基于RBF網絡Q學習的AUV路徑跟蹤控制方法
2021-07-12 12:01:18李澤宇劉衛東李樂張文博郭利偉
西北工業大學學報 2021年3期
李澤宇, 劉衛東, 李樂, 張文博, 郭利偉
(西北工業大學 航海學院, 陜西 西安 710072)
水下回收技術極大地提高了AUV續航能力,路徑精確跟蹤是實現水下回收的關鍵[1]。欠驅動AUV通過速度和姿態角耦合控制調整自身航行位置,從而實現路徑跟蹤控制。在回收的不同階段,AUV的實際航行速度會產生較大變化,為路徑精確跟蹤帶來困難[2-3]。
許多傳統控制算法都曾被應用到AUV路徑跟蹤控制問題當中,Min等[4]設計了AUV路徑點跟蹤PD控制器,魯棒性較差;張磊[5]采用遺傳算法對模糊跟蹤控制器進行了優化,算法性能對專家知識依賴較大;王宏健等[6]采用二階濾波避免了反步法解析求導的復雜過程,能夠實現AUV路徑的精確跟蹤,但系統魯棒性較弱;王金強等[7-8]針對一種新型飛翼式AUV的位置跟蹤問題,采用自適應神經網絡對滑模控制器進行優化補償,但未考慮AUV航速變化對路徑跟蹤控制的影響,且一組控制參數難以滿足不同航行工況的控制需求。近年來隨著相關技術進步,模型預測和強化學習等基于數據的算法同樣被應用到AUV的跟蹤控制當中。Shen等[9]采用滾動優化方法對AUV進行了路徑優化與跟蹤控制一體化設計;Sun等[10]采用深度強化學習方法設計了AUV三維路徑跟蹤控制器;Shi等[11]采用多逆偽Q學習算法設計了軌跡跟蹤控制算法;姚緒梁等[12]采用模型預測控制與滑模控制方法對AUV直線路徑進行了仿真跟蹤。這些方法對AUV模型準確性依賴較低,對外干擾也具有良好的魯棒性,但算法結構復雜,經大量運算才能得到最優控制律,難以直接應用到工程實踐。若將傳統算法與學習網絡相結合,對多種航行工況進行離線訓練,將訓練后的學習參數應用于在線控制,可降低AUV實時優化的運算量,加快實時運動控制收斂速度,提高AUV在不同航速及外擾動下的路徑跟蹤性能。
1 跟蹤導引律及姿態控制器設計
欠驅動AUV具有左右對稱性,AUV與水下回收裝置處在同一深度上,有利于AUV回收對接。AUV水平面路徑跟蹤控制原理如圖1所示,已知一條AUV全局回收路徑曲線S[3],離散化路徑點序列為P(p1,p2,…,pn),其中pi(ξi,ζ0,ηi),i=1,2,…,n,路徑點深度ζ0保持不變。AUV路徑跟蹤控制轉化以下2個子問題組合控制:即調整目標路徑航向ψcmd的導引控制,以及對ψcmd的航向角跟蹤控制。
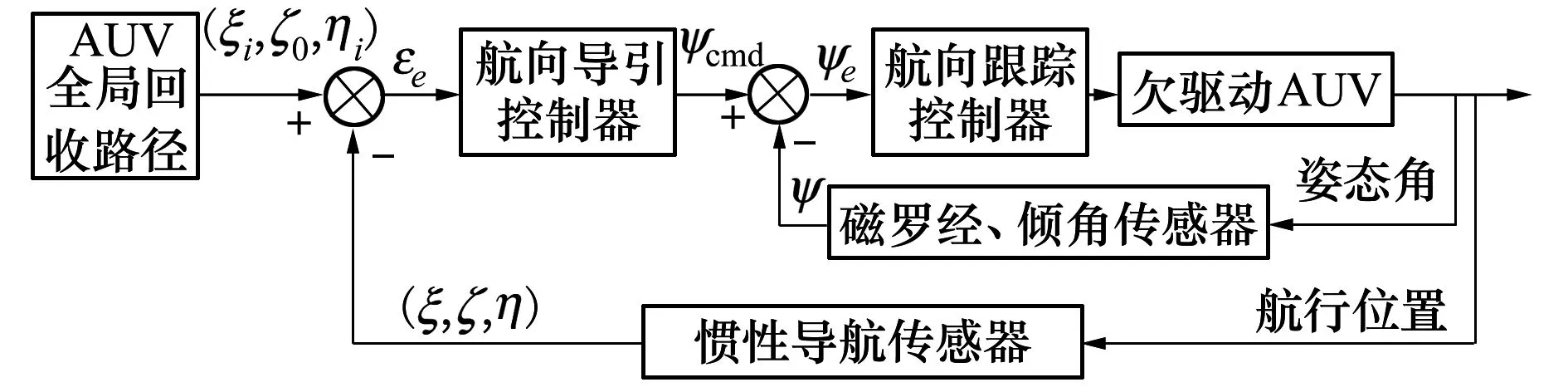
圖1 欠驅動AUV水平面路徑跟蹤控制原理圖
為實現水平面路徑跟蹤,AUV需要保持在指令深度ζ0處航行,控制原理如圖2所示。
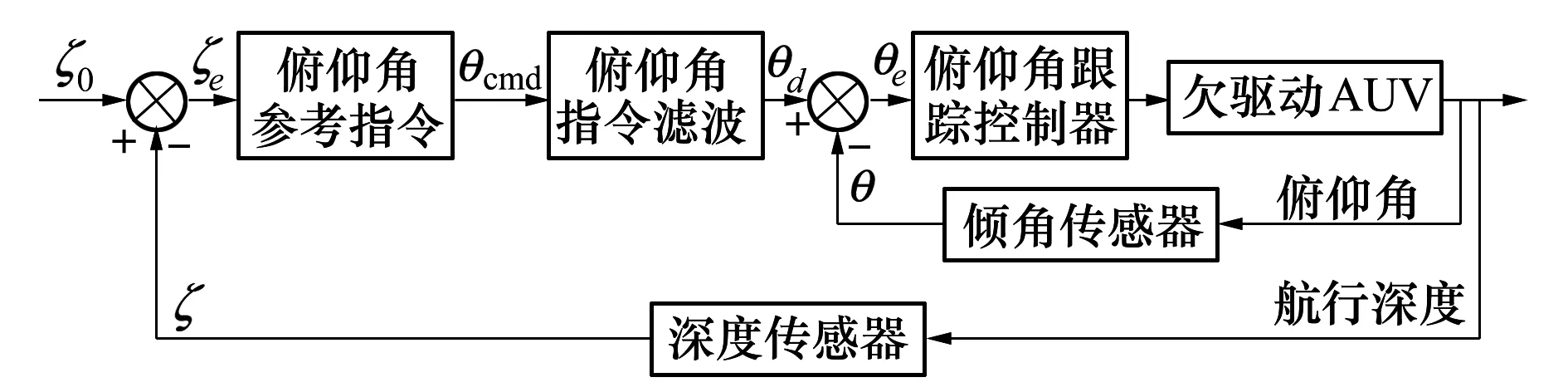
圖2 AUV深度控制原理圖
1.1 AUV路徑跟蹤導引律

