基于動(dòng)態(tài)詞典匹配的語(yǔ)義增強(qiáng)中文命名實(shí)體識(shí)別算法
2021-07-14 00:14:12陳曙東歐陽(yáng)小葉
無(wú)線電工程 2021年7期
陳曙東,羅 超,歐陽(yáng)小葉,李 威
(1.中國(guó)科學(xué)院大學(xué) 微電子學(xué)院,北京 100049;2.中國(guó)科學(xué)院 微電子研究所,北京 100029)
0 引言
自然語(yǔ)言處理(Nature Language Processing,NLP)是人工智能領(lǐng)域的熱點(diǎn)研究方向,在機(jī)器翻譯、語(yǔ)音識(shí)別、情感分析、問(wèn)答系統(tǒng)、聊天機(jī)器人、文本分類和知識(shí)圖譜等方面都有重要應(yīng)用。命名實(shí)體識(shí)別(Name Entity Recognition,NER)[1-5]作為自然語(yǔ)言處理的一項(xiàng)基本任務(wù),旨在從非結(jié)構(gòu)化文本中識(shí)別出命名實(shí)體(如人名、地名和組織機(jī)構(gòu)名)。
傳統(tǒng)的命名實(shí)體識(shí)別方法主要包括基于規(guī)則[6]的方法、基于統(tǒng)計(jì)機(jī)器學(xué)習(xí)的方法以及二者混合的方法等。其中,基于規(guī)則的方法借助知識(shí)庫(kù)和詞典,利用語(yǔ)言學(xué)專家手工構(gòu)造的規(guī)則模板進(jìn)行命名實(shí)體的識(shí)別,是命名實(shí)體識(shí)別中最早使用的方法。基于統(tǒng)計(jì)機(jī)器學(xué)習(xí)的方法通過(guò)人工選取文本特征,借助融合語(yǔ)言模型和機(jī)器學(xué)習(xí)算法進(jìn)行命名實(shí)體識(shí)別,代表性的方法主要包括隱馬爾可夫模型[7]、最大熵[8]、支持向量機(jī)[9]和條件隨機(jī)場(chǎng)(Conditional Random Field,CRF)[10-12]等。
近年來(lái),隨著基于神經(jīng)網(wǎng)絡(luò)的各類深度學(xué)習(xí)方法的快速發(fā)展,NER研究逐漸從機(jī)器學(xué)習(xí)轉(zhuǎn)向深度學(xué)習(xí)。該類方法首先使用大規(guī)模的未標(biāo)注語(yǔ)料進(jìn)行詞向量訓(xùn)練,然后通過(guò)將預(yù)訓(xùn)練的詞向量輸入到深度學(xué)習(xí)網(wǎng)絡(luò)模型,用以實(shí)現(xiàn)端到端的命名實(shí)體識(shí)別。Huang等[13]利用雙向長(zhǎng)短時(shí)記憶(Bidirectional Long Short-Time Memory,BiLSTM)網(wǎng)絡(luò)和CRF來(lái)進(jìn)行命名實(shí)體識(shí)別,此模型獲得較好的表現(xiàn)。相比傳統(tǒng)機(jī)器學(xué)習(xí)方法,基于深度學(xué)習(xí)的方法通過(guò)自主學(xué)習(xí)而非人工方式從原始數(shù)據(jù)中獲得更深層次和更抽象的文本特征,較好地解決了傳統(tǒng)方法特征選取難度大和對(duì)數(shù)據(jù)的人為干擾等問(wèn)題,因此成為研究熱點(diǎn)。
