基于Neo4j 的數據空間多源異構數據集成管理研究
2021-07-03 03:52:02李帥郭妍彤周文迪
現代計算機 2021年12期
關鍵詞:數據庫
李帥,郭妍彤,周文迪
(四川大學計算機學院,成都610065)
0 引言
隨著制造業信息化和工業化不斷融合,制造過程中涉及到的數據呈現多源化、異構化,數據具有典型的“4V”特征[1],這些數據涉及人、機、料、法、環,能夠幫助制造商提高設計和生產效率,降低缺陷和返工,更好地滿足客戶需求和進行有效的營銷[2]。涉及人、機、料、法、環的數據是多源異構的,制造企業中數據來源多方、結構各異,如何集成這些數據才能打破“數據孤島”[3]、建立數據生態、降低企業成本、開發潛在價值是目前諸多企業迫在眉睫的任務。
傳統關系型數據庫儲存的是結構化數據,一個數據庫通常只儲存一種類型數據,不同數據庫間可能存在關聯關系,但是數據庫之間的關系卻得不到體現,不能有效滿足查詢需求。特別地,這一問題在企業數據上尤為突出。隨著企業發展,數據越來越多,呈現指數級增長趨勢,各數據庫是自治的,邏輯上存在聯系,但物理上卻是分開的。有學者用分布式系統[4]實現這些數據庫的聯系,但存在并行帶來的高開銷問題,數據一致性得不到保障,對非結構化數據存儲管理不足[5]。隨著多維數據、半結構化數據和非結構化數據越來越多(Web 頁面、視頻、音頻、圖片等),企業面臨的數據管理問題愈加嚴重,如何集成這些多源異構的數據顯得尤為困難,人們開始考慮遷移到其他數據庫[6],許多學者提出過多種數據存儲架構,包括數據倉庫[7]、數據湖[8]、數據中臺[9],但效果并不理想。
數據空間是指某一實體擁有的所有信息以及從這些信息中抽象出來的一些關聯數據的集合[10],在邏輯上是一張圖,其構建過程為pay-as-you-go 的方式[11],不像傳統數據集成時pay-before-you-go 的構建方式,也不像數據湖弱化多源異構數據的數據關系。數據空間是以圖結構的形式集成多源異構數據,降低數據存儲空間,保障源數據可尋,不受數據格式影響,打破多源數據之間的壁壘,構建數據生態。本文提出的基于Neo4j 的數據空間模型由本體關系、包裝代理、身份識別、數據集成四個部分組成。
1 數據空間架構
數據空間不再是數據庫的簡單聚集,而是多源異構數據的代理。數據空間的構造途徑是集成、更新多源異構數據集,主要包括本體關系、包裝代理、身份識別。數據空間主要包括三類數據:關系數據、元數據、數據內容。關系數據是指數據集間關系或構建的實例間關系,例如制造企業中工人與車間的關系;元數據是指數據內容的描述信息,包括數據名稱、數據格式、數據基本屬性等;數據內容是指數據項的具體內容,既對應的視頻文件、音頻文件、表文件等。如圖1,關系數據源自本體關系,元數據源自包裝代理,數據內容與身份識別對應。
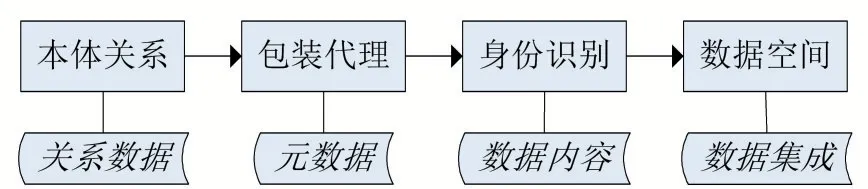
圖1 數據空間中各模塊集成數據流程
數據空間作為一種數據管理技術面臨著諸多挑戰,既要求集成多源異構的數據,同時具備對數據的增加、刪除、查找、修改等傳統問題。數據空間集成了RDBMS、Email、Document、Mobilephone、WebPage、XML、Image 等數據源。如圖2,數據空間中的數據是高度異構的,但是在數據操作時要求數據具有大致相同的格式,因此數據擴展是數據集成的第一步,既對源數據建立包裝代理(wrapper),抽取特定格式的數據對象建立圖數據庫,在數據空間中通過鏈接訪問源數據。