圖3 AUV路徑跟蹤示意圖
εe=
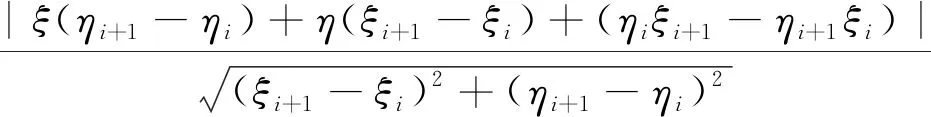
(1)
ψcmd=
(2)
1.2 AUV航向滑模控制律
AUV航向導引律(2)給出了AUV跟蹤期望路徑所需要的指令航向角度,而對指令航向角的精確穩定跟蹤是實現AUV全局路徑跟蹤的關鍵。AUV水平面偏航運動方程如(3)式所示:
(3)
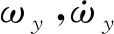
定義滑模面函數如(4)式,其中cψ>0,ψe=ψd-ψ,ψd表示航向控制指令,與(2)式中ψcmd數值大小相同。取航向跟蹤控制律如(5)式所示,則AUV航向跟蹤誤差ψe在有限時間內漸進收斂。
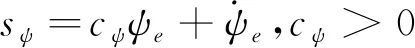
(4)
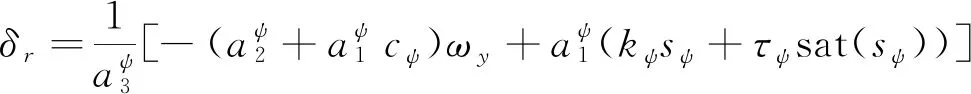
(5)
(6)
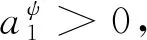
恒成立,因此,根據Barbalat引理,對于運動方程(3)式、滑模切換面(4)式以及控制律(5)式組成的閉環系統,系統具有漸進穩定性,誤差在有限時間內收斂。
1.3 AUV俯仰跟蹤控制律
(7)
式中
AUV回收路徑指令深度為ζ0,深度誤差ζe=ζ0-ζ,選取理想深度動態偏差特性為
(8)
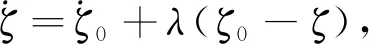
(9)
(10)
記俯仰角誤差θe=θd-θ,滑模面如(11)式所示,取俯仰跟蹤控制律如(12)式所示,則俯仰角誤差θe在有限時間內收斂。
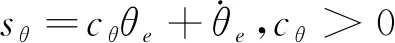
(11)
δe=
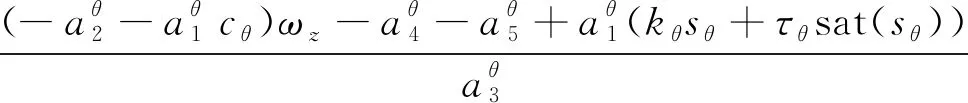
(12)
(13)
與航向角控制同理,AUV艉部舵面無法直接實現深度控制,只有通過圖2中的雙回路,在實現俯仰角指令θd的跟蹤前提下,實現深度控制,因而θd也被認為是常值。根據Barbalat引理,對于運動方程式(7)、滑模切換面式(11)以及控制律式(12)組成的閉環系統,系統具有漸進穩定性,誤差在有限時間內收斂。
2 RBF網絡Q學習參數優化
由航向及俯仰運動方程(3)式和(7)式可知,當航速保持恒定時,AUV運動狀態的響應特性主要與舵角δr和δe變化有關,舵角控制律(5)式和(12)式中,除AUV自身狀態變量ψ,wy,θ,wz等外,滑模控制參數c(·),k(·),τ(·)的取值直接影響舵角變化過程,參數的選取決定了系統控制特性。
在AUV回收對接中,受轉速指令、轉向、浮潛運動以及時變擾流等影響,AUV航速難以保持穩定狀態,傳統方法中同一組滑模控制參數不利于保證AUV全局路徑跟蹤控制性能。本節采用學習算法,根據AUV航行狀態反饋,實時優化滑模控制參數,提高系統性能。
