遙感影像目標(biāo)分類的三種基礎(chǔ)機(jī)器學(xué)習(xí)方法比較
2021-07-07 06:19:56周海龍柴需楷張金童彭思卿楊陽趙驍翊武義軒姜瑜王珂尹偉男白曉樂李志亮鄭逢杰陳興峰
河北遙感 2021年2期
關(guān)鍵詞:分類
周海龍,柴需楷,張金童,彭思卿,楊陽,趙驍翊,武義軒,姜瑜,王珂,尹偉男,白曉樂,李志亮,鄭逢杰,陳興峰
(1.航天工程大學(xué)航天信息學(xué)院,北京101416;2.中國科學(xué)院空天信息創(chuàng)新研究院,北京100094)
遙感技術(shù)在近幾十年高速發(fā)展,海量的遙感數(shù)據(jù)已經(jīng)基本滿足了人們對于地表成像的各種需求,高空間分辨率、高光譜、熱紅外、合成孔徑雷達(dá)等多類數(shù)據(jù)服務(wù)于國土調(diào)查、地質(zhì)災(zāi)害、海洋研究、農(nóng)業(yè)監(jiān)測、退耕還林、氣象環(huán)境變化等多個領(lǐng)域,遙感在其中發(fā)揮了巨大的作用[1-6]。伴隨著計算機(jī)技術(shù)的發(fā)展,遙感與計算機(jī)被連接在一起,目前遙感圖像解譯分為人工、計算機(jī)自動、人機(jī)結(jié)合三種方式,自從深度學(xué)習(xí)技術(shù)在圖像、語音識別領(lǐng)域取得突破進(jìn)展之后,遙感圖像目標(biāo)分類也越來越多的使用深度學(xué)習(xí)方法[7-9]。當(dāng)前識別的方法得到較多關(guān)注和應(yīng)用的有U-net[10-12]、Yolo[13-15]等,這些方法設(shè)計了復(fù)雜的深度學(xué)習(xí)模型架構(gòu)。總結(jié)來看,都是基于一些基礎(chǔ)的模型架構(gòu)進(jìn)行利用,這些基礎(chǔ)模型對遙感目標(biāo)分類的敏感性準(zhǔn)確度有何差異?本文針對遙感圖像分類識別應(yīng)用進(jìn)行了多種方法的實驗研究,旨在分析比較各種算法的性能與優(yōu)劣,為基礎(chǔ)機(jī)器學(xué)習(xí)的使用選擇以及遙感目標(biāo)分類的復(fù)雜深度學(xué)習(xí)架構(gòu)設(shè)計提供參考。
對比實驗使用已標(biāo)注的光學(xué)遙感圖像數(shù)據(jù)集,構(gòu)建了3種深度學(xué)習(xí)基礎(chǔ)模型架構(gòu):全連接神經(jīng)網(wǎng)絡(luò)(Full Connected Neural Network, FCNN)、卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network, CNN)、隨機(jī)森林(Random Forest, RF)。通過遙感分類的混淆矩陣給出總體精度,對不同的模型進(jìn)行評價。
1 三種深度學(xué)習(xí)方法
1.1 全連接神經(jīng)網(wǎng)絡(luò)(FCNN)
全連接神經(jīng)網(wǎng)絡(luò)的網(wǎng)絡(luò)結(jié)構(gòu)由輸入層、隱藏層、輸出層構(gòu)成,全連接的含義即為隱藏層中各節(jié)點都與上一層的所有節(jié)點連接,其基本網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示。

