融合改進Stacking與規則的文本情感分析
2021-07-08 08:27:42宛艷萍谷佳真
小型微型計算機系統 2021年7期
宛艷萍,谷佳真,張 芳
(河北工業大學 人工智能與數據科學學院,天津 300401)
1 引 言
文本情感分析是通過對文本的觀點、情感或者極性進行挖掘的一種計算機技術,是對用戶在互聯網中發布的帶有情感的文本進行整合和信息提取.相較于英文文本,中文文本因其句式、語法和分詞等方面更加復雜而分析更加困難,成為了研究者們進行情感分析的焦點.
現階段的中文文本情感分析技術大體分為兩種方法:基于規則的文本情感分析和基于機器學習的文本情感分析.基于規則的文本情感分析方法在處理跨領域文本時,其情感分析結果未達到應有效果;基于機器學習的文本情感分析方法包括傳統機器學習算法和深度學習算法,其訓練結果依賴于訓練集的設置,并且單一的傳統機器學習方法在處理不同文本時各有利弊.由于單一機器學習方法并不能滿足研究者們對文本情感分析的準確度要求,便將集成機器學習方法應用在該領域.
常見的集成學習方法有:Boosting、Bagging和Stacking等.其中Stacking算法集成了多個傳統機器學習算法,融合其各自優點,具有泛化能力強、比任何一種單一的機器學習效果好等優點.然而隨著人工智能的發展,可供Stacking集成的算法越來越多,而Stacking算法并不是隨著集成的分類器數量越多效果越好,對于文本情感分類領域,如何選擇集成的分類器種類也是一個有待解決的問題.
為了解決上述問題,本文擬實現一種基于融合改進Stacking與規則的文本情感分析方法:
1)建立基于文本規則的方法模型,計算文本情感傾向值,從而得到類標簽.
2)在傳統Stacking集成算法的基礎上進行改進.改進基學習器與元學習器的輸入用以提高分類器的準確度.
3)將基于文本規則的情感分析方法與Stacking算法融合,得到新的文本情感分類模型Stacking-I.
4)對比本文方法各種配置的分類情況,得出對于評論文本情感分析的最佳Stacking-I配置.
為驗證該方法的效果,研究將在不同的網絡評論文本上進行實驗.
2 相關工作
文本情感分析的主要工作就是提取文本中的特征,并利用該文本特征來分析文本的情感.
基于文本規則的情感分析方法在文本情感分析領域發揮著重要的作用.該方法需要首先通過對文本集的分析建立情感詞典,再將文本中的詞語與情感詞典中的詞語進行對照獲得詞語極性,根據中文文本規則等建立計算整體文本情感傾向值的數學模型,最終獲得該文本的情感極性.朱建平等人[1]根據文本中正向詞和負向詞的數量來決定文本的情感詞的極性;肖江等人[2]將情感詞、否定詞、程度副詞、縮寫詞和表情符號賦予權值,并用加權求和的方式來計算文本情感傾向值,得到文本的情感極性.基于文本規則的情感分析方法過于依賴情感詞典,對未登錄詞的情感傾向分析有較大的偏差,因此在跨領域情感分析中效果不理想.
基于機器學習的情感分析方法通過提取可能影響文本情感分析的特征值,利用監督學習的方法,采用傳統機器學習或深度學習算法,將文本進行情感分類,最終得到情感分析結果.2002年Pang等人[3]初次將機器學習應用在情感分類問題上;Kouloumis等人[4]將表情和縮寫加入情感分析的特征當中;李明等人[5]提出了一種基于SVM結合PMI的細粒度商品評論情感分析方法.深度學習也同樣被應用在文本情感分析當中:譚旭等人[6]通過構造中文文本詞向量解析模型和RAE深度學習模型來實現文本信息的高層特征提取和情感分類;周錦峰等人[7]提出一種多窗口多池化層的卷積神經網絡模型.傳統機器學習方法對于不同的文本分析各有優缺點,且其得到的情感分析效果不能達到預期,因此研究者們提出了融合多種機器學習的方法.高歡等人[8]結合情感詞典構造文本特征,利用邏輯回歸、Light GBM等機器學習方法進行在線評論情感分類;Liu P等人[9]將條件隨機場與最大熵模型相結合進行情感分析;黃偉等人[10]利用了一種基于多個分類器投票集成的半監督方法進行情感分類;李壽山等人[11]采用一種基于Stacking集成分類方法來進行中文文本情感分析研究.基于機器學習的方法過于依賴訓練集的設定,其缺少對上下文的分析,且對于特征的選取和拓展不夠靈活,而深度學習適合處理大量數據,對于處理網絡評論這種的數據量較少的數據集表現不能達到預期.
