基于特征相對貢獻度對加權Mel倒譜的改進
2021-07-14 01:13:12王家盛郭其威馬建敏
聲學技術 2021年3期
王家盛,郭其威,吳 松,馬建敏
(1. 復旦大學航空航天系,上海200433;2. 上海宇航系統工程研究所,上海201109)
0 引 言
聲紋識別技術是生物識別技術的一種,借助人體生物特征或者行為特征對身份進行識別。與其他生物識別技術相比,說話人識別具有簡便經濟,隱藏性高以及獲取成本廉價等優勢,可廣泛應用于公共安全、金融服務、智能硬件等應用場景。
在聲紋識別中,影響識別率最大的就是特征參數的提取與選擇。目前主流的說話人特征主要是提取以梅爾倒譜系數(Mel Frequency Cepstrum Coefficient, MFCC)為代表的基于人耳聽覺感知特性的特征參數,類似的特征還有伽馬通頻率倒譜系數(Gammatone Frequency Cepstral Coefficients, GFCC)、耳蝸濾波器特征參數(Cochlear Filter Cepstral Coefficients, CFCC)等。其中,在大量的實驗中已證實MFCC具有優異的識別率表現,故對MFCC特征參數的優化與改進一直都是說話人識別研究中的重點。目前以優化特征的方式去改善聲紋識別性能的研究,主要可分為三個方向,即針對特征提取過程的改進、特征融合以及差異化特征分量。
在MFCC的提取過程中,實際上存在許多的簡單設定,并不能很好地模擬人耳聽覺效應。如傳統的傅里葉變換僅能提供2π/N等分的固定頻率分辨率,單個三角帶通濾波器呈中心對稱分布等。張怡然等通過引入多窗譜估計代替傳統的加漢明窗求頻譜的操作,減少了頻譜估計的方差值,能使特征更好地反映出聲道的結構[1]。章熙春等將彎折傅里葉變換(Wrapped Discrete Fourier transform, WDFT)應用到MFCC特征中以提高低頻段的頻率分辨率[2],鄧蕾等采用彎折濾波器組(Warped Filter Banks,WFBS)基于人耳基底膜感知頻率群在低頻處密集、高頻處寬松的分布特性,更好地模擬出人耳的聽覺機理[3]。Chakroborty等提出了翻轉梅爾倒譜濾波器組,目的是補償抑制高頻后的說話人信息缺失[4]。曹孝玉則進一步在翻轉梅爾倒譜率濾波器的基礎上提出混合型濾波器[5]。
