一種改進(jìn)時(shí)序卷積網(wǎng)絡(luò)的序列推薦方法
2021-07-08 08:27:40施浩杰劉學(xué)軍肖慶華
小型微型計(jì)算機(jī)系統(tǒng) 2021年7期
施浩杰,劉學(xué)軍,肖慶華
(南京工業(yè)大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,南京 211816)
1 引 言
推薦系統(tǒng)的主要目的是根據(jù)用戶的歷史交互信息,來(lái)預(yù)測(cè)用戶下一步的偏好行為[1].傳統(tǒng)的協(xié)同過濾(Collaborative Filtering,CF)方法認(rèn)為用戶的偏好和項(xiàng)目屬性都是靜態(tài)的,主要利用用戶信息(如個(gè)人資料、項(xiàng)目評(píng)分等)進(jìn)行相似度計(jì)算,從而進(jìn)行偏好分析,卻忽略了用戶的興趣偏好是一種時(shí)序數(shù)據(jù).用戶的興趣會(huì)隨著時(shí)間的變化發(fā)生偏移,項(xiàng)目屬性也會(huì)隨時(shí)間而變化,如電影的受歡迎程度會(huì)隨外部事件(如獲得奧斯卡獎(jiǎng))而發(fā)生變化[2].同時(shí),協(xié)同過濾方法使用未來(lái)的評(píng)分來(lái)評(píng)估當(dāng)前喜好的做法也在一定程度上違背了統(tǒng)計(jì)分析中的因果關(guān)系.近年來(lái),考慮用戶歷史行為的序列推薦方法,為問題的解決提供了新的思路.隨著深度學(xué)習(xí)的蓬勃發(fā)展,循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks,RNNs)由于其天然的序列結(jié)構(gòu),成為當(dāng)前學(xué)術(shù)界對(duì)序列進(jìn)行建模的主要工具.但RNN的決策要取決于所有過去的隱藏狀態(tài),無(wú)法在序列中充分利用并行計(jì)算,因此在訓(xùn)練和評(píng)估時(shí)的速度都受到限制.另外,在現(xiàn)實(shí)情況下,用戶的興趣可能并不是連續(xù)的.
如圖1(a)所示,通常情況下,用戶購(gòu)買手機(jī)之后,會(huì)傾向于依次購(gòu)買手機(jī)殼和充電寶,這個(gè)時(shí)候推薦系統(tǒng)可以依靠經(jīng)驗(yàn)推薦數(shù)據(jù)線.但是實(shí)際會(huì)出現(xiàn)這樣的情況,如圖1(b)所示,用戶在瀏覽了手機(jī)和充電寶之后,又突然搜索了并不相關(guān)的自行車,這時(shí)自行車的瀏覽就會(huì)成為推薦充電寶的干擾項(xiàng),因此需要在推薦時(shí)考慮更為久遠(yuǎn)的項(xiàng)目,從而對(duì)推薦列表的生成產(chǎn)生影響.
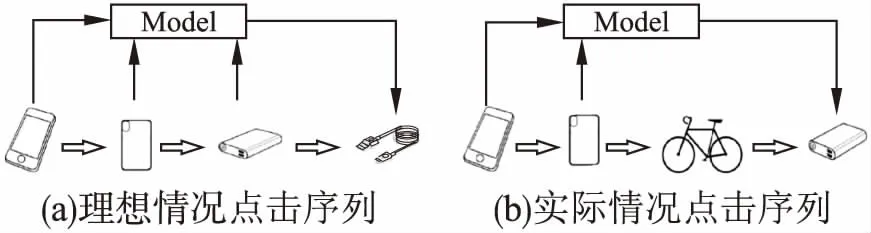
圖1 傳統(tǒng)序列推薦方法存在的問題Fig.1 Problems in traditional sequential recommendation methods
為了解決上述問題,本文提出了一種基于改進(jìn)的時(shí)序卷積網(wǎng)絡(luò)的序列推薦方法(SETCNs),主要工作包括:1)使用時(shí)序卷積網(wǎng)絡(luò)(Temporal Convolutional Network,TCN)取代傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò),作為捕捉序列信息的主要模型,通過結(jié)構(gòu)空洞的擴(kuò)張卷積擴(kuò)大感受野,捕捉更為復(fù)雜的序列關(guān)系,從而加強(qiáng)了長(zhǎng)期依賴;2)通過將殘差連接和注意力機(jī)制結(jié)合,在TCN的基礎(chǔ)上對(duì)壓縮-激勵(lì)網(wǎng)絡(luò)[3](SENets)進(jìn)行了改進(jìn).通過壓縮激勵(lì)模塊,讓TCN能夠?qū)娱g的短時(shí)空間特征序列的權(quán)值進(jìn)行重新標(biāo)定,從而更好地利用序列特征,加強(qiáng)重點(diǎn)項(xiàng)目對(duì)推薦決策的影響,實(shí)現(xiàn)更好的推薦效果.
2 相關(guān)工作
傳統(tǒng)的序列推薦研究主要有頻繁模式挖掘(Frequent Pattern Mining,FPM)和馬爾可夫鏈模型(Markov Chains,MCs).
