并行化洪水演進模擬研究綜述
2021-07-14 16:21:26張大偉姜曉明向立云
計算機工程與應用 2021年13期
李 健,張大偉,姜曉明,向立云
1.中國地質大學(武漢)海洋學院,武漢430074
2.中國水利水電科學研究院防洪減災所,北京100038
3.水利部防洪抗旱減災工程技術研究中心,北京100038
洪水風險圖編制是防汛減災非工程措施的重要手段,對降低洪水災害至關重要。但在實際應用中,洪水、降雨和地形條件復雜多變,實際汛情與計算方案情景差別很大,制約了洪水風險圖的實際應用效果[1]。實施可針對多種情景、任意邊界條件、實時演示和人機交互式計算的洪水演進模擬,為防汛決策等提供動態、實時的洪水淹沒信息,具有重要的現實意義。但是,基于水動力計算的洪水演進模擬計算量較大時,模擬耗時延長,將妨礙洪水淹沒的實時演示和防洪決策,并行化計算可解決此類問題[1]。
洪水演進模擬是計算水力學領域的一個重要研究方向,涉及繁雜的數值算法、研究手段和編程技術等,目前已幾乎不可能對其進行全面詳盡的綜述。然而,實際應用中多采用基于Godunov 型有限體積算法和網格計算的洪水演進模型,涉及到復雜地形處理、干濕前鋒追蹤、通量格式和諧性、模型魯棒性等問題[2],對此國內外學者從不同角度撰寫了大量綜述性論文,包括:洪水模擬的不同物理機制[3]、洪水演進模型的復雜度分析[4]、洪水淹沒的不確定性分析[5]、城市洪水淹沒模擬[6]。近年來計算機硬件和軟件的發展,尤其異構并行計算技術的發展,極大地推動了洪水演進模型的研發。但是,目前僅有覃金帛等[7]介紹GPU并行優化在水文計算和水庫調度研究中的應用,未見有系統性介紹并行化洪水演進模擬的綜述性論文。因此,有必要及時總結洪水演進的并行化研究成果,促進今后的洪水演進過程的并行化模擬研究。