Stacking集成算法是指用一個模型來組合其他各個模型,具有很強的泛化能力,可以綜合各個傳統機器學習的優點,且對時間、空間復雜度的影響較少.而基于學習器和元學習器的算法選擇即Stacking算法的配置則也是研究者們的一個重要課題.Kai等人[12]實證表明多響應線性回歸MLR作為元學習器可以很好的學習效果;GzVeroski等人[13]的研究中用多響應模型樹代替多響應線性回歸來提高分類性能;Webb等人[14]則將AdaBoost算法作為Stacking的基分類器.其他研究者基于Stacking也做了相應的研究[15-18].然而對于不同的領域,最優的Stacking配置并不相同,因而需要對文本情感分析領域的最優Stacking配置進行探索.
本文針對于上述所提兩種方法的優缺點,提出了一種融合改進Stacking與規則的中文文本情感分析方法,該方法不僅利用了基于文本規則方法的靈活性和對上下文的考量等優點,還利用了Stacking算法的泛化能力和集合多種單一的機器學習算法優點等優勢以提高對網絡評論文本的情感分析準確率.
3 算法基本實現
圖1為本文提出的基于融合改進Stacking與規則的中文文本情感分析框架圖,該模型分為以下4個部分:
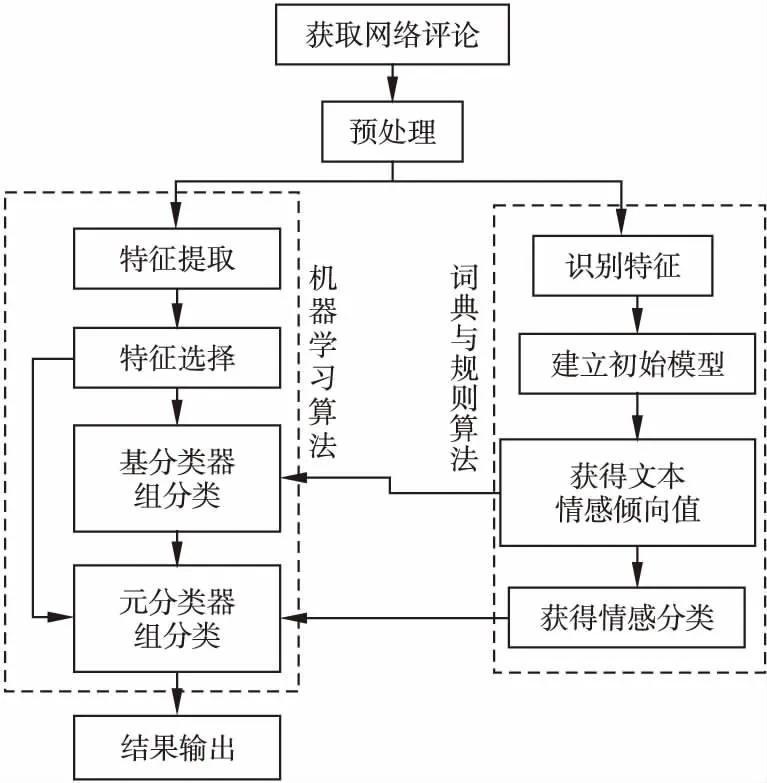
圖1 融合改進Stacking與規則的方法總框架Fig.1 Framework of the model based on the integration of improved Stacking and text rule
1)網絡評論文本預處理.該部分的主要任務就是將從網絡中爬取的評論文本進行分詞以及去停用詞等預處理,使得文本可以更好的在所提出的模型中進行處理分類.
2)基于文本規則的情感分析.該部分的主要內容為構建情感詞典,利用情感詞典將文本中的特征與之對照,根據所建立的情感分析模型計算評論文本情感傾向值,并根據文本情感傾向值進行文本情感分類.該部分所得到的文本情感傾向值與分類結果放入改進的Stacking算法中輔助該算法進行最終的情感分類.
3)基于改進Stacking的情感分析.該部分利用文本中提取并選擇的特征將原有的Stacking算法改進,利用Stacking算法的泛化優點來對網絡評論文本進行情感分析
4)將兩種方法融合得到最終的文本情感傾向.將基于文本規則的方法的分析結果放入基于改進Stacking的方法中,從而得到文本情感分析的結果.
下文將從以上4個部分進行深入介紹.