頻繁模式挖掘的基本思想是首先在序列數(shù)據(jù)上尋找頻繁模式,通俗來(lái)說即項(xiàng)目A和項(xiàng)目B的共現(xiàn)性,然后利用挖掘出的模式來(lái)指導(dǎo)后續(xù)的推薦.Lu等[4]提出了一種移動(dòng)應(yīng)用程序順序模式挖掘方法,考慮用戶移動(dòng)和應(yīng)用啟動(dòng),以發(fā)現(xiàn)順序模式,用于通過預(yù)測(cè)用戶的下一個(gè)使用的應(yīng)用程序來(lái)解決上下文自適應(yīng)的問題.頻繁模式挖掘雖然簡(jiǎn)單直接,但會(huì)產(chǎn)生大量的冗余模式,增加不必要的開銷.并且由于頻率約束,會(huì)經(jīng)常丟失那些出現(xiàn)頻率低的模式和項(xiàng)目,這使得推薦結(jié)果被限制在那些流行的項(xiàng)目.
基于馬爾可夫鏈的推薦方法,其主要學(xué)習(xí)的是狀態(tài)轉(zhuǎn)移概率,即用戶點(diǎn)擊物品A之后,下一次點(diǎn)擊的物品是B的概率,并基于這個(gè)狀態(tài)轉(zhuǎn)移概率進(jìn)行推薦.Khattar等[5]提出了一種基于項(xiàng)目的協(xié)同過濾的新方法,用于使用馬爾科夫決策過程(Markov Decision Process,MDP)推薦新聞項(xiàng)目,最簡(jiǎn)單的MDP本質(zhì)上是一階馬爾科夫鏈,其中可以基于項(xiàng)目之間的轉(zhuǎn)移概率簡(jiǎn)單地計(jì)算下一個(gè)推薦.這類算法缺點(diǎn)是當(dāng)試圖包括用戶所有可能選擇的序列時(shí),狀態(tài)的數(shù)量會(huì)隨問題維度擴(kuò)大而指數(shù)增加,狀態(tài)空間難以管理.因?yàn)殡S著物品的增加,建模所有可能的點(diǎn)擊序列是十分困難的.另一方面,由于馬爾可夫特性假設(shè)當(dāng)前的交互僅取決于一個(gè)或最近的幾個(gè)交互,因此只能捕獲短期依賴而忽略了長(zhǎng)期的依賴關(guān)系.He等[6]基于馬爾可夫鏈提出了一種個(gè)性化的序列推薦模型,將矩陣分解和馬爾可夫鏈方法結(jié)合起來(lái),以同時(shí)適應(yīng)長(zhǎng)期和短期動(dòng)態(tài).
近年來(lái),學(xué)術(shù)界也涌現(xiàn)出了利用深度學(xué)習(xí)方法來(lái)對(duì)序列推薦進(jìn)行建模的熱潮,其中一些解決方案代表了序列推薦研究領(lǐng)域的最新技術(shù).Hidasi等[7]使用門控循環(huán)單元(Gated Recurrent Unit,GRU)來(lái)建模序列數(shù)據(jù),直接從給定會(huì)話中的先前點(diǎn)擊學(xué)習(xí)會(huì)話表示,并提供下一個(gè)動(dòng)作的建議.這是首次嘗試應(yīng)用RNN來(lái)解決序列推薦問題,模型結(jié)果比傳統(tǒng)方法有非常顯著的提升.Tan等[8]進(jìn)一步研究了RNN在基于序列推薦領(lǐng)域的應(yīng)用,提出了一種數(shù)據(jù)增強(qiáng)技術(shù),并改變輸入數(shù)據(jù)的數(shù)據(jù)分布,用于改進(jìn)模型的性能.Li等[9]提出一種基于RNN的編碼器-解碼器模型,它將來(lái)自RNN的最后隱藏狀態(tài)作為序列行為,并使用先前點(diǎn)擊的隱藏狀態(tài)進(jìn)行注意力計(jì)算,以捕獲給定會(huì)話中的主要目的(一般興趣).Jannach等[10]將循環(huán)方法和基于鄰域的方法結(jié)合在一起,以混合順序模式和共現(xiàn)信號(hào).Tuan等[11]將會(huì)話點(diǎn)擊與內(nèi)容特征(如項(xiàng)目描述和項(xiàng)目類別)結(jié)合起來(lái),通過使用三維卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNNs)生成推薦.為了解決基本神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的局限性,一些高級(jí)模型通常與某種基本的神經(jīng)網(wǎng)絡(luò)結(jié)合,來(lái)應(yīng)對(duì)特定的挑戰(zhàn).例如,注意力模型通常被用來(lái)在一個(gè)序列中強(qiáng)調(diào)那些真正重要的交互作用,同時(shí)淡化那些與下一次交互作用無(wú)關(guān)的交互.Liu等[12]提出了一個(gè)短期注意優(yōu)先模型,通過采用簡(jiǎn)單的多層感知器(Multi-Layer Perceptron,MLP)和注意力網(wǎng)絡(luò)來(lái)捕捉用戶的一般興趣和當(dāng)前興趣.總的來(lái)說,基于深度學(xué)習(xí)的序列推薦研究方興未艾,主要涉及如何設(shè)計(jì)不同的網(wǎng)絡(luò)結(jié)構(gòu)以簡(jiǎn)便高效地捕獲高階動(dòng)態(tài).
