中魯棒性協同過濾的三個方面的技術,包括攻擊策略、探測策略和魯棒性推薦算法。其中,魯棒性推薦算法專注于對惡意噪音的探測和過濾,例如文獻[12]通過交替進行聚類去噪和訓練SVD兩個過程,提高SVD的魯棒性。此后,針對惡意噪音的魯棒性推薦算法致力于控制惡意攻擊的影響,因為直接過濾可能的噪音會同時消除一些真實的用戶畫像。近年來,基于神經網絡的協同過濾方法被廣泛研究,在自然噪音環境中,針對推薦系統的兩大任務,即評分預測和Top-K推薦,一些研究者已經提出了不同的魯棒性神經推薦模型。
2 魯棒性協同過濾用于Top-K推薦
2.1 現有研究
在自然噪音環境下,魯棒性Top-K推薦旨在從噪音交互中準確捕捉用戶的真實興趣或偏好,以產生準確且穩定的個性化Top-K推薦列表。現有魯棒性Top-K協同過濾方法,其大致可分為兩種類型。一種現有工作通過在訓練過程中向訓練數據或模型參數中注入額外噪音來提高推薦模型的魯棒性[9,14-16],另一種現有工作則利用變分自編碼器(VAE)等生成模型獲得魯棒的用戶和商品嵌入以提高推薦模型的魯棒性[17-19]。
基于噪音注入的方法包括兩種類型。一種方法將降噪自編碼器引入Top-K協同過濾。例如,根據降噪準則,CDAE[15]在模型學習時以一定概率對用戶交互向量進行drop-out破壞,之后從破壞的用戶交互向量中學習用戶隱表示以重構原始交互向量;通過最小化重構誤差,CDAE能夠從破壞的用戶交互向量中學習魯棒的隱表示,從而具有一定的容噪能力。另一種方法引入對抗訓練和對抗噪音提高模型的魯棒性[10,18,20]。例如,文獻[14]提出對抗個性化排名方法APR,該方法利用對抗訓練在模型學習過程中為模型參數引入一定水平的對抗噪音,從而學習魯棒的用戶和商品表示,提高貝葉斯個性化排名方法的魯棒性。由于基于神經網絡的協同過濾算法優秀的推薦表現,文獻[9]提出一個通用的對抗學習框架,致力于同時提高基于神經網絡的推薦模型的Top-K推薦性能和魯棒性。
然而,這兩種基于噪音注入的方法仍有兩個不足。第一,模型的魯棒性依賴于一個先驗確定的噪音注入水平,固定的噪音水平忽略了不同用戶個性化的噪音分布;第二,基于對抗噪音的方法需要設置恰當的對抗噪音水平,從而平衡模型的推薦性能和魯棒性,防止過強的對抗噪音降低模型的推薦表現。
近年來,由于變分自編碼器強大的表示學習能力,一些工作提出基于變分自編碼器的魯棒性Top-K推薦模型[19,21]。例如,文獻[19]提出一個推薦變分自編碼器模型,簡稱RecVAE,該模型為變分自編碼器的推斷網絡設計了一個新的網絡結構,并結合降噪準則從用戶的隱式反饋數據中捕捉用戶偏好,大大提升了Top-K推薦的性能。這些研究也證明,變分自編碼器能夠很好地處理稀疏的用戶交互向量。
對于基于變分自編碼器的Top-K推薦方法的魯棒性,本文從兩個角度進行闡述。第一,變分自編碼器基于用戶歷史交互為每個用戶學習一個隱表示的高斯分布,該分布建模了用戶交互數據的不確定性,其中高斯分布的方差刻畫了用戶個性化的噪音水平;第二,變分自編碼器的優化使用了重參數技巧,重參過程相當于為潛空間引入隨機噪音,從而為推薦模型引入了隨機性,有利于提高模型的泛化性能。然而,一些研究也指出,變分自編碼器傾向于學習一個單模態的潛特征空間,其缺乏足夠的表達能力以捕捉隱表示的真實后驗分布。在推薦系統的應用場景中,用戶-商品的交互數據常常蘊含多模態的特征,即不同用戶或不同商品具有不同的偏好分布或特征分布。因此,許多基于變分自編碼器的推薦模型常常難以捕捉多模態的偏好分布。