3.1 預處理
通常文本預處理包括去重、降噪、分詞和去停用詞等過程.對于網絡評論文本,其中的#話題#、@用戶和URL等不包含用戶的情感信息,應在分詞前將其去掉.由于網絡評論文本有不規范等特征,文本集中可能出現亂碼、錯字以及重復文本等情況,應將文本進行規范和篩選.本文使用的分詞系統為Jieba分詞系統,將文本進行分詞后,再通過自建停用詞表,將文本進行去停用詞處理.
3.2 基于文本規則的情感分析
基于文本規則的情感分析方法首先建立針對文本集的詞典,該詞典包括情感詞典、否定詞典、程度副詞詞典等一系列可以影響情感分析的詞典.再將文本中的詞與詞典中的詞進行對照,獲取其權值.通過詞語權重值以及語句規則來建立情感分析模型,并利用模型對每個文本進行情感分析.下面我們將從基于文本規則的兩個重要部分進行介紹.
3.2.1 構建詞典
由于不同的詞語對文本的情感傾向影響程度不同,本文采用投票制,通過采納100名志愿者對詞匯的理解,構建了情感詞典、否定詞典、程度副詞典、詞組詞典、連詞詞典、標點表六個詞典,并給詞典中的每個詞匯賦予權值,下面對每一個詞典的具體內容進行詳細介紹.
1)情感詞典
本文的情感詞典分為兩個部分,一個是正向情感詞典,另一個是負向情感詞典.而構建的情感詞典包括:HowNet中文情感詞典、網絡情感詞典以及通過分析語料自建的領域情感詞典.其中網絡情感詞典通過百度搜索引擎的網絡新詞中獲取,經過去重和權值賦予等過程構建出如表1和表2所示的情感詞典,其中包含負向情感詞匯4450個,和正向情感詞匯4554個.

表1 部分正向情感詞Table 1 Part of the positive emotion words

表2 部分負向情感詞Table 2 Part of the negative emotion words
2)否定詞典
句子中否定詞的出現可以改變句子的情感極性,因此分清句子情感極性傾向,則要將句子中的否定詞考慮在內,因此我們收集了一些可以影響句子極性的否定詞并構造如表3中的否定詞典,本文將用到24個否定詞.

表3 部分否定詞Table 3 Part of the denial
3)程度副詞典
程度副詞修飾情感詞,并對文本情感極性有所影響,其影響有時是增強有時是減弱,而每個詞匯對文本的情感增強或減弱的程度不同,因此本文將根據每個程度副詞對情感極性的影響,賦予了對應的權重.本文將用到98個程度副詞,表4列出了部分程度副詞.

表4 部分程度副詞Table 4 Part of the adverb
4)詞組詞典
由于行文的復雜性,中文文本存在很多不包含情感詞卻依舊含有情感極性的詞組,我們通過總結語料,得到了正向以及負向詞組詞典,將該詞組賦予權值,其中正數為正向,負數為負向,得到了本文所需要的詞組詞典.該詞典中包括37個詞組,表5列出部分詞組及其權值.

表5 部分詞組Table 5 Part of the phrases
5)連詞詞典
中文文本中經常為了語義的連貫性而出現連詞,一部分的連詞同樣可以突顯出該文本中所跟分句的情感極性,因此文本建立連詞詞典,并為其賦權.表6列出了部分連詞及其權重.

表6 部分連詞Table 6 Part of the conjunction
6)標點表
除以上詞表可以影響文本情感極性外,文本中出現的表情符號有時也會影響文本的情感分析結果,例如“??”等符號通常代表文本對某件事情的消極態度的增強.因此文本中還根據標點規定了各個標點的權值用以情感分析.部分符號以及對應權值如表7所示.

表7 部分標點符號Table 7 Part of the punctuation
3.2.2 建立方法模型
基于文本規則的方法主要是要建立方法模型用于計算該文本的情感傾向值,通過計算得到的文本傾向值來確定該文本的情感極性.
本文首先將微博的評論文本,通過標點符號進行分句,并對單個分句進行情感分析.而分句中又存在影響該分句情感傾向的詞組,該詞組一般是由情感詞、程度副詞和否定詞組成,因此將分句中的詞語與情感詞典中的詞語進行比較,獲得其相對應的權值,每一個情感詞作為該分句中的一個情感詞組.計算該情感詞組的情感傾向值SW如式(1)所示:
SW=WvWdS
(1)
其中SW為該情感詞組的情感傾向值,Wv為初始為1的情感詞前后3個窗口出現的程度副詞的權重,Wd為情感詞前后3個窗口出現的否定詞的權重,其初始為1,S為該情感詞的權值.
