CallN:基于卷積神經網絡的Android惡意軟件家族分類技術
2021-07-02 01:56:54劉易葉凱
現代計算機 2021年13期
劉易,葉凱
(1.四川大學網絡空間安全學院,成都610065;2.棕北中學,成都610041)
0 引言
隨著Android手機用戶大幅增長,移動終端出現大量Android惡意軟件。根據2019年Android惡意軟件專題報告顯示,360安全中心全年截獲移動端新增惡意樣本為180.9萬個,平均每天截獲惡意程序樣本0.5萬個[1]。Android惡意軟件通常采用消耗手機資費、竊取手機隱私、遠程控制手機等攻擊行為,這使得移動智能終端安全受到嚴重威脅。現有Android惡意軟件檢測方法能有效識別已知樣本,但不能有效檢測改造升級后的新版本Android惡意軟件,也不利于對新型惡意軟件進行溯源。
當前Android惡意軟件特征提取技術主要為動態分析和靜態分析,通過獲取Android應用程序權限、API以及字節碼等信息作為特征。William等人[2]提出污點分析系統TaintDroid,用于檢測Android應用中敏感數據泄露。通過修改Android虛擬機解釋器,TaintDroid實現系統級別污點追蹤,發現大量應用存在地理位置、設備ID、電話號碼等數據的泄露。Chen等人[3]監控運行狀態下API調用,結合半監督機器學習,準確識別惡意軟件。動態分析技術能夠應對混淆、加殼等問題;需要的特征體量相對較少,無需頻繁更新特征。但是動態分析需要在監控下進行真機的運行[4],耗時、占用過多系統資源特性難以應對大量惡意軟件識別。靜態分析通過逆向工程分析Android應用信息,這種方式不需要在真機實時運行,能夠快速分析大量應用軟件。Schmidt等人[5]基于Opcode對惡意樣本進行分類,與此類似的有Zhou等人[6]提出了DroidMoss,將Android應用軟件的DEX文件反編譯為Dalvik字節碼,并通過Opcode來計算應用軟件的模散列值,結合應用軟件的作者信息作為應用軟件的“指紋”判定Android應用是否被重打包,以此判定Android應用的惡意性。此類方法能夠較為精準地判定Android惡意樣本。Fan[7]、Zhang[8]、Yang[9]等人通過頻繁調用子圖來關聯惡意An?droid應用。