2.2 未來研究方向
本節總結了自然噪音環境下,魯棒性Top-K推薦仍面臨的兩大挑戰:第一,不同用戶的交互數據具有不同的噪音水平;第二,不同用戶的偏好分布是多模態的。因此,魯棒性推薦需要自適應地建模用戶的個性化噪音水平,同時具有足夠的表達能力以捕捉用戶的多模態偏好。
現有工作利用變分自編碼器的網絡結構為解決第一個挑戰提出了一種解決方法,但是原始變分自編碼器難以處理多模態的偏好分布。為了捕捉多模態的數據分布,文獻[23]提出WAE,其具有VAE的優良特性,但利用Wasserstein距離保持了潛特征空間的多模態,從而鼓勵模型近似真實的數據分布;文獻[24]引入生成對抗網絡(GAN)[20]并提出一種名為對抗變分貝葉斯(AVB)的訓練技巧,使推斷網絡能夠更靈活地近似真實的后驗分布;文獻[25]將AVB的思想引入協同過濾推薦。與此同時,作為另一種強大的生成模型,生成對抗網絡具有強大的捕捉數據分布的能力,因此現有工作也開始探索GAN在推薦領域的應用,主要包括兩個方面:第一,利用GAN學習用戶隱表示,以捕捉用戶的潛特征偏好;第二,利用GAN直接生成用戶交互向量。然而,不像圖片常常具有稠密的向量表示,推薦系統中稀疏的用戶交互數據為GAN學習用戶偏好分布帶來新的挑戰。由于變分自編碼器正好具有很好的處理稀疏數據的能力,本文認為未來的工作可以結合GAN和VAE這兩種強大的生成模型為Top-K協同過濾任務設計一種新的網絡結構,以同時捕捉個性化的噪音分布和多模態的偏好分布,從而提升Top-K推薦的準確率和魯棒性。
3 魯棒性協同過濾用于評分預測
3.1 現有研究
在自然噪音環境下,魯棒性評分預測旨在從噪音反饋中準確捕捉用戶的真實偏好,以準確且穩定地重構“用戶-商品”評分矩陣。利用評分預測進行推薦最早被學術界廣泛研究。自從2006年Netflix大獎賽以來,推薦系統開始從學術界被引入工業界,并廣泛應用于各種電子商務應用中。Netflix大獎賽主要解決電影評分預測問題,其中矩陣分解(MF)方法大獲成功,成為主流的協同過濾算法之一。MF迭代訓練一個低維用戶矩陣和一個低維商品矩陣,使這兩個矩陣的乘積近似原始評分矩陣,從而補全原始評分矩陣并據此進行推薦。顯而易見,以MF為代表的評分預測方法的性能依賴于用戶評分的真實有效性。然而,一些研究已經發現用戶評分是有偏差的。文獻[25-26]指出,當用戶被要求再次評分其曾經評分過的商品時,只有大約60%的用戶保持相同的分數。事實上,由于記憶損失、用戶偏好難以量化以及許多其他因素,大量的可觀測評分是有噪音的,這些噪音評分會影響協同過濾模型在評分預測任務上的準確性和魯棒性。
早期主要有兩種方法處理評分中的自然噪音:第一,移除噪音評分或噪音用戶畫像[28-29];第二,通過獲取再評分數據探測和糾正噪音評分[2,22]。然而,估計誤差導致直接移除可能的噪音會同時錯誤地刪除非噪音評分,增加評分矩陣的稀疏性,而記憶偏差、用戶意愿等因素導致難以保證再評分數據的真實有效。