分句中除情感詞組會影響該分句的情感傾向值外,其中的連詞、標點以及某些動詞名詞詞組也會影響情感傾向值,于是計算該分句的情感傾向Ss如式(2)所示:
SS=WpWc(∑Swi+Wph)
(2)
其中Wp為該分句中出現標點的權重,Wc為該分句中出現連詞的權重,Swi為該分句中第i個情感詞組的情感傾向值,Wph該分句中出現動名詞詞組的權重.
除以上情況外,分句的位置也會對評論文本的情感傾向產生影響,其中首句和尾句的情感傾向對整個評論文本的傾向影響較大,因此分句的情感傾向值可再通過式(3)進行處理,得到加權的第i個分句情感傾向值Si:
Si=WdSsi
(3)
其中Wd為句子權重,當該分句為首句或尾句時,其值為2;當該句在其他位置時,其值為1.而Ssi則為之前計算的該分句的情感傾向值.
根據以上的計算,整個評論文本的情感傾向值如式(4)所示:
(4)
其中Score為該評論文本的情感傾向值,Si為第i個分句的情感傾向值,n為整個評論的分句數.
根據情感傾向值的計算,本文通過對情感傾向值的分析,可以確定該評論文本的情感極性,如式(5)所示:
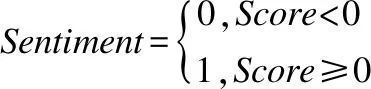
(5)
其中,當sentiment為0時,該評論的情感為負向的,反之,評論的情感為正向的.
3.3 基于改進Stacking算法
3.3.1 Stacking集成算法
集成算法的基本思想就是集成分類器.Stacking算法的集成方式為:集成不同基分類器,再將基分類器的輸出作為第2層元分類器的輸入進行再次分類.該分類方法可以中和傳統機器學習方法的優缺,其分類結果比其集成的任意單一分類器的分類結果都要好,因此本文考慮在Stacking集成分類方法的基礎上進行改良,從而有效對網絡評論文本進行情感分析.
傳統的Stacking集成方法中,將基分類器分類后的類標簽,即本文中的情感正向和負向作為元分類器的輸入.Wolpert[19]研究表明新數據的屬性表示對Stacking集成的泛化性能影響很大,因此本文將類標簽用類概率替代.類概率不僅僅包含了基分類器的預測結果,還包含了基分類器的置信程度和各個基分類器之間的差異性等信息,因此使其分類結果更能結合基分類器的優缺點,提高泛化能力.傳統Stacking算法框架如圖2所示.
圖2中ti為n個文本中每個網絡評論文本經過向量化處理后的表示,m為基分類器的個數,fm為基分類器對應的機器學習算法,且其互不相同,ti′為文本經過基分類器分類后所得的分類概率向量,其中Pij+為第i個評論文本通過第j個基分類器分類后結果為正向的概率,Pij-為第i個評論文本通過第j個基分類器分類后結果為負向的概率,F則為元分類器的機器學習算法.
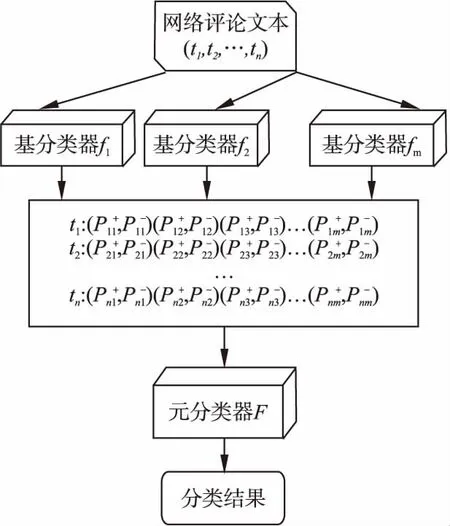
圖2 Stacking集成算法Fig.2 Stacking integration algorithm
3.3.2 改進Stacking集成算法
然而只在元分類器層輸入基分類器的分類類概率,效果雖有提高但并不能滿足本文要求的準確率,其原因為分類后的類概率所攜帶的原始數據信息不足,導致元分類器的分類結果不理想.因此本文將元分類器的輸入進行改進,輸入向量在類概率的基礎上添加原始數據經過特征提取等工作所得的特征向量以提高整個集成分類器的分類準確率,具體結構如圖3所示.本文使用CBOW實現詞語向量化,并通過χ檢驗進行特征提取.其中xiq為n個評論文本內第i個評論文本進行向量化后的第q個特征值.