2.1 Q學習算法參數定義
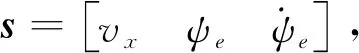
(14)
Qt+1(s,a)=
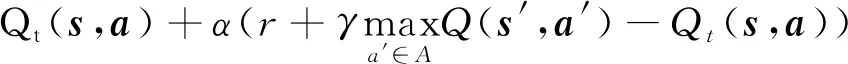
(15)
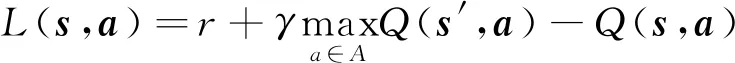
(16)
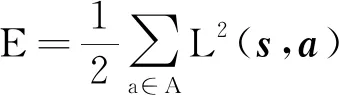
(17)
2.2 姿態控制參數優化過程
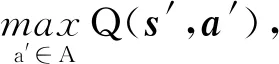
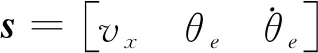
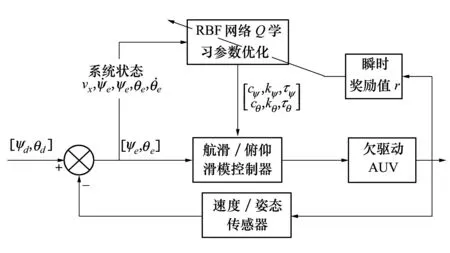
圖4 RBF-Q學習參數優化控制原理圖
3 仿真驗證
建立數值仿真環境,依次進行AUV不同航速下的定深、定向控制仿真,以及全局路徑跟蹤控制仿真,將RBF-Q學習參數優化控制方法與傳統滑模控制(SMC)方法進行對比,分析算法特點。
仿真中采用了某AUV空間六自由度非線性模型,舵角δr和δe限幅均為±15°,AUV航速區間為3.5~11 kn,外部擾動主要體現在AUV速度分量vx,vy,vz上的噪聲擾動。算法主要參數取值如下:學習率α=0.5,折扣系數γ=0.9,航向及俯仰控制參數c(·),k(·)和τ(·)的取值個數為10,綜合考慮超調量、穩態誤差及響應速度,AUV航速為8 kn時,滑模控制律(5)式和(12)式中的最優參數取值如表1所示,其中Δ表示取值間隔。RBF-Q學習算法需要對AUV不同航速、航向角度指令和俯仰角度指令進行離線學習訓練,表2給出了RBF-Q學習網絡訓練的取值范圍,為避免過擬合,AUV航速增加了一定幅值的隨機噪聲。

表1 AUV航向及俯仰控制參數取值

表2 RBF-Q學習離線訓練樣本取值
3.1 AUV多航速定深、定向控制
在回收過程中,AUV存在不同航速下的定深、定向航行狀態,選取工況為:航向角ψ由0°定向30°,深度ζ由175 m定深160 m,無外擾動條件下,選取AUV航速vx為8 kn和6 kn進行對比,結果如圖5和圖6所示;在6 kn航速下考慮時變擾動,航向及深度指令不變,仿真結果如圖7所示。
從圖5可以看到,2種算法下AUV定向、定深響應曲線近似重合,航向角ψ、俯仰角θ及深度ζ響應均具有較小的超調量和穩態誤差,表明在8 kn航速下,RBF-Q學習算法對滑模控制器的改善效果很小。但當AUV航速變化為6 kn時,AUV艉部舵效下降,傳統滑模控制器的深度響應曲線出現超調量約16.7%,如圖6所示,RBF-Q學習算法將深度響應的超調量降低至6.6%,在航向角響應中,RBF-Q學習算法比傳統滑模算法響應時間縮短了10 s,控制效果改善顯著。