為了彌補MFCC特征自身的局限,加入其他特征參數以提升系統識別正確率與應用場景,即特征融合。最典型的就是在靜態 MFCC的基礎上加入動態差分特征,補償說話人動態行為特征。唐宗渤將 MFCC與離散小波變換結合得到離散小波加權系數(Discrete Wavelet Transform Weighted Coefficient, DWTWC)特征[6]。呂霄云等將短時能量信息與 MFCC特征作為混合參數應用于異常聲音的識別[7]。沈凌潔等加入了韻律特征,在聲調識別場景有不錯的表現[8]。柯晶晶等將差分動態特征和加權后的Mel倒譜進行特征融合,提升了說話人系統的識別率[9]。茅正沖等利用Teager能量算子導出信號的瞬時相位信息,將其與耳蝸倒譜系數進行融合[10]。周萍等將MFCC與魯棒性更強的GFCC參數相互融合,提高了特征的識別性能和抗噪性[11]。
常規的特征提取或者進行簡單的特征堆疊勢必會導致大量的信息冗余現象,大量實驗已經證明,并不是特征的維數越高越好,各個維度的識別性能也存在不同的差異。故需要將識別性能強或者包含說話人身份信息的特征維度加強,讓低識別性的特征權重減少或消失。魏丹芳等將一階和二階動態系數加權合并成一個向量,能夠提高復雜場景環境下的分類正確率[12]。鮮曉東等基于Fisher比值對三類 MFCC特征參數進行篩選并組成一種混合特征參數,提高語音中高頻信息的識別精細度[13]。魏君穎等也采用了此方法結合翻轉梅爾倒譜系數選出區分度大的特征分量,提升了特征在噪聲環境下的魯棒性[14]。
本文基于強化特征差異的方法,借助 GMMUBM基線系統,對各維度MFCC分量的表征能力進行了分析,利用增減分量法定量計算出各維度對識別率的貢獻度,基于此對MFCC特征進行了二次提取,改進了特征分量的權重系數,提高了說話人識別的準確率。
1 MFCC特征提取與改進
聲道特性通常被認為是聲紋識別中包含說話人信息量最多的部分,由短時功率譜的包絡表征,即共振峰。如何準確地表達這個包絡成為聲紋特征構造的關鍵。
1940年Stevens和Volkmann對人耳主觀感知頻域的非線性進行了研究,給出了Mel標度與實際頻率f的定量近似關系[15]:
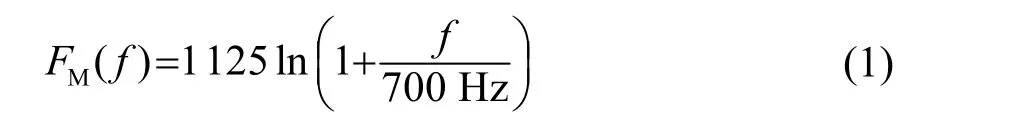
Mel頻率倒譜系數(MFCC)作為人耳聽覺感知特性的代表參數,能夠更好地仿真人耳主觀感知頻域與實際接收的聲音頻率的非線性關系。