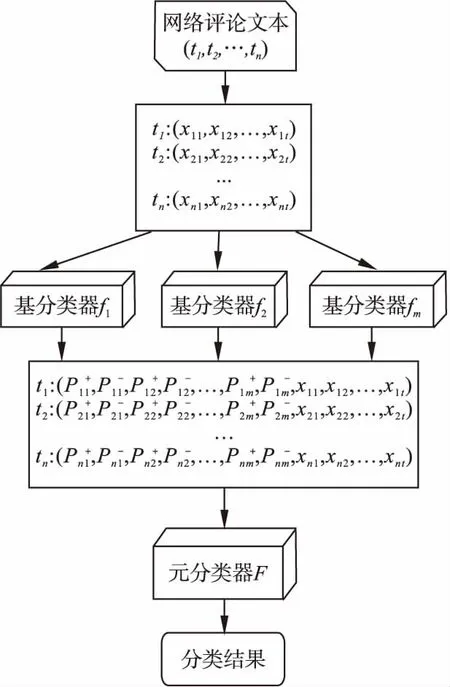
圖3 改進Stacking算法Fig.3 Improved Stacking algorithm
此外,傳統的Stacking算法對于基分類器與元分類器算法的選擇只局限于傳統機器學習方法.隨著機器學習的發展,更多的集成機器學習算法出現,其分類是性能比傳統的機器學習好.已知Stacking算法的準確率一定比其集成的機器學習方法準確率高,因此本文將其他集成算法以及深度學習學習算法加入基分類器與元分類器算法的選擇中,進而提高其分類準確率.
3.4 融合集成與情感詞典
前文已經提到,文本規則法和機器學習法各有優缺,本文將結合兩種方法,中和兩種方法的優缺,得到一個新的文本情感分析模型.該模型將基于文本規則方法的輸出,作為改進Stacking算法的輸入,該輸入不僅僅局限于類標簽,還包括文本情感傾向值,其輸入不僅作為基分類器的一部分,還將影響元分類器.
研究者們在之前的研究中,已經將基于文本規則的方法與基于機器學習的方法進行了簡單的融合,即已經出現將基于文本規則方法分析所得的情感傾向值作為傳統機器學習輸入特征的一部分,以此來彌補傳統機器學習方法未考慮上下文關系的缺陷,提高文本情感分析的準確率.與之不同的是,本文將基于文本規則方法所得文本傾向值進行歸一化處理后再放入分類器中,以此來統一輸入向量中的特征量,其具體的歸一化處理如式(6)所示:
score′=(score-s.min)/(s.max-s.min)
(6)
其中,score為該文本計算所得的情感傾向值,s.min為最小情感傾向值,s.max為最大情感傾向值.
此外,Stacking集成算法的基本思想就是融合各種分類方法,并將這些分類方法所得結果放入第2層分類器中,以此來解決各分類方法優缺不一的情況.
對于文本情感分析,分類方法則不局限于各種機器學習方法,還包括文本規則情感分析法,因此本文將基于文本規則的情感分析方法也作為Stacking集成算法中的一個基分類器,將基于文本規則的情感分析方法所得的類標簽作為元分類器輸入的一部分進行再次分類.具體本文模型如圖4所示,其中Scorei為基于文本規則方法所得的歸一化后的文本情感傾向值,sentimenti為該方法最后得到的類標簽.
