基于多路交叉的用戶金融行為預(yù)測
2021-07-05 11:01:46程鵬超杜軍平薛哲
智能系統(tǒng)學報 2021年2期
程鵬超,杜軍平,薛哲
(北京郵電大學 智能通信軟件與多媒體北京市重點實驗室,北京 100876)
隨著人們生活水平的提高,人們更加關(guān)注對 生活質(zhì)量的追求,在閑余的時間買賣基金、股票等以獲取更多地利潤。隨著人們金融行為和意識的提升,金融領(lǐng)域的用戶行為挖掘可以探究用戶的行為規(guī)律,通過挖掘用戶金融行為的規(guī)律與變化,為用戶推薦或提供更好的服務(wù)。金融大數(shù)據(jù)中包括結(jié)構(gòu)化文本數(shù)據(jù)、非結(jié)構(gòu)化文本數(shù)據(jù)、數(shù)值數(shù)據(jù)等。挖掘金融大數(shù)據(jù)中用戶的金融行為來改進金融領(lǐng)域服務(wù)模式,提高金融領(lǐng)域服務(wù)質(zhì)量,已經(jīng)成為了一個重要的研究方向[1]。
為了有效挖掘金融大數(shù)據(jù)中用戶潛在的金融行為特征,提高金融領(lǐng)域的服務(wù)模式和服務(wù)質(zhì)量,本文提出了一種基于多路交叉特征的用戶金融行為預(yù)測算法(user financial behavior prediction algorithm based on multi-way crossing, MCUP)。首先,根據(jù)數(shù)據(jù)包含的屬性構(gòu)建訓練的特征,利用因子分解機模型[2](factorization machines, FM)模型借助下游行為預(yù)測任務(wù)對金融數(shù)據(jù)的特征進行預(yù)訓練,可以獲取到數(shù)據(jù)中特征的隱含向量。對于文本特征而言,利用預(yù)訓練模型對文本特征進行表示以獲得語義豐富的特征向量。然后,引入特征交叉層來對金融數(shù)據(jù)的較高階特征進行提取,解決FM線性模型只能提取低階特征的缺點。同時,利用殘差網(wǎng)絡(luò)結(jié)構(gòu)對金融數(shù)據(jù)的高階特征進行提取,解決深度神經(jīng)網(wǎng)絡(luò)在提取金融數(shù)據(jù)高階特征時會因為網(wǎng)絡(luò)層數(shù)過深而導致梯度消失的問題。最后,利用將FM、特征交叉網(wǎng)絡(luò)和殘差網(wǎng)絡(luò)結(jié)合在一起的多塔模型進行用戶金融行為的預(yù)測,融合低階特征與高階特征進行實驗。
本文的主要貢獻如下:
1) 提出了一種基于多路交叉的用戶金融行為預(yù)測方法,結(jié)合數(shù)據(jù)低階特征和高階交叉特征對金融大數(shù)據(jù)用戶行為進行預(yù)測;
2) 使用預(yù)訓練FM模型對訓練特征隱向量表示進行初始化,加速訓練和模型收斂,同時FM可以提取數(shù)據(jù)特征的一階和二階交叉特征;
3) 引入交叉特征層和殘差網(wǎng)絡(luò)提取數(shù)據(jù)高階特征,將稀疏的身份(identity, ID)特征表示成稠密向量作為輸入,同時考慮到高階特征對用戶行為的預(yù)測效果影響。
1 用戶行為預(yù)測的研究現(xiàn)狀
目前現(xiàn)有的用戶行為的預(yù)測的方法一般分為2種類型,傳統(tǒng)的機器學習方法和深度學習方法。對于傳統(tǒng)的機器學習方法而言,F(xiàn)M在理論上可以進行任意階特征的交叉,由于計算復(fù)雜度的限制,目前只是用來進行二階特征交叉。FM核心在于提出了特征隱向量的概念,將原始特征的出現(xiàn)都作為一個特征,每個特征利用稠密的向量來進行表示,解決了多項式特征交叉時交叉系數(shù)更新慢的缺點。FM的不足之處在于所有特征對于行為預(yù)測的結(jié)果影響系數(shù)是相同的,導致數(shù)據(jù)各個特征之間沒有區(qū)分性。