近日,Bai等[13]對(duì)于序列問題提出了一種新的架構(gòu)時(shí)序卷積網(wǎng)絡(luò),與傳統(tǒng)的序列模型如LSTM或GRU相比,TCN具有更簡(jiǎn)單的結(jié)構(gòu)和更高的效率.在此基礎(chǔ)上,為了提取更完整的時(shí)間特征,本文在TCN的基礎(chǔ)上引入了SENets進(jìn)行增強(qiáng),SENets是一種新的結(jié)構(gòu)單元,其作用是通過對(duì)特征各個(gè)通道之間的相互依賴關(guān)系進(jìn)行建模,增強(qiáng)重點(diǎn)通道的權(quán)重來(lái)提高網(wǎng)絡(luò)表示的質(zhì)量.在本文的方法中,我們對(duì)SENets進(jìn)行了改進(jìn),通過使用壓縮激勵(lì)模塊,將其組合入TCN,增強(qiáng)TCN在時(shí)間特征提取中的能力,通過注意力機(jī)制加強(qiáng)了重點(diǎn)項(xiàng)目對(duì)推薦結(jié)果的影響.模型利用擴(kuò)張卷積增大感受野,捕獲更多的序列關(guān)系,利用殘差連接減小反向傳播過程中的梯度消失問題.通過對(duì)用戶和項(xiàng)目特征的融合,模型可以綜合考慮用戶的短期和長(zhǎng)期偏好進(jìn)行個(gè)性化推薦.
3 SETCNs方法
3.1 問題描述
序列推薦的主要任務(wù)是根據(jù)已獲得的用戶當(dāng)前序列信息(包括用戶的一系列歷史交互行為)中發(fā)現(xiàn)用戶的興趣偏好,預(yù)測(cè)的用戶下一步的點(diǎn)擊行為,并由此進(jìn)行項(xiàng)目推薦.
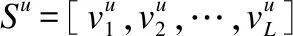
3.2 模型框架
圖2為SETCNs模型的總體框架.首先,所有的項(xiàng)目先被嵌入成高維向量,再根據(jù)時(shí)間戳組成序列數(shù)據(jù).項(xiàng)目的嵌入表示通過item2vec[14]生成,作為用戶的短期偏好,用戶的嵌入表示通過隱因子模型(Latent Factor Model,LFM)[15]生成,作為用戶的長(zhǎng)期偏好.模型的重點(diǎn)在于序列數(shù)據(jù)的建模,在TCN的基本框架下,通過擴(kuò)張卷積,逐層擴(kuò)大感受野,捕捉更多的序列關(guān)系.圖2中的壓縮-激勵(lì)模塊(Squeeze and Excitation Block,S-E Block)主要負(fù)責(zé)調(diào)整各維度之間的關(guān)系.各層之間通過殘差連接,在最后將用戶和項(xiàng)目獲得的向量拼接,共同輸入全連接層,獲得推薦項(xiàng)目的概率值.
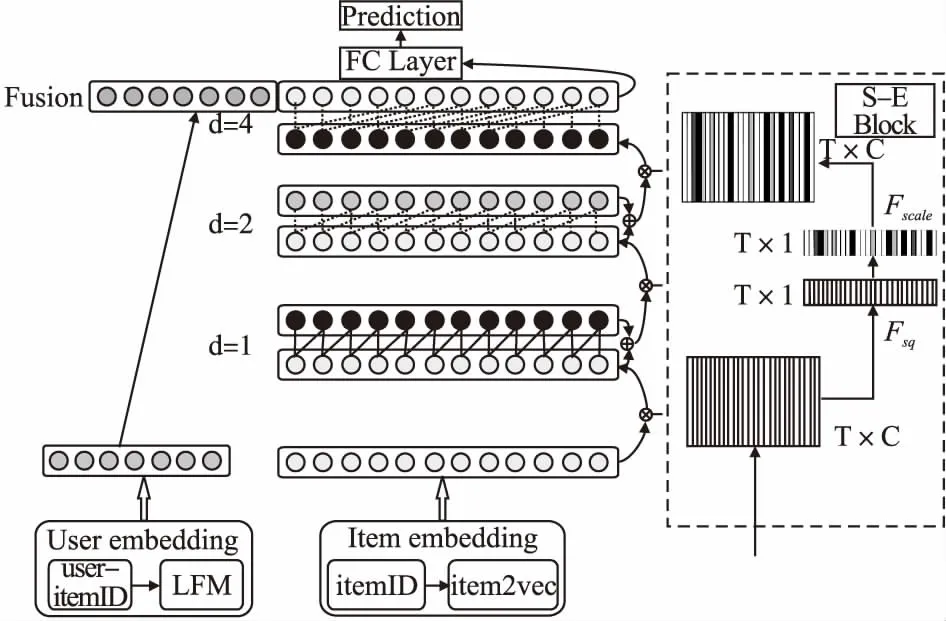
圖2 SETCNs整體框架Fig.2 Framework of SETCNs
3.2.1 嵌入層
假設(shè)將所有用戶的歷史項(xiàng)目交互定義為語(yǔ)料庫(kù)S,將某單一用戶u的歷史交互項(xiàng)目視為一個(gè)集合Su,且有Su∈S.通過學(xué)習(xí)所有用戶歷史記錄中項(xiàng)目間的共現(xiàn)關(guān)系,獲得該項(xiàng)目的詞向量表示.具體的目標(biāo)函數(shù)如公式(1)和公式(2):
(1)
(2)
其中,其中u∈Si,ν∈Sj,L為語(yǔ)料庫(kù)集合長(zhǎng)度,N為對(duì)于每個(gè)正樣本負(fù)采樣的個(gè)數(shù).
另外,對(duì)用戶的嵌入表示,采用LFM進(jìn)行表示.其基本思想是:認(rèn)為每個(gè)用戶都有自己的偏好,同時(shí)每個(gè)項(xiàng)目也包含所有用戶的偏好信息.而這個(gè)偏好信息即潛在因子,是潛在影響用戶對(duì)項(xiàng)目評(píng)分的因素.某個(gè)用戶u對(duì)某個(gè)項(xiàng)目i的感興趣程度可以表示為公式(3):
(3)
pu表示用戶u與K個(gè)潛在因子的關(guān)聯(lián)關(guān)系,qi表示物品i與K個(gè)潛在因子的關(guān)聯(lián)關(guān)系.以樣本出現(xiàn)的次數(shù)作為權(quán)重,隨機(jī)選擇項(xiàng)目構(gòu)建負(fù)樣本集,保證正負(fù)樣本平衡.通過將公式(4)作為損失函數(shù),利用隨機(jī)梯度下降(Stochastic Gradient Descent, SGD)算法在數(shù)據(jù)集上迭代更新,直至收斂.