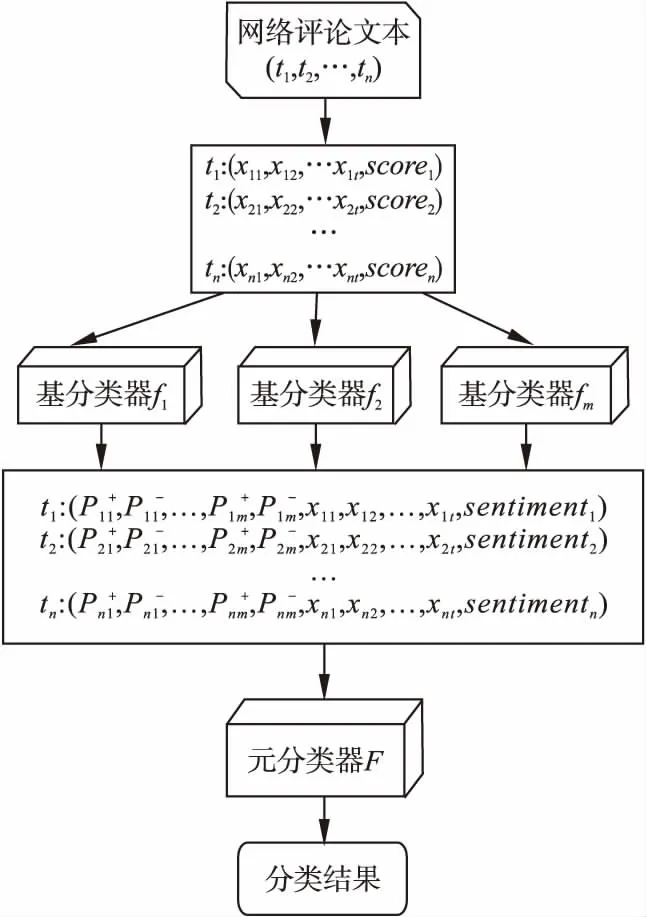
圖4 融合兩種方法框架Fig.4 Framework for merging the two approaches
4 實 驗
該節將分析本文提出的算法Stacking-I在具體的網絡文本評論情感分析中的表現.
4.1 實驗設置
本文將從網絡上爬取某外賣app評論,通過去重降噪等處理,人工標注得到內有2500、4000、5000條數據的3組數據集,其中正負向評論比為1∶1.在研究者們的研究中表明Stacking集成算法中,訓練集與測試集的比例為4∶1時的效果最好.因此本文在2000條數據集A中設置2000條作為訓練集,500條作為測試集;在4000條數據集B中設置3200條作為訓練集,800條作為測試集;在5000條數據集C中設置4000條作為訓練集,1000條作為測試集.其中每個訓練集與測試集正負向數據分布平均.
本次實驗結果使用準確率作為評估值,且通過Python語言實現,部分傳統機器學習方法應用Scikit-learn框架實現,深度學習方法應用keras框架實現.
4.2 實驗驗證
4.2.1 對比實驗
實驗結果如表8所示.本文將基于融合改進Stacking與規則的文本情感分析方法(Stacking-I)與傳統機器學習、其他集成算法以及深度學習算法進行比較,意在證實本文提出的算法模型stacking-I可以有效提高文本情感分類的準確率.
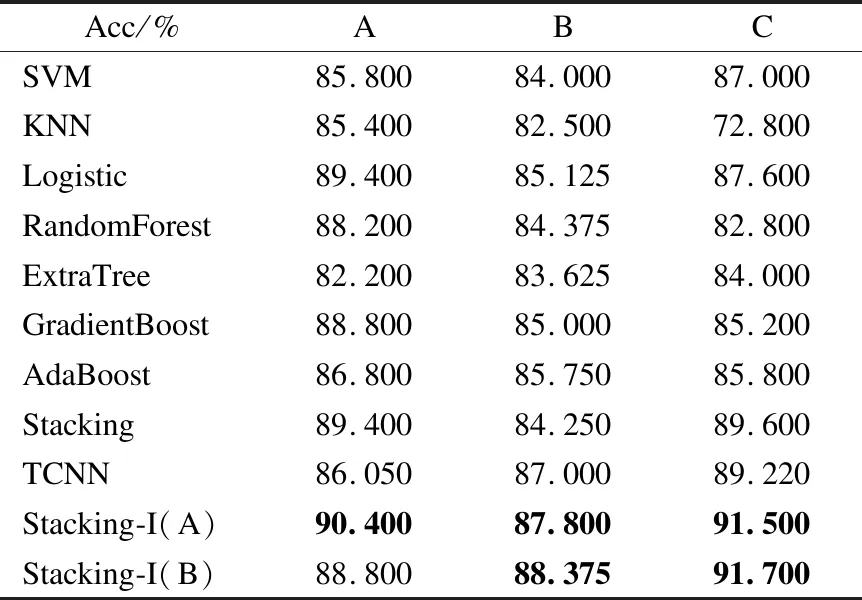
表8 與各類方法的比較Table 8 Comparison with traditional machine learning methods
表8中TCNN中有3個中間層,每個中間層有16個人隱藏單元;Stacking-I(A)的配置為:AdaBoost、RandomForest、Bagging和GradientBoosting作為基分類器,Logistic作為元分類器;Stacking-I(B)的配置為:RandomForest、ExtraTree、KNN和TCNN為基分類器,Logistic作為元分類器.由實驗數據可以看出,本文提出的基于融合改進Stacking與規則的中文文本情感分析方法(Stacking-I)比傳統機器學習模型對該數據集的情感分析準確率有明顯提高,對比其他的集成算法及深度學習算法,Stacking-I也有很大的提高.
