低復雜度HEVC幀內編碼快速劃分算法
2021-07-08 09:06:38周帥燃
小型微型計算機系統 2021年7期
關鍵詞:深度
周帥燃,楊 靜
(上海海事大學 信息工程學院,上海 201306)
1 引 言
與之前的H.264/高級視頻編碼(AVC)來說,高效視頻編碼(HEVC)標準[1]在相似的視頻質量下節省了大約50%的比特率.這主要是因為在HEVC當中引用了新的四叉樹劃分對圖像結構進行劃分成樹單元(Coding Tree Unit,CTU),其中最大編碼單元(Largest Coding Unit,LCU)尺寸為64×64,最小編碼單元(Shortest Coding Unit,SCU)尺寸為8×8.雖然這樣使編碼劃分更加靈活,預測模式更加準確,但是同樣也極大增加了編碼復雜度,Correa G等人[2]實驗得到HEVC的編碼時間是AVC編碼的253%,這顯然不可能順利應用在現實生活中,因此,有必要將HEVC的編碼復雜度降低到可以接受的范圍,并且其編碼性能的損失可以忽略不計.
近些年來,在降低HEVC編碼復雜度的研究中已經看到了巨大的進步,出現了各種有效的方法.盡管這些方法大都是運用在幀間預測模式上,但是也有必要降低HEVC幀內編碼復雜度,毋笑蓉等人[3]提出了一種基于機器學習的隨機森林分類算法,有效提高了幀內編碼劃分速度.朱威等人[4]提出一種結合紋理信息和方向信息特征,分析編碼單元的紋理劃分特征與最佳編碼單元之間的相關性,來判斷是否提前終止劃分.易清明等人[5]提取編碼單元紋理特征并線下訓練支持向量機模型,從而對編碼深度進行快速決策,并根據CU紋理復雜度,對紋理簡單的CU提前終止劃分,對紋理復雜的CU直接進行劃分[6].Yao-Dong T等人[7]通過對當前CU以及進一步劃分的四個子CU的率失真代價(RDO)進行對比,來決定當前CU是否劃分.黃勝等人[8]采用差分矩陣來表示紋理的復雜度,采用子塊相似度來對CU是否劃分進行判決.Song Y等人[9]設計了一種離散全變差的像素插值求解計算,利用像素之間的差值得到的全變差與設定好的閾值相比較,來確定編碼單元是否劃分.
上述算法中紋理復雜度雖然被大量使用,但根據不同使用場景,紋理特征仍然有被挖掘利用的潛能.在編碼率失真性能不受到影響的前提下降低編碼復雜度,本文結合傳統方法和深度學習提出了一種應用在編碼單元決策的算法.針對64×64編碼單元,通過綜合分析紋理復雜度和量化參數,利用閾值來決策編碼單元是否劃分;而針對32×32和16×16紋理復雜度較高的編碼單元,不能簡單通過閾值來準確預測是否提前劃分,故設計一種CNN結構提前終止劃分(訓練數據庫來源于Li T等人研究[10]).
2 編碼深度快速決策
本節從3個部分詳細描述了編碼單元快速劃分算法,首先針對大小為64×64的編碼單元提出了基于閾值紋理分類的模型.其次針對32×32和16×16的編碼單元設計一種CNN網絡.最后對編碼單元快速劃分算法進行了總結.
2.1 閾值紋理分類
針對64×64的編碼單元,本文利用相鄰均方誤差來測量它的紋理復雜度,并用大量實驗綜合考慮閾值與量化參數(QP)和CU深度的關系,建立閾值與64×64編碼單元之間的關系.
標準差(SD)是常用度量紋理復雜度的指標之一,它能準確的反映出全局的紋理復雜度,但是具有較弱的局部復雜性反映能力,而相鄰均方誤差(NMSE)就能彌補這種缺陷,因此本文選取NMSE作為圖像紋理復雜度,NMSE計算表達式如下:
(1)
(2)
本文通過大量的實驗發現閾值與CU劃分深度、QP和紋理復雜度高度相關,圖1顯示了在QP=32的情況下4個序列上的最佳CU分布(PeopleOnStreet,BasketballDrill,RaceHorses and Cactus).由圖1可以看出,5種大小的CU所占比例都不超過40%,因此在閾值分析的時候需要考慮CU的大小.圖2是BasketballDrillText的第1幀CU在QP(22,27,32,37)的分布.從圖2被選中的灰色方格可以看出隨著QP的不斷減小,越來越多高深度的CU顯現出來,這是因為在QP較小的時候,CTU往往被劃分為較小尺寸的CU,主要是為了避免較大的失真度.因此可以看出QP也是閾值建模的重要因素.通過以上分析,并根據大量實驗數據得出閾值與QP之間的關系如圖3所示.