(4)
將模型收斂后得到的用戶潛在因子矩陣p作為對(duì)用戶的嵌入表示.
3.2.2 擴(kuò)張因果卷積
本文引入TCN,采用擴(kuò)張因果卷積來(lái)提取特征.因果的思想是出于處理序列特征的要求,與傳統(tǒng)卷積方法不同點(diǎn)在于,因果卷積是在時(shí)間序列上進(jìn)行,具體如圖3所示.每一層的輸出都是由前一層對(duì)應(yīng)未知的輸入及其前一個(gè)位置的輸入共同得到.
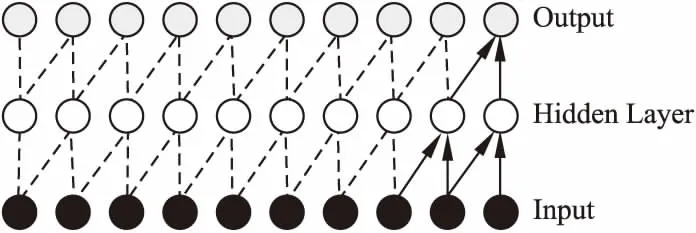
圖3 因果卷積Fig.3 Casual convolution
其數(shù)學(xué)模型可表示為:y1,y2,…,yt-1,yt=f(x1,x2,…,xt),簡(jiǎn)單來(lái)說,即根據(jù)x1,x2,…,xt和y1,y2,…,yt-1去預(yù)測(cè)yt,使得yt接近于實(shí)際值.
但是標(biāo)準(zhǔn)濾波器只能與感受野線性地進(jìn)行卷積,其深度會(huì)隨著網(wǎng)絡(luò)深度的增加而迅速增加.輸入和輸出距離越遠(yuǎn),就越需考慮之前的輸入?yún)⑴c運(yùn)算的問題.在推薦系統(tǒng)中可以理解為,當(dāng)前推薦項(xiàng)目的確定,需要更長(zhǎng)時(shí)間段上的用戶偏好信息.這帶來(lái)大量需要訓(xùn)練的參數(shù),因此難用以處理長(zhǎng)期序列.擴(kuò)張的基本思想是通過用零填充卷積濾波器,使其應(yīng)用于大于其原始長(zhǎng)度的場(chǎng),具體如圖4所示.通過擴(kuò)張卷積,模型在層數(shù)不大的情況下可以獲得更大的感受野,因此模型使用參數(shù)的較少.同時(shí),擴(kuò)張的卷積可以保留輸入的空間尺寸,使得后期卷積層和殘差結(jié)構(gòu)的堆疊操作都變得更加容易.
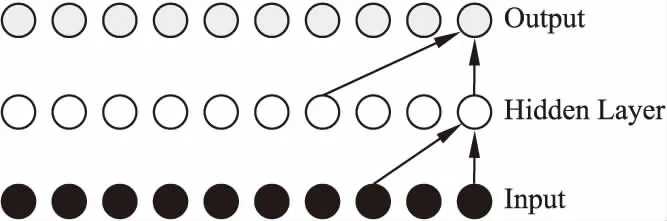
圖4 擴(kuò)張卷積Fig.4 Dilated convolution
擴(kuò)張卷積的計(jì)算如公式(5):
yt=(x*h)t=∑xt-dm·hm
(5)
其中*代表擴(kuò)張卷積的計(jì)算符號(hào),d是擴(kuò)張率,通常設(shè)為2的指數(shù)形式(1,2,4,8,…,2i),h是卷積濾波器的參數(shù).在實(shí)驗(yàn)中,為了更方便且直觀的使用擴(kuò)張卷積,需要對(duì)原始的數(shù)據(jù)進(jìn)行一維變換操作,如圖5所示,將大小為L(zhǎng)×D二維矩陣E轉(zhuǎn)換成大小為1×L×D的三維張量,E的每一行表示一個(gè)項(xiàng)目的嵌入表示,L表示序列的長(zhǎng)度,D表示項(xiàng)目嵌入的維度,可以類比視為圖像中的通道.
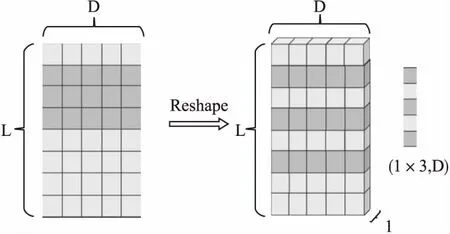
圖5 原始數(shù)據(jù)進(jìn)行一維變換Fig.5 One-dimensional transformation of the original data
3.2.3 壓縮激勵(lì)模塊
卷積濾波器利用在一定感受野內(nèi)融合空間和各通道間的信息達(dá)到特征提取的目的,一般通過使用不同大小的卷積核在同一特征圖上進(jìn)行滑動(dòng)來(lái)學(xué)習(xí)提取圖像的二維空間信息,獲得不同大小的感受野輸入神經(jīng)網(wǎng)絡(luò),增強(qiáng)網(wǎng)絡(luò)的表達(dá)能力,但是通常忽略了各個(gè)特征通道之間的關(guān)系.本文通過設(shè)計(jì)壓縮-激勵(lì)(Squeeze and Excitation)模塊,采用了一種全新的特征重標(biāo)定策略去建模各特征通道之間的相互依賴關(guān)系.通過網(wǎng)絡(luò)學(xué)習(xí)自動(dòng)獲取各個(gè)通道在當(dāng)前任務(wù)上的重要性,再根據(jù)學(xué)習(xí)到的通道權(quán)重,將注意力集中在關(guān)鍵的部分,提升有用特征權(quán)重,抑制對(duì)當(dāng)前任務(wù)用處不大的特征,從而完成增強(qiáng)網(wǎng)絡(luò)特征提取的作用.
