分布式強化學習算法在異常財務數(shù)據(jù)分析中的應用
2021-07-11 08:16:28董亞曉楊寒冰樊浩
電子設計工程 2021年13期
董亞曉,楊寒冰,樊浩
(西安航空職業(yè)技術學院,陜西西安 710089)
企業(yè)的財務狀況時刻發(fā)生著變化,面臨著內(nèi)部與外部的多重因素影響。如何迅速、精確地智能化分析企業(yè)的財務數(shù)據(jù),并準確判斷企業(yè)的運營情況,對于資本市場具有重要的實用價值[1-5]。
當前,隨著人工智能技術的發(fā)展,借助計算機技術構建智能化的財務數(shù)據(jù)分析模型,實現(xiàn)異常財務數(shù)據(jù)的識別與告警是“金融+計算機”融合趨勢的重要表現(xiàn)之一,但現(xiàn)有的分析算法存在效率低、準確率差的缺點。為了克服這些缺點,文中對分布式強化學習算法進行了研究。通過建立合理的財務數(shù)據(jù)分析指標體系,實現(xiàn)了對異常財務數(shù)據(jù)的識別[6-12]。
1 理論基礎與系統(tǒng)設計
1.1 分布式強化學習
強化學習的靈感來源于人類對動物學習行為的觀察,強化學習是一個典型的人工智能系統(tǒng)。該系統(tǒng)通過感知環(huán)境的變化,采取試探性動作。同時系統(tǒng)感知這一動作的反饋結果,以評判狀態(tài)的適應度。系統(tǒng)不斷重復這一反饋的過程,從而得到該環(huán)境下的最優(yōu)反應行為。傳統(tǒng)強化學習方法的學習載體通常只有一個,近年來,隨著計算機運算能力的增強,多個學習單元的分布式強化學習系統(tǒng)成為了研究的熱點之一。分布式強化學習系統(tǒng)包含:中央強化學習、獨立強化學習、群體強化學習等多個類別,文中使用了中央強化學習系統(tǒng)[13-16]。
圖1 給出了中央強化學習的體系結構圖。對于中央強化學習方法,可以用數(shù)學形式表述為:
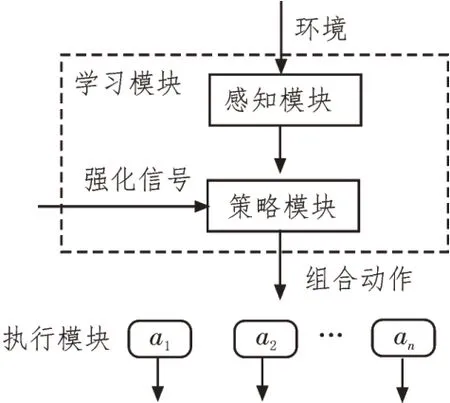
圖1 中央強化學習體系結構圖

其中,W代表RLC系統(tǒng)環(huán)境變量的集合,L是學習單元的集合,E是執(zhí)行單元的集合。W、E各自的定義形式如下:

在環(huán)境變量集合W的定義中,S是這一環(huán)境下所有可能出現(xiàn)的不同狀態(tài);Δ由若干個轉移向量組成,代表S中不同狀態(tài)的轉移概率;T是狀態(tài)環(huán)境的轉移映射集合,根據(jù)W中變量的定義,可以得到式(3)所示的關系:


W中包含了環(huán)境強化模塊R。該模塊通過<環(huán)境,動作>這樣的指令對,映射成如下所示的實數(shù)型激勵:

在RLC系統(tǒng)中,L是系統(tǒng)的學習單元,其定義如式(6)所示。

其中,X={x1,x2,…,xn}是學習單元輸入的集合,I是從環(huán)境狀態(tài)S到學習單元的映射,P是L的學習測率,根據(jù)這些定義可以得到式(7):

對于RLC系統(tǒng),其學習模塊并不具有主動學習的能力,因此可以被動執(zhí)行所得到的任務,通過相關的學習算法對策略模塊的參數(shù)進行優(yōu)化。
1.2 瞬時差分算法
對于強化系統(tǒng)而言,某一次對于系統(tǒng)的激勵是存在延遲的,所以系統(tǒng)的某一次響應可能是由于很早之前的某次動作引起。為了解決這種延遲問題,文中引入了瞬時差分(Temporal Difference,TD)算法,該算法可以在學習中同步之前狀態(tài)的經(jīng)驗。對于具體的TD 算法而言,首先定義了m+1 個不同時刻的狀態(tài)si,觀測數(shù)據(jù)以及每個狀態(tài)的預測值Vi:

在TD 算法的學習過程中,對于t時刻,無需等到獲得最終預測值y后再進行狀態(tài)修正,而在t+1 時刻即可進行更新,即:

在實現(xiàn)TD 算法時,需要引入神經(jīng)網(wǎng)絡結構對V(st)進行記錄。此時,TD 算法中的學習過程可以使用規(guī)則,如式(10)所示。