圖1 全連接神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)示意圖
神經(jīng)網(wǎng)絡(luò)思路來源于人的神經(jīng)細(xì)胞,整個網(wǎng)絡(luò)的運行是由一個神經(jīng)元的輸出作為下一個神經(jīng)元的輸入層層傳導(dǎo)的。類似于人的神經(jīng)細(xì)胞,會響應(yīng)刺激并將反應(yīng)結(jié)果表現(xiàn)在人體動作上,神經(jīng)網(wǎng)絡(luò)會對輸入數(shù)據(jù)進(jìn)行處理即進(jìn)行一個線性運算,之后再通過激活函數(shù)做個非線性運算,這個過程相當(dāng)于神經(jīng)網(wǎng)絡(luò)對數(shù)據(jù)進(jìn)行更深層次的理解,而后通過一層層的神經(jīng)元處理傳導(dǎo),整個神經(jīng)網(wǎng)絡(luò)都對輸入數(shù)據(jù)有了響應(yīng),最后經(jīng)過輸出層,全連接神經(jīng)網(wǎng)絡(luò)將處理后的結(jié)果傳遞出來。
1.2 卷積神經(jīng)網(wǎng)絡(luò)(CNN)
FCNN 是將一維向量數(shù)據(jù)作為輸入,整個網(wǎng)絡(luò)僅僅處理數(shù)據(jù)。CNN 在此基礎(chǔ)上加入了神經(jīng)網(wǎng)絡(luò)對于空間結(jié)構(gòu)的學(xué)習(xí),引入了卷積核的概念。CNN 的輸入數(shù)據(jù)是二維的,卷積核會對二維數(shù)據(jù)進(jìn)行逐塊處理,如圖2 所示,類似于人看報紙一塊塊閱讀之后提煉主要信息,卷積核處理完之后會得到更加簡單的附有空間信息的數(shù)據(jù)。CNN 的網(wǎng)絡(luò)結(jié)構(gòu)包含輸入層、卷積層、最大池化層、全連接層和輸出層,卷積層和最大池化層利用卷積核對二維數(shù)據(jù)進(jìn)行空間信息的提取,之后轉(zhuǎn)換成一維向量再利用FCNN 的原理處理得到結(jié)果。

圖2 卷積核工作示意圖
1.3 隨機(jī)森林(RF)
隨機(jī)森林的基礎(chǔ)為決策樹,決策樹基本形式如圖3 所示。隨機(jī)森林顧名思義是由許多決策樹共同構(gòu)成的,它們擁有某種方式的隨機(jī)性,并且隨機(jī)森林的每一棵決策樹之間是沒有關(guān)聯(lián)的,隨機(jī)森林中決策樹的每個內(nèi)部的節(jié)點代表對一類屬性進(jìn)行“測試”,每個分支代表測試后結(jié)果,每一個葉子節(jié)點代表一個類標(biāo)簽。在形成森林之后,當(dāng)有輸入時,所有決策樹都進(jìn)行判斷選擇最適合本決策樹分類要求的類標(biāo)簽,最終所有決策樹會投票表決,得票多的成為最終的輸出結(jié)果。單棵決策樹的分類能力很弱,利用多棵不相關(guān)的樹組合增強(qiáng)結(jié)果可信度,隨機(jī)森林通過這種方式提高樣本類型預(yù)測的準(zhǔn)確性。

圖3 決策樹基本形式
2 遙感數(shù)據(jù)樣本
光學(xué)遙感圖像從遙感圖像描述數(shù)據(jù)集Remote Sensing Image Captioning Data Set (RSICD)[16]獲取。數(shù)據(jù)集RSICD 從Google 地球,百度地圖,MapABC,天地圖等收集了1 萬多張高分辨率遙感圖像,該數(shù)據(jù)集具有較高的類內(nèi)多樣性和較低的類間差異性,適合用于深度學(xué)習(xí)模型對比。目標(biāo)分類的標(biāo)注信息來自于圖像的文件名。
所有光學(xué)遙感樣本均是高寬為224 像素的RGB圖像,并分為測試集與訓(xùn)練集用于模型的訓(xùn)練與檢測。從其中共選取了8 類典型地表目標(biāo),具體樣本歸類和數(shù)據(jù)集情況如表1 所示。

