基于多任務特征學習的網絡加密流量識別算法
2021-07-06 02:14:52繆志敏李晨溪錢明遠
計算機技術與發展 2021年6期
關鍵詞:特征
孟 娟,孟 鵬,繆志敏,李晨溪,錢明遠
(1.解放軍31108部隊,江蘇 南京 210016;2.湖北科技學院,湖北 咸寧 437000;3.解放軍陸軍工程大學,江蘇 南京 210007)
0 引 言
隨著互聯網加密協議應用越來越廣泛,網絡加密流量的識別問題日益引起人們的重視。網絡加密流量的有效識別,對保護用戶信息,監管非法數據,檢測網絡攻擊,維護網絡安全有著重要意義。
盡管網絡加密流量識別問題屬于網絡流量識別的子問題,但是傳統的網絡流量識別方法,如基于端口匹配識別、深度包檢測、深入流檢測等難以直接應用于網絡加密流量識別中。目前對網絡加密流量識別問題的研究多針對特定的加密協議,利用加密協議建立連接階段的明文特征,通過特征碼匹配來完成識別,或者利用加密協議建立連接階段的報文指紋特征,如特定的報文長度、到達時間等來完成識別[1-7]。這些識別方法均針對某種特定的加密協議,并未給出一種通用的網絡加密流量識別方法。
盡管網絡流量的具體加密協議細節各不相同,但好的加密算法的一個最基本的要求是要保證算法是安全的。算法的安全性體現在算法數學基礎的穩健性、算法的抗攻擊性、算法的相對強度和算法輸出序列的隨機性。其中前3項因算法結構的種類而異,而利用統計檢測原理來檢測算法輸出序列是否隨機,只關心輸入輸出,在這種情況下,算法的具體結構是被忽略的,因此,可以通過網絡流量的隨機性特征來識別網絡加密流量。
利用網絡加密流量的隨機性特征,該文提出了一種基于多任務特征學習的網絡加密流量識別算法。該算法采用隨機性檢驗獲取數據流的隨機性特征,提取多維隨機性特征值,然后基于2,1范式最小化對一組相關任務進行聯合特征學習。最后針對網絡加密流量進行實驗分析,結果表明,該算法對網絡加密流量的識別精度可達到80%以上。
1 網絡加密流量的隨機性特征
1.1 隨機性度量
隨機性度量是指通過判斷被測序列是否存在某些隨機序列的特定特征,進而判斷其是否隨機。隨機性度量中需要對兩個問題進行研究:第一個問題是如何檢驗,就是確定應該對被測序列的哪些特征進行統計分析,如頻數、游程、相關性、累積和等,在設計隨機性檢驗方法時,應該選擇那些能反映隨機特性的方法,并盡可能反映更多特性,這樣通過較少的指標就可以全面地評價其隨機性。第二個問題是如何對測試結果做出評估,就是用什么方法來對統計檢驗得到的結果進行準確的評價,評價方法有門限值、P-value等。評價方法要盡可能準確。
現已知的隨機性檢驗方法達200多種。其中具有代表性的是美國商務部國家標準技術協會(NIST)在2001年5月公布的FIPS140-2標準[8]和SP800-22標準[9]、德國資訊安全聯合辦公室(BSI)在2001年9月公布的AIS31標準[10]。國內也有隨機性檢驗方法的相關研究[11-12]。
讓一個隨機序列通過所有的隨機性檢驗,在時間、空間上需要很大的開支,同時有些檢驗方法反映的是隨機序列同一方面的特性。對于網絡加密流量而言,采用具有權威代表性的NIST SP800-22標準中的15種檢驗方法更加方便和準確,15種檢驗方法及其所針對的序列屬性簡列如下:
(1)單比特頻數檢驗。序列中1的個數。
(2)分組組內頻數檢驗。對序列分組后每個子序列中1的個數。
(3)游程檢驗。序列中的游程個數。
(4)組內最長游程檢驗。對序列分組后每個子序列的最長游程長度。
(5)二進制矩陣秩檢驗。將序列構造成N個矩陣,計算每個矩陣的秩。
(6)離散傅里葉變換檢驗。序列進行傅里葉變換后的頻率幅值。
(7)非重疊模式匹配檢驗。某特定模式的出現次數。
(8)重疊模式匹配檢驗。某特定模式的出現次數。
(9)Maurer通用統計檢驗。特定長度子序列的所有模式中,相同模式間間隔距離的位數。
(10)線形復雜度檢驗。用Berlekamp-Massey算法計算每個子序列的線形復雜度。
(11)串行檢驗。特定長度模式出現的頻數;
(12)近似熵檢驗。特定長度模式出現頻率的熵值。
(13)累加和檢驗。序列累加和的最大值。
(14)隨機游走檢驗。隨機游走中各循環到達距離原點特定長度位置的次數。
(15)隨機游走變體檢驗。隨機游走中到達距離原點特定長度的位置的總次數。
該標準建立在假設檢驗的基礎上,統一采用P-value評價方式。每個隨機性檢驗的核心是其使用的統計量和統計量所滿足的分布,每個統計量針對了一個特定的序列屬性。
1.2 隨機性特征的相關性
利用NIST SP800-22 隨機性檢驗可構建加密數據流的15類隨機性特征,根據不同的參數設置可提取不同維度的隨機性特征。按缺省設置運行NIST后得到統計結果,從統計結果中提取188維隨機性特征值,其中單比特頻數特征、分組頻數特征關注的是序列中0和1出現的頻率,游程特征、組內最長游程特征關注的是序列中比特變化的特點,離散傅里葉變換特征、非重疊模式匹配特征、重疊模式匹配特征、串行特征和近似熵特征關注的是序列中是否有某一個模式出現的頻率較高。Maurer通用統計特征和線性復雜度特征關注的是序列的壓縮性。累加和特征、隨機游動特征和隨機游動變體特征關注的是序列的隨機游動特性。各個統計特征都各有其關注點,從統計原理上來看,這些特征之間具有一定的聯系,但是,從統計原理上分析特征之間相關性并不容易,有時候兩個看起來差別很大的兩個特征也有可能具有較高的相關性,這里通過計算它們的互信息熵對這些隨機性特征進行相關性分析。
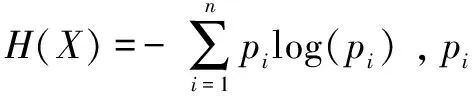
H(X/bj)=Hn(P(a1,bj),P(a2,bj),…,P(an,bj))=
(1)
而
(2)
由上式可得:
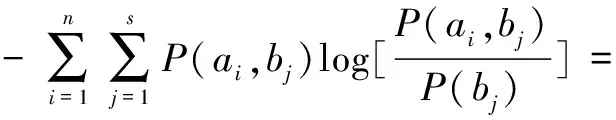
P(bj)]=
H(X,Y)-H(Y)
(3)
H(X,Y)是聯合熵,H(X,Y)反映了X和Y這兩個統計量信息量的總和:
(4)
H(X)是X的信息熵,H(X/Y)是給定Y的條件下X的信息量,根據式(3)和式(4)可以計算出統計量間的互信息熵。
I(X,Y)=H(X)-H(X/Y)=
H(X)+H(Y)-H(X,Y)=
I(Y,X)
(5)
互信息熵反映了兩個統計量之間信息量的相互影響,可利用概率分布來估計互信息熵:
(6)
其中,PX,Y(x,y)指X和Y的聯合概率密度分布,PX(x)·PY(y)指X和Y各自獨立時的概率分布。
互信息熵反映了兩個統計量間的相互影響程度。當互信息熵為零時,這兩個統計量相互獨立,當互信息熵增大時,兩個統計量間的相關程度增強。