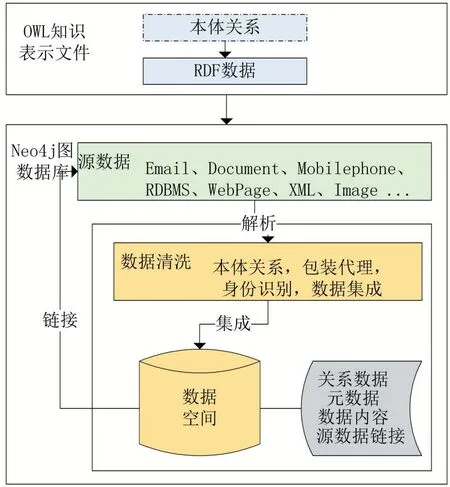
圖2 數據空間架構
本文提出的基于Neo4j 的數據空間多源異構數據集成模式是將源數據與數據空間分離的模式,源數據解析到數據空間,保證了數據可變但模式穩定。數據空間的任務是對多源異構數據(RDBMS、Email、Docu?ment、Mobilephone、WebPage、XML、Image)建模,包括構建本體獲得本體關系、包裝代理、新數據身份識別、數據集成,獲取關系數據、元數據、數據內容和源數據鏈接。Neo4j 圖數據庫存儲數據和關系,并具有數據挖掘功能[12],節點信息包含元數據、數據內容以及源數據鏈接,關系數據表示節點與節點的關系。通過鏈接對源數據操作,解決數據一致性問題,同時也避免了數據空間因源數據導入而導致存儲空間快速激增問題。
2 本體關系
Protégé編輯本體,獲得一個用OWL 表示的知識表示文件。對于結構化數據,利用D2RQ 轉化工具把表數據轉化成虛擬的RDF 數據[13],使數據在RDF 層面實現數據格式的統一。對于非結構化數據,需要對本體數據“包裝代理”處理,以建立鏈接方式獲取數據源。如圖3 所示,將數據存儲到圖數據庫Neo4j 中主要包括兩個部分,其一為將本體數據轉化為RDF 數據,其二為把RDF 文件映射到Neo4j。RDF 是三元組數據<主體,謂詞,客體>,一般情況下RDF 三元組轉換到Neo4j 圖數據庫分為兩種情況,第一中是轉化為兩個節點,以及這兩個節點對應的關系,第二種是轉化為一個節點和節點對應的屬性。具體轉化方式根據實際情況而定。
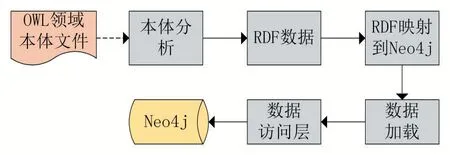
圖3 OWL文件存入Neo4j數據庫流程
3 包裝代理建立
數據庫集成面臨的最大困難是多源數據格式不統一,使得存儲、查詢、修改等不能得到解決,包裝器的目的是對多源異構的數據進行統一表示,經由包裝器把RDBMS、Email、Document、Mobilephone、WebPage、XML、Image 等數據集成到數據空間,交由圖數據庫管理。
定義1:將源數據視為node,把該node 用五元組(εDB,πDB,ωDB,γDB,τDB)表示,其中εDB是源數據名稱,πDB是源數據標示信息,ωDB是源數據內容,γDB是源數據內容標示信息,τDB是識別數據。
εDB(源數據名稱):εDB=DB,DB是源數據庫名稱,εDB可為NULL。
πDB(源數據標示信息):πDB=<C,T>,其中C,T表示源數據的標示信息,包括源數據初次創建時間,數據庫大小,以及數據的更改時間,既C=(creat time:data,size:int,modidied time:data),T=(data1,int,data2)。
ωDB(源數據內容):源數據的每個字符為ωi,則ωDB=∑ωi,表示所查數據的所有內容。
γDB(源數據內容標示信息):令γDB=<N,Nf,Ro>,表示源數據內容的標示信息,其中文件名N=<dc1,dc2,dc3,dc4…>,文件格式Nf= <.txt, .doc,.pdf,.xml, .jpg, .mp4…>,列名Ro= <col1,col2,col3,col4…>。