Suarez-Tangil等人[10]提出基于文本挖掘方法,計算代碼結構相似性進行分類。Massarelli等人[11],基于Drebin數據集,采用動態分析、SVM對惡意軟件進行家族分類,準確率達到82%。Kim等人[12],基于BitDe?fender標記的8個家族中682個樣本,采用動態分析和靜態分析進行特征提取,通過計算相似性對惡意代碼進行聚類,準確率達到97%。Fan等人[13],從功能調用圖中提取頻繁調用子圖,通過計算子圖相似性實現惡意軟件分類,準確率達到94.2%。Fasano等人[14]基于靜態分析,對12個惡意軟件家族進行家族分類,平均準確率達到96.1%。Canfora等人[15],分析在編譯源代碼時生成的Java字節碼,并識別每個惡意軟件家族的惡意行為,準確率達到97%。Chakraborty等人[16],提出一種既能對樣本數量規模大和樣本數量規模小的家族進行分類,有效實現分類和聚類。雖然現有的方法在家族分類上取得很好的效果,但是在特征提取的粒度還有待提高,以取得良好的兼容性和可用性。為解決這些問題,本文提出基于拓撲排序的數據預處理過程,使得API調用具有節點依賴的特性,并結合CNN深度學習框架進行分類的方法。
本文采用Androguard分析Android應用,得到API調用圖,基于創建的API數據集對API調用圖進行剪枝與標記;再將調用圖轉換為RGB三通道圖像;采用本文提出的CallN作為卷積神經網絡分類器原型框架;最后根據實際傳入圖像特征以及分類的需求,對深度卷積神經網絡進行微調,以此實現對Android惡意軟件分類。將Android應用轉換而成的RGB圖像與API調用序列的拓撲排序成對應關系。隨機提取的特征是一組滿足調用順序的特征序列,使得特征同時滿足隨機性和有效性。分類器與樣本集是相互獨立的,這樣有效避免分類方法只針對某些樣本集有效的情況。
本文的主要工作和貢獻如下:
(1)本文提出一種基于API調用圖的特征選擇方法,基于拓撲排序優化了惡意軟件的行為特征提取的隨機性、有效性。
(2)基于Res2Net殘差連接思想,結合Android惡意軟件特征圖規模小的特性,本文提出CallN模型以更細粒度提取惡意軟件的特征,能有效提高惡意家族分類的準確率。
