基于基本面數據和注意力機制的股票趨勢預測
2021-07-03 03:51:38白迪
現代計算機 2021年12期
白迪
(四川大學計算機學院,成都610065)
0 引言
在金融市場中,資產的價格和回報的預測一直是金融從業者和學者們最具挑戰和激動人心的問題之一[1-2]。研究估計,機器學習應用于銀行和金融部門的年潛在價值占全球收入的5.2%,約為3000 億美元[3]。與傳統的財務模型相比,機器學習提出利用以前未使用的新數據源進行準確預測的希望。近年來,有許多使用基本面數據進行股票價格和回報預測的研究,并且取得了良好的效果,并且證明了機器學習在基本面數據對股票價格和回報預測的有效性[5]。
人類的注意力機制是從直覺中得到,他是利用有限的注意力資源從大量信息中快速篩選出高價值信息的手段。深度學習中的注意力機制借鑒了人類的注意力思維方式[6],并被廣泛應用到計算機視覺和自然語言處理中。而在進行基本面數據進行資產價格和回報預測時,由于基本面的數據量較大,每個基本面指標對于預測結果的影響也是不同的,因此本文使用帶有注意力機制的機器學習進行資產價格和回報的預測。
1 問題描述
本實驗使用基本面數據預測資產下一季度的回報率,其輸入如公式(1)所示:

其中xt,i代表在時間t 時刻第i 個基本面指標,共有N 個指標。模型預測的輸出為資產的回報率。計算公式如下所示:

其中closet代表資產在t 時刻的收盤價,Predictedt代表了資產在t 時刻預測出的回報率。
2 數據準備
2.1 數據獲取
本實驗所采集的股票數據使用的是滬深300 指數成分股。選用滬深300 指數成分股作為實驗數據主要有兩個原因。第一:滬深300 指數的金融基本面指標在數據量方面相對完整和龐大。這是因為這些股票都是大盤股,而且它們中的大多數上市時間相對較早。第二,滬深300 成分股在不同行業間相對平衡,而且它覆蓋了銀行、鋼鐵、石油、電力、煤炭、水泥、家電、機械、紡織、食品、釀酒、化纖、有色金屬、交通運輸、電子器件、商業百貨、生物制藥、酒店旅游、房地產等數十個主要行業的龍頭企業。但由于滬深300 成分股的組成經常處于變化中,本實驗采用2019 年12 月的成分股作為它的組成。本文滬深300 成分股的歷史數據來自于量化交易網站聚寬。
2.2 填充缺失數據