1.1 MFCC特征提取
MFCC特征的提取大致可以分為以下兩個部分。首先,需要對采樣后的離散數字信息進行預處理。預處理主要包含去除寂靜幀、預加重、分幀和加窗等步驟。
預加重的目的在于彌補發聲系統所抑制的高頻分量損失,消除口鼻輻射端的影響,強化語音信號與聲道間的聯系,表達式為

其次,將預處理后的信息經過FFT變換可以得到信號的能量譜,將其作為基本特征傳入Mel三角濾波器組中,將每個子帶中的對數能量再進行一次離散余弦變換,可以得到一組系數。目前通常的方式是舍棄第1維參數,保留2~13維作為MFCC靜態特征。若僅用靜態 MFCC特征去訓練模型會損失掉動態幀的信息,一般會在后面加入一階差分動態特征和二階差分動態特征。
通過上述的MFCC提取過程可知,存在以下兩個步驟會導致特征的重復冗余:(1) 分幀步驟中為了保證短時范圍內提取的特征平滑變化,需使相鄰幀中有一部分重疊;(2) 為了彌補靜態MFCC特征的表征局限,引入語音特征向量的動態變換特性,動態特征一定程度上能提升識別率,但其計算過程中重復調用了前后幀的信息,且過多的動態特征引入反而不利于模型的識別。
1.2 權重系數的改進
為了使提取后的特征最大程度地包含說話人個性信息,可以對原始 MFCC特征序列進一步處理,即進行二次特征提取,提取后的特征更具區分性。提高特征參數區分性的方法有兩種:特征篩選和特征加權。
特征篩選,是指從原始特征參數中選取出表征能力強的部分分量進行模型訓練與識別。常用Fisher比值(簡稱F比)來判斷特征分量的區分能力,F比計算公式為

圖 1為 TIMIT數據集下 30位說話人的靜態MFCC各維Fisher比分布情況。
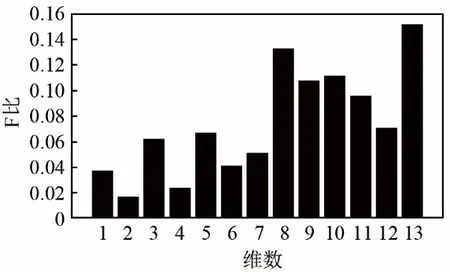
圖1 MFCC 參數各維 Fisher 比Fig.1 Fisher ratios of various dimensions of MFCC
由圖1可知,MFCC第13維的F比最高。但根據經驗,高維特征分量值太小易受到噪聲影響,區分性好的特征并非一定能訓練出識別性能高的說話人識別模型,故特征與模型之間還存在一個匹配問題。雖然F比計算簡便,但它假設特征分量之間是相互獨立的,沒有考慮到參數之間的相關性。
特征加權,是通過對特征參數內部設置不同的加權系數,放大或者縮小指定特征分量在識別時的作用。常采用升半正弦函數對 MFCC參數進行加權,公式[16]為