表1 光學(xué)遙感圖像樣本數(shù)據(jù)集介紹
3 方法
Python 的TensorFlow 庫 與sklearn 庫 提 供 了FCNN、CNN、RF 的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置與網(wǎng)絡(luò)訓(xùn)練測試模塊,選擇用Python 對三個算法進(jìn)行訓(xùn)練。程序主要有三塊內(nèi)容,分別為輸入、網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置和輸出。由于Python 的TensorFlow 庫與sklearn 庫不能直接將RGB 的三波段圖像作為FCNN、CNN、RF 的輸入,所以將選擇的圖像數(shù)據(jù)在輸入神經(jīng)網(wǎng)絡(luò)之前由RGB格式的圖像轉(zhuǎn)換為單波段灰度圖像,方便之后三種機(jī)器學(xué)習(xí)的數(shù)據(jù)讀入。三個算法網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置完成之后將進(jìn)行數(shù)據(jù)的訓(xùn)練,設(shè)定的訓(xùn)練樣本數(shù)與測試樣本數(shù)約為8:1。最終的結(jié)果將分別呈現(xiàn)三個算法的精度與混淆矩陣。
三種機(jī)器學(xué)習(xí)基礎(chǔ)模型的設(shè)計開發(fā)情況如下。
3.1 全連接神經(jīng)網(wǎng)絡(luò)
基于Python 的TensorFlow 庫對FCNN 的網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行設(shè)置與測試。FCNN 的網(wǎng)絡(luò)結(jié)構(gòu)包含三部分:輸入、隱藏層、輸出。FCNN 的輸入需要的是一維向量,因此將單波段的灰度圖像由二維矩陣轉(zhuǎn)換到一維向量,輸入為長度是50176 的一維向量。隱藏層中設(shè)置了6 個全連接層,神經(jīng)元個數(shù)按照遞減的形式設(shè)置,輸出時的神經(jīng)元個數(shù)為8 個,對應(yīng)所分的8 類目標(biāo),其激活函數(shù)為‘softmax’,其余全連接層的激活函數(shù)為‘relu’。
具體的FCNN 網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置如表2 所示,網(wǎng)絡(luò)結(jié)構(gòu)示意圖見圖4。

圖4 FCNN 網(wǎng)絡(luò)結(jié)構(gòu)示意圖

表2 FCNN 結(jié)構(gòu)設(shè)置
3.2 卷積神經(jīng)網(wǎng)絡(luò)
基于Python 的TensorFlow 庫對CNN 的網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行設(shè)置與測試。CNN 的輸入是圖像對應(yīng)的224×224 的二維數(shù)據(jù),其隱藏層包含了四部分,即卷積層、最大池化層、折疊層、全連接層。使用兩個卷積層和兩個最大池化層用于對二維數(shù)據(jù)進(jìn)行處理提取圖像重要空間信息,而后選擇使用折疊層將二維數(shù)據(jù)轉(zhuǎn)化成一維向量,再經(jīng)過兩個全連接層后輸出8 個神經(jīng)元節(jié)點對應(yīng)8 類目標(biāo),兩個全連接層的激活函數(shù)均為‘Relu’。具體的網(wǎng)絡(luò)結(jié)構(gòu)如表3 所示,網(wǎng)絡(luò)結(jié)構(gòu)示意圖見圖5。

表3 CNN 結(jié)構(gòu)設(shè)置

圖5 CNN 網(wǎng)絡(luò)結(jié)構(gòu)示意圖
3.3 隨機(jī)森林
使用Python 平臺的sklearn 庫對RF 的網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行設(shè)置與測試。Sklearn 庫中的randomforest 函數(shù)集成了隨機(jī)森林的主要結(jié)構(gòu),只需對RF 樹的數(shù)量與深度進(jìn)行設(shè)置就可以得出結(jié)果,經(jīng)過嘗試之后選擇樹的數(shù)量為3000,樹的深度為1000。袋外數(shù)據(jù)為未用于測試的輸入圖像數(shù)據(jù),為提高精度,選擇引入袋外數(shù)據(jù)。具體的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置如表4 所示,網(wǎng)絡(luò)結(jié)構(gòu)示意圖見圖6。

表4 RF 結(jié)構(gòu)設(shè)置

圖6 RF 網(wǎng)絡(luò)結(jié)構(gòu)示意圖
3.4 開發(fā)環(huán)境
基于Python 平臺的TensorFlow 庫設(shè)計開發(fā)FCNN、CNN 分類 器,基 于Python 平臺的Sklearn 庫設(shè)計開發(fā)RF 分類器。3 個網(wǎng)絡(luò)結(jié)構(gòu)在相同配置下進(jìn)行測試訓(xùn)練,具體開發(fā)運行環(huán)境如表5 所示:

表5 深度學(xué)習(xí)模型開發(fā)運行軟硬件環(huán)境
4 結(jié)果
4.1 混淆矩陣
混淆矩陣是在圖像精度評價過程中常用的一種可視化方式,其為二維矩陣,每一列代表了實際應(yīng)該獲取的信息,每一列數(shù)據(jù)總和為該類目標(biāo)的測試集數(shù)量,每一行代表了模型預(yù)測獲取的信息,每一行數(shù)據(jù)總和為預(yù)測的該類目標(biāo)數(shù)量。矩陣對角線上的數(shù)值為對應(yīng)目標(biāo)正確分類的數(shù)量。混淆矩陣可以直觀看出每一類目標(biāo)的分類效果并利于分析影響分類精度的原因。利用混淆矩陣計算分類精度的公式如式1 所示。
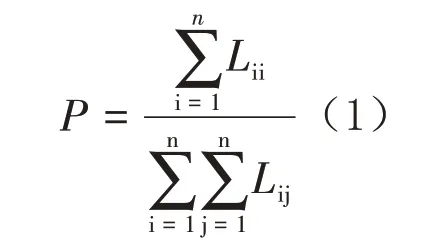
式中:P為分類精度,i和j分別為行數(shù)與列數(shù),L為需要計算的混淆矩陣,n 為混淆矩陣的維度。
利用上述網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置得到FCNN、CNN、RF 的混淆矩陣分別如表6、表7、表8 所示。

表6 FCNN 混淆矩陣

表7 CNN 混淆矩陣

表8 RF 混淆矩陣

meadow sparseres idential stadium 1 0 0 0 0 1 0 0 0 0 0 0 0 0 1 24 0 0 1 39 0 0 0 23
4.2 結(jié)果分析
根據(jù)混淆矩陣可以分析出,最容易被錯分的為desert 和bareland 類,如圖7(a)、圖7(b)所示,錯分原因為兩類在整體的色調(diào)形狀接近,紋理上都沒有太大的起伏,導(dǎo)致特征提取結(jié)果相似,使得精度較低。beach 類是效果較好的,如圖7(c)所示,從影像可以看出,這一類有清晰的分界線,沙灘與大海的界限清晰,梯度下降明顯,便于特征提取,因此此類別精度高。類似于人,機(jī)器分類的時候也需要有明顯的特征才能給出滿意的效果。影響分類精度的不僅僅是算法,數(shù)據(jù)集的分類效果也對精度有一定影響。(圖7(a)(b)(c),見中間彩頁)
由混淆矩陣結(jié)合式1 可以得到FCNN、CNN、RF的分類精度分別為62.2%;89.1%;80%,可見CNN 的精度是這三類中精度最高的。結(jié)合網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置分析,F(xiàn)CNN 與RF 網(wǎng)絡(luò)的輸入是一維數(shù)據(jù),而CNN的數(shù)據(jù)就是對應(yīng)圖像的二維數(shù)據(jù),將二維數(shù)據(jù)轉(zhuǎn)換到一維數(shù)據(jù)會丟失圖像一些空間信息,因此CNN 相比于FCNN 與RF 更能反映圖像的真實空間信息,所以CNN會得到更高的精度。
5 結(jié)論
深度學(xué)習(xí)等算法已經(jīng)融入到各行各業(yè),不同的算法各自展現(xiàn)著不同的優(yōu)勢,其發(fā)展離不開基礎(chǔ)的機(jī)器學(xué)習(xí)算法,基礎(chǔ)的機(jī)器學(xué)習(xí)算法經(jīng)過不斷的開發(fā)與新思想的注入,衍生出新的算法。為研究基礎(chǔ)的機(jī)器學(xué)習(xí)算法對于目標(biāo)的識別精度如何,本文基于Python平臺的TensorFlow庫與sklearn庫對FCNN、CNN 和RF 三種基礎(chǔ)機(jī)器學(xué)習(xí)算法進(jìn)行網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計,并利用一組光學(xué)圖像進(jìn)行訓(xùn)練與測試,最終根據(jù)網(wǎng)絡(luò)結(jié)構(gòu)與混淆矩陣分析得出結(jié)論:CNN對于光學(xué)圖像的識別精度最高。CNN通過卷積核對二維圖像進(jìn)行特征提取,而FCNN和RF在輸入的時候已經(jīng)把圖像轉(zhuǎn)換成一維向量,不利于二維信息的提取,因此CNN作為目標(biāo)識別和分類的基礎(chǔ)型機(jī)器學(xué)習(xí)模型是合理的。
遙感目標(biāo)分類和識別的深度學(xué)習(xí)方法發(fā)源自通用的圖像識別領(lǐng)域,對于遙感的定量化信息使用不足,甚至在光譜、量化等級方面有所損失,圖像數(shù)據(jù)被壓縮會降低分類精度,相反引入附加數(shù)據(jù)或許能夠提高目標(biāo)識別精度。相信未來定量遙感和深度學(xué)習(xí)的結(jié)合,有助于提高遙感目標(biāo)分類精度。
猜你喜歡
西北民族大學(xué)學(xué)報(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