2 多任務特征學習概率模型
多任務特征學習[13-19]旨在學習多個相關任務的共同特征表示。在網絡加密流量識別中,將不同加密協議的網絡加密流量識別看作不同的任務,盡管各個任務中網絡流量的加密協議不同,但加密流量都具有隨機性的特征,因此,可以通過多任務特征學習對多個任務的聯合特征進行學習,識別網絡加密流量。
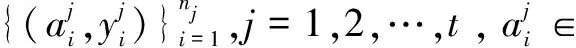
(7)
其中,wj∈d是第j個任務的權重向量,全部t個任務的權重向量形成權重矩陣W=[w1,w2,…,wt]∈d×t。
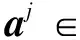
(8)
記σ=[σ1,σ2,…,σt]T∈t,假定數據{A,y}獨立于分布式(8),則似然函數可以寫成:
為了捕獲任務間的相關性,定義先驗W,W的第i行記為wi∈1×t,對應所有任務的第i個特征,假設wi由以下指數先驗產生:
p(wi|δi)∝exp(-‖wi‖δi),i=1,2,…,d
(10)
其中,δi>0為超參數,當t=1時,式(10)為拉普拉斯先驗。假定δ=[δ1,δ2,…,δd]T∈d,w1,w2,…,wd獨立于先驗(10),W的先驗表示為:
(11)
W的后驗正比于先驗和似然函數的乘積,即:
p(W|A,y,σ,δ)∝p(y|W,A,σ)p(W|δ)
(12)
取式(12)的負對數并結合式(7)~式(11),通過最小化式(13)可得到W的最大后驗估計。
(13)
簡單起見,假定σ=σj,?j=1,2,…,t,并且δ=δi,?i=1,2,…,d,由式(13)可得到2,1范式正則化的最小二乘回歸問題,即:
(14)

(15)
其中,ρ>0為正則化參數;loss(W)為凸光滑的損失函數,如最小二乘損失或logistic損失。
如果是單任務,則式(10)為拉普拉斯先驗分布,此時式(15)就是1范式正則化優化問題。如果是多個任務,第i個特征的權重通過wi的二范式分組聚集,因此,2,1范式正則化傾向于對多個任務進行聯合特征學習。
3 基于多任務特征學習的網絡加密流量識別算法
利用網絡加密流量的隨機性特征,提出基于多任務特征學習的網絡加密流量識別算法。首先采集網絡數據流樣本,對數據流進行預處理,獲取載荷信息作為有效數據;然后,對有效數據進行NIST SP800-22隨機性檢驗,獲取數據流的多維隨機性特征;最后對這些隨機性特征進行多任務特征學習,利用學習模型對未知樣本進行加密流量識別。算法流程如圖1所示。

圖1 基于多任務特征學習的網絡加密流量識別
3.1 數據預處理
對獲得的網絡數據進行預處理,獲取有效數據,主要包括以下幾個步驟:首先,根據傳輸鏈路的類型判斷具體的鏈路層協議,丟棄無關內容后對網絡層數據進行提取;然后,根據網絡層數據協議類型分類處理,丟棄非IP協議報文,對IP協議報文去除報頭內容后,將具有相同源、目的地址,相同源、目的端口以及相同協議的報文組成一個數據流;最后,對有效數據進行提取。如果數據流中的報文載荷是TCP或UDP協議報文,則去除相應的協議報頭后剩余的數據即是提取的有效數據;如果數據流中的載荷不是TCP或UDP協議報文,則可直接將數據流中的報文載荷作為有效數據。
3.2 隨機性特征提取