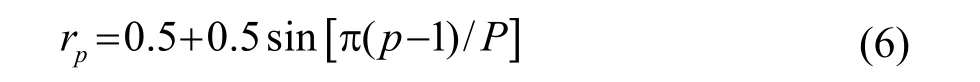
其中: p =1,2, … ,P,P是特征參數的維數。rp代表第p維分量上的權重系數。升半正弦函數的數學特征呈現兩端低中間高,代表對易受噪聲干擾的低階特征分量以及數值相對較小的高階分量進行衰減,對魯棒性較好的中部分量則維持不變。但升半正弦函數僅粗糙地設置了權重系數,沒有定量刻畫出每個分量在識別時的重要度。
基于此,本文對升半正弦公式進行優化。首先通過實驗得出各維特征分量對識別率的相對貢獻度。再據此,定量計算出各個特征分量上的權重系數。具體步驟如下:
(1) 采用增減分量法[17]定量計算不同特征分量對識別率的貢獻度,平均貢獻度計算公式為

式中:p( i, j)是從i階到j階特征系數的識別率;n是倒譜階數。
本文隨機選取TIMIT數據集中100人的10句話作為實驗數據集,從語音中提取13維MFCC倒譜參數作為靜態特征,再分別作一階、二階差分得到各13維的動態特征,構成39維特征向量。依次計算 MFCC各特征分量的順序組合在說話人識別系統中的識別率情況,結果如圖2所示。
圖2中每一條曲線的繪制方式如下,從下側標簽中選擇第i維特征Ci作為MFCC組合特征中的起始特征分量,依次計算Ci~Ci+1,Ci~Ci+2,… ,直至Ci~C39組合下的識別率,并將結果依次連接形成曲線。考慮到單獨一維特征在模型中的識別率太低,結果已經失去參考意義,加入會影響到貢獻度的計算,故實驗中所有測試特征向量的長度最低為2維。
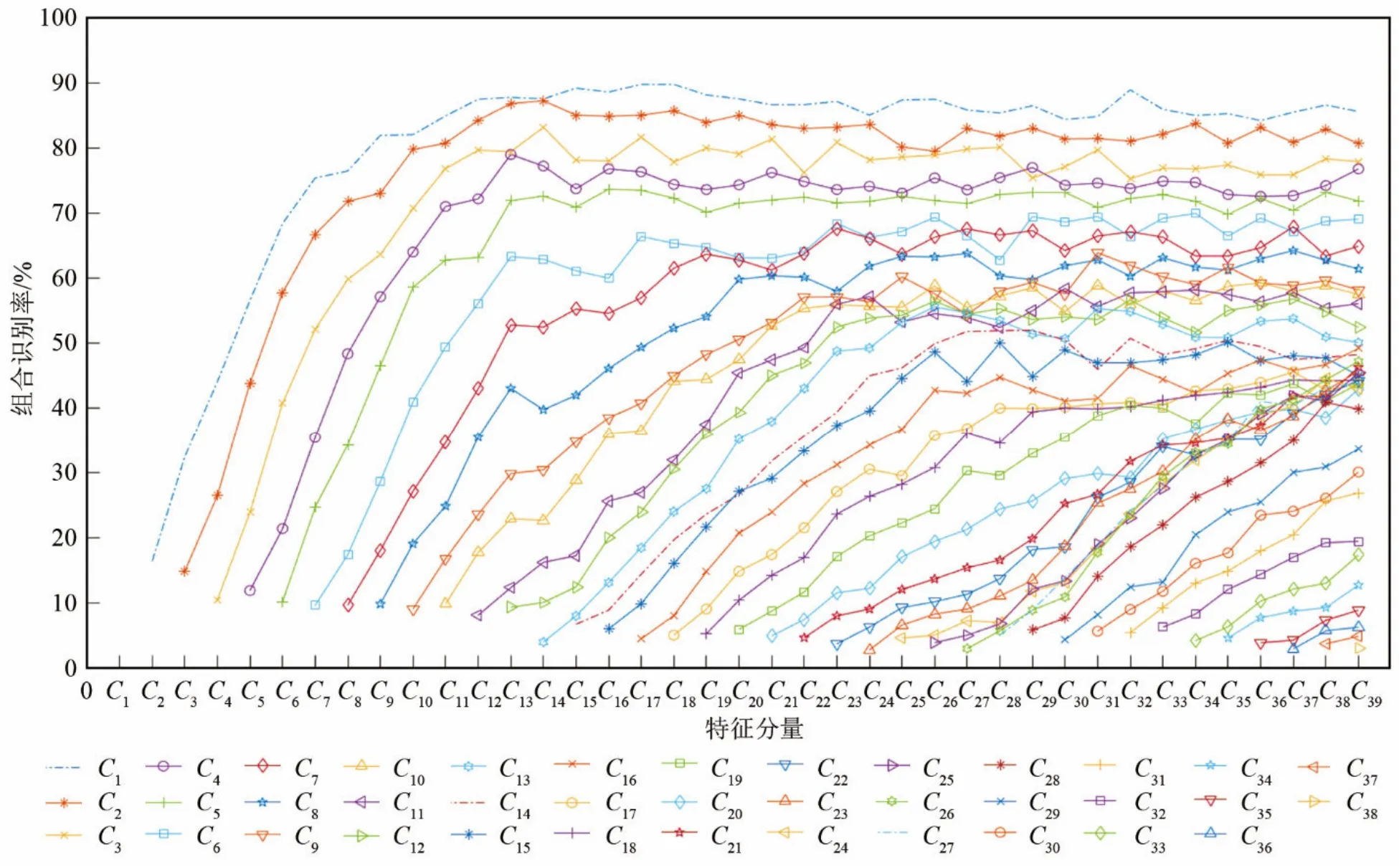
圖2 MFCC不同起始特征分量的特征組合識別率Fig.2 Recognition rates of different combinations of MFCC with different initial features
根據式(7)計算出 MFCC各維分量的平均貢獻度,得到貢獻率柱狀圖如圖3所示。
從圖3中可以發現,第一,靜態特征對最終識別率的貢獻度明顯大于動態特征對最終識別率的貢獻度,貢獻度越高,一定程度上反映的就是特征中包含說話人信息量也越多,此結果表明最有用的說話人的信息是包含在第 1~13維靜態特征之中的。第二,從圖3(a)中可以看出特征分量貢獻度的分布規律并不完全呈現出一種半正弦趨勢,反映的是一種類波浪分布,其中第 3~7維帶來更高的識別率。第三,動態特征是在靜態特征的基礎上差分得到的,從實際的測試結果看,貢獻度變化也符合前者的波浪走勢。
