個人大數據的定價方法設計
2021-07-02 01:56:56郭妍彤
現代計算機 2021年13期
關鍵詞:信息
郭妍彤
(四川大學計算機學院,成都610065)
0 引言
數據時代的快速發展給人們的生活帶來了很多便利,可以幫助我們足不出戶的采購、交易甚至是辦理政務手續,政府及企業也越來越重視對數據的管理及開發利用;但是大數據巨大的應用價值導致數據泄露事件頻出,并且人們帶來了騷擾廣告和詐騙電話等困擾。現在的個人數據所有權管理混亂,個人數據所有者不但無法很好的使用個人數據來獲得利益,反而深受數據泄露之擾,導致個人用戶也缺乏了提供數據的積極性,需要數據的需求者也很難通過合法合規的渠道來獲得自己需要的數據。為此,麻省理工學院媒體實驗室Sandy Pentland教授2010年提出個人數據商店(Personal Data Store)理念,鼓勵人們貢獻和分享數據[1],并基于此產生了一種新的數據管理理念——個人數據銀行。個人數據銀行是指將個人數據當作一種新型的“貨幣”存儲在個人數據銀行中,建立一種大數據資產管理運營系統,將個人用戶授權后的信息進行采集、清理、共享和使用,同時給個人用戶一定比例的利息作為回報。
在構建個人數據銀行的過程中,如何合理地對個大數據進行定價也是一個需要解決的問題,一個良好的定價方式可以對個人數據銀行的運行和數據的流通起到促進作用。
1 研究介紹
個人大數據最大的特點在于數據提供者的不同及數據質量的參差。個人大數據的數據提供者是許許多多不同的個人用戶,他們在授權平臺對其采集數據后,會源源不斷地制造各種不同種類、不同質量的數據。這些數據并不都有相似的數據質量,也會因為授權等級而有許多不同的差異,比如相似的個人運動中的一條跑步數據,提供者A允許平臺收集地理位置信息,那么這就是一條擁有完整跑步期間軌跡信息的跑步數據,而提供者B不允許收集地理位置信息,那么這就是一條只有時間、長度及速度的跑步記錄。雖然都是相似的跑步信息,但是這樣不同的數據包含了不同的價值和信息量,在個人數據銀行中所能獲得的收益也應該不盡相同。
將數據商品和以前的一般商品相比較而言,其衡量價值和價格的屬性也與一般商品有很大的差別,定價已經不是以前“成本驅動”的定價時代了[2]。現如今數據市場越來越大,人們對數據的需求也越來越多,但是數據定價方式還沒有形成統一的評價標準。在數據定價中,首先要將視線轉移到“價值驅動”上,正確地衡量數據的質量和價值,同時以此對數據進行差異性定價,是最需要解決的問題。其次,在現有的數據定價方法中,大多數都是以包為數據定價的基本單位,這樣無法區分每條數據的差距,對于每條元組來說都是一樣的平均價,這對于個人數據銀行這樣的構建前提來說,并不適合。不同的數據根據其信息量不同、價值不同、重要程度不同等差異,應有不同的價格,如果每條元組的價格一致,那么無法給個人用戶提供激勵以促進大家提供更多高質量的數據。
2 個人數據銀行定價設計
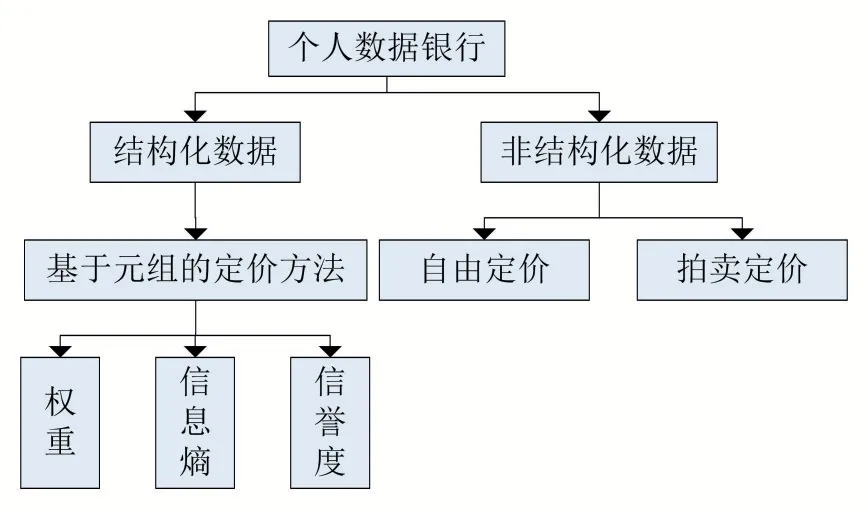
圖1 個人數據銀行定價總體設計
首先,我們先根據數據的結構不同,將數據分為結構化數據和非結構化數據。
在現在的數據流通中,格式化數據是使用最多的數據,小到一條外賣訂單、大到一張醫療診斷單,其實都是一種結構化的數據。為此,我們將根據國家標準的《信息安全技術個人信息安全規范》中的分類標準對結構化數據進行劃分,在數據經過脫敏后劃分成個人基本資料、網絡身份標識信息、個人健康生理信息、個人教育工作信息、個人財產信息、個人通信信息、聯系人信息、個人上網記錄、個人常用設備信息、個人位置信息、其他信息等十二類數據,并對每組信息設定好已有的數據結構模式及規模,進行整理及清洗。
而其他無法被輕易收集并處理成結構化數據的個人大數據,如個人的制作的視頻集、個人拍攝的地貌圖等個人用戶愿意提供的有價值的數據,統一分為非結構化數據。
2.1 結構化數據的定價
針對不同種類的數據,應該有不同的定價方式。像是結構化數據,因為其不同的數據元組是由不同的數據提供者所提供,所以在數據的定價中,需要能夠區分每一條數據,因為根據每一條數據的價值不同該數據的數據提供者所獲得的收益也是不同的。對此,Shen[1]提出了以元組為基礎的定價方式。在這種定價方式中,數據的最小衡量單位是元組,而其具體定價主要由三個部分影響,分別是:屬性權重、數據熵和數據提供者的信譽值。