與英文的NER任務(wù)相比,由于中文的句子中詞組不是自然分開(kāi)的,所以純粹基于字符的中文NER方法的缺點(diǎn)是沒(méi)有充分利用詞組的信息,考慮到這一點(diǎn),Ma等[14]提出了SoftLexicon模型,利用了詞典匹配的方法,用詞集標(biāo)簽“B,M,E,S”來(lái)表示字符在匹配的詞組結(jié)果中的位置,再對(duì)每個(gè)詞組的頻率進(jìn)行靜態(tài)歸一化,來(lái)表示詞集標(biāo)簽的權(quán)重。但是,對(duì)于詞組標(biāo)簽信息進(jìn)行靜態(tài)歸一化,而不是動(dòng)態(tài)地讓模型學(xué)習(xí)詞組標(biāo)簽的權(quán)重,會(huì)導(dǎo)致模型并不能自動(dòng)學(xué)習(xí)到特征,當(dāng)遇到詞典中沒(méi)有出現(xiàn)的詞組時(shí),模型就不能很好地對(duì)詞集標(biāo)簽進(jìn)行權(quán)重賦值。
針對(duì)詞組靜態(tài)歸一化的不足,本文提出了基于動(dòng)態(tài)詞典匹配的語(yǔ)義增強(qiáng)中文NER(Semantic Enhanced Chinese NER algorithm Based on Dynamic Dictionary Matching,SEDDM)算法。新算法解決了SoftLexicon模型存在的靜態(tài)歸一化等問(wèn)題,并且具有更優(yōu)的性能,通過(guò)在不同數(shù)據(jù)集上的實(shí)驗(yàn)測(cè)試,結(jié)果有效驗(yàn)證了新算法的實(shí)體識(shí)別準(zhǔn)確率更高。
1 相關(guān)工作
在初始的中文NER中,常見(jiàn)做法是,先使用現(xiàn)有的中文分詞(Chinese Word Segmentation,CWS)系統(tǒng)進(jìn)行分詞,然后將詞級(jí)序列標(biāo)記模型應(yīng)用于句子的分割[15]。然而,CWS系統(tǒng)不可避免地會(huì)出現(xiàn)對(duì)語(yǔ)句的錯(cuò)誤分割,導(dǎo)致實(shí)體邊界的劃分和實(shí)體類別的預(yù)測(cè)錯(cuò)誤。因此,He等人[16]提出基于字符的中文NER,被證明是有效的。Huang等人[13]使用BiLSTM進(jìn)行字符特征提取并使用CRF進(jìn)行解碼,該方法已實(shí)現(xiàn)較好的性能。其中,BiLSTM-CRF 模型是解決文本序列標(biāo)簽問(wèn)題的基準(zhǔn)模型。
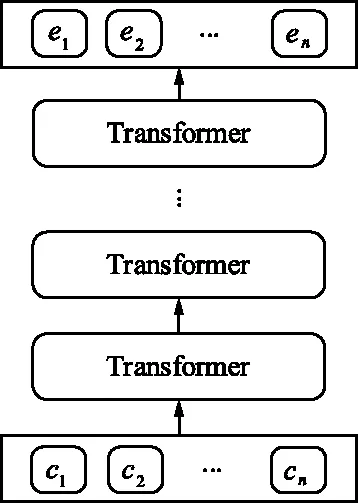
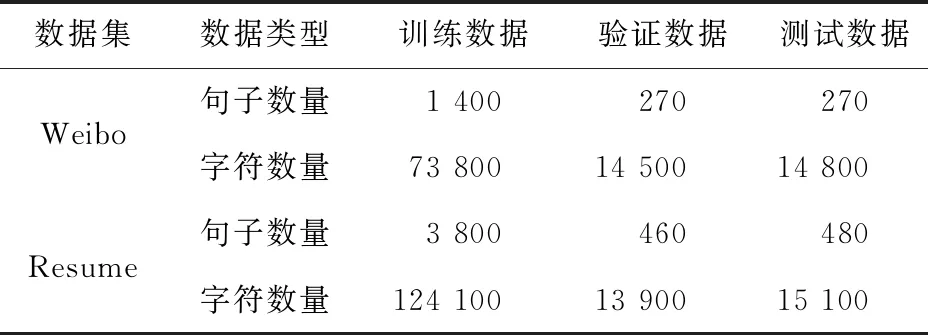
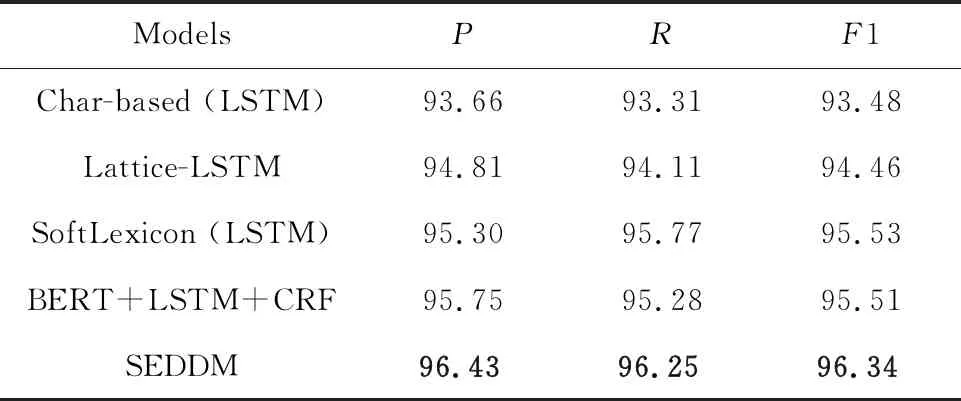
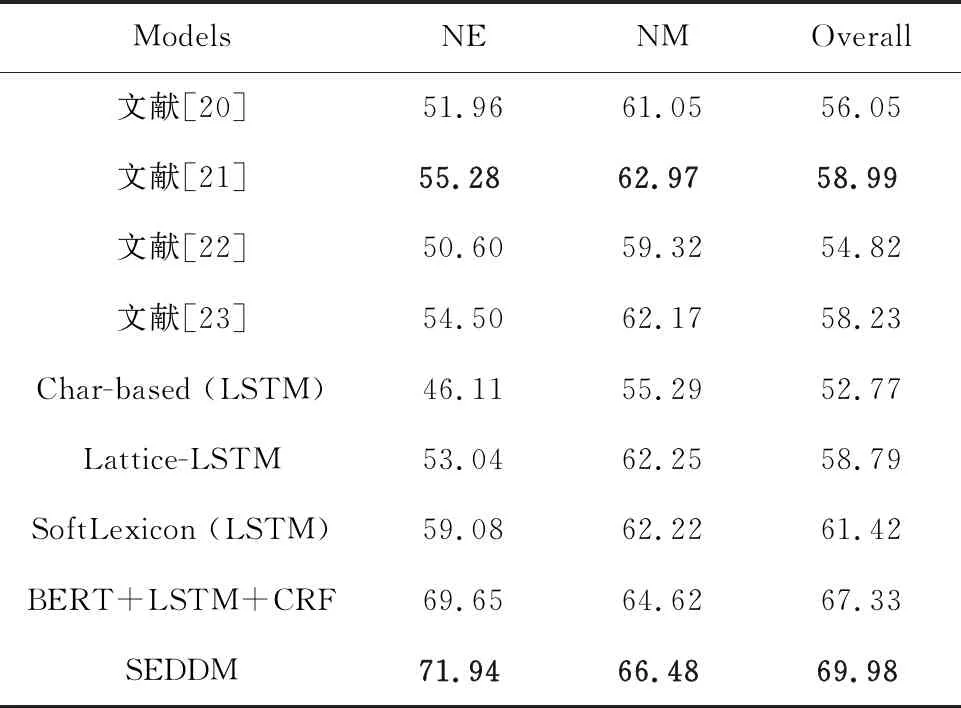
但是,純粹基于字符的NER方法,其缺點(diǎn)是沒(méi)有充分利用詞組的信息,考慮到這一點(diǎn),Zhang等[17]提出了Lattice-LSTM模型,其設(shè)計(jì)將詞匯信息,整合到基于字符的神經(jīng)網(wǎng)絡(luò)模型中。為了達(dá)到這個(gè)目的,首先對(duì)輸入的句子執(zhí)行詞匯匹配。