圖1 序列PeopleOnstreet、Catus、Johnny和ChinaSpeed CU分布圖Fig.1 Distribution of the sequence PeopleOnstreet,Catus,Johnny and ChinaSpeed CU

圖2 BasketballDrillText第1幀CTU分布圖Fig.2 BasketballDrillText CTU distribution of the first frame

圖3 QP與閾值之間的關系Fig.3 Relationship between QP and threshold
本文選取在QP=22時閾值為1.7,QP=27時閾值為2.2,QP=32時閾值為2.8,QP=37時閾值為3.6.即將等式(1)中NMSE的值與閾值作比較,若NMSE的值大于閾值,則對64×64的編碼單元直接劃分,相反則提前終止劃分.
2.2 基于CNN的CU分類器
深度學習在實踐過程中往往需要大量的學習樣本,并對每個學習樣本標記類別,本文選取學者李天一[10]建立的HEVC幀內預測編碼數單元數據庫(CTU Partion of Intra Mode HEVC,CPIH)為訓練樣本,以防測試序列與訓練樣本存在相關性.
CPIH數據庫是以高分辨拍攝的2000張分辨率為4928×3264原始圖像集,此外每組圖像集又被下采樣分辨率為2880×1920,1536×1024,768×512的圖像集,并且每一幀都由原始HM編碼器進行編碼,不僅保證了足夠多變的訓練數據,也提高CTU預測劃分精準度.
本文設計分離的CNN結構提高劃分效率.首先將CU深度引入內核大小,使內核大小與CU大小一致,以避免部分紋理細節損失[11].其次將QP引入損失函數,以提高樣本的擬合度.具體的CNN結構如圖4所示.
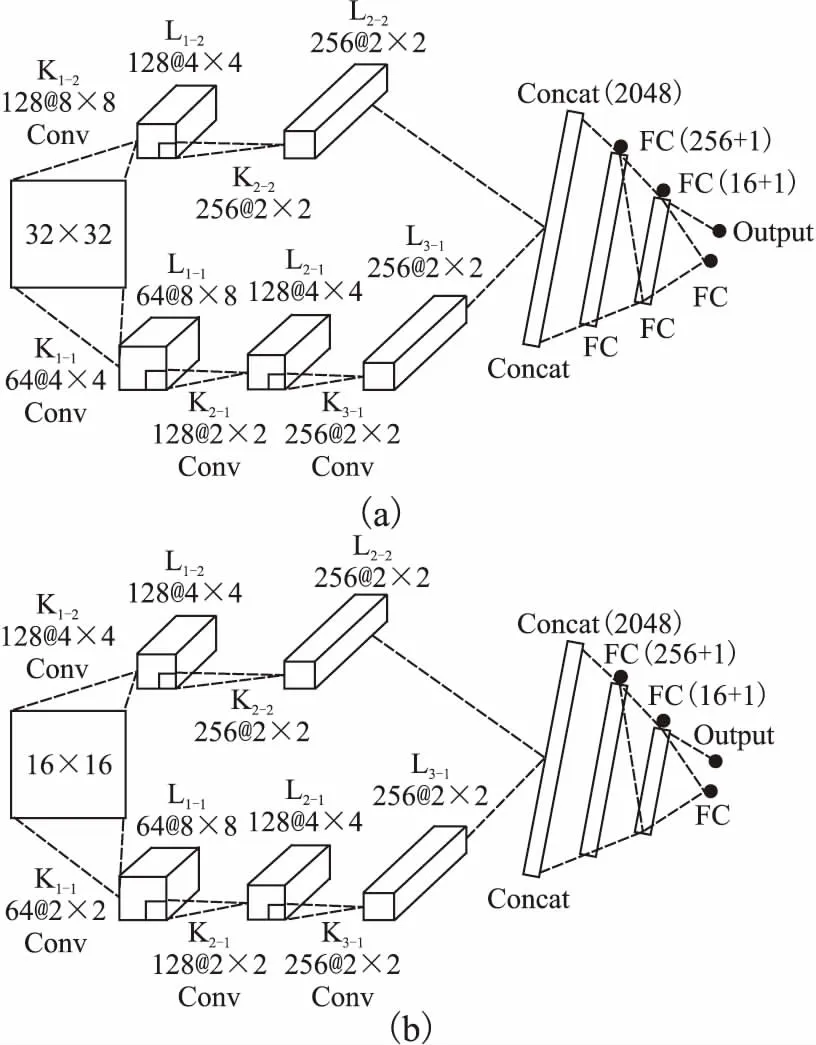
圖4 CTU 32×32和16×16的CNN結構Fig.4 CNN structure for CTU 32×32 and 16×16
輸入層(Input Layer):CNN模型輸入是不同CU大小的矩陣,CU的輸入大小(32×32,16×16),對應著每個CU的亮度.