隨著外部擾動的增加,如圖7所示,RBF-Q學習控制器在穩態精度、響應速度和超調量方面,均比傳統滑模算法具有更好的表現,二者在航向穩態誤差相差了約5.5°,深度誤差相差了約2 m,但這些控制效果的改善存在一定的代價,即RBF-Q學習算法根據AUV航速、跟蹤誤差及其變化率持續優化滑模控制器參數。在8 kn無擾動條件下,控制參數基本無變化,初始參數即在最優解附近。當航速減小為6 kn,算法對控制器進行了短暫優化,之后隨著誤差收斂優化過程結束,達到穩定,而擾動的增加,使RBF-Q學習網絡持續對參數進行優化,以降低擾動影響。

圖5 無擾動8 kn航速下AUV定向定深控制響應 圖6 無擾動6 kn航速下AUV定向定深控制響應
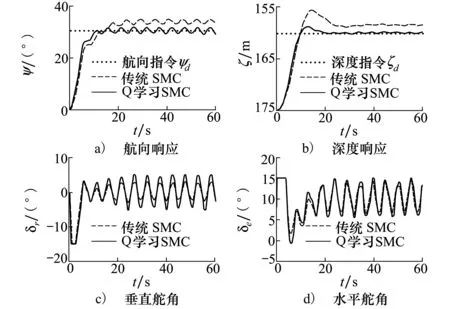
圖7 時變擾流,6 kn航速下AUV定向定深控制響應
3.2 AUV全局路徑跟蹤控制仿真
為分析2種算法在AUV路徑跟蹤控制中的性能,本節對先前研究成果[3]中的路徑進行跟蹤仿真,該路徑為水平面內的避障回收路徑,離散路徑點個數為100,航行深度設定為ζ0=120 m,根據本文(1)式和(2)式進行跟蹤導引,依次采用傳統滑模控制方法和RBF-Q學習參數優化控制方法對路徑進行跟蹤仿真,結果如圖8和圖9所示。
圖8給出了AUV在E-ξη平面內的航行軌跡,AUV的起點與規劃路徑起點不重合,回收路徑上存在多個障礙物,外部擾動為時變海流。在路徑的起始階段,傳統滑模控制算法下的AUV軌跡更加接近期望軌跡,隨著學習網絡的持續優化,在路徑中后段,RBF-Q學習算法控制下的AUV軌跡與期望軌跡基本重合,而傳統滑模控制算法下的AUV軌跡始終與期望軌跡存在偏差。圖9給出了AUV跟蹤過程中航向角和深度響應曲線。為避開水中障礙并到達路徑終點,AUV進行了多次轉向運動,RBF-Q學習算法對時變航向指令具有準、更快的響應效果,而且在深度保持控制中,RBF-Q學習算法的振蕩幅值更小,穩態控制精度更高。
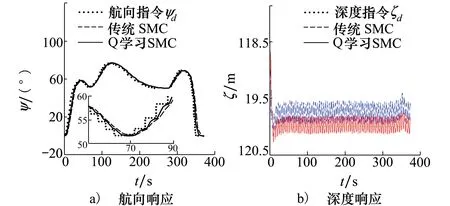
圖9 AUV路徑跟蹤航向及深度控制響應
4 結 論
AUV水下回收對接過程中,航行速度受推進器轉速、姿態變化以及時變擾流等因素影響難以保持穩定,使艉部舵面的操縱性能發生改變,導致同一組控制參數無法滿足復雜環境下的姿態控制和路徑跟蹤控制性能要求。針對上述問題,本文采用RBF網絡Q學習算法對傳統滑模控制參數進行優化,根據AUV當前航速、指令誤差及其變化律選擇相應的控制參數,經過大量離線訓練獲取學習網絡權重參數,將其應用到在線控制當中,仿真結果表明RBF-Q學習算法能夠有效改善AUV姿態控制和路徑跟蹤控制的性能,在相同條件下,RBF-Q學算法比傳統滑模算法具有更小的超調量和穩態誤差,響應速度更快。在后續研究中,針對舵角控制輸入中出現的非線性抖動問題作進一步優化,逐步進行AUV路徑跟蹤控制的實航試驗研究。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