如果對(duì)于i 然而,Lattice-LSTM的模型結(jié)構(gòu)太復(fù)雜,使得模型訓(xùn)練和預(yù)測(cè)速度變慢;此外,很難將Lattice-LSTM的結(jié)構(gòu)遷移到其他神經(jīng)網(wǎng)絡(luò)模型中(例如CNN[18]、Transformers[19])。為了解決這些問(wèn)題,Ma等[14]提出了SoftLexicon模型,該方法利用字符在匹配詞組中的位置,分為“B,M,E,S”4個(gè)詞集標(biāo)簽,并使用靜態(tài)歸一化的方法,將這4個(gè)詞集進(jìn)行權(quán)重分配,最終將詞集信息合并到字符表示中。由于只是改變字符的特征表示,所以可以使用通用的序列建模層和標(biāo)簽推理層。 本文提出一種新的基于字典的動(dòng)態(tài)詞組權(quán)重語(yǔ)義增強(qiáng)模型SEDDM神經(jīng)網(wǎng)絡(luò)來(lái)獲得詞集“B,M,E,S”的權(quán)重,并引入ALBERT預(yù)訓(xùn)練模型特征,增強(qiáng)字符的特征表示。在2個(gè)數(shù)據(jù)集上,獲得較好的結(jié)果。 在本文中,保留SoftLexicon的優(yōu)點(diǎn),同時(shí)克服其缺點(diǎn)。為此,提出了一種新的方法,通過(guò)神經(jīng)網(wǎng)絡(luò)來(lái)調(diào)整匹配詞組各個(gè)標(biāo)簽的權(quán)重,使得模型具有更好的推廣能力。本文將此方法稱為基于動(dòng)態(tài)詞典匹配的語(yǔ)義增強(qiáng)中文NER算法,模型如圖1所示。 圖1 基于動(dòng)態(tài)詞典匹配的語(yǔ)義增強(qiáng)中文命名實(shí)體識(shí)別算法模型 首先,對(duì)輸入的句子在字符表示層獲得字符的增強(qiáng)特征表示,其中,字符增強(qiáng)特征表示主要由3部分組成:① 將輸入序列的每個(gè)字符映射為一個(gè)密集向量word2vec;② 將序列中相鄰的字符在詞典中進(jìn)行詞組匹配,并按照字符在詞組中的位置,劃分為“B,M,E,S”4個(gè)類別,由于標(biāo)簽中匹配到的詞組個(gè)數(shù)不盡相同,所以經(jīng)過(guò)padding為統(tǒng)一長(zhǎng)度后,運(yùn)用神經(jīng)網(wǎng)絡(luò)進(jìn)行標(biāo)簽權(quán)重分配,得到詞組的文本信息;③ 加入ALBERT預(yù)訓(xùn)練模型的字符特征表示,并將這些特征整合為每個(gè)字符的增強(qiáng)特征表示。然后,在序列建模層運(yùn)用BiLSTM對(duì)字符的word2vec向量與字符增強(qiáng)特征進(jìn)行模型訓(xùn)練;④ 將序列建模層輸出,運(yùn)用條件隨機(jī)場(chǎng)識(shí)別出命名實(shí)體。 2.1.1 字符向量 對(duì)基于字符的中文NER模型,輸入語(yǔ)句被視為字符序列s={c1,c2,…,cn}∈Vc,其中Vc是字符詞匯表。每個(gè)字符ci用一個(gè)密集向量(嵌入)表示: 式中,ec表示字符嵌入的查找表。 2.1.2 詞組匹配的標(biāo)簽分類 對(duì)于輸入的句子,將各個(gè)字符與其臨近的字符組成詞組,在詞典中進(jìn)行匹配,所有匹配到詞組的字利用4個(gè)細(xì)分標(biāo)簽“B,M,E,S”來(lái)記錄。