近年來,一些方法致力于僅利用歷史評分訓練魯棒的評分預測模型,其主要包括對噪音評分的糾正和降低噪音評分的影響兩種思想[26-27,32]。文獻[27]利用噪音探測和噪音糾正兩個過程來處理自然噪音,其主要缺點是需要先驗地定義一些分類標準和并劃分分類區間,最終的預測模型的性能依賴于噪音探測和噪音糾正的質量,而噪音探測和糾正的質量可能受到不完美的預測模型的影響,并且噪音探測過程中使用預設的閾值劃分分類區間,沒有考慮到用戶評分層次的個性化。最近,一些方法通過降低噪音評分在模型損失中的權重來提高模型訓練的穩定性和評分預測準確性[26,32]。文獻[32]發現現有的自適應學習率方法可以提高模型在稀疏數據上的收斂表現,然而用戶評分不僅稀疏且有噪音,對噪音數據設置小的學習率有利于降低噪音數據對模型學習的干擾。文獻[26,32]以不同方式實現了自適應學習率的評分預測算法,旨在提高評分預測模型對自然噪音的魯棒性。
3.2 未來研究方向
個性化噪音分布和多模態偏好分布同樣為魯棒性評分預測帶來巨大挑戰。由于神經網絡強大的信息抽取能力,利用神經網絡自適應地評估用戶評分中的自然噪音是一個很有前景的研究方向。另外,相對于隱式反饋來說,顯式的用戶評分數據往往具有更高的稀疏性,成為魯棒性評分預測的另一大挑戰。直觀地,神經網絡的訓練依賴于訓練數據的規模,稀疏的評分數據通常導致神經網絡模型訓練不足而難以捕捉用戶的真實偏好分布。因此,本文認為設計一種合適的網絡結構,其能夠在識別噪音的同時實現有效的數據增強,有利于提高模型在稀疏且有噪音的場景下的評分預測魯棒性。
4 實驗
本節,我們在兩個真實的數據集上比較了現有魯棒性推薦算法的性能。
4.1 數據集
我們在MovieLens 1M和Digital Music數據集上進行實驗。這兩個數據集的統計信息如表1所示。

表1 數據集統計信息
在MovieLens 1M數據集中,每個用戶至少有20個評分。Digital Music數據集是來自亞馬遜的一個公開數據集,其原始數據集具有較高的稀疏度,我們僅保留至少有5次評分的用戶和商品。對于Top-K推薦任務,我們將顯式的評分轉化為隱式的0-1交互數據。
4.2 對比方法
對于Top-K推薦任務,我們在CDAE[15]、APR[14]、ACAE[9]、RecVAE[19]和NeuMF[3]上進行了實驗;對于評分預測任務,我們在AdaError[32]、Norma[26]和MF上進行了實驗。其中,NeuMF是一種神經協同過濾的通用框架,該方法采用多層感知機建模用戶和商品的潛特征之間的非線性交互;MF是一個矩陣分解模型,該方法學習用戶和商品的低維嵌入向量,并使用向量的內積為預測評分。
4.3 評價指標
4.3.1 Top-K推薦評價指標