根據τDB建立各源數據間關系,對源數據間關系定義如下:

4 身份識別
當有新數據加入數據空間時要判斷數據相關性,數據空間會在存儲數據時對數據進行評估,如果數據對象與主體相關,則存儲,否者放棄該數據對象。身份識別步驟如下:
(1)通過包裝代理提取新數據NewDB的識別數據信息τNew;
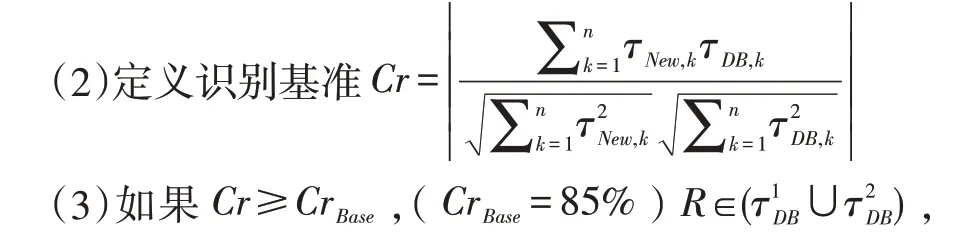
則識別成功;
(4)如果Cr<CrBase,放棄該數據對象;
(5)建立節點加入NewDB
身份識別流程如圖4。
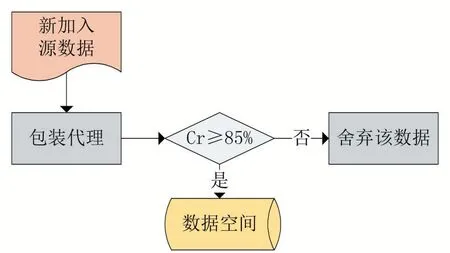
圖4 身份識別流程
5 數據空間集成
數據空間是對多源異構數據集成管理的系統,是由數據構成的高維空間,它包含數據內容以及數據之間的關聯關系,這些數據以圖結構形式集成,反映數據間的生態關系。在制造企業中,與產品相關的五大因素為:人、機、料、法、環。“人”指生產設備的操作人員,“機”指生產的執行設備,“料”指生產加工使用的原料及工具,“法”指生產加工的方法,“環”指生產環境[14]。數據空間則是集成管理人、機、料、法、環相關數據。

實體用三元組表示:節點(Node)、關系(Relation?ship)、屬性(Properties)。其中,可以為節點、關系賦予相應屬性。在節點上賦予屬性,當數據儲存時,內存消耗可以得到有效解決;為關系賦予屬性,則可以更加靈活擴展模型。無論是節點還是關系,都可以擁有多個屬性用來描述其特征,節點間可以相互建立關系,每個節點可以設置多個屬性的鍵值對(Key,Value),每個關系有from Node 和to Node,同時每個關系可以設置多個屬性的鍵值對(Key,Value)。
RDF 是三元組數據<主體,謂詞,客體>,其中主體或者客體對應Neo4j 中的節點,謂詞對應于節點與節點之間的關系,存入Neo4j 后由于節點名稱的存在,如果要在數據庫中找到存放的節點,必須要建立索引。