對(duì)于輸入序列s={c1,c2,…,cn}中的每個(gè)字符ci,這4個(gè)集合構(gòu)造如下: 式中,wi,j為子序列{ci,ci+1,…,cj},相當(dāng)于組成的詞組;L為使用的詞典,對(duì)于某一個(gè)字符,如果詞典中沒(méi)有詞組與之匹配,則用“None”來(lái)表示,詞組匹配的分類如圖2所示。 圖2 詞組匹配的分類 利用詞典匹配的方法,找到每個(gè)字符所匹配到的詞組,并對(duì)這個(gè)字符在詞組中的位置進(jìn)行標(biāo)簽分類。其中,B表示字符處于詞組的開(kāi)始,M表示字符處于詞組的中間,E表示字符處于詞組的結(jié)尾,S表示單個(gè)字符。在輸入句子“火車經(jīng)過(guò)唐山東站”中,以字符c6(“山”)為例,可以在詞典中匹配到的詞組有w5,6(“唐山”)、w5,8(“唐山東站”)和w6,7(“山東”)。其中c6處于w6,7的開(kāi)始,所以將詞組“山東”歸類到標(biāo)簽B中;c6處于w5,8的中間,將詞組“唐山東站”歸類到標(biāo)簽M中;c6處于w5,6的末尾,將詞組“唐山”歸類到標(biāo)簽E中。 2.1.3 詞集標(biāo)簽權(quán)重 獲得每個(gè)字符的“B,M,E,S”標(biāo)簽詞集后,求得4個(gè)標(biāo)簽的最大長(zhǎng)度lenmax,將標(biāo)簽長(zhǎng)度小于lenmax的進(jìn)行0向量填充,然后將填充后的標(biāo)簽向量輸入到神經(jīng)網(wǎng)絡(luò)中。 特別的,設(shè)z(w)表示詞典的詞組w出現(xiàn)在統(tǒng)計(jì)數(shù)據(jù)中的頻率,得到詞集S的權(quán)重表示如下: vs(S)=g(Z·w1+b1)·w2+b2 , 其中, , 式中,ew為詞嵌入查找表;p(·)為進(jìn)行0向量填充;g(·)為ReLU激活函數(shù)。在這項(xiàng)工作中,統(tǒng)計(jì)數(shù)據(jù)集是由訓(xùn)練和驗(yàn)證數(shù)據(jù)集組成。如果任務(wù)中有未標(biāo)記的數(shù)據(jù),則該未標(biāo)記的數(shù)據(jù)集可以作為統(tǒng)計(jì)數(shù)據(jù)集。此外,值得注意的是,如果詞組w的子序列覆蓋了另一個(gè)短詞組,則w的頻率不會(huì)增加,這避免了短詞組的頻率總是小于覆蓋它的長(zhǎng)詞組的頻率的問(wèn)題。 2.1.4 ALBERT預(yù)訓(xùn)練模型 ALBERT預(yù)訓(xùn)練語(yǔ)言模型采用雙向Transformer獲取文本的特征表示。其模型結(jié)構(gòu)如圖 3所示。其中c1,c2,…,cn表示序列中的每一個(gè)字符,經(jīng)過(guò)多層雙向Transformer編碼器的訓(xùn)練,最終得到字符的特征向量表示e1,e2,…,en。Transformer的模型結(jié)構(gòu)為Encoder-Decoder,ALBERT采用的是其 Encoder部分,該部分由多個(gè)相同的基本層組成。其中,每個(gè)基本層包含2個(gè)子網(wǎng)絡(luò)層:第1個(gè)為多頭自注意力機(jī)制層;第2個(gè)為普通前饋網(wǎng)絡(luò)層。 圖3 ALBERT模型結(jié)構(gòu) 2.1.5 字符增強(qiáng)特征 將4個(gè)詞集的向量表示組合成一個(gè)固定維的向量特征。為了盡可能多地保留特征信息,選擇將4個(gè)詞集的特征連接起來(lái),表示如下: es(B,M,E,S)=[vs(B);vs(M);vs(E);vs(S)]。 