壓縮操作是對(duì)提取到的特征,在每個(gè)通道上執(zhí)行全局平均池化(global average pooling).這將每個(gè)特征通道都?jí)嚎s成一個(gè)代表全局感受野的實(shí)數(shù),它表示該特征通道的全局響應(yīng),并且可以保持輸出維度和輸入的特征通道數(shù)一致.對(duì)于維度為D,長(zhǎng)度為T的一串序列E=[ν1,ν2,…,ν|T|],所計(jì)算的維度描述為z=[z1,z2,…,z|T|],其中z是一個(gè)T×1維的向量,其中每一個(gè)元素的計(jì)算如公式(6):
(6)
其中vt(i)代表序列第t個(gè)元素的第i個(gè)維度,此時(shí)可以將zt作為t時(shí)刻特征的權(quán)重.
為了利用壓縮操作的信息和利用通道間的信息依賴,接下來(lái)使用激勵(lì)操作來(lái)完成特征的重標(biāo)定,而且這個(gè)操作需要滿足兩個(gè)前提:第一,能夠利用簡(jiǎn)單靈活的操作獲得通道間的非線性關(guān)系;第二,學(xué)到的關(guān)系不一定是互斥的,因?yàn)樾枰訌?qiáng)多個(gè)通道特征,而不像one-hot編碼方式,只加強(qiáng)了某一個(gè)通道的特征.按公式(7)采用門控機(jī)制進(jìn)行激活.
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
(7)
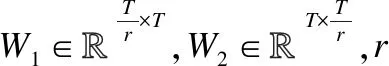
(8)
Fscale(vt,st)表示標(biāo)量st和特征圖vt∈RT之間的乘法,其實(shí)質(zhì)相當(dāng)于把vt矩陣中的每個(gè)值都乘以對(duì)應(yīng)的權(quán)重st,在通道維度上完成對(duì)特征權(quán)值的重新標(biāo)定.
完整的壓縮-激勵(lì)操作可視為一次編碼-反編碼的過程,先將T × 1的序列壓縮到r × 1獲取全局感受野,再將其激勵(lì)回新的T × 1序列.因?yàn)樵诿恳徊蕉技尤肓思?lì)函數(shù),所以在學(xué)習(xí)過程中,誤差始終能夠通過反向傳播調(diào)整參數(shù)W1和W2[16].因?yàn)樾蛄袛?shù)據(jù)的結(jié)構(gòu)并沒有改變,因此TCN模型也不需要改變?cè)镜慕Y(jié)構(gòu),可以直接利用序列權(quán)值再調(diào)整后的特征進(jìn)行訓(xùn)練.
3.2.4 殘差連接
在序列特征抽取過程中,因果卷積層和擴(kuò)張卷積層的疊加造成神經(jīng)網(wǎng)絡(luò)逐漸加深.為減少模型訓(xùn)練過程中,網(wǎng)絡(luò)反向傳播發(fā)生的梯度衰減和消失問題,需要在模型的輸出層引入殘差連接.殘差學(xué)習(xí)的基本思想是將多個(gè)卷積層堆疊在一起作為一個(gè)塊,然后采用跳躍連接的方法,將前一層的特征信息傳遞到后一層.將模型的輸入被加權(quán)融合到卷積網(wǎng)絡(luò)的輸出中,輸出被表述為輸入本身和其一個(gè)非線性變換的線性疊加.其表達(dá)如公式(9):
Output=σ(X+F(X))
(9)
其中,X表示輸入,F(xiàn)(X)表示前一層卷積層的輸出,σ表示sigmoid激活函數(shù).殘差連接的概念已經(jīng)在多種分類任務(wù)上取得了良好的應(yīng)用,在提取高維卷積特征后,殘差連接將大大提高模型的泛化能力,維護(hù)輸入信息并擴(kuò)大傳播梯度,減小訓(xùn)練難度,使得模型成為深層網(wǎng)絡(luò)和淺層網(wǎng)絡(luò)的集成.
3.2.5 全連接層
為了捕捉用戶的全局偏好,本文將用戶的嵌入表示與時(shí)序卷積提取的特征拼接,再通過全連接的方式,得到預(yù)測(cè)項(xiàng)目出現(xiàn)的概率分布.對(duì)具有L層的TCN,最后一層的輸出通過引入具有softmax激活函數(shù)的全連接層來(lái)實(shí)現(xiàn)序列分類.為減少在訓(xùn)練過程中的過擬合問題,在全連接層會(huì)采取Inverted dropout的方式隨機(jī)關(guān)閉神經(jīng)元的參數(shù)更新.與傳統(tǒng)的dropout方法不同之處在于,Inverted dropout操作僅在訓(xùn)練階段進(jìn)行,省略了測(cè)試階段的步驟.