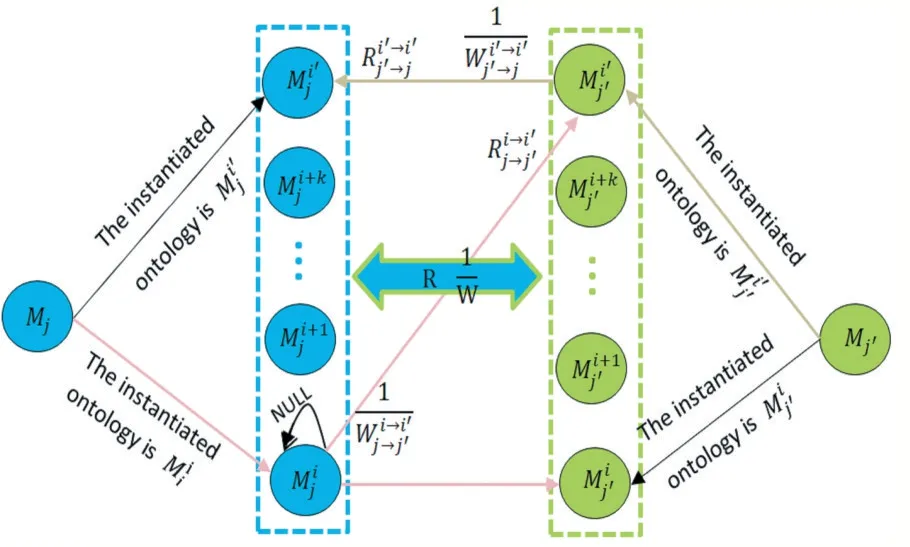
圖5 數據空間節點存儲模型


目標問題的求解算法:
輸入:源數據
輸出:元數據、實例化主體

其中,P 表示問題的答案范圍,當P 可以由DB 直接得到時,不需要進行額外元數據提取,只需完成步驟一。adhoc()是元數據提取函數,Function(R)是節點關系函數。當目標P 的范圍超過DB 但小于πDB時,繼續步驟二,返回源數據名稱εDB。當目標P 的范圍超過πDB但小于εDB時,繼續步驟三,返回源數據內容ωDB。當目標P 的范圍在關系R 的范圍內,返回識別實例化主體τDB。當新數據加入到數據空間時,如果CrNewDB>CrBase,則循環以上所有步驟。
6 實驗與分析
6.1 實驗環境
處理器Intel Core i7-7700HQ CPU @ 2.80 GHz,RAM 8.00 Gb,64 位操作系統,Protégé5.2.0,Neo4j-com?munity-3.5.9,Java1.8.0_181,Eclipse4.3.0。
6.2 實驗結果與分析

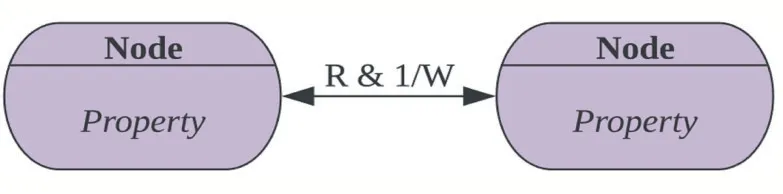
圖6 節點與節點關系
集成人、機、料、法、環相關數據到數據空間如圖7,數據空間是一個復雜網絡,包括節點、關系、權重以及節點屬性。節點是源數據中的實體,關系是指實體之間存在的關聯關系,權重是指關聯關系的重要程度,屬性是源數據的值。通過源數據的相關記錄,基于Neo4j圖數據庫建立實體之間關系。
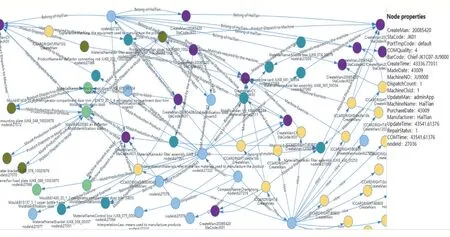
圖7 集成人、機、料、法、環數據