(3)實現原型系統,在Drebin數據集上對本文提出的模型進行驗證,達到99.93%分類準確率,能夠有效對Android惡意家族進行準確分類。
1 算法實現
1.1 概述
本文提出的方法主要分為Android惡意軟件特征圖轉換、卷積神經網絡兩部分。Android惡意軟件特征圖轉換過程包括API數據集構建、靜態特征分析、對API調用圖進行處理并轉換為RGB圖像。卷積神經網絡部分輸入Android惡意軟件轉換而成的RGB圖像,該圖像是長為M寬為N的三通道圖像。由于CNN卷積神經網絡要求輸入圖像的尺度相同,輸入神經網絡之前需要對不同大小的圖像進行插值式采樣轉化成一樣大小的圖像。利用輸入圖像訓練分類模型,網絡輸出是對各個Android惡意軟件類的家族類別的預測。技術架構如圖1所示。
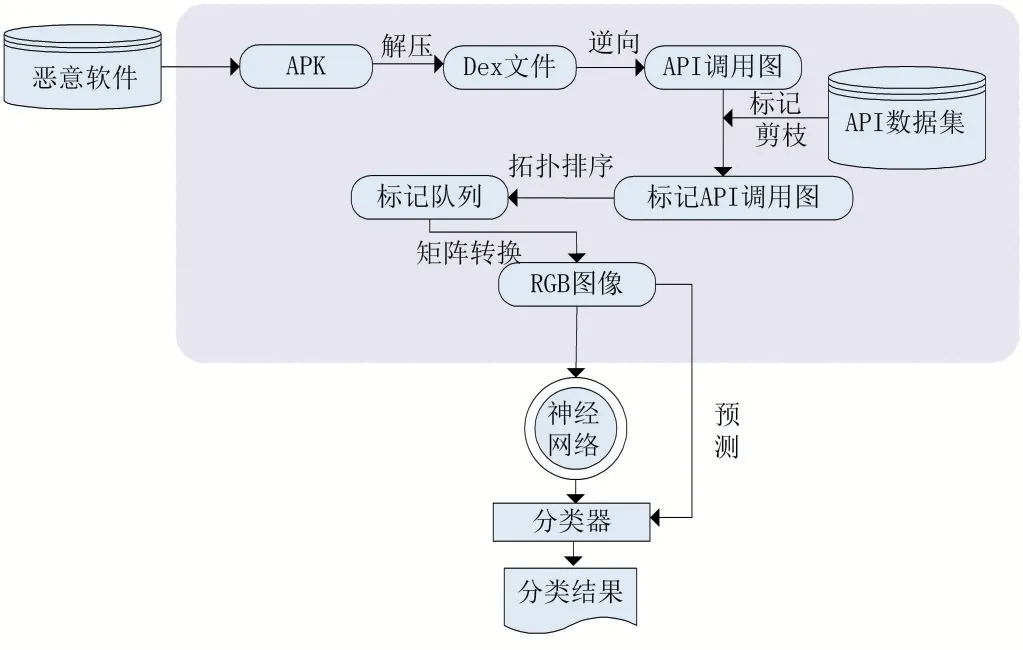
圖1分類技術架構
圖1 表示本文提出的方法技術架構。Android惡意軟件特征圖轉換:將惡意軟件進行解壓獲得Dex文件;利用Androguard分析惡意軟件得到API調用圖;利用API數據集對API調用圖進行剪枝、標記得到用數字標記的API調用圖;對標記API調用圖進行拓撲排序得到一個由數字組成的隊列;將數字隊列轉換為矩陣從而轉換為RGB圖像。卷積神經網絡:通過轉換的圖片作為輸入,通過卷積計算、提取特征、訓練分類器,利用分類器對圖像信息進行預測。
1.2 Android惡意軟件特征圖轉換
Android應用程序由資源文件、配置文件、簽名文件等所有內容組成的APK文件。因此DEX文件代表一個Android應用的軟件的主要特征。本文將DEX文件作為分析對象,利用Androguard分析惡意軟件得到API調用圖。Android程序軟件的API調用圖能夠表現出程序的主要特征,將API調用圖轉換為一個圖像,可以追蹤應用軟件的特征。
本文建立一個API數據集,基于此數據集對調用圖進行剪枝并且標記。API數據集規則:基于安卓開發者網站官方提供的API1-API29的所有API數據,作為官方提供的API,設置為激活狀態;非官方提供的API設置為休眠狀態即不使用該API,當處于休眠狀態的API在不同的惡意軟件中出現,將該API由休眠狀態改為激活狀態。轉換過程如圖2所示。