此處,vs表示詞集S的權(quán)重。最后一步是特征合并,將詞集特征與ALBERT預(yù)訓(xùn)練模型特征添加到字符的表示中,每個(gè)字符的增強(qiáng)特征表示為: 結(jié)合了詞典信息與ALBERT預(yù)訓(xùn)練模型特征,然后將字符的向量表示與字符的增強(qiáng)特征輸入到序列建模層,該層對(duì)字符之間的依賴關(guān)系進(jìn)行建模。該層的通用架構(gòu)包括雙向長(zhǎng)短時(shí)記憶BiLSTM網(wǎng)絡(luò),卷積神經(jīng)網(wǎng)絡(luò)(CNN)和Transformer模型。本文使用了單層BiLSTM來(lái)實(shí)現(xiàn)。其中,正向LSTM神經(jīng)網(wǎng)絡(luò)的定義為: ht=ot⊙tanh (ct), 在序列建模層之上,通常應(yīng)用條件隨機(jī)場(chǎng)來(lái)依次對(duì)整個(gè)字符序列進(jìn)行標(biāo)簽推斷: 可以使用維特比算法來(lái)有效解決。 本實(shí)驗(yàn)的數(shù)據(jù)采用中文Resume數(shù)據(jù)集、中文Weibo數(shù)據(jù)集,數(shù)據(jù)集統(tǒng)計(jì)結(jié)果如表1所示。在Resume數(shù)據(jù)集中,按照句子數(shù)量劃分為:訓(xùn)練數(shù)據(jù)1 400、驗(yàn)證數(shù)據(jù)270和測(cè)試數(shù)據(jù)270,按照字符數(shù)量劃分,分別為73 800,14 500,14 800個(gè)字符。同理,在Weibo數(shù)據(jù)集中,按照句子數(shù)量劃分為:訓(xùn)練數(shù)據(jù)3 800、驗(yàn)證數(shù)據(jù)460和測(cè)試數(shù)據(jù)480,對(duì)應(yīng)的字符數(shù)量分別為124 100,13 900,15 100個(gè)字符。 表1 數(shù)據(jù)集統(tǒng)計(jì) Weibo數(shù)據(jù)集分為:named entities(NE)、nominal entities(NM)和Overall三種類型,分別表示常用的命名實(shí)體(NE)、寬泛的名義實(shí)體(NM)和二者均包含的實(shí)體(Overall)。比如:“畫家”“書法家”在NE中不算作命名實(shí)體,但是在NM中卻算作命名實(shí)體。 模型采用訓(xùn)練數(shù)據(jù)集訓(xùn)練,驗(yàn)證數(shù)據(jù)集驗(yàn)證,測(cè)試數(shù)據(jù)集評(píng)估,采用精確率(Precision,P)、召回率(Recall,R)、F1 值評(píng)估中文命名實(shí)體識(shí)別模型的性能,當(dāng)且僅當(dāng)一個(gè)預(yù)測(cè)標(biāo)記的實(shí)體與真實(shí)實(shí)體完全匹配時(shí)才將其視為正確,計(jì)算公式如下: 測(cè)試數(shù)據(jù)集F1值(best_test)的更新條件為:在多輪的迭代中,若當(dāng)前驗(yàn)證數(shù)據(jù)集的F1值(current_dev)比之前最佳F1值(best_dev)高的時(shí)候,則更新best_dev,best_test值: when current_dev > best_dev : best_dev = current_dev best_test = current_test。 