的修正需要依據(jù)“預測值-實際值”誤差的反向傳播,首先定義誤差函數(shù),如式(11)所示。

2 方法實現(xiàn)
2.1 指標體系建立
對企業(yè)的財務進行實時分析,及時發(fā)現(xiàn)異常財務數(shù)據(jù)并發(fā)出預警,是資本市場的需求之一。因此,在構建財務指標體系時需要遵循真實性、系統(tǒng)性、科學性與可行性等多個原則。所以,指標的選擇需要綜合反應公司的償債、營運、盈利、成長等多個方面。此外,企業(yè)的運行數(shù)據(jù)并非僅包含財務指標,非財務指標也可以反映公司的財務狀況。因此,在建立指標體系時也能夠適當引入。綜合以上討論,文中建立了圖2 所示的財務指標體系。
從圖2 中可以看出,指標體系包含財務類與非財務類指標。財務類指標除了可以反映企業(yè)的償債、營運、盈利、發(fā)展等能力之外,還能反映出企業(yè)的現(xiàn)金流量,此外,財務指標還引入了上市企業(yè)的每股指標。非財務類指標主要體現(xiàn)了企業(yè)的治理結構、股權結構以及財務的審計意見,可以從側面反映公司的財務狀況。

圖2 財務分析指標體系
數(shù)據(jù)測試與分析過程中,在算法的數(shù)據(jù)采集上,文中篩選了300 家公司2016~2019 年的真實財務數(shù)據(jù)。在這些數(shù)據(jù)中,2019 年包含ST 公司150 家,非ST公司150家,ST與非ST的比例為1∶1。對于每個企業(yè),這份數(shù)據(jù)包含了其T、T-1、T-2、T-3 年的數(shù)據(jù)。
如表1 所示,由于每家公司因財務數(shù)據(jù)異常成為ST 公司的年份不同,因此在該份數(shù)據(jù)集中,每個公司的數(shù)據(jù)屬性也不相同。若某公司2019 年才成為ST 公司,則文中將有足夠的數(shù)據(jù)分析其T、T-1、T-2、T-3 的變化狀態(tài)。根據(jù)表1 可知,有20 家公司可以分析3 年的數(shù)據(jù)變化。

表1 仿真數(shù)據(jù)結構
2.2 財務數(shù)據(jù)分析與預警仿真
在進行數(shù)據(jù)分析時,文中分別使用T-1、T-2、T-3的數(shù)據(jù)在上文所設計的算法模型上進行仿真。為了更優(yōu)地評估時間、財務數(shù)據(jù)等多個維度變化對于算法性能的影響,文中設計了多組實驗,每組實驗使用不同年份的財務數(shù)據(jù)。實驗的設計如表2~4所示。

表2 實驗一

表3 實驗二

表4 實驗三
文中進行仿真實驗的軟硬件環(huán)境如表5 所示。

表5 算法仿真環(huán)境
基于圖2 所示的指標體系,構建基于TD 算法的RLC 系統(tǒng)。在進行算法的仿真前,需要先確定RLC系統(tǒng)中執(zhí)行模塊的數(shù)量。文中在實驗1 的模式下通過遍歷的方式,計算出不同執(zhí)行模塊數(shù)量下的算法正確率及運行時間,分別如圖3(a)與圖3(b)所示。
從圖3(a)可以看出,當模塊數(shù)量小于8 時,算法的正確率增長迅速,從45%左右增長到了近80%;當執(zhí)行模塊數(shù)量大于8 時,算法的正確率增長緩慢,維持在80%左右。從圖3(b)可以看出,當執(zhí)行模塊小于7 時,算法的運行時間增長緩慢,維持在大約1.8×105s;當執(zhí)行模塊數(shù)大于7 時,運算時間增長迅速,綜合考慮圖3(a)和圖3(b),文中最終確定使用的執(zhí)行模塊數(shù)量為8 個。

圖3 執(zhí)行模塊數(shù)量對于算法正確率和運算時間的影響
表6 給出了在分布式強化學習下的不同實驗結果。為了對比,文中還引入了BP 神經(jīng)網(wǎng)絡,如表7 所示。從計算結果可以看出,對于異常財務數(shù)據(jù)的分析,分布式加強學習算法對ST 公司的識別正確率在各個實驗場景下均優(yōu)于BP 神經(jīng)網(wǎng)絡。其中,實驗三的計算精度提升了4.6%。從算法本身來看,實驗三的正確率優(yōu)于實驗二,實驗二的正確率優(yōu)于實驗一。這一結果說明,通過多個不同年度的財務數(shù)據(jù)累計,可以更優(yōu)地分析出企業(yè)的財務狀態(tài)。

表6 基于分布式強化學習的實驗結果

表7 基于BP神經(jīng)網(wǎng)絡的實驗結果
3 結束語
企業(yè)的財務數(shù)據(jù)分析,是一項較為復雜的系統(tǒng)工程。文中將分布式強化學習方法引入企業(yè)的財務數(shù)據(jù)分析中,通過構建合理的財務評價指標體系實現(xiàn)了對企業(yè)經(jīng)營狀態(tài)的精準評估。采用真實數(shù)據(jù)集進行的數(shù)據(jù)測試與仿真實驗結果表明,在該場景下分布式強化學習算法的性能優(yōu)于普通的反向傳播神經(jīng)網(wǎng)絡。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
工業(yè)設計(2022年8期)2022-09-09 07:43:20
現(xiàn)代企業(yè)(2021年2期)2021-07-20 07:57:18
軍民兩用技術與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
現(xiàn)代經(jīng)濟信息(2020年34期)2020-06-08 06:02:40
意林·全彩Color(2019年9期)2019-10-17 02:25:48
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
家庭影院技術(2017年9期)2017-09-26 03:41:45
河南水利年鑒(2017年0期)2017-05-19 02:29:27