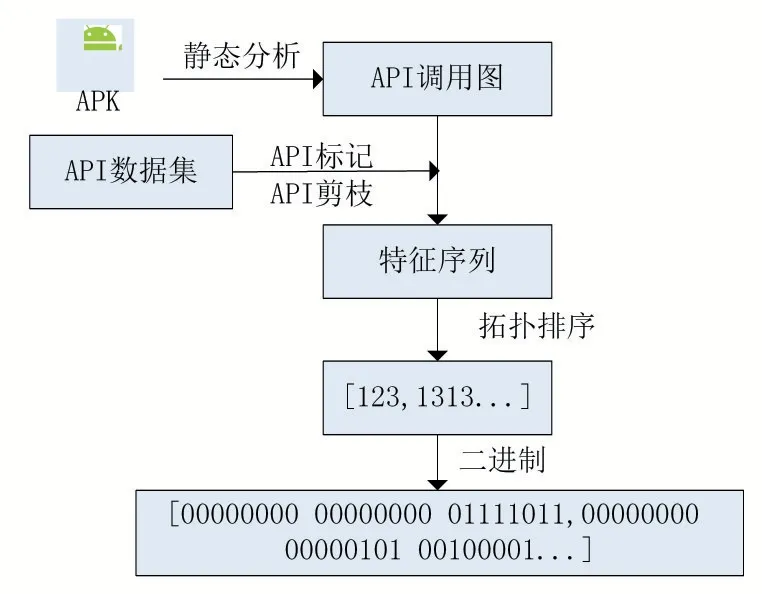
圖2 APK轉換過程
在圖2中,表示一個完整的APK轉換為RGB圖像的過程,通過靜態分析獲取調用圖,利用API數據集中已標記好的API將API序列轉換為一個由數字組成的向量,并且根據API數據集中提供的激活狀態API數據進行剪枝。得到的特征序列進行拓撲排序并輸出一個數值向量,將向量中每一個數字轉換為24位的2進制的數據,得到的2進制向量重構為(n,m,3)的矩陣。選擇二維矩陣的寬度和高度(即圖像的空間分辨率)主要取決于API序列的長度。矩陣寬度和高度轉化過程如表1所示。
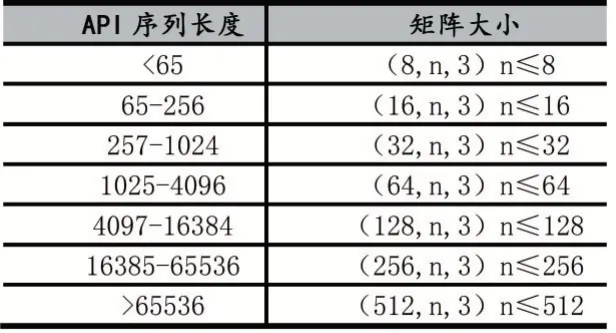
表1 矩陣轉換規則
圖3中表示剪枝過程,基于API數據集將API調用圖中處于休眠狀態的API刪除,將休眠狀態的API刪除生成新的依賴連接。圖3表示刪除節點的流程,API B處于休眠狀態的API,因此將B刪除,使A指向C、D。
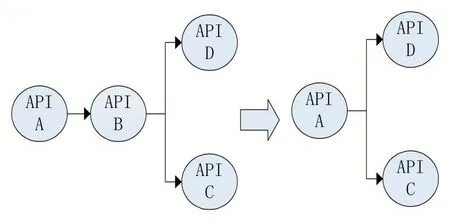
圖3 API序列剪枝
API調用圖是一個有向圖,保存的形式為點(Node)、邊(Edge)。因此API調用圖的剪枝過程就是對點和邊進行操作。
剪枝算法的偽代碼描述如算法1。
算法1:剪枝算法


1.3 卷積神經網絡模型
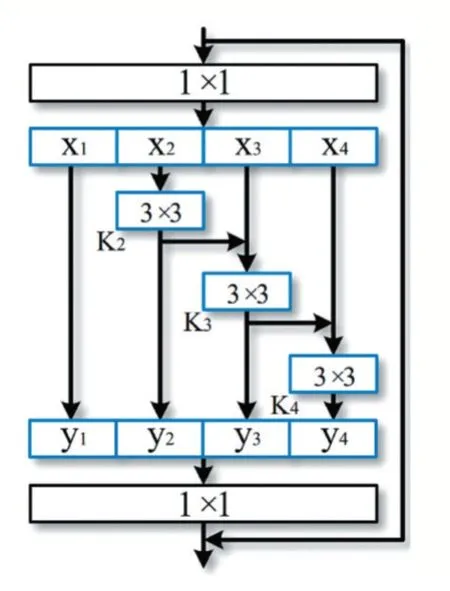
本文采用卷積神經網絡對Android惡意軟件進行分析,基于Res2Net[17]殘差連接思想對惡意軟件進行特征提取。Res2Net用3×3過濾器組,將不同的過濾器組以層級殘差式風格連接,可以得到不同數量以及不同感受野大小的輸出。例如y2得到3×3的感受野,那么y3就得到5×5的感受野,y4同樣會得到更大尺寸如7×7的感受野。最后將這四個輸出進行融合并經過一個1×1的卷積。這種先拆分后融合的策略能夠使卷積可以更高效更細粒度的處理特征。
基于Res2Net能夠高效提取細粒度的特征,同時Android惡意軟件的特征圖的規格小于普通圖像,對Res2Net進行改進。本文實現Res2Net模型以及對Res2Net進行改進,將改進的部分模型命名為CallN,CallN將3×3過濾器改為2×2與3×3的交叉過濾器組提取特征。