考慮到洪水演進模擬研究的主流性、前沿性和實際應用價值,本文將介紹基于網求解淺水方程的并行化洪水演進模型,尤其是非結構網格模式。由于粒子法應用于實際河道或流域的洪水模擬時,存在邊界條件難以定義和計算量大等問題,以及計算機圖形學中的流體模擬,側重計算機可視化和高性能制圖算法,而流體模擬多采用無條件穩定的快速傅里葉變換(FFT)等算法,并不是求解流體方程,因此,本文綜述不包括上述的兩種數學模型,粒子法或計算機圖形學領域的并行化洪水演進模擬研究綜述可參考文獻[8]。本文將結合近年洪水演進模擬的最新數值算法和并行化技術,進行文獻綜述、討論和展望,期望為今后快速洪水預報研究起到拋磚引玉的作用,為防洪減災的實時會商和洪水風險圖的編制提供技術支撐。
1 洪水演進模擬的并行化需求
近年來洪水演進模型被廣泛應用于評估洪水造成的經濟損失,洪水演進模型包括1D、2D 和3D 模型,在復雜度和預報能力等方面存在較大差異。1D模型可提供的信息有限,一般僅用于模擬復雜河網或與2D 模型耦合,實現區域洪水模擬,但存在人為處理邊界條件的問題[9]。2D 模型采用結構網格或非結構網格求解淺水方程,精度高但計算量增大[10-12],可采用自適應網格加密(AMR)技術[13]和3D 模型[14]的方法來克服,但實際應用中的計算量任然較大。因此,基于網格計算的并行化洪水演進模型的研發和應用勢在必行。
2 洪水演進模型的并行化模式
常見的并行模式見表1,區別包括:并行層次(數據集、線程和進程)、并行粒度(細粒度和粗粒度)、硬件支持、軟件實現和編寫并行化代碼的編程語言。本文涉及的硬件、軟件和并行計算的計算機術語,僅列出對應的中文全稱和英文縮略詞,具體含義可參考文獻[15-16],后文中介紹的洪水演進模型使用的并行模式與表1 所列相對應。如果計算完全在中央處理單元(CPU)中完成,稱為同構并行計算,如果計算部分執行于CPU,部分執行于其他硬件設備,如圖形處理單元(GPU),稱為異構并行計算。從并行層級的角度,表1列出了從最低層級的數據并行,到線程級和進程級并行。
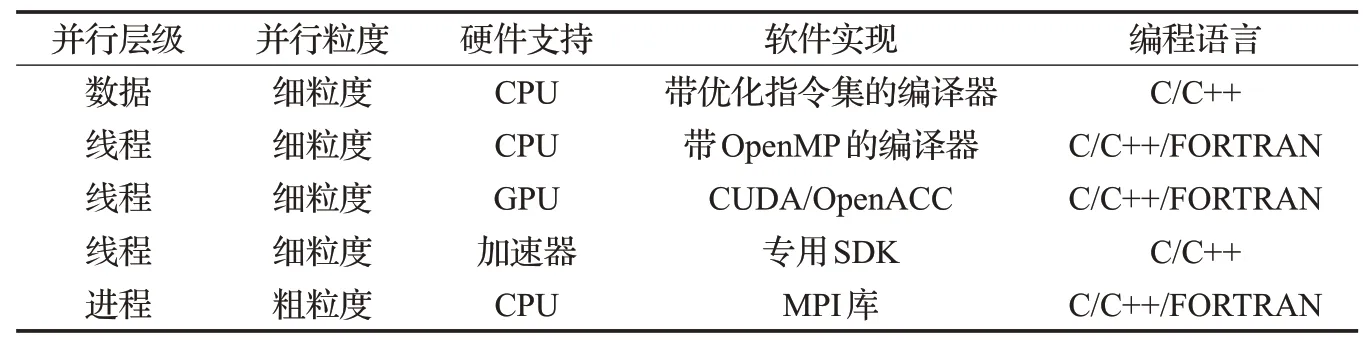
表1 常見的并行技術列表
3 并行化洪水演進模擬研究現狀
3.1 同構并行化洪水演進模型