(2) 仿照升半正弦系數的構造方式,對 MFCC的第1~13維特征分量計算權重系數,如圖3(a)所示,第 11維特征分量的識別率貢獻度最低,設置其權重系數為 0.5,用于保證倒譜分量不至于完全衰減;貢獻度最高的第5維分量權重則設置為1,其余權重系數根據min-max標準化方法將數值放縮至[0.5, 1]區間內。
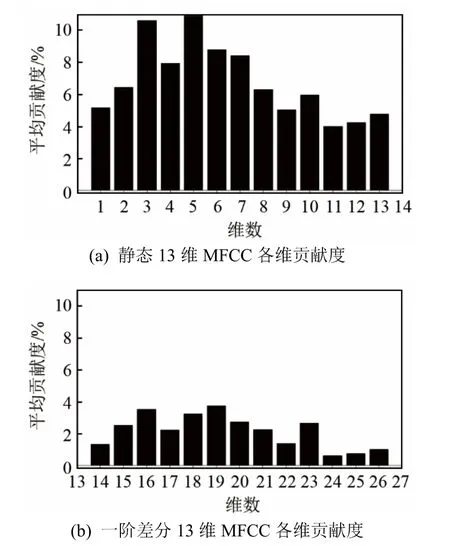
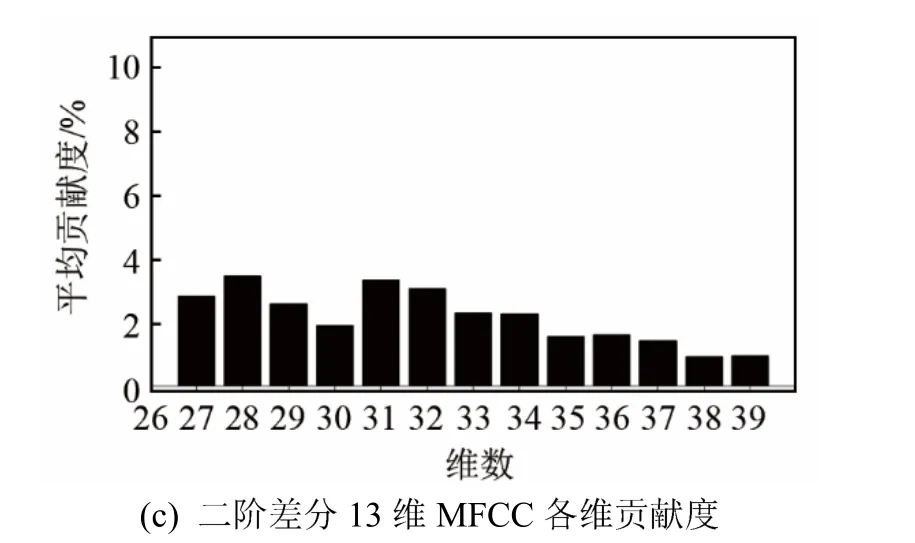
圖3 MFCC靜態及其差分特征對識別率的貢獻度Fig.3 Contribution of MFCC feature and its differential features to recognition
為了泛化實驗結果,同時也考慮到各分量本質上反映的是譜包絡的變化信息,權重需平滑過渡才能更好地體現分量間的相互依賴關系。使用Matlab軟件自帶的曲線擬合工具箱對放縮后的權重系數進行傅里葉擬合,并將擬合曲線對應特征序號上的離散值作為改進后的權重系數,權重系數為
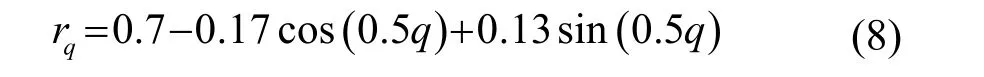
式中: q =1,2,… ,Q。rq代表第 q維分量上經過放縮和擬合處理后的權重系數。本文將此系數稱為貢獻度擬合權重系數。
圖4比較了升半弦權重系數和貢獻度擬合權重系數的分布特性。由圖4可以看出貢獻度擬合權重系數呈類波浪分布,相對于升半弦權重系數,能更準確地反映出各特征分量的識別能力表現。
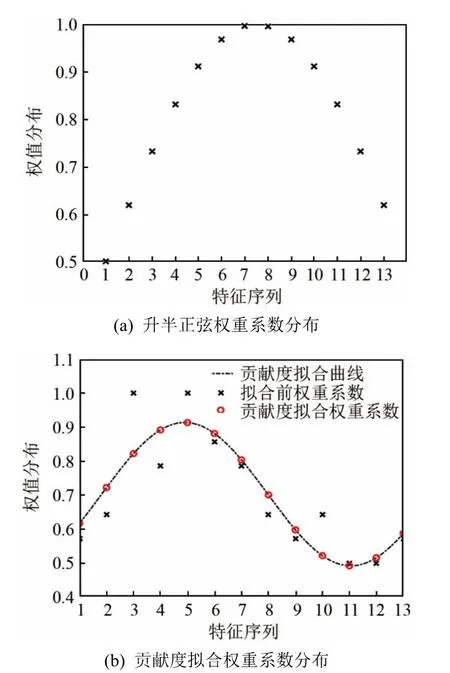
圖4 不同權重系數分布對比Fig.4 Comparison of different weight coefficient distribution
(3) 將貢獻度擬合權重系數對MFCC特征各個分量進行加權,即可得改進后的MFCC特征參數:
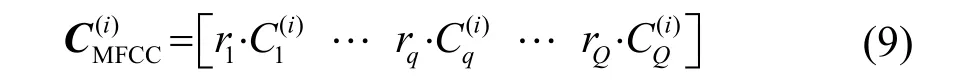
2 高斯混合模型