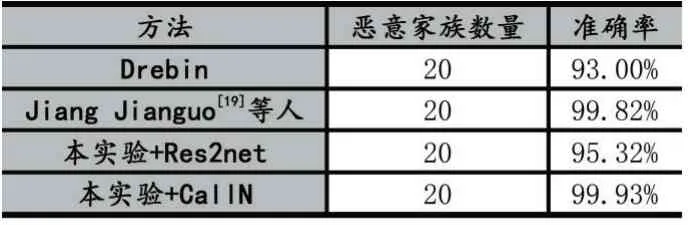
CallN輸入是由Android惡意軟件轉換而成的圖像,長度和寬度設定為固定大小的圖像,采用填充的方法對輸入圖像的尺寸進行處理。圖5為本文提出模型CallN,首先輸入t張特征圖,對圖像進行1×1卷積分為{Xi|0 圖5 CallN模型 當一組過濾器對一組特征圖提取特征之后,自上一組特征圖提取的特征傳遞到下一組特征圖中與下一組的特征圖進行特征提取,直至最后一組。得到特征{yi|0 圖4 Res2Net模型 為驗證本文提出的惡意軟件分類方法是否能夠有效檢測惡意軟件家族。本文基于Drebin[18]數據集,選擇Drebin數據集中家族規模前20的惡意軟件家族進行分類實驗,卷積神經網絡部分采用本文提出的CallN模型以及Res2Net模型。 Drebin作為Android惡意軟件家族分類模型的樣本集,Drebin數據集包含來自179個Android惡意軟件家族的5560個樣本。實驗選擇家族規模前20的惡意軟件家族共計4728個惡意軟件,訓練集、驗證集和測試集的比例為8:1:1。 本次實驗是在64位Windows10環境下進行,實驗配置如表2所示。 表2 實驗環境 在圖5中表示基于CallN模型對20個家族分類訓練結果,在圖5(a)表示訓練分類準確率,以及驗證分類準確率,其中紅色曲線為訓練集準確率,藍色曲線為驗證集準確率。圖5(b)表示訓練集損失值和驗證集損失值。在圖5(a)第一時期(epoch)訓練集準確率為68.81%,驗證集準確率為69.35%。在前150時期中,batch_size設置過低導致訓練結果呈現輕微震蕩,在本實驗中設置batch_size為8。隨著訓練時期的增加,隨后的訓練中曲線較為平滑并且呈收斂趨勢。根據圖6的數據表明,隨著訓練時期增加,準確率呈上升趨勢,損失呈減少趨勢。通過300時期的訓練,分類模型的訓練準確率達到99.99%,驗證準確率達到99.93%。 圖6 20個惡意家族分類實驗結果 為驗證CallN的有效性,本文采用預先劃分并且未參與訓練的457個惡意軟件對建立的模型進行交叉驗證。圖7為分類結果的混淆矩陣,預測結果表明所有的家族樣本能夠被準確分類。 圖7 分類結果熱力圖 在表3中計算20個惡意家族的精確率、召回率、F1-score。