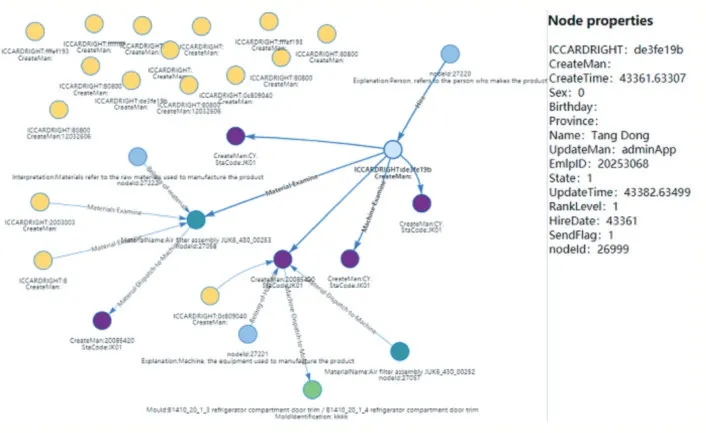
圖8 集成“人”相關數據
因為數據空間的復雜性,在查詢數據時需要對節點數目限制,根據實例化本體的限制,得到的節點個數和關系也是受到限制的,這樣的好處在于選取復雜網絡的部分結構,從而避免復雜網絡造成不易理解的弊端。根據查詢節點的不同,數據空間也不同,如圖9 所示,限制節點數為15,實例化“機”本體,得到數據空間中集成的機器數據以及與其相關的信息組成的關聯網絡。同樣限制節點數為15 時,集成在數據空間中與“料”相關的信息如圖10 所示,包含了由人、機、料、法、環構成的關聯網絡。
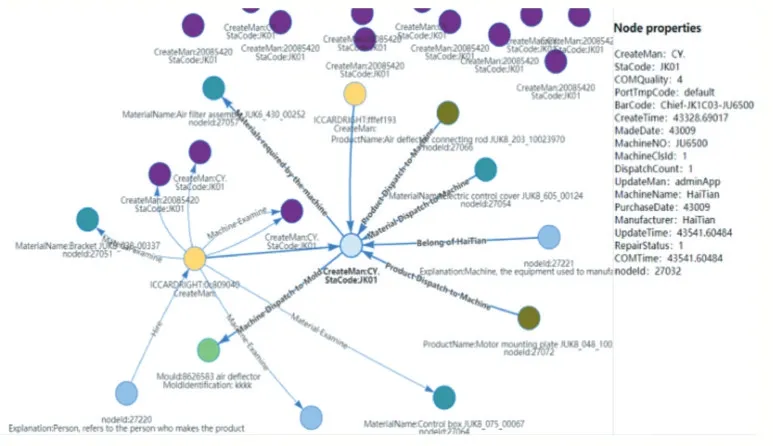
圖9 集成“機”相關數據
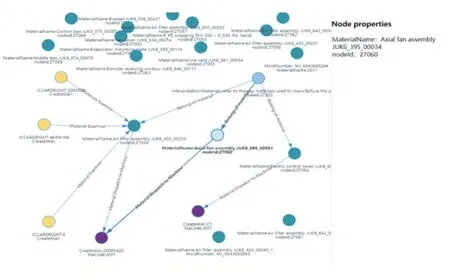
圖10 集成“料”相關數據


圖11 是把本體“人”實例化后在數據空間集成的效果。節點屬性除了包括節點的基本信息外還包括源數據鏈接,通過鏈接訪問源數據。這里的鏈接是指多源異構的數據的存儲路徑,可以是本地路徑也可以是遠程路徑。這樣集成數據的好處有以下兩方面:一方面減少數據儲存空間的消耗,另一方面是當需要查詢源數據時有路徑可尋。
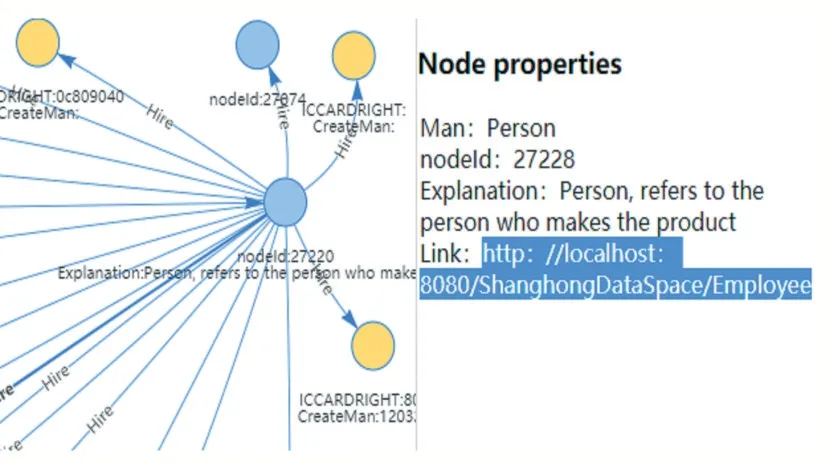
圖11 數據空間鏈接到源數據
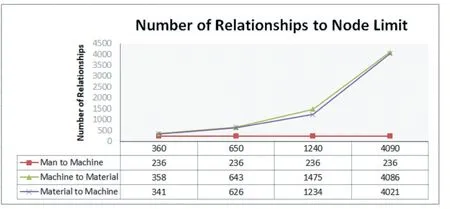
圖12 節點數目改變時實體數量與關聯關系
7 結語
數據空間打破“數據孤島”,集成管理多源異構數據。使以前獨立存儲于各數據庫的數據有了關聯,組成數據生態,數據與數據產生聯系,為數據賦予了新生命的同時也產生潛在的不可估量的價值,這為數據挖掘和數據分析提供便利。在生產制造過程中,根據數據空間生產線權重變化,不斷調整企業“人機料法環”的配比,確保生產安全,降低生產成本,提高產品質量,數據生態良性循環。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