為了解決FM無法區(qū)分特征對行為預(yù)測性能的影響,文獻[3]提出了場敏感因子分解模型(field-aware factorization machines, FFM),F(xiàn)FM是在FM的基礎(chǔ)上引入了域概念的行為預(yù)測模型。FFM將具有相同性質(zhì)的特征歸結(jié)于同一個域,每一維特征針對每一個域都會學習到一個隱向量,所以隱向量不僅僅與單個特征相關(guān)而且和域相關(guān)。FM和FFM僅僅考慮到了數(shù)據(jù)的低階特征,而沒有考慮數(shù)據(jù)高階交叉特征,類似用戶ID和物品ID特征需要深度網(wǎng)絡(luò)才能提取高階交叉特征[4]。隨著深度學習技術(shù)的發(fā)展,深度學習在推薦、廣告、計算機視覺、自然語言處理、語音識別等領(lǐng)域取得了重要進展,深度學習幾乎無限的表達能力被廣泛地研究[5]。文獻[6]利用結(jié)構(gòu)化和非結(jié)構(gòu)化大數(shù)據(jù)對商品購買行為進行了預(yù)測。文獻[7]基于用戶行為序列數(shù)據(jù)和選擇模型的方法,對用戶金融行為選擇出最優(yōu)的因子模型并預(yù)測用戶的行為。文獻[8]利用支持向量機模型對用戶的消費情況進行預(yù)測并獲得了較好的預(yù)測結(jié)果。文獻[9]結(jié)合支持向量機和邏輯回歸模型進行了購買行為的預(yù)測,進一步提升了金融行為預(yù)測的準確性。文獻[10]采用改進的決策樹構(gòu)建用戶金融行為預(yù)測模型,實現(xiàn)了大數(shù)據(jù)環(huán)境下的模型構(gòu)建和訓練。文獻[11]構(gòu)建了Pareto/NBD模型,結(jié)合協(xié)變量進一步提升了用戶購買行為預(yù)測的準確率。文獻[12]通過改進了傳統(tǒng)的預(yù)測模型,在產(chǎn)品購買行為數(shù)據(jù)集上驗證了方法的有效性。文獻[13]挖掘了用戶購買行為規(guī)律,分析出了符合用戶購買意愿的商品序列。文獻[14]構(gòu)建了線上消費購買率預(yù)測模型,預(yù)測了未來用戶購買的行為規(guī)律。文獻[15]結(jié)合遺傳算法與傳統(tǒng)算法進行最優(yōu)模型組合,并通過實驗驗證了該方法的有效性。
深度學習技術(shù)同樣也應(yīng)用到了用戶行為預(yù)測方面。文獻[16]采用CNN-LSTM(convolutional neural network long short term memory)模型預(yù)測用戶購買行為,利用卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)進行特征抽取,通過長短期記憶網(wǎng)絡(luò)(long short term memory,LSTM)[17]建立時間序列,實現(xiàn)對特征的自動抽取和行為預(yù)測。支持因子分解機的神經(jīng)網(wǎng)絡(luò)模型(factorization-machine supported neural networks, FNN)[18]就是來解決FM和FFM僅考慮一階和二階特征的問題,F(xiàn)NN利用FM作為預(yù)訓練模型,將訓練好的特征的隱向量作為后續(xù)深度神經(jīng)網(wǎng)絡(luò)的輸入,來得到特征的高階組合。它可以解決類似用戶ID沒有出現(xiàn)過的泛化問題,但是忽略了低階特征的重要性,即在數(shù)據(jù)中頻繁出現(xiàn)的低階特征組合也能顯示出用戶行為。因此,低階特征和高階組合特征對用戶行為的預(yù)測都很重要。深度因子分解模型(deep factorization machines, DeepFM)[19]提出了雙塔模型分別對數(shù)據(jù)低階特征和高階交叉特征進行提取。