為了實現說話人識別,需要將提取后的特征建立相應的說話人識別模型,目前比較常用的理論模型是高斯混合模型(Gaussian Mixture Model,GMM)。在此基礎上發展出來的聯合因子分析(Joint Factor Analysis, JFA)[18]和全因子模型(i-vector)[19]都是對高斯混合模型的一種改進。每個GMM分量可以被認為是對隱性的聲學特征進行建模,從統計意義上來說,同一個人身上提取若干段語音片段,并將從這些語音中提取出的特征放入相應的特征空間中,可以發現模型生成的方式是基本一致的。其中需要估計的多元混合高斯分布參數為
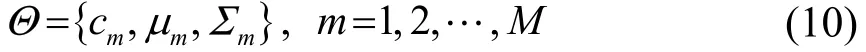
式中:M是高斯混合模型中分量的個數;cm是各個高斯分量的權重;μm是第m個高斯分量的均值;Σm是第m個高斯分量的協方差矩陣。
此外,為解決GMM由于訓練語音不足導致擬合不充分等問題,挑選出除數據集外的所有說話人進行建模得到通用背景模型(Universal Background Model, UBM)[20],其本質就是一個與說話人無關的高斯混合模型。
說話人識別系統框圖如圖5所示。說話人識別系統主要由三個模塊構成:特征提取、模型訓練以及說話人識別。特征提取中,使用貢獻度擬合權重系數對提取后的特征各分量進行加權。其中涉及的參數如下:幀長為20 ms,幀移為10 ms,漢寧窗,Mel濾波器的個數為24,選擇信號的對數能量作為第1維特征分量,再與從語音中提取到的12維倒譜系數組合成為13維靜態MFCC。
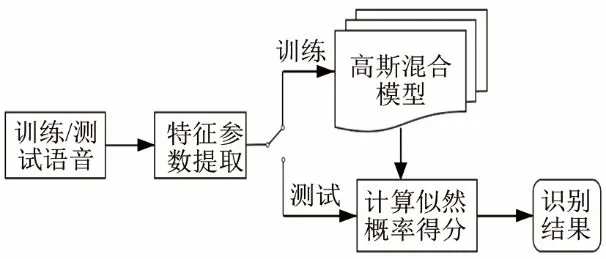
圖5 說話人識別系統框圖Fig.5 Framework of speaker recognition system
在模型的訓練階段根據UBM理論以及期望最大化(Expectation-Maximum, EM)算法生成每一個說話人所對應的高斯聚類模型,選定擬合高斯分布的數量為 32個。在識別階段,計算待測語音特征在所有模型中的對數似然概率,選擇得分最高的模型作為最終的識別結果。
最終的識別率計算公式為

3 識別實驗與結果分析
本文采用的是 TIMIT語音庫,是由德州儀器(TI)、麻省理工學院(MIT)和斯坦福研究院(SRI)合作構建的。由來自美國八個主要方言地區的630個人每人說出給定的 10個句子。其主要的特點是人聲干凈、發音清晰、沒有環境噪聲的干擾。從語音庫中隨機選擇100人作為實驗數據集,取第1句話作為訓練集數據,其余9句話用于測試。