其中影響數據的因素為信息熵(q)、權重(w)及R指數(r),其對應的權重分別為α、β、γ,則滿足以下約束:
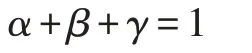
則每個元組的價格P i為:
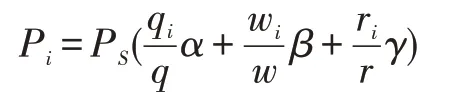
其中P S為整個數據集分成的價格。
這種方法中使用了信息熵來衡量數據中不同數據項的信息量,用權重來衡量數據中不同類型數據的價值含量,用信譽值來衡量數據提供者的信譽值。
但是在該方法中,并沒有給出權重設計的詳細方式,所以需要根據數據分類的情況,對數據的權重進行新的劃分。我們可以將數據根據《信息安全技術個人信息安全規范》分類后,再根據每類數據中的詳細分類對個人用戶的重要性來對數據權重進行劃分。
在該方法中,數據信譽度是根據所有數據的數據售出的次數而衡量的,但是在實際應用中,數據的售出次數與數據提供者的信譽度并沒有很大關聯,如果數據提供者剛好提供了售出次數多的數據類型,并不代表這位數據提供者的其他信息也是高質量的。因此,在本節設計中,將數據信譽度R值進行重新定義,如定義1,其中數據質量為數據信息熵和數據權重的加權和。
定義1如果某個用戶的數據元組至少有r條數據質量大于r,那么這個用戶的數據引用指數為R,稱為“R指數”。
在此基礎上,我們可以將數據質量M定義為如下公式:

在個人數據銀行中,數據需求者可以根據數據質量M、信息熵、權重和r指數來對數據質量進行篩選,可以給數據需求者更多樣化的選擇。
2.2 非結構化數據的定價
對于非結構化的數據,已經有規模的數據可以像結構化數據一樣,為其定義幾個反映其數據質量的指標,并根據數據指標對其進行數據價值的加權衡量。但是由于個人大數據的種類繁多,并不是所有的非結構化數據都可以很好地用這種方法進行,對此主要有兩種定價方式:
(1)自由定價
自由定價即是根據數據所有者的意愿自己決定數據的具體價格。這種定價方式主要由數據所有者自己決定。這種定價方式簡單、快捷,但是定價方式不透明。
(2)拍賣定價
拍賣定價是一種常用的數據定價手段,通常在數據提供者對自己提供的數據有自信的情況下會采用這種方式,因為通常情況下經過拍賣的商品一般是相對來說罕見、稀有的商品。在網上進行拍賣,雖然有節省場地、參與方便、時長更自由等優點,但是也會因為其網絡形式而產生很多問題,例如:在網上競拍者更容易產生聯系從而容易出現共謀的情況、有些競拍者會在拍賣結束前進行搶拍或拍賣結束后不認賬等情況,這都會對賣方和其他競拍者產生不利的影響。
所以在拍賣中還需要考慮到拍賣流程的安全性和私密性,需要在流程中由個人數據銀行來保證交易的不可否認性、抗共謀性、底價隱藏性和密封遞價性等特性,以保證參與數據各方的利益。
3 定價設計分析
在本文中對結構化屬性提出了使用基于元組的定價方法,其中對屬性進行劃分可以根據不同數據屬性的權重對不同數據種類進行定價,比如含有精準位置的運動信息肯定會比普通的運動信息要更有價值、使用場所更多;而信息熵可以從數據的信息量來衡量數據的價值,數據的信息熵越高則數據的信息量越高;信譽度則可以從數據的提供者的角度來衡量數據價值,如果數據提供者總是提供高質量的信息,那么將有機會獲得更高的數據收益分成,將會促進數據提供者為個人數據銀行提供更多更高質量的數據。
對于非結構化數據本文提出了使用自由定價和拍賣定價的方式,自由定價和拍賣定價都是一種積累數據定價信息的方式,我們可以根據這兩種方法來收集非結構化數據的歷史價格和影響價格的因素,在同類型數據收集到一定的規模后,可以根據收集到的信息將已有一定規模的非結構化數據獨立出來,像結構化數據一樣根據影響數據質量的因素進行定價。
4 結語
對于個人大數據中數據定價難的問題,提出將個人大數據分為結構化數據和非結構化數據兩類,并對結構化數據使用基于元組的定價方式,對非結構化數據使用基于自由定價和拍賣定價的方式。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