成分股中原始的基本面數據有相當一部分數據條目缺失。由于數據集中缺失數據的存在可能為數據處理制造問題,從而最終產生無效的結論。對于機器學習問題,特別是在大多數機器學習方法的設計中都要求有完整的數據用于訓練和測試,因此在創建機器學習模型前必須對缺失數據進行處理。
數據缺失值的產生有三種機制,第一,完全隨機缺失:某個變量是否缺失與它自身的值無關,也與其他任何變量的值無關。第二,隨機缺失:在控制了其他變量已觀測到的值后,某個變量是否缺失與他自身的值無關。第三,非隨機缺失:即使控制了其他變量已觀測到的值,某個變量是否缺失仍然與它自身的值有關。
如文獻[7-8]中所述,通常處理缺失數據有以下幾種方法:
(1)整列刪除:整列刪除移除有一個或多個缺失值的記錄。對于完全隨機丟失的數據,整列刪除只會導致統計能力的下降。如果數據不是隨機缺失的,這種方法可能產生有偏參數估計。
(2)成對刪除:整列狀態刪除通常用一個特殊碼代表無效值和缺失值,同時保留數據集中的全部變量和樣本。但是,在具體計算時只采用有完整答案的樣本,因而不同的分析因涉及的變量不同,其有效樣本量也會有所不同。這是一種保守的處理方法,最大限度地保留了數據集中的可用信息。
(3)向前填充/向后填充:向前填充/向后填充即使用后一位/前一位的數據填充缺失數據。
(4)最大似然估計法:最大似然估計法使用可用數據的最大似然函數來計算最大似然估計。同樣,最大似然估計法還假設數據如果不是完全隨機缺失,至少是隨機缺失的。
原始數據中有大量的數據缺失集中在一些特征上,而其他缺失數據分布的較為離散。本文使用了特征刪除和均值替代的方法。如果某個特征有大量或超過50%的數據缺失,該特征項將會被移除。經過特征刪除后,經統計刪除的數據共有8%。若某只股票有超過10%的基本面數據為空,這刪除該股票的數據。剩余的缺失數據使用向后填充法填補。
2.3 趨勢平穩化
本實驗的目標變量是預測季度的回報率。由于原始數據中有許多的特征擁有一個與時間相關的全局趨勢,這些具有全局趨勢的特征可能會阻礙我們機器學習模型的泛化能力,從而導致不可靠的預測結果。因此我們對所有的特征進行了百分比的轉換,如公式(3)所示:

2.4 小結
經過數據處理后,最終共有138 支股票和23 個特征被選取。每只股票有59 個觀測值,從2005 年第一季度到2019 年第四季度。這23 個特征值如表1所示。