對于Top-K推薦任務,我們采用留一法進行評估,即對于每個數據集,我們為每一個用戶抽取一條交互數據用于測試,該方法被廣泛應用于Top-K推薦評估[9,14-15,33]。需要注意的是,對于每個數據集,我們以類似構造測試集的方式構造驗證集,用于調整超參數。由于在測試時對每個用戶進行所有商品的排序非常耗時,因此我們采用文獻[15]和[33]的做法,即檢查測試集中用戶已經交互過的商品是否排在事先隨機選擇的99個該用戶未交互過的商品之前。我們采用命中率(HR)和歸一化折扣累積增益(NDCG)來衡量Top-K推薦性能。命中率的計算公式定義為:

其中rel i表示排名為i的物品是否被命中,若命中則rel i=1,否則r el i=0。HR和NDCG都是越高越好。
4.3.2 評分預測評價指標
對于評分預測任務,對于每個數據集,我們按8:2隨機劃分訓練集和測試集,之后在訓練集中隨機留出20%的評分構成驗證集。我們采用RMSE(Root Mean Square Error)和MAE(Mean Absolute Error)作為評價指標。定義如下:
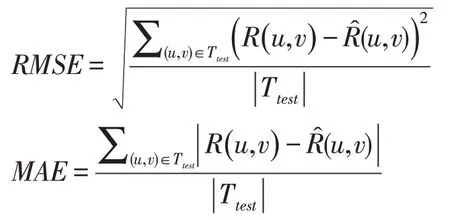
其中,T test表示測試集。
4.4 實驗結果
表2展示了在兩個數據集上各個方法的Top-K推薦表現。除了NeuMF以外,其他方法都以不同方式考慮了噪音交互。通過實驗指標我們發現,考慮了噪音交互的魯棒性方法并不一定具有最優的Top-K推薦性能。例如,在Digital Music數據集上,魯棒性推薦方法APR、ACAE和RecVAE的表現好于未考慮噪音交互的NeuMF,但是在MovieLens 1M數據集上,NeuMF優于所有的魯棒性方法。另外,魯棒性推薦方法在不同的數據集上表現有所差異。例如,RecVAE和APR分別是MovieLens 1M和Digital Music數據集上最好的魯棒性推薦方法。這些實驗結果證明了個性化噪音水平和多模態偏好可能是影響推薦模型魯棒性的重要因素。
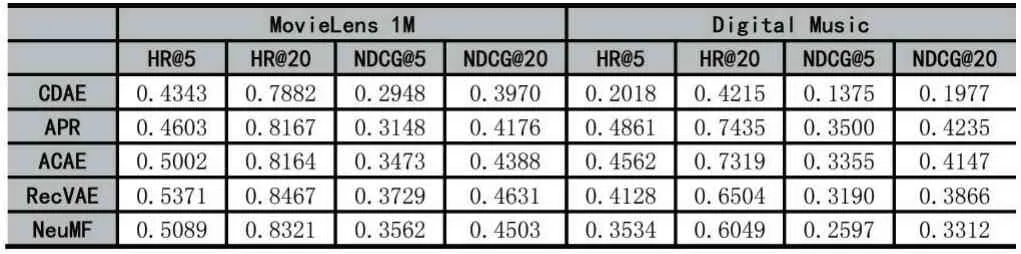
表2 所有模型在MovieLens 1M和Digital Music數據集上的Top-K推薦表現
表3展示了在兩個數據集上各個方法的評分預測準確性。其中,MF沒有考慮噪音評分。通過觀察實驗指標我們發現,考慮了噪音交互的魯棒性評分預測方法并不總是具有最優的表現。例如,在MovieLens 1M數據集上,Norma具有最好的表現,而同樣考慮了噪音評分的AdaError的表現甚至差于MF;在Digital Music數據集上,MF的評分預測表現最好,Norma的性能差于AdaError。我們認為,這樣的結果可能與數據集的不同稀疏性有關。
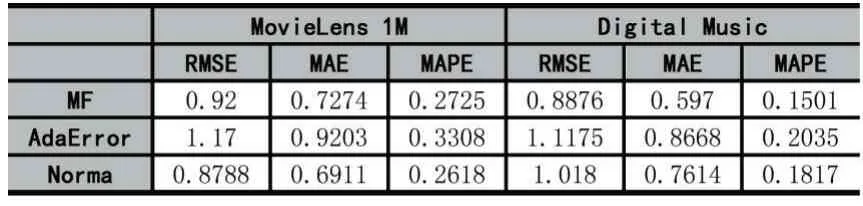
表3 所有模型在MovieLens 1M和Digital Music數據集上的評分預測準確度
5 結語
本文總結了噪音環境下魯棒性協同過濾的研究現狀,重點回顧了自然噪音環境下基于神經網絡的魯棒性Top-K推薦和評分預測方法,并在兩個真實的數據集上進行了實驗。最后,針對Top-K推薦和評分預測兩大任務,本文分別提出一些魯棒性推薦的未來研究方向。實驗結果顯示了本文提出的研究方向對于提升推薦模型魯棒性的可行性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