利用FM模型自動地提取數(shù)據(jù)一階與二階特征,深度神經(jīng)網(wǎng)絡(luò)提取數(shù)據(jù)的高階特征,通過融合數(shù)據(jù)低階特征和高階特征來進行用戶行為的預(yù)測,利用FM天然可以自動組合二階特征和一階特征的優(yōu)點來避免人工干預(yù),并且在模型橫向和縱向來共享FM的特征隱向量,真正實現(xiàn)了端到端的用戶行為預(yù)測。DeepFM模型的輸入對于連續(xù)特征是不友好的,需要把文本特征作為用戶行為預(yù)測的特征之一,文本特征大多數(shù)情況會用一個低維稠密向量來表示。深度交叉網(wǎng)絡(luò)(Deep&Cross network)[20]共享輸入,即deep部分和cross部分輸入是相同的,在其輸入的時候?qū)τ陬愃莆谋咎卣鞫詴⑵渑c其他特征進行連接作為輸入。cross部分在理論上可以做到對高階特征的組合,而且其參數(shù)隨輸入維度是線性增加的,F(xiàn)M要想對高階特征進行組合其復(fù)雜度是呈指數(shù)增長的。Deep&cross雖然既有高階特征又有低階特征,但是對于輸入的離散特征進行one-hot處理后,特征之間是同等重要的,沒有field的概念。
2 基于多路交叉特征的用戶行為預(yù)測的算法(MCUP)
基于多路交叉特征的用戶行為預(yù)測的方法的框架如圖1所示。
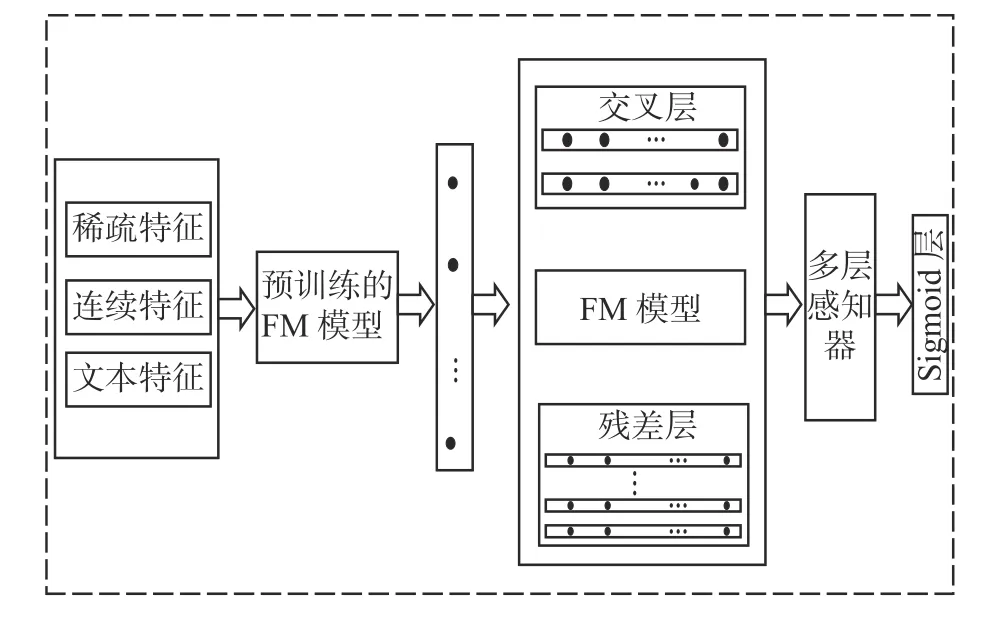
圖 1 基于多路交叉特征的用戶行為預(yù)測框架Fig. 1 The framework of user behavior prediction based on multi-way
模型由3部分構(gòu)成,如圖1所示,左側(cè)模塊表示利用預(yù)訓練FM模型獲取離散特征和連續(xù)特征的稠密向量表示;中間模塊利用交叉層對輸入特征進行特征交叉獲得較高階特征向量表示;右側(cè)輸入特征經(jīng)過殘差網(wǎng)絡(luò)模塊來提取高階特征,得到特征的高階組合。將3個模塊的輸出特征向量進行連接作為淺層全連接網(wǎng)絡(luò)的輸入,最后得到用戶行為的預(yù)測結(jié)果。
2.1 基于多項式的交叉特征提取
FM模型在理論上可以擬合任意高階特征,由于FM模型在擬合高階特征的同時,模型復(fù)雜度將會成指數(shù)倍增加,所以一般只使用FM到二階特征交叉。為了在保證模型復(fù)雜度低的情況下,對高階特征進行交叉組合提取,引入基于多項式的交叉特征提取方法。
基于多項式的交叉特征提取方法核心思想是利用乘法計算來進行特征交叉。同樣,在理論上基于多項式的交叉特征層可以擬合任意高階組合特征。主要利用x0xlT這種表達方式來進行特征交叉,使用原始特征與基于多項式的交叉特征層進行乘法運算,使得特征交叉通過一個rank-one的數(shù)字來表示,大大減少了模型的參數(shù)量。具體為
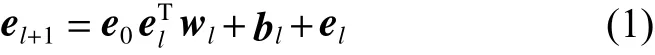
式中:el+1表示l+1層特征向量;e0表示模型原始輸入特征向量;wl表示第l層模型參數(shù);bl表示第l層偏移量;el表示第l層特征向量。
每一層的特征都由其上一層的特征進行交叉組合,并把上一層的原始特征重新加回來。這樣既能特征組合,自動生成交叉組合特征,又能保留低階原始特征,隨著cross層的增加,可以生成任意高階的交叉組合特征,且在此過程中沒有引入更多的參數(shù),有效控制了模型復(fù)雜度。
2.2 基于預(yù)訓練的分解因子機
FM的核心在于提出了特征隱向量的概念,將原始特征的出現(xiàn)都作為一個特征,每個特征利用稠密的向量來進行表示,解決了由于數(shù)據(jù)稀疏導致多項式特征交叉時交叉系數(shù)更新慢的缺點。FM利用交叉的特征隱向量之間計算得分來代替多項式計算時的特征交叉系數(shù),根據(jù)隨機梯度下降的計算公式可以計算出參數(shù)的更新公式,由參數(shù)更新公式可以得出參數(shù)的更新只要交叉特征中的一個值不為0即可,從而解決了百萬級的類別特征經(jīng)過one-hot編碼后數(shù)據(jù)特征稀疏的問題。本文提出利用下游任務(wù)去預(yù)訓練FM模型,使用預(yù)訓練FM模型對MCUP算法中FM模塊進行初始化,以達到加速模型訓練和收斂。