卷積層(Convolution Layer):針對32×32CTU,并行運用8×8和4×4兩個內核,8×8內核可以在32×32 CTU中有效地提取紋理特征的4個8×8子CU,4×4內核可以增強紋理細節并避免填充.針對16×16CTU,并行運用4×4和2×2兩個內核.對于非重疊卷積,本文將內核步幅統一設置為2×2,在第一層卷積之后,通過與非卷積重疊的2×2內核進行卷積來進行操作,直至最后特征圖大小為2×2.
歸并層(Concatenation Layer):將卷積層所產生的兩組分別具有256個2×2特征圖串聯在一起,然后通過串聯層轉換為向量.歸并后的特征圖由不同來源組合而成,有助于獲得全局和局部特征.
全連接層(Full Connection Layer):歸并后的級聯向量要流經三個全連接層,包括兩個隱藏層和一個輸出層,在第二層全連接層和輸出層之間,在CNN訓練過程當中,會以50%的概率隨機丟失,避免過擬合,提高網絡泛化能力.
由于ReLU具有很快的收斂速度,所有卷積層和隱藏的全連接層都是有用修正線性單元(rectified linear units,ReLU),并且根據輸出結果為劃分或者不劃分,輸出層采用S型(Sigmod)函數進行激活,使輸出層都位于(0,1)之間.
2.3 CU劃分算法總結
本節總結了整體CU劃分過程,針對64×64的編碼單元,首先通過計算紋理復雜度與我們經驗所得的閾值進行比較判斷是否劃分,如果小于則不劃分,大于則進行下一步判
斷,對其他不同大小的CTU使用CNN分類器來決定是否劃分.整個算法流程如圖5所示.

圖5 算法總流程圖Fig.5 Overall flow chart of the algorithm
3 實驗結果與分析
本文提出的算法以HM16.5標準為基礎,所配置的文件是內部主文件,量化參數是22、27、32、37,測試序列是JCT-VC的推薦測試序列.結果分析的硬件是Intel Core i7-8700 CPU,3.2GHz主頻,16GB內存,Windows10 64操作系統的計算機進行的.本文選取編碼時間減少的百分比ΔTS、比特率變化百分比ΔBR和峰值信噪比變化ΔPSNR來衡量編碼性能和質量,計算公式如下所示:
(3)
(4)
ΔPSNR=PSNRprop-PSNRHM
(5)
式(3)中THM和Tprop分別代表原始算法編碼所需時間和所提出的算法需要的時間,式(4)中BRHM和BRprop分別代表原始編碼的比特率和所提算法的比特率,式(5)中PSNRHM和PSNRprop分別代表原始編碼的峰值信噪比和所提算法的峰值信噪比.
表1為本文算法與原始HM16.5算法之間的對比結果,由表可看出本文算法在編碼比特率僅增加2.15%和峰值信噪比(PSNR)損失0.11dB的狀況下,平均節省60.28%的幀內編碼時間.為了評估本文算法整體性能,本文還與其他兩種先進的算法進行比較,為了公平起見,使用相同的配置文件encoder intra main.cfg對16個標準測試序列進行編碼.表1中PartyScene 和BlowingBubbles等此類型測試序列紋理比較復雜,算法測試性能較差,主要原因是這種類型視頻序列在編碼過程中一般要遍歷到較深的編碼深度,視頻優化空間較小.總體來說,本文算法優化后的視頻序列在主觀視覺上與原始編碼后的效果基本無差別.