實(shí)驗(yàn)在Pytorch 1.6.0中實(shí)現(xiàn)了所有的神經(jīng)網(wǎng)絡(luò)模型,將隨機(jī)梯度下降法作為優(yōu)化器,學(xué)習(xí)率learning rate設(shè)置為0.005,模型的batchsize設(shè)置為1,dropout大小為0.5,lstm隱藏層設(shè)置為500,迭代次數(shù)epoch設(shè)置為100,神經(jīng)網(wǎng)絡(luò)中間層大小為2×lenmax。 在實(shí)驗(yàn)中,GPU為NVIDIA RTX 2060 SUPER,模型在GPU上進(jìn)行訓(xùn)練。在Weibo數(shù)據(jù)集上,100個(gè)epoch共訓(xùn)練了7 h;在Resume數(shù)據(jù)集上,100個(gè)epoch共訓(xùn)練了15 h。 實(shí)驗(yàn)結(jié)果對(duì)比方法:Peng等[20]提出使用3種類型的中文嵌入方法,利用NER的訓(xùn)練文本,對(duì)embedding進(jìn)行微調(diào);Peng等[21]提出對(duì)每一個(gè)在詞的不同位置中出現(xiàn)的字,訓(xùn)練一個(gè)字向量的方法;He等[22]提出了一種基于BiLSTM神經(jīng)網(wǎng)絡(luò)的半監(jiān)督學(xué)習(xí)模型;He等[23]提出了跨域?qū)W習(xí)和半監(jiān)督學(xué)習(xí)的統(tǒng)一模型;Char-based(LSTM)是最常用的字符級(jí)命名實(shí)體識(shí)別方法;Lattice-LSTM是Zhang等[17]對(duì)Char-based(LSTM)的改進(jìn)方法;SoftLexicon(LSTM)是Peng等[14]對(duì)Lattice-LSTM的改進(jìn)方法;BERT+LSTM+CRF是加入預(yù)訓(xùn)練模型BERT后,結(jié)合傳統(tǒng)LSTM+CRF得到的結(jié)果;SEDDM表示本文提出的基于動(dòng)態(tài)詞典匹配的語(yǔ)義增強(qiáng)中文命名實(shí)體識(shí)別算法。 不同模型在Resume數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果如表2所示,相比Char-based(LSTM),本文提出的模型F1值提高了2.86%,說(shuō)明引入詞組信息的有效性;相比Lattice-LSTM,模型F1值提高了1.88%,表明對(duì)詞組信息整合到字符表示特征中,能擁有更好的表現(xiàn)能力;相比SoftLexicon(LSTM),模型F1值提高了0.81%,表明對(duì)詞組標(biāo)簽集運(yùn)用神經(jīng)網(wǎng)絡(luò)加權(quán)的有效性;相比BERT+LSTM+CRF,模型F1值提高了0.83%,表明ALBERT和詞組信息的有效性。總體來(lái)看,本文提出的模型擁有比之前模型更好的表現(xiàn)結(jié)果,也驗(yàn)證了本文工作的有效性。 表2 Resume數(shù)據(jù)集的模型結(jié)果 不同模型在3種類型的Weibo數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果如表3所示,均為F1值。