其中能夠對18個惡意家族進行準確分類,FakeRun中一個惡意軟件被分為GinMaster。 表3 20個惡意家族分類結果 在與已有相關工作對比過程中,本文采用Drebin中20個惡意家族的惡意樣本進行分類實驗,與Drebin方法以及Jiang Jianguo等人的研究進行對比。如表4所示。 表4 其他工作對比 結果表明,本文提出的CallN對惡意家族的分類準確率是優于現有的方法,達到99.93%。對比Res2Net結合本文的數據預處理方法的分類效果,CallN針對Android惡意軟件特征圖的分類效果更為理想。 本文提出一種基于卷積神經網絡(CNN)的An?droid惡意軟件檢測與分類的方法。首先將Android惡意軟件樣本轉換成RGB圖像,然后訓練一個分類模型對RGB圖像進行分類,以此實現對Android惡意軟件的分類。本文在Drebin樣本集上進行分類,在20個惡意家族進行分類實驗,取得99.93%的分類準確率。后續會尋找更多的數據集進行測試,取得更多的實驗數據,提升本方法的實用性。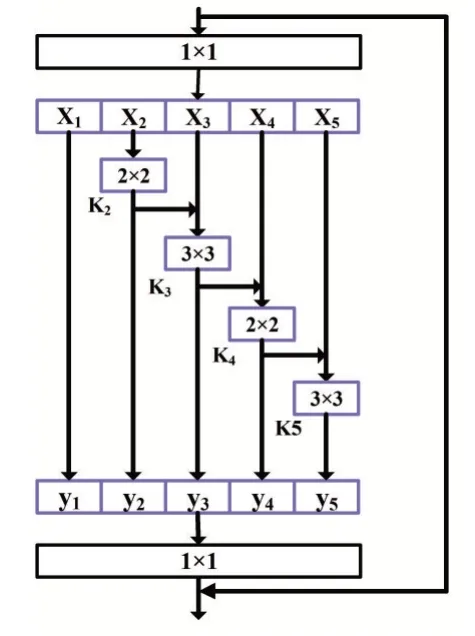
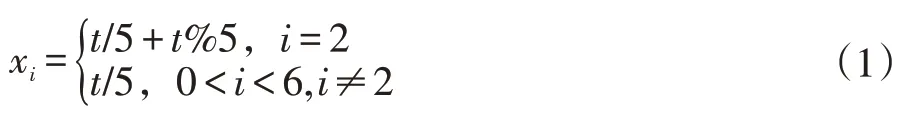
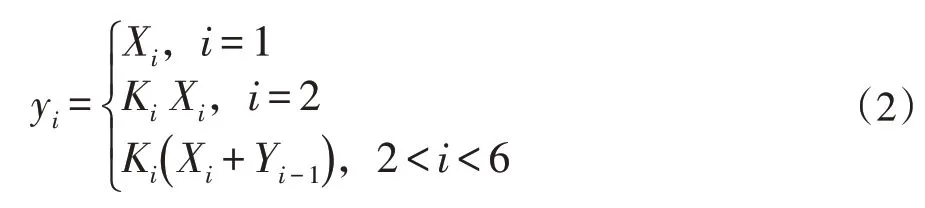
2 實驗評估
2.1 實驗數據集及實驗環境
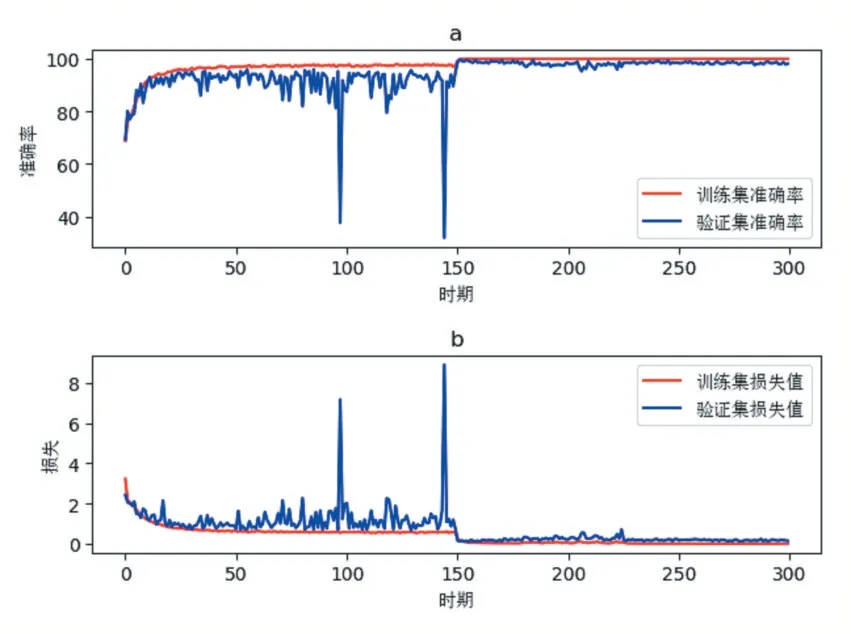
2.2 實驗結果與分析
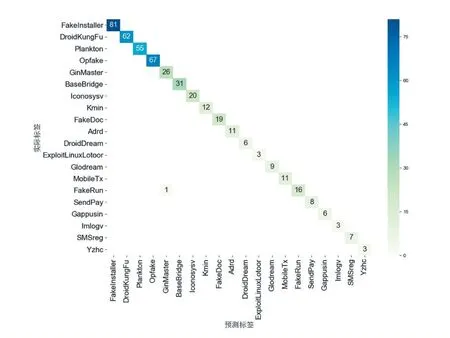
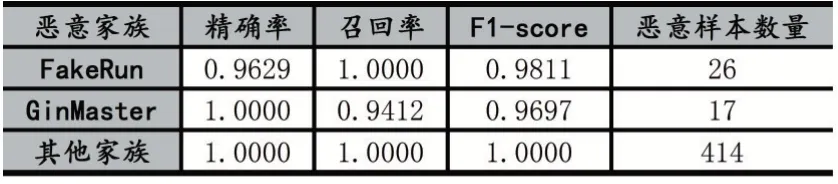
3 結語
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56大眾健康(2021年6期)2021-06-08 19:30:06世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28當代陜西(2019年10期)2019-06-03 10:12:04中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