FM一般只用到二階特征組合,為

式中:θ0表示偏置參數(shù);θi表示一階特征的參數(shù);θij表示二階組合特征的參數(shù);xi表示第i個特征;xj表示第j個特征。

式中:vi、vj分別表示第i、j個特征對應(yīng)的隱向量;其他表示含義同式(1)。
在MCUP算法中利用預(yù)訓練FM模型對數(shù)據(jù)中的特征進行預(yù)訓練,類似自然語言處理中詞向量的操作方式,可以獲得數(shù)據(jù)特征的隱向量表示。利用預(yù)訓練FM模型對MCUP算法進行初始化,可以通過數(shù)據(jù)集對特征隱向量進行微調(diào)獲得更好的用戶行為預(yù)測的效果。
2.3 基于殘差網(wǎng)絡(luò)的高階特征提取
線性回歸(linear regression, LR)算法、FM算法等僅僅考慮到了低階特征的組合,在下游任務(wù)中低階特征可以記住用戶歷史行為,從而對下游任務(wù)的目標起到正向作用。但是在收集到的數(shù)據(jù)中存在大量的ID類特征,即One-hot操作后會得到離散稀疏的向量表示,通常ID類特征在特征組合中起到非常重要的作用。高維離散特征通用的處理方式是使用One-hot進行表示后,利用LR算法進行用戶行為預(yù)測等下游任務(wù)。隨著深度神經(jīng)網(wǎng)絡(luò)和嵌入方法的發(fā)展更新,高維離散特征不僅使用One-hot進行表示,后續(xù)還使用詞嵌入的方法對ID類特征進行嵌入學習,使用低維稠密特征對ID類特征進行表示。
基于殘差網(wǎng)絡(luò)的高階特征提取方法將ID類特征和連續(xù)型特征放在一起作為模型輸入,利用深度神經(jīng)網(wǎng)絡(luò)中的殘差概念來將網(wǎng)絡(luò)做深。隨著網(wǎng)絡(luò)深度的增加,特征不斷進行交叉組合,最后得到具有泛化能力的高階特征。殘差網(wǎng)絡(luò)的計算為

式中:el表示第l層的輸出特征;el-1表示第l層的特征輸入;wl表示第l層的模型參數(shù)。
3 實驗與結(jié)果
3.1 度量標準
評價用戶行為預(yù)測結(jié)果好壞的指標一般可以使用精確率、召回率、F1。在實際場景中,也用AUC和MAP來表示模型效果的好壞。
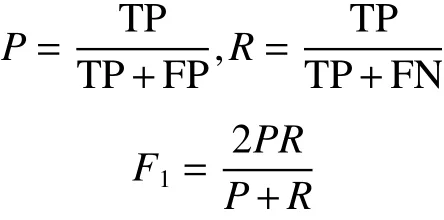
式中:TP表示標記為真正例;FP表示標記為假正例;FN表示標記為假反例;TN表示標記為真假例。
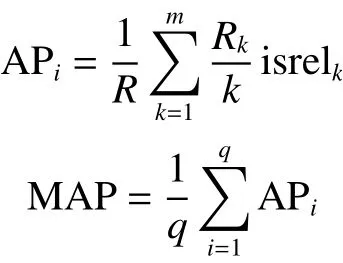
式中:m表示與第i個查詢相關(guān)的數(shù)據(jù)數(shù)量;Rk表示相關(guān)性排序前k個數(shù)據(jù)中與查詢數(shù)據(jù)相關(guān)的數(shù)據(jù)數(shù)量;isrelk表示第k個數(shù)據(jù)是否與查詢相關(guān),如果相關(guān)值為1,反之為0;q表示查詢集合中數(shù)據(jù)數(shù)量;APi表示第i個查詢的平均精確率。
3.2 數(shù)據(jù)集
實驗數(shù)據(jù)為2019年天弘基金用戶點擊行為、2019年長信基金用戶點擊行為和鵬華基金用戶點擊行為。點擊基金的用戶行為表示用戶在界面點擊基金對基金基本信息進行查看。基金數(shù)據(jù)集詳細描述見表1。

表 1 基金數(shù)據(jù)集Table 1 Fund dataset
3.3 實驗和結(jié)果