3.3 網(wǎng)絡(luò)訓(xùn)練
模型采用監(jiān)督學(xué)習(xí)方式進(jìn)行訓(xùn)練,以數(shù)據(jù)集中序列數(shù)據(jù)對(duì)應(yīng)的下一個(gè)真實(shí)項(xiàng)目表示真實(shí)概率分布,將模型輸出的項(xiàng)目概率分布作為預(yù)測(cè)值.實(shí)驗(yàn)使用二元交叉熵(binary cross entropy)作為目標(biāo)函數(shù),訓(xùn)練目標(biāo)是最小化預(yù)測(cè)值與真實(shí)值之間的差異.為減少過擬合風(fēng)險(xiǎn)帶來(lái)的模型泛化能力降低,目標(biāo)函數(shù)引入了正則化.函數(shù)如公式(10):
(10)
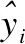
4 實(shí) 驗(yàn)
本文提出的網(wǎng)絡(luò)結(jié)構(gòu)基于Tensorflow平臺(tái)實(shí)現(xiàn),該實(shí)驗(yàn)在CPU為Intel Xeon E5-2630v3,顯卡為GTX 1080Ti(11G),內(nèi)存為32G的服務(wù)器上運(yùn)行,實(shí)驗(yàn)環(huán)境為Window10,Pycharm,Cuda9.0,Cudnn7.0.
4.1 數(shù)據(jù)集及實(shí)驗(yàn)設(shè)置
1.Movielens-1M數(shù)據(jù)集
Movielens1數(shù)據(jù)集是由美國(guó)明尼蘇達(dá)大學(xué)GroupLens實(shí)驗(yàn)室提供的在推薦系統(tǒng)領(lǐng)域常用的數(shù)據(jù)集,有多個(gè)大小的版本.主要包括一系列用戶對(duì)電影的評(píng)分,還附有這些用戶的信息(如用戶性別、職業(yè))和電影的信息(如電影類別).
2.Gowalla數(shù)據(jù)集
Gowalla2是一個(gè)基于位置的社交網(wǎng)站,用戶可以通過簽到共享自己的位置,每一次的操作都帶有時(shí)間戳.數(shù)據(jù)集中包括用戶軌跡和社交群組.
實(shí)驗(yàn)遵循以下預(yù)處理程序:將評(píng)論或評(píng)分的存在視為用戶與商品互動(dòng),從而將顯性反饋的評(píng)分?jǐn)?shù)據(jù)轉(zhuǎn)換為隱性反饋的交互行為數(shù)據(jù).使用時(shí)間戳確定序列的順序,并丟棄ML-1M中互動(dòng)次數(shù)低于5和Gowalla中互動(dòng)次數(shù)低于15的部分.將處理后的數(shù)據(jù)集的80%作為訓(xùn)練集,同時(shí)將剩下的20%作為測(cè)試集.同時(shí),將真實(shí)數(shù)據(jù)集中樣本視為正樣本,為增強(qiáng)數(shù)據(jù)集,在需要時(shí)通過隨機(jī)采樣生成負(fù)樣本.處理完的實(shí)驗(yàn)數(shù)據(jù)集相關(guān)數(shù)據(jù)如表1所示.
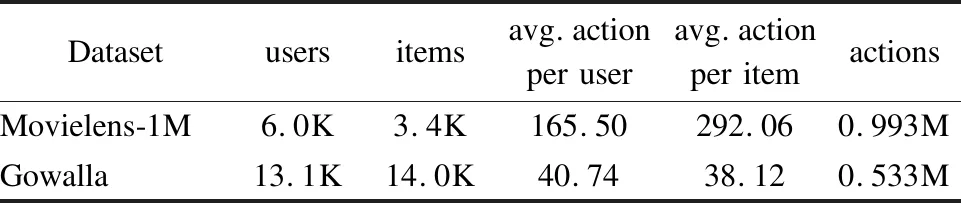
表1 處理后數(shù)據(jù)情況說明Table 1 Description of the processed data
4.2 評(píng)價(jià)指標(biāo)
本文使用召回率(Recall)和平均倒數(shù)排名(Mean Reciprocal Rank,MRR)作為評(píng)價(jià)指標(biāo),這兩個(gè)指標(biāo)也廣泛用于評(píng)估其他推薦系統(tǒng)相關(guān)工作.
Recall@K:該指標(biāo)表示用戶真實(shí)點(diǎn)擊的項(xiàng)目出現(xiàn)在推薦列表前K位的點(diǎn)擊序列個(gè)數(shù)占測(cè)試集中序列總數(shù)的比例.只關(guān)心其是否出現(xiàn)在推薦列表而不考慮其順序.這可以很好地模擬某些實(shí)際情況,絕對(duì)順序無(wú)關(guān)緊要,而不會(huì)突出顯示推薦.定義如公式(11):
(11)
其中N表示測(cè)試數(shù)據(jù)的總數(shù)量,nhit表示命中的項(xiàng)目數(shù)量.
MRR@K:該指標(biāo)表示用戶真實(shí)點(diǎn)擊項(xiàng)目在推薦列表中位置序號(hào)的倒數(shù)平均值,具體定義如公式(12).若用戶點(diǎn)擊項(xiàng)目沒有出現(xiàn)在推薦列表的前K位,MRR將結(jié)果為0.MRR在評(píng)價(jià)推薦列表質(zhì)量時(shí)會(huì)考慮物品的次序,是一個(gè)順序敏感的指標(biāo).
(12)
MRR是范圍[0,1]的歸一化分?jǐn)?shù),其值的增加反映了大多數(shù)“命中”將在推薦列表的排名位置中更高,表明相應(yīng)推薦系統(tǒng)的性能更好.