針對文本數據集A,傳統機器學習算法中,準確率最高可以到89.4%,而Stacking-I(A)所得分類準確率比其高1%;Stacking-I(A)與傳統Stacking算法相比提高了1%;在其他集成算法中準確率最高為88.8%,Stacking-I(A)比其高1.6%;與深度學習TCNN相比,Stacking-I比其高3.6%.
對于數據B,傳統機器學習算法中,準確率最高可以到85.125%,而Stacking-I(A)和Stacking-I(B)比該算法所得分類準確率提高2.2%和2.7%;Stacking-I(A)和Stacking-I(B)與傳統Stacking算法相比提高了3.6%和4.1%;在其他集成算法中,AdaBoost算法的準確率最高為85.75%,Stacking-I(A)和Stacking-I(B)分別比其高1.5%和2.0%;與深度學習TCNN相比,Stacking-I(A)和Stacking-I(B)分別比其高0.8%和1.3%.
對于數據C,傳統機器學習算法中,準確率最高可以到87.6%,而Stacking-I(A)和Stacking-I(B)比該算法所得分類準確率高3.7%和3.9%;Stacking-I(A)和Stacking-I(B)與傳統Stacking算法相比分別提高了2%和2.2%;在其他集成算法中,AdaBoost準確率最高為85.8%,Stacking-I(A)和Stacking-I(B)分別比其高5.5%和5.7%;與深度學習TCNN相比,Stacking-I(A)和Stacking-I(B)分別比其高2.3%和2.5%.
通過對比可以看出,融合改進Stacking與規則的中文文本情感分析方法(Stacking-I)有更好的性能,且比傳統機器學習方法、其他集成算法和深度學習方法的準確率都要高,有效提高了文本情感分析的準確率.
4.2.2 獲取最優配置
本部分將從Stacking算法的配置討論,通過對時間復雜度與準確率兩方面進行考慮,選出最適合本文數據集的一組Stacking配置.
1)元分類器
研究者們對于Stacking算法配置的研究中,線性分類器作為元分類器時,準確率較高,本文固定基分類器,將Logistic、TCNN、BiLSTM作為元分類器在3組數據上實驗,其中BiLSTM為雙向單層LSTM,得到實驗結果如表9所示.可以看出,當Logistic作為元分類器時的文本情感分類效果最優.
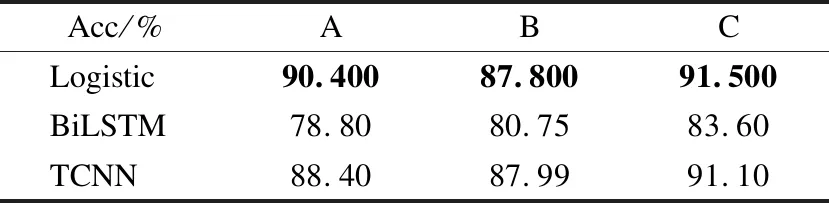
表9 不同元分類器對比Table 9 Comparison with different meta-classifiers
2)基分類器
對于基分類器的選擇,本文將從兩個方面進行探究.
對于基分類器的數量問題,若分類器的數量過多會導致算法的時間復雜度過大.因此本文通過控制基分類器數量在數據集C上進行全排列組合實驗,獲得了圖5,從而分析得到最優的分類器數量.由圖可見,基分類器數量為4時效果最優.
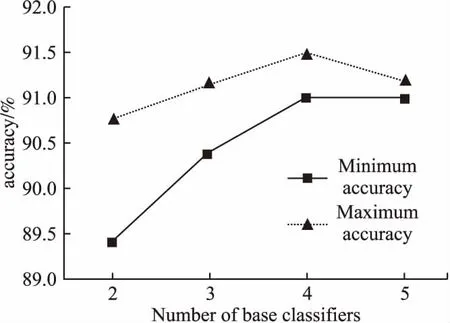
圖5 基分類器個數與分類準確率的關系Fig.5 Relationship between the number of base classifiers and classification accuracy
對于基分類器選擇的問題,本文經過大量的實驗對比,將基分類器的組成分為3組:基分類器只包含傳統機器學習方法和集成方法,基分類器包含一種深度學習方法以及基分類器包含兩種深度學習方法.最終在3大組中實驗得到了3種準確率組內最高Stacking-I基分類器配置,分別為AdaBoost、RandomForest、Bagging和GradientBoosting的組合(Stacking-I(A)),RandomForest、ExtraTree、KNN和TCNN的組合(Stacking-I(B))以及RandomForest、ExtraTree、BILSTM和TCNN的組合(Stacking-I(C)),其具體文本情感分類準確率如表10所示.