首先,使用 Matlab軟件從語音信號中提取出13維MFCC特征向量,并用以下三種方法進一步提取特征:(1) 使用圖1中計算出的Fisher比值進行分量篩選,并將其組合成基于F比特征篩選的向量。(2) 使用公式(6)作為特征參數的權重系數,計算得到基于升半正弦權重系數的特征加權向量。(3)同理,根據公式(8)可得基于貢獻度擬合權重系數的特征加權向量。
其次,對每個說話人建立高斯混合模型,并根據測試語音的似然概率得分對識別率進行計算,改進后的特征在TIMIT數據集上的識別率結果如表1所示。
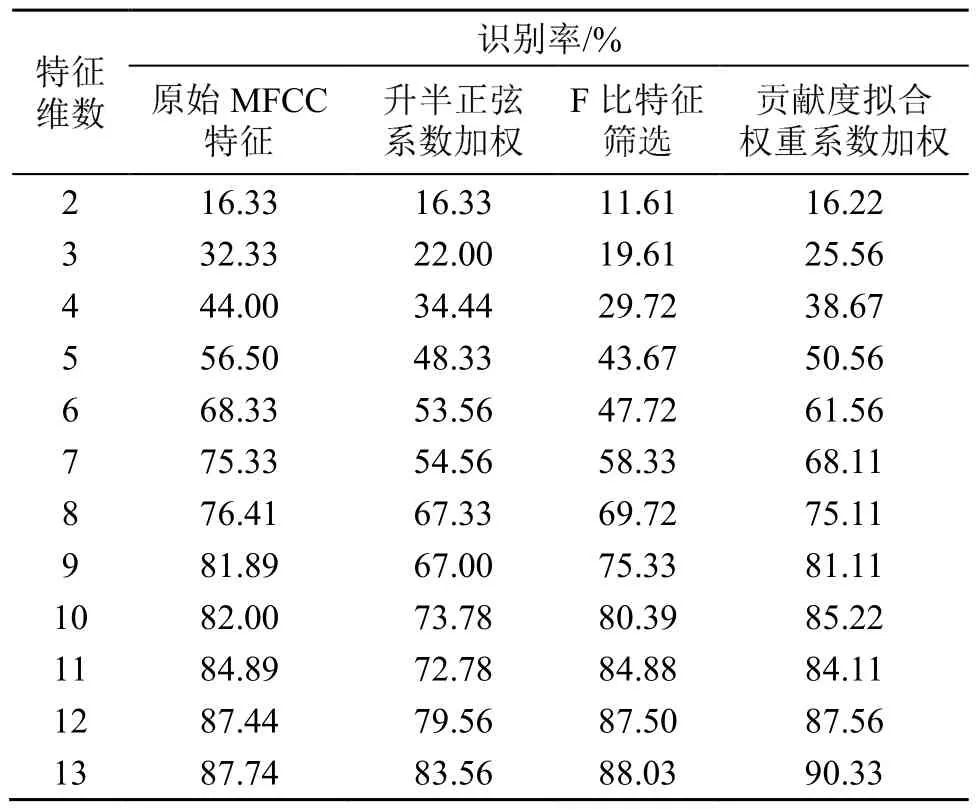
表1 幾種改進方式的識別率比較Table 1 Comparison of recognition rates of different improvement methods
根據表1可以發現,基于Fisher準則的維度篩選在2~10維的特征識別準確率均不如原始特征,說明F比僅反映特征分量的區分性,篩選破壞了分量原有次序,只是將區分性較高的特征分量進行簡單組合,并不能保證取得高識別率;特征加權,本質是差異化各維分量的表征能力,隨著特征維數的增加,各維分量間的區分性被不斷放大,將整體13維下的識別率作為特征加權改進后的效果進行分析。經升半正弦系數加權后的特征在TIMIT數據集上表現不是很理想,比原始MFCC特征分量的識別率低4.18個百分點,基于升半正弦的構造原理,原因可能是通過犧牲純凈語音集下一定程度的識別率性能,換取了特征在噪聲環境下的魯棒性提升;貢獻度擬合權重系數以特征對識別率的貢獻度作為加權依據,最終識別率比原始特征高出2.59個百分點。
4 結 論
特征提取是聲紋識別中的關鍵一環,本文以傳統的 MFCC特征為例,利用增減分量法對 MFCC各維特征分量對語音的表征能力進行了分析,并以此為基礎改進特征的權重系數,提出貢獻度擬合權重系數。與傳統的升半正弦系數相比,改進后每維分量上的權重系數可以通過貢獻度分布確定,能更準確地反映各維分量對識別性能的影響。實驗結果表明,與基于Fisher比值的特征篩選和基于升半正弦系數的特征加權相比,經貢獻度擬合權重系數加權后得到的特征能得到更高的識別率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