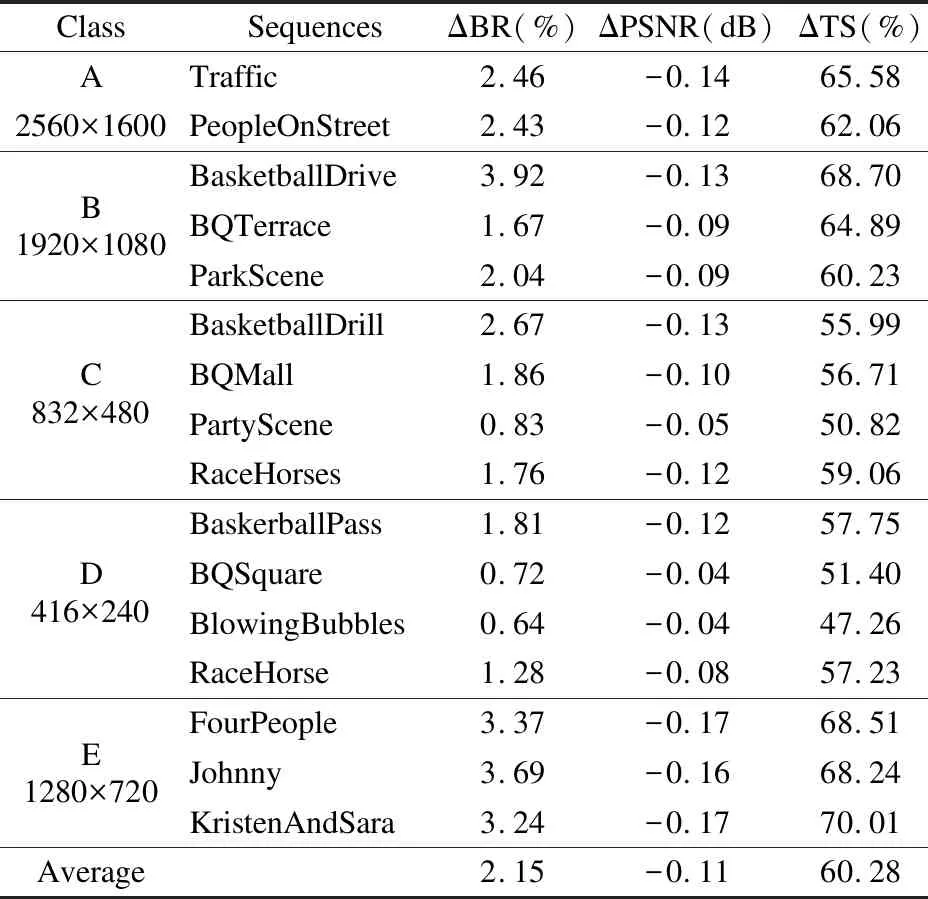
表1 本文算法實驗結果Table 1 Experimental results of this algorithm
表2顯示了本文算法與其他文獻在幀內快速編碼算法的性能對比.從表中可以看出,Li T[10]和Liu D[12]等人得出的編碼比特率分別增加2.38%和8.56%,均高于本文算法得到的比特率.而在PSNR損失方面,Li T[10]等人提出的算法與本
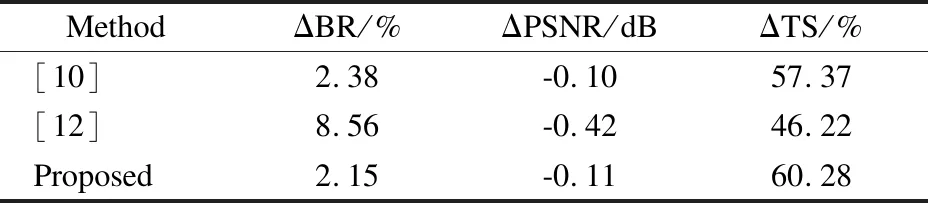
表2 與其他優秀算法比較Table 2 Comparison with other excellent algorithms
文算法相近,而Liu D[12]等人提出的算法遠高于本文算法得到的PSNR.最重要的是在編碼時間方面,本文算法分別比上述研究的算法快2.91%和14.06%.故可以看出本文算法整體編碼性能表現更加優秀.
4 結 論
為了降低HEVC幀內編碼復雜度,本文提出了一種基于紋理分類的深度卷積神經網絡(CNN)模型來對CTU的劃分進行預測.針對64×64的編碼單元,通過分析QP、紋理復雜度與CU深度之間的關系,大量進行數據實驗,建立閾值來快速對其進行劃分判斷.針對32×32和16×16編碼單元,本文設計了兩種不同的CNN結構來決斷它們是否劃分.實驗結果表明,本文算法與原始HM16.5算法相比,可節省60.28%的編碼時間,而在編碼比特率和峰值信噪比的損失方面可忽略不計.
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