洪水演進模型根據空間網格模式,可分為結構網格和非結構網格;根據時間離散格式,可分為顯格式和隱格式;根據對控制方程的不同簡化,可分為求解儲水單元、擴散波、淺水方程和靜水壓力假設的Navier-Stokes方程等類型的模型;根據數值方法,可分為有限差分法(FDM)、有限體積法(FVM)和有限單元法(FEM)等模型。針對不同類型的洪水演進模型,需要采用不同的并行模式。本文將根據以上分類,從并行計算的角度,選擇有代表性的模型列于表2,其中不包括未得到廣泛應用或測試或未并行化的洪水演進模型[11-12,17-29]。另外,表2所列模型還考慮了代碼的可獲取性,方便讀者選擇使用,檢驗洪水淹沒模擬結果的可重復性及模型對比分析。
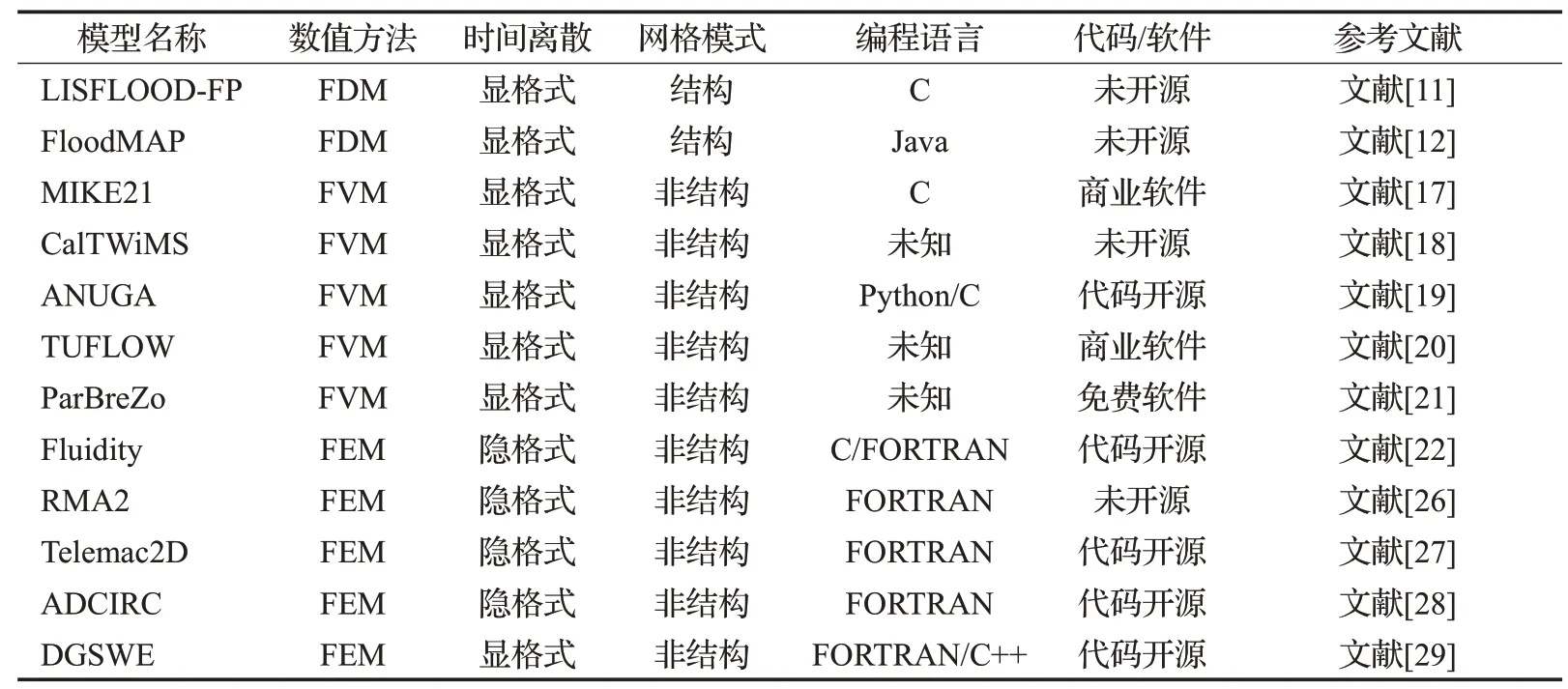
表2 一些有名的同構并行化洪水演進模型列表
較早的洪水模型多使用結構網格和FDM,如LISFLOOD-FP和FloodMAP模型,結構網格模型數據結構簡單,易于并行化編程,其中LISFLOOD-FP模型采用了OpenMP、MPI 和Clearspeed 三種并行機制,而Flood-MAP 采用多線程技術,LISFLOOD-FP 和FloodMAP 兩種模型采用顯格式近似求解黎曼問題的數值通量的方法,允許使用的計算時間步長較小,必須并行化才能應用于精細模擬區域洪水淹沒。需要指出的是,不同的并行化洪水演進模型,求解的控制方程,使用的數值方法和并行化機制均不同,籠統地比較不同模型的并行計算效率并無意義,但并行化結構網格模型研究為之后的并行化模型研發奠定了基礎。
近年來,洪水演進模擬已由結構網格計算轉向非結構網格計算的模式開發,而FVM在單元界面上近似求解黎曼問題,具有較強的洪水激波捕捉能力,如MIKE21[17]、CalTWiMS[18]、ANUGA[19]、TUFLOW[20]和ParBreZo[21]等模型,但缺點是:
(1)對網格質量要求高,網格的正交性嚴重影響數值格式的計算精度,進而影響計算穩定性。
(2)采用顯格式,當網格尺寸很小時,受CFL條件限制,允許使用的計算時間步長很小,嚴重影響計算效率。
(3)數值通量格式涉及大量數組循環計算。