對數據預處理后得到的有效數據進行NIST SP800-22隨機性檢驗,利用NIST SP800-22的15種檢驗方法,一共可提取15類隨機性特征,根據不同的參數設置可得到不同維度的隨機性特征值。該文按照缺省設置,得到188維隨機性特征值。
3.3 多任務特征學習

通過最小化如下目標函數來求解W:
ρ‖W‖2,1
(16)
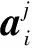
利用加速梯度方法(accelerated gradient methods,AGM)[20]來求解此優化問題。AGM不同于傳統的梯度方法,每次迭代使用前兩個點的線性組合作為搜索點,而不是僅使用最新點。AGM收斂速度為O(1/k2),這是最優的一階方法,AGM的關鍵子程序是計算鄰近算子。
(17)
式中,Ω(W,λ)為非平滑正則化項;γ為步長,?L(·)為L(·)的梯度;S為當前搜索點。
3.4 網絡加密流量識別
對于測試樣本X,依據式(18)判斷其是否為加密數據流:
y=sign(XTW+c)
(18)
4 實驗與結果分析
首先采集不同加密協議的網絡加密數據流和非加密數據流。作為研究對象的加密數據流取自網上銀行網站數據、VPN加密通信數據、TOR匿名通信和私有加密協議數據,非加密數據流取自普通新聞類網站數據和在線視音頻數據,對網絡流量進行預處理后得到有效載荷,對每一類數據,取5 000個樣本,每個數據樣本長度為1 000比特。然后對流量數據樣本進行NIST SP800-22隨機性檢驗,測試中的參數均使用缺省值,每個樣本可得到188維隨機性特征值。將得到的實驗數據集劃分為50%訓練數據集和50%驗證數據集。
4.1 識別參數選擇
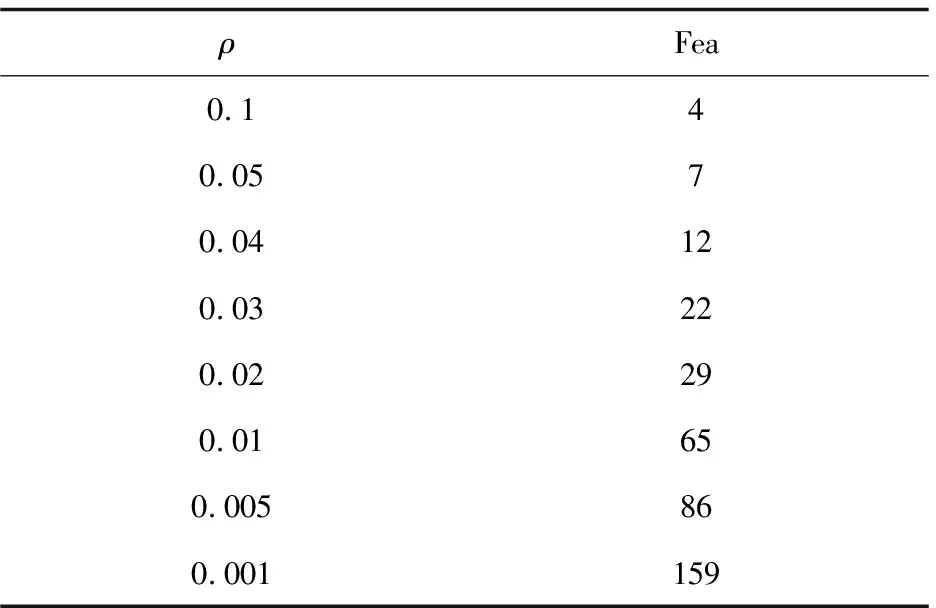
表1 學習的聯合隨機性特征數隨參數ρ變化
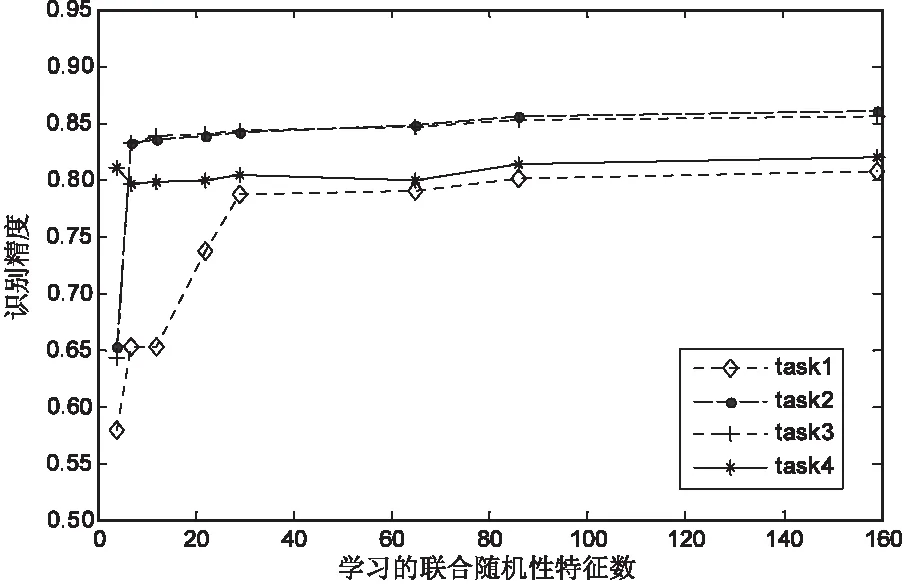
圖2 識別精度對比
4.2 識別性能分析
為了進一步驗證該文提出的基于多任務特征學習的網絡加密流量識別算法的有效性,與傳統的單任務特征學習算法進行了對比。
傳統的單任務特征學習算法不考慮任務之間的特征關聯關系,通過求解1范式正則化優化問題來進行單任務特征學習:
(19)
其中[a1,a2,…,an]∈n×d是隨機性特征矩陣,yi是樣本標簽,W是參數模型,c是偏置,單任務特征學習通過1正則化進行特征學習。單任務特征學習和多任務特征學習算法的平均識別精度對比如圖3所示。由圖3可以看出,多任務特征學習的平均識別精度超過80%,單任務特征學習的平均識別精度明顯低于多任務特征學習,但單任務特征學習的平均識別精度隨著特征數變化的穩定性優于多任務特征學習。

圖3 平均識別精度對比
5 結束語
基于多任務特征學習,將NIST SP800-22的15種隨機性檢驗方法得到的檢驗數值作為188維隨機性特征值,利用2,1正則化項對一組相關任務進行聯合特征學習,不僅能夠準確識別已知加密協議流量,同時還對未知加密協議流量具有一定的識別能力。實驗結果表明,提出的算法可以有效識別網絡加密流量,平均識別精度超過80%。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