4.3 參數(shù)設(shè)置
對(duì)于SETCNs模型,本文使用Adam優(yōu)化器進(jìn)行訓(xùn)練,每
個(gè)壓縮-激勵(lì)模塊的增長(zhǎng)率(growth rate)k設(shè)為12,模塊的壓縮率(compression rate)c設(shè)為0.5,學(xué)習(xí)率(learning rate)初始化為1e-4,批量大小(batch size)設(shè)為32,dropout概率p設(shè)置為0.5,擴(kuò)張率(dilation rate)d設(shè)為[1,2,4].項(xiàng)目的嵌入維度分別設(shè)為[16,32,64,128],進(jìn)行對(duì)比.
4.4 實(shí)驗(yàn)對(duì)比
為了探究本文提出的模型效果,模型將與3種傳統(tǒng)推薦方法和3種基于循環(huán)神經(jīng)網(wǎng)絡(luò)的推薦方法分別在兩個(gè)常用數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)驗(yàn)證.其中,3種傳統(tǒng)方法包括:POP、S-POP和FPMC[17];3種基于循環(huán)神經(jīng)網(wǎng)絡(luò)的模型包括GRU4Rec、GRU4Rec+和NARM[18].
POP和S-POP分別推薦訓(xùn)練集和當(dāng)前會(huì)話中的前N個(gè)頻繁項(xiàng)目.
FPMC是一種綜合馬爾可夫鏈和矩陣分解的序列預(yù)測(cè)方法.
GRU4Rec是首次使用RNN對(duì)用戶序列進(jìn)行建模的方法.
GRU4Rec+進(jìn)一步提出了一種數(shù)據(jù)增強(qiáng)技術(shù),通過改變輸入數(shù)據(jù)的數(shù)據(jù)分布,改進(jìn)模型的性能.
NARM采用引入注意力機(jī)制的RNN捕獲用戶的主要興趣和序列行為.
實(shí)驗(yàn)首先觀察項(xiàng)目嵌入維度參數(shù)的選取對(duì)本文方法的影響,如圖6和圖7所示,在兩個(gè)數(shù)據(jù)集上,都可以發(fā)現(xiàn)項(xiàng)目的嵌入維度的增加會(huì)導(dǎo)致評(píng)價(jià)指標(biāo)的上升,考慮其中的原因是
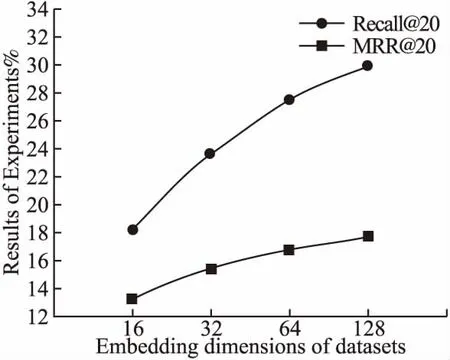
圖6 不同嵌入維度在Movielens-1M數(shù)據(jù)集對(duì)實(shí)驗(yàn)結(jié)果的影響Fig.6 Effects of different embedding dimensions on experimental results in Movielens-1M dataset
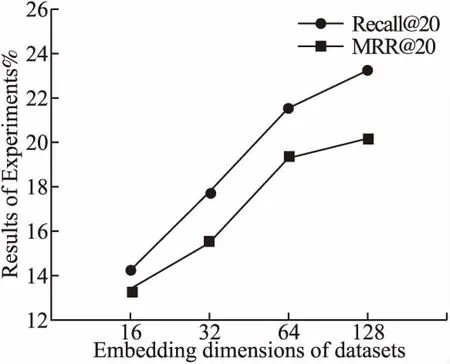
圖7 不同嵌入維度在Gowalla數(shù)據(jù)集對(duì)實(shí)驗(yàn)結(jié)果的影響Fig.7 Effects of different embedding dimensions on experimental results in Gowalla dataset
向量的維度過低表示能力不夠,而更高的維度會(huì)帶有更多的
1http://files.grouplens.org/datasets/movielens/ml-1m.zip
2http://snap.stanford.edu/data/loc-gowalla.html
隱含信息.通過S-E模塊,模型在高維度的情況下可以更好地捕獲其中的信息,但維度的增加也會(huì)帶來(lái)相應(yīng)的參數(shù)的增加和計(jì)算的開銷,這是需要在實(shí)際應(yīng)用中進(jìn)行衡量的問題.
以下的實(shí)驗(yàn)結(jié)果以最終結(jié)果表現(xiàn)最佳的項(xiàng)目嵌入維度為128為準(zhǔn),具體的各項(xiàng)實(shí)驗(yàn)結(jié)果對(duì)比如表2所示.