(4)采用靜態網格,可能在干濕地形劇烈變化的區域網格密度不足,影響計算精度。
采用FEM離散方法可克服第(1)點問題,并行化計算可克服第(2)、(3)點問題,其中基于OpenMP 的細粒度線程并行可加速計算數組循環計算,結合區域分解后的MPI 進程并行,可取得更好的加速計算效果。基于AMR動態網格技術可克服第(4)點問題,實現自動加密局部網格密度,跟蹤干濕前鋒位置。但改進的方法也存在以下局限性:
(1)AMR網格可能會產生正交性較差的網格,一般結合FEM模型使用[22],已廣泛應用于洪水或海嘯傳播過程的模擬,但增大了并行化的難度,特別是采用MPI 并行時,靜態非結構網格可使用METIS[23]或SCOTCH[24]等庫實現荷載均衡的網格區域分解,并可降低分區間的數據通信量,提高并行計算效率,而AMR動態網格密度調整會引起荷載不均衡,需要進行分區網格的動態調整,可使用Zoltan庫[25]實現,但編程的難度會增大。
(2)AMR非結構網格還會破壞數據結構的局部性,這對GPU異構并行計算效率的影響尤其顯著。
(3)局部高密度網格會引起計算不穩定問題。
(4)在非結構網格上難以構建高階的空間離散格式。
(5)非結構網格隱格式模型,最終形成的具有稀疏系數矩陣的線性方程組求解量巨大,成為計算瓶頸,且系數矩陣的數據局部性對求解效率影響顯著。
近年來,基于FEM 的洪水演進模型研究得到廣泛開展(見表2),盡管FEM較FVM在編程上難度更大,但FEM 適應低質量網格的能力更高,因此計算穩定性較FVM 更好。FEM 可分為連續迦遼金(CG)法和間斷迦遼金(DG)法。CG法結合MPI并行化,一般采用隱格式離散,可高效地模擬洪水演進,但CG法求解對流占優的不連續問題時,存在質量不守恒和格式的耗散性過強的問題,一般采用流線迎風Petrov-Galerkin(SUPG)法解決,如RMA2[26]和Telemac2D[27]模型,也有基于求解通用波動連續性方程(GWCE)的CG法來提高離散格式的質量守恒性,如ADCIRC模型[28]。