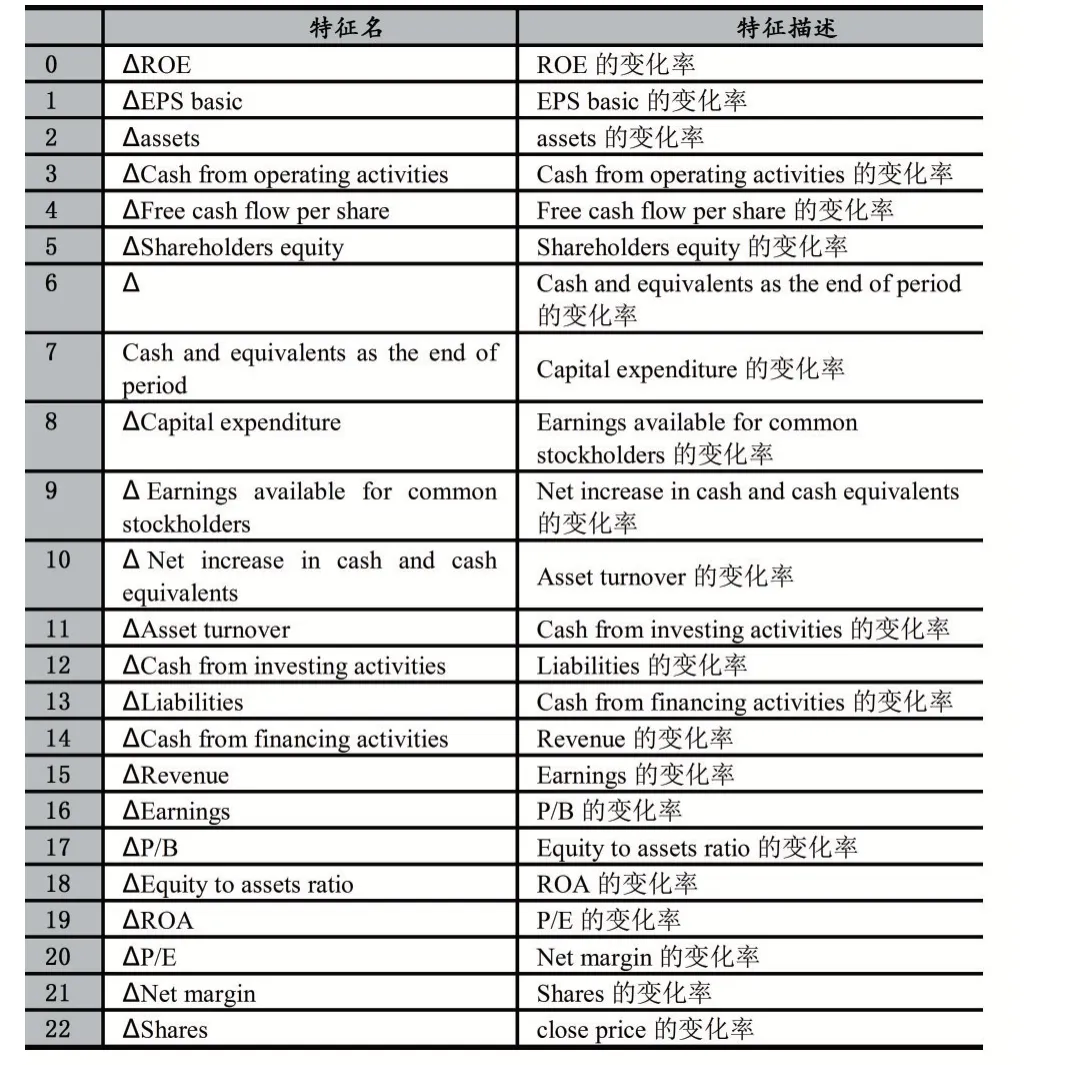
表1 數據集經過預處理后的特征值
3 實驗與分析
3.1 數據集劃分
在金融預測問題中,特別是數據有限的情況下,使用機器學習的方法時較容易出現過擬合。因此,我們將數據集劃分為訓練集,驗證集和測試集。訓練集占總數據的60%,測試集和驗證集分別占總數據的20%。即從2005 年第一季度至2013 年第四季度為訓練集,從2014 年第一季度至2016 年第四季度為驗證集,從2017 年第一季度至2019 年第四季度為測試集。除此之外為了最大化的利用數據,在驗證之后我們使用訓練集的數據和驗證集的數據訓練模型,然后進行測試[5]。我們的策略如圖1 所示。
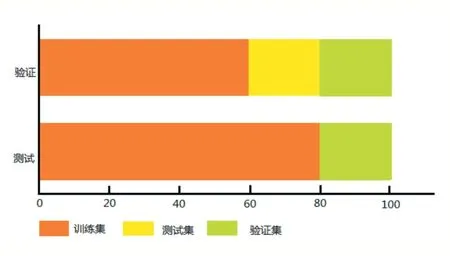
圖1 數據集劃分策略
3.2 數據歸一化
由于不同特征的數值范圍可能不一致,因此本實驗對每個特征進行標準化,以提升我們預測模型的性能[9]。歸一化公式(4)如下所示:

其中x是原始的特征向量,xˉ為特征向量的平均值,σ為特征向量標準差。為了防止訓練集使用到驗證集和測試集信息,需要對訓練集與驗證集、測試集分開進行歸一化處理本實驗對訓練集歸一化后,使用訓練集的平均值和標準差對驗證集和測試集進行歸一化。
3.3 損失函數
當訓練一個回歸模型時,損失函數取決于特定的算法。此外,模型訓練中的損失函數也是一個可以調優的超參數。對于前饋神經網絡,我們使用均方根誤差(RMSE)作為訓練的損失函數。對于隨機森林,不涉及訓練周期和損失函數,RMSE 如公式(5)所示:
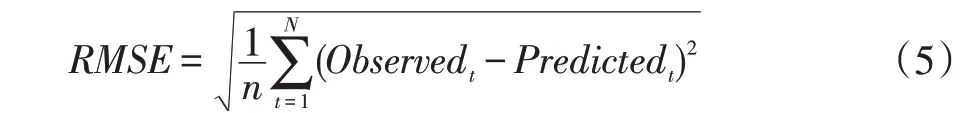
3.4 基線模型
在本實驗中,使用的基線模型為FNN 和RF,使用這兩個模型用來預測季度的回報[5]。
(1)前饋神經網絡
前饋神經網絡使用的開發工具為:Python 和Ten?sorFlow 的接口Keras。前饋神經網絡其隱藏層的數量(Hidden layers)、每個隱藏層神經單元的個數(Layer sizes)、激活函數(Activation)、訓練的周期(Training ep?ochs)、學習率(Learning rate)和優化器(Optimizer)如表2 所示。