相比利用了字符嵌入特征的Peng等[20-21]提出的模型,以及跨域?qū)W習(xí)和半監(jiān)督學(xué)習(xí)的He等[22-23]提出的模型,在所有3個(gè)數(shù)據(jù)集上,本文所提出的SEDDM方法的表現(xiàn),F(xiàn)1值比上述最優(yōu)方法分別提高了16.66%,3.51%,10.99%;同理,相比Char-based(LSTM)、Lattice-LSTM、SoftLexicon(LSTM)和BERT + LSTM + CRF模型,本文所提出的SEDDM方法,擁有更好的表現(xiàn)結(jié)果。 表3 3種Weibo數(shù)據(jù)集的模型結(jié)果 可以看出,在模型整體表現(xiàn)比較差的時(shí)候,對(duì)NE數(shù)據(jù)集的識(shí)別率比較低,對(duì)NM數(shù)據(jù)集的識(shí)別率比較高;當(dāng)模型整體表現(xiàn)更好的時(shí)候,對(duì)NE數(shù)據(jù)集的識(shí)別率卻變得更高。所以可以看出,模型簡(jiǎn)單的時(shí)候,能較好地識(shí)別出寬泛的實(shí)體,對(duì)于精確的實(shí)體表現(xiàn)較差;當(dāng)模型復(fù)雜的時(shí)候,對(duì)精確的實(shí)體表現(xiàn)更好。 對(duì)比表2和表3可以看到,相同的模型在Resume數(shù)據(jù)集與Weibo數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果有較大差異,觀察2個(gè)數(shù)據(jù)集的構(gòu)成,因?yàn)镽esume數(shù)據(jù)集中,命名實(shí)體所占的比例更大更集中,而Weibo數(shù)據(jù)集中,命名實(shí)體的分布相對(duì)比較稀疏。所以,模型在2個(gè)不同的數(shù)據(jù)集上擁有較大的結(jié)果。 本文提出了一種基于動(dòng)態(tài)詞典匹配的語(yǔ)義增強(qiáng)中文命名實(shí)體識(shí)別算法,對(duì)輸入句子中的字符在詞典中進(jìn)行詞組匹配,利用4個(gè)標(biāo)簽“B,M,E,S”來(lái)表示字符在詞組中的位置,使用動(dòng)態(tài)權(quán)重將字典信息整合到字符表示中,添加ALBERT預(yù)訓(xùn)練模型來(lái)增強(qiáng)字符的表示,并基于BiLSTM進(jìn)行序列建模,在中文Resume、Weibo數(shù)據(jù)集下,相比于之前的方法,其F1值有所提升。2 基于字典的動(dòng)態(tài)注意力權(quán)重語(yǔ)義增強(qiáng)模型

2.1 字符表示層

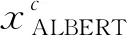
2.2 序列建模層
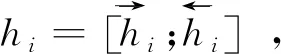
2.3 標(biāo)簽推理層

3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集和評(píng)估指標(biāo)
3.2 參數(shù)設(shè)置
3.3 實(shí)驗(yàn)結(jié)果和分析
4 結(jié)束語(yǔ)
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