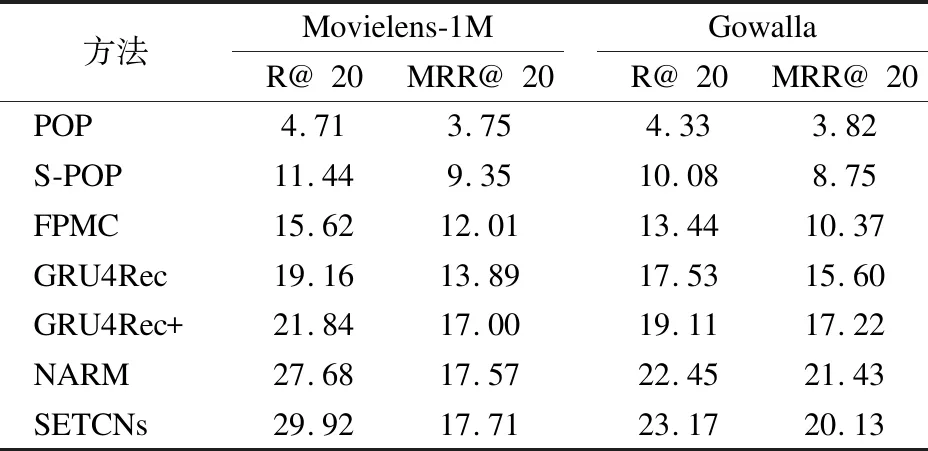
表2 實(shí)驗(yàn)結(jié)果對(duì)比Table 2 Comparison of experimental results
從表2中可以得出結(jié)論,相對(duì)于傳統(tǒng)的基于流行度的算法,基于神經(jīng)網(wǎng)絡(luò)的方法GRU4Rec,GRU4Rec+,NARM和SETCNs在各項(xiàng)指標(biāo)上都有較為明顯的提升,這是由于基于流行度的方法只考慮了個(gè)體的單獨(dú)點(diǎn)擊,忽略了用戶的興趣變化是一個(gè)時(shí)序相關(guān)的問題,沒有考慮過往項(xiàng)目對(duì)未來(lái)偏好指示的問題.
同時(shí),SETCNs表現(xiàn)也要優(yōu)于FPMC方法,這表明傳統(tǒng)的基于馬爾可夫鏈的方法主要依賴的連續(xù)項(xiàng)目的獨(dú)立性假設(shè)是不現(xiàn)實(shí)的,F(xiàn)PMC方法主要只捕捉一階馬爾可夫關(guān)系,但用戶的偏好并非絕對(duì)連續(xù),而是會(huì)受到各種因素的影響,產(chǎn)生間歇性的變化.
對(duì)比神經(jīng)網(wǎng)絡(luò)算法GRU4Rec和GRU4Rec+,SETCNs方法也有一定的提高,說明基于時(shí)序卷積網(wǎng)絡(luò)的方法可以處理更長(zhǎng)期的序列.與NARM方法相比,本文的方法提高不多,這是因?yàn)镹ARM方法同樣采用注意力機(jī)制來(lái)捕獲主要目的,但本文依舊在效果上依舊有所超越,這是由于時(shí)序卷積的結(jié)構(gòu)決定了它可以獲得更好地感受野,將更多的序列項(xiàng)目引入推薦的決策中.
另外,如圖8所示,通過對(duì)比SETCNs方法和GRU4Rec+方法的損失函數(shù)曲線變化圖發(fā)現(xiàn),SETCNs的loss值下降到穩(wěn)定值的速度比GRU4Rec+下降到穩(wěn)定值的速度更快,收斂性較好,表明SETCNs相對(duì)于傳統(tǒng)的循環(huán)神經(jīng)網(wǎng)絡(luò),訓(xùn)練速度更快,且取得較好收斂效果.同時(shí),與GRU4REC和NARM的對(duì)比也有類似的結(jié)論.因?yàn)樵趦蓚€(gè)數(shù)據(jù)集上獲取的結(jié)果類似,圖中只展示針對(duì)Movielens-1M數(shù)據(jù)集的訓(xùn)練效果.
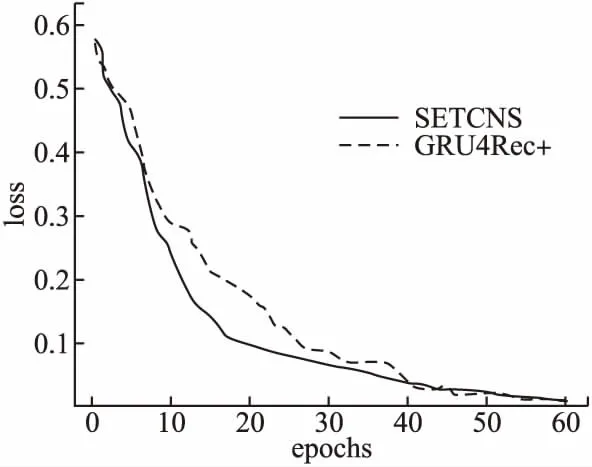
圖8 SETCNs方法與GRU4Rec+方法訓(xùn)練損失下降曲線對(duì)比Fig.8 Comparison of SETCNs and GRU4Rec+ in loss decline curve
5 總 結(jié)
本文針對(duì)傳統(tǒng)推薦算法無(wú)法表示用戶興趣的動(dòng)態(tài)變化,基于循環(huán)神經(jīng)網(wǎng)絡(luò)的推薦方法無(wú)法捕捉復(fù)雜的序列關(guān)系,長(zhǎng)期依賴差的問題,提出了一種針對(duì)序列推薦的SETCNs模型.在該模型中,通過嵌入壓縮激勵(lì)模塊的改進(jìn)時(shí)序卷積網(wǎng)絡(luò)來(lái)對(duì)序列時(shí)空特征進(jìn)行識(shí)別,利用注意力機(jī)制加強(qiáng)了重點(diǎn)項(xiàng)目對(duì)推薦決策的影響.模型通過對(duì)用戶的興趣隨時(shí)間的演變進(jìn)行序列建模,利用擴(kuò)張卷積增大感受野,捕獲更多的序列關(guān)系,利用殘差連接減小反向傳播過程中的梯度消失問題,并綜合考慮了用戶的長(zhǎng)期和短期偏好,為用戶提供個(gè)性化推薦.綜合實(shí)驗(yàn)結(jié)果表明,所提出的算法優(yōu)于基線算法,有效提升了推薦系統(tǒng)的精度.
猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