為了驗證基于多路交叉特征的用戶行為預(yù)測(MCUP)算法的有效性,在3個不同的基金數(shù)據(jù)集上對用戶點擊行為進行預(yù)測。對于每個基金數(shù)據(jù)集設(shè)置3組對比實驗,MCUP算法分別與FM算法、FNN算法和Deep&Cross算法。利用精確率、召回率、F1和MAP對MCUP算法的性能進行評測,特別地在計算MAP指標的時候選取前2、4、6、8和10結(jié)果來進行統(tǒng)計,從而驗證MCUP算法在用戶行為預(yù)測任務(wù)的有效性。
根據(jù)表2可以看出,MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10指標均優(yōu)于傳統(tǒng)的FM與基于深度學習的FNN算法和Deep&Cross算法。在天弘基金數(shù)據(jù)集上,用戶點擊基金信息的行為預(yù)測任務(wù)中MCUP算法相較于Deep&Cross算法而言,在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10上分別高0.7%、0.5%、0.8%、0.7%、1%。MCUP算法使用預(yù)訓練FM模型對特征隱向量進行初始化,相對于Deep&Cross算法具有更好的收斂速度和預(yù)測效果。MCUP算法比起傳統(tǒng)的FM算法在MAP@10提升最大,F(xiàn)M算法僅僅考慮到一階和二階特征對用戶點擊行為預(yù)測結(jié)果的影響,MCUP算法不僅考慮了低階特征,而且使用殘差網(wǎng)絡(luò)來提取高階交叉特征。

表 2 MCUP與對比算法在天弘基金數(shù)據(jù)集上點擊MAPTable 2 MAP of MCUP and comparison algorithm click behavior on Tianhong fund dataset
根據(jù)圖2可以看出,MCUP算法在前2、4、6、8和10的數(shù)據(jù)中F1指標均優(yōu)于對比算法。在天弘基金數(shù)據(jù)集上,用戶點擊基金信息的行為預(yù)測任務(wù)中,MCUP算法相對于FM算法在top@2上提升最大,MCUP算法同時考慮了低階特征和高階交叉特征對用戶點擊行為預(yù)測的影響,利用殘差網(wǎng)絡(luò)隱式地提取數(shù)據(jù)高階交叉特征和FM算法獲取數(shù)據(jù)一階和二階特征。

圖 2 MCUP與對比算法在天弘基金數(shù)據(jù)集上點擊F1曲線Fig. 2 F1 curves of MCUP and comparison algorithm click behavior on the Tianhong Fund dataset
根據(jù)表3可以看出,MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10指標均優(yōu)于傳統(tǒng)的FM與基于深度學習的FNN算法和Deep&Cross算法。在長信基金數(shù)據(jù)集上,用戶點擊基金信息的行為預(yù)測任務(wù)中MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10上比FNN分別高1.8%、1.6%、1.9%、1.6%、1.7%。MCUP算法不僅使用預(yù)訓練FM算法對特征隱向量進行初始化,利用FM提取低階特征并且使用殘差網(wǎng)絡(luò)提取高階交叉特征,而FNN算法只利用預(yù)訓練的FM算法進行高階交叉特征的提取,沒有考慮低階特征對于用戶點擊行為預(yù)測的影響。MCUP算法比具有相似結(jié)構(gòu)的Deep&Cross算法在MAP@10提升最大,Deep&Cross算法沒有考慮到一階和二階特征對用戶點擊行為預(yù)測結(jié)果的影響,MCUP算法利用FM來進行低階特征的提取。

表 3 MCUP與對比算法在長信基金數(shù)據(jù)集上點擊MAPTable 3 MAP of MCUP and comparison algorithm click behavior on Changxin fund dataset