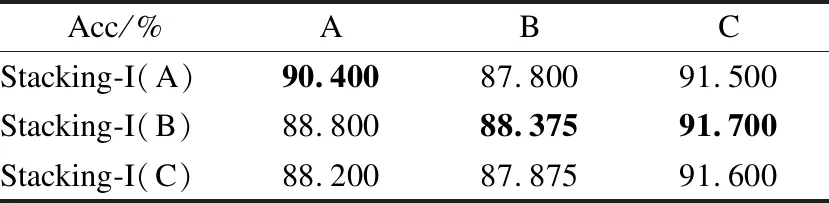
表10 不同基分類器對比Table 10 Comparison with different base-classifiers
對于數據量少的數據集,Stacking-I(A)的配置在文本分類時表現更好,而當數據量變大時,Stacking-I(B)的配置在文本分類時表現更好.Stacking-I(C)的表現與Stacking-I(B)的相差不多,但因為集成了兩個深度學習算法,其時間復雜度相較于Stacking-I(B)更大.因此在數據量小時,Stacking-I(A)的配置,即AdaBoost、RandomForest、Bagging和GradientBoosting作為基分類器的效果更好;而當數據量大時,Stacking-I(B)的配置,即RandomForest、ExtraTree、KNN和TCNN作為基分類器的效果更好.
4.2.3 分析算法時間復雜度
該部分將從算法的時間復雜度上進行分析,將本文所提算法Stacking-I的兩種不同配置與其他機器學習算法、深度學習算法TCNN在數據集C上的運行時間對比,其結果如表11所示.

表11 算法運行時間對比Table 11 Comparison of algorithm′s running time
通過對比可知,本文所提出的Stacking-I(A)和Stacking-I(A)的時間復雜度比傳統機器學習算法、集成算法要高,且Stacking-I(A)其比運行時間最長的GrandiantBoost算法運行時間增加了60%.而Stacking-I(A)與深度學習TCNN相比,其運行時間更短,運行時間縮短了55.7%.Stacking-I(B)與深度學習TCNN相比,其運行增加了25%.
因此Stacking-I(A)的時間復雜度雖然與其他機器學習方法相比有所增加,但其復雜度遠遠低于深度學習TCNN算法的時間復雜度,且其分類準確率與其他算法相比表現更加優秀.而 Stacking-I(B)雖在時間復雜度上有所增加,但其分類準確率遠遠高于其他算法,因此本文認為Stacking-I算法在對時間復雜度影響較小的前提下,提高了文本情感分析的準確率.
以上實驗證明了本文提出的融合改進Stacking與規則的文本情感分析方法Stacking-I相較于基于傳統機器學習、集成學習以及深度學習的文本情感分析方法有著更高的分類準確率,最高可達91.70%.且通過大量實驗,在不同數據量的情況下,本文得出了最佳的Stacking-I的配置.
5 總 結
本文提出了一種融合改進Stacking與規則的中文文本情感分析方法Stacking-I:
1)建立基于文本規則的方法模型,計算文本情感傾向值,從而得到類標簽.
2)在Stacking集成算法的基礎上進行改進,改進元學習器的輸入用以提高分類器的準確度.
3)將基于文本規則的情感分析方法與Stacking算法融合.
4)對比該模型各種配置的分類情況,得出針對不同數據量的最佳文本情感分析Stacking-I配置.
通過實驗可知,相比于傳統機器學習方法、其他集成算法以及深度學習方法,本文所提模型Stacking-I在情感分析在對時間復雜度影響不大的情況下,其準確率有了明顯地提高,最高可達91.7%.并且本文確定了當,Logistic作為元分類器時效果最佳,而對于基分類器的選擇,當數據量小時其配置為:AdaBoost、RandomForest、Bagging和GradientBoosting作為基分類器效果最佳,當數據量相對較大時,RandomForest、ExtraTree、KNN和TCNN作為基分類器的效果最好.
Stacking-I算法彌補了基于文本規則和基于機器學習方法的文本情感分析的不足,融合了兩方法的優點,并在對時間復雜度影響不大的情況下,提高了文本情感分析的泛化能力和準確率.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