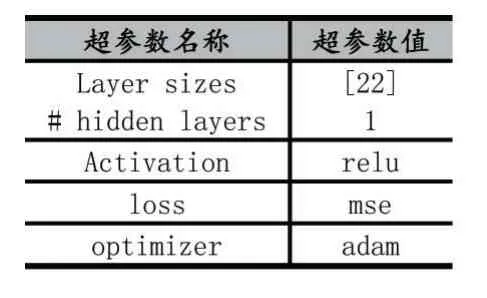
表2 前饋神經網絡的超參數
(2)隨機森林
隨機森林使用的開發工具為Python 的scikit-learn庫。其超參數設置如表3 所示。
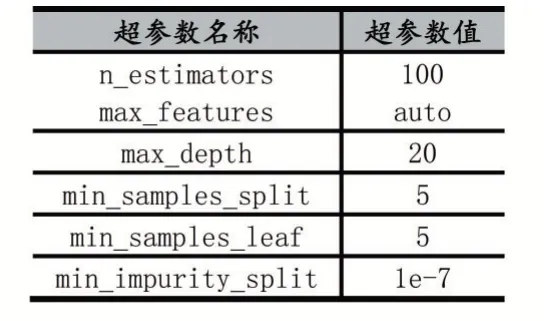
表3 隨機森林的超參數
3.5 帶有注意力機制前饋神經網絡
由于不同的基本面指標對預測結果的影響不同,因此本實驗的注意力機制作用在指標上。帶注意力的模型使用的開發工具為Python 和TensorFlow 的接口Keras。其模型的參數如表4 所示。
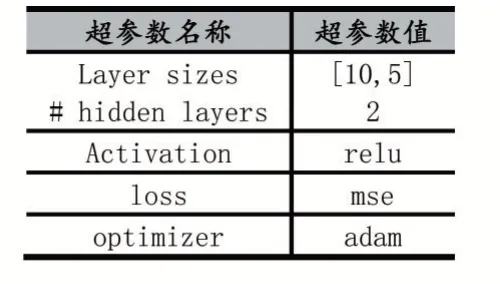
表4 帶有注意力機制的前饋神經網絡的超參數
3.6 實驗比較
本文使用了前饋神經網絡、隨機森林和帶有注意力機制的前饋神經網絡三種模型。股票預測結果在不同時間的均方根誤差如圖2 所示,三種模型的平均均方根誤差如表5 所示。

表5 三種模型的均方根誤差
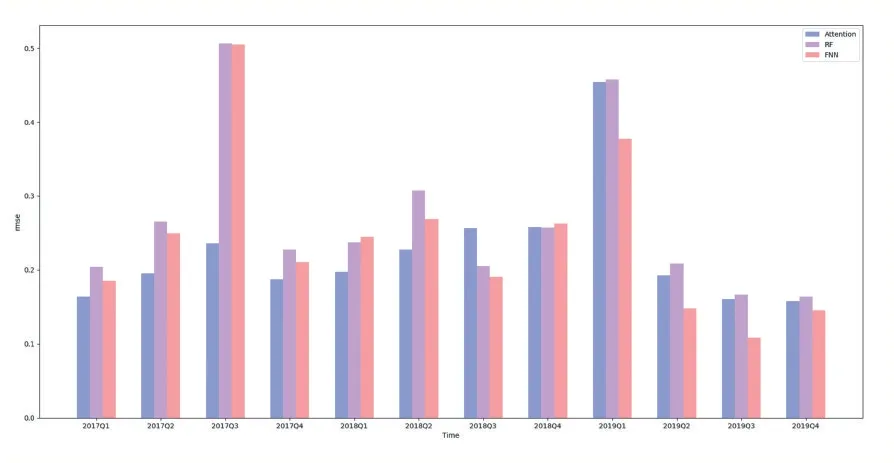
圖2 三種模型結果對比
由圖2,帶有注意力機制的模型其均方誤根差在多數季度要小于前饋神經網絡和隨機森林的均方根誤差。在表5 中,帶有注意力機制的前饋神經網絡的效果分別比前饋神經網絡和隨機森林的效果提升了43.75%和47.05%,也證明了帶有注意力機制的前饋神經網絡的有效性。
4 結語
機器學習在股票價格和回報測試是一個熱門的課題。本文使用帶有注意力機制的前饋神經網絡結合基本面信息對股票的回報進行預測,并取得了較好的結果。但仍存在不足之處,例如在金融領域中,使用基本面數據時,其所在的行業信息也是很重要的一個因素,因此可以嘗試將行業信息加入模型中進行預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
四川勞動保障(2021年9期)2022-01-18 05:11:08
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛生(2014年3期)2014-11-12 13:18:12