根據(jù)圖3可以看出,MCUP算法在前2、4、6、8和10的數(shù)據(jù)中F1指標均優(yōu)于對比算法。在長信基金數(shù)據(jù)集上,用戶點擊基金信息的行為預(yù)測任務(wù)中,MCUP算法相對于Deep&Cross算法在top@6以后提升的幅度逐漸增大,相較于Deep&Cross算法的Deep神經(jīng)網(wǎng)絡(luò),MCUP算法使用殘差網(wǎng)絡(luò)隱式地提取數(shù)據(jù)高階交叉特征,具有更強的表達能力。

圖 3 MCUP與對比算法在長信基金數(shù)據(jù)集上點擊F1曲線Fig. 3 F1 curves of MCUP and comparison algorithm click behavior on the Changxin fund dataset
根據(jù)表4可以看出,MCUP算法在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10指標均優(yōu)于傳統(tǒng)的FM算法、FNN算法和Deep&Cross算法。在鵬華基金數(shù)據(jù)集上,用戶點擊基金信息的行為預(yù)測任務(wù)中MCUP算法相較于Deep&Cross算法而言,在MAP@2、MAP@4、MAP@6、MAP@8和MAP@10上分別高0.3%、0.2%、0.3%、0.2%、0.4%。MCUP在MAP@10上的性能最好,說明MCUP算法能夠盡可能地將用戶點擊過的基金數(shù)據(jù)排到前面。MCUP算法融合低階特征和高階交叉特征對用戶點擊行為進行預(yù)測,極大地挖掘了用戶潛在的興趣意圖。

表 4 MCUP與對比算法在鵬華基金數(shù)據(jù)集上點擊MAPTable 4 MAP of MCUP and comparison algorithm click behavior on Penghua fund dataset
根據(jù)圖4可以看出,MCUP算法在前2、4、6、8和10的數(shù)據(jù)中F1指標均優(yōu)于對比算法。在鵬華基金數(shù)據(jù)集上,用戶點擊基金信息的行為預(yù)測任務(wù)中,MCUP算法相對于FNN算法提升更加平穩(wěn)且F1性能更優(yōu),MCUP算法利用特征交叉層顯示進行數(shù)據(jù)特征的有限階交叉,而且使用殘差網(wǎng)絡(luò)隱式地進行數(shù)據(jù)高階特征的提取,同時考慮了低階特征和高階交叉特征對用戶點擊行為預(yù)測的影響。

圖 4 MCUP與對比算法在鵬華基金數(shù)據(jù)集上點擊F1曲線Fig. 4 F1 curves of MCUP and comparison algorithm click behavior on the Penghua Fund dataset
4 結(jié)束語
為了有效挖掘金融大數(shù)據(jù)中用戶潛在的金融行為特征,本文提出了一種基于多路交叉特征的用戶金融行為預(yù)測算法。首先,利用FM模型對金融數(shù)據(jù)的特征進行預(yù)訓練,獲取到數(shù)據(jù)中特征的隱含向量。然后,引入特征交叉層和殘差網(wǎng)絡(luò)結(jié)構(gòu)來對金融數(shù)據(jù)的較高階特征進行提取,解決了FM線性模型只能提取低階特征、模型無法有效訓練等問題。最后,將FM、特征交叉網(wǎng)絡(luò)和殘差網(wǎng)絡(luò)結(jié)合為統(tǒng)一的多塔模型進行用戶金融行為的預(yù)測。在多個金融行為預(yù)測數(shù)據(jù)集上的實驗結(jié)果表明,本方法能夠有效融合金融大數(shù)據(jù)的低階特征與高階特征,并準確地預(yù)測了用戶的金融行為。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