DG法不要求單元界面處滿足連續性條件,即具有FEM的靈活性又具有FVM的激波捕捉能力,同時可方便構建高階格式,如Fluidity[22]和DGSWE[29]模型。值得注意的是,FEM 模型的數學原理抽象,編程難度較大,模型計算量大,需要并行化才能高精度地模擬洪水演進過程。FEM模型結合基于網格質量指標判斷的AMR 動態網格技術,實現洪水演進過程中的干濕前鋒的準確捕捉,可明顯提高城市洪水和局部沖刷[30]等問題的模擬精度。求解大型線性方程組時,可有效利用多種并行模式的線性方程組求解器來提高計算效率,如PETSc 庫[31],同時可使用SCOTCH 庫中的Cuthill-McKee 算法或Gibbs-Poole-Stockmeyer 算法,實施對網格單元和節點編號重排序,進一步改善非結構網格模型的求解效率。需要指出的是,高階DG法中的高斯求積運算較大,需要合理設計網格分辨率,使計算結果在精度和計算效率上達到平衡。
3.2 異構并行化洪水演進模型
GPU 異構并行計算是利用顯卡中的眾多核心實現大量浮點運算的線程并行,非常適合用于加速FVM 洪水演進模型中數值通量涉及的數組循環計算,GPU異構并行的研究文獻在近年來快速增長。下面選擇有代表性的GPU異構并行洪水演進模型列于表3[17,20,32-41]。
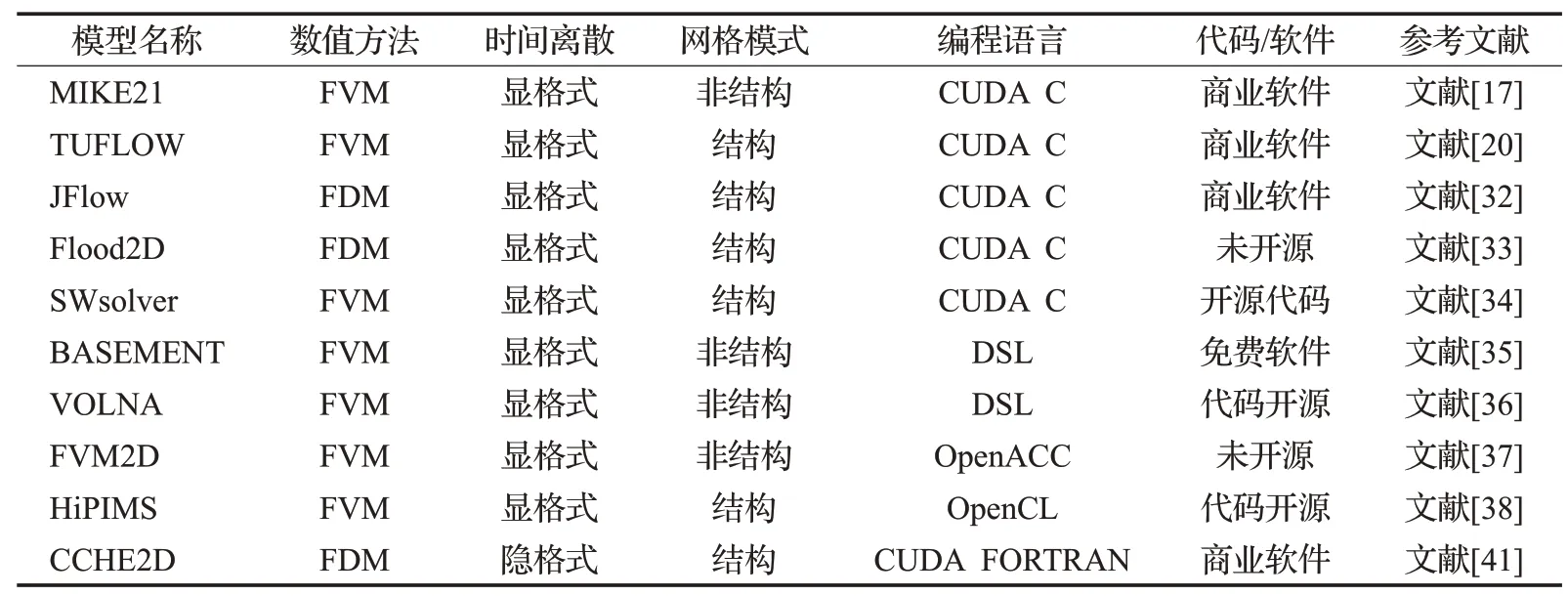
表3 一些有名的異構并行化洪水演進模型列表
早期的GPU異構并行洪水演進模型,均采用CUDA C語言編程,且GPU的硬件架構可有效加速結構網格的FDM 模型的計算效率,如JFlow[32]和Flood2D[33]模型。由于FVM 模型在求解不連續問題方面的優勢,異構并行的結構網格FVM 洪水演進模型也大量開展,如TUFLOW[20]和SWsolver[34]模型。非結構網格模型的數據結構較為復雜,異構并行編程的難度更大,且數據結構也會影響異構并行計算效率。因此,異構并行非結構洪水演進模型較異構并行結構網格模型的研究要晚,但已成為前沿研究課題,此類模型包括商業軟件MIKE21、免費軟件但不公開代碼的BASEMENT[35]以及開源代碼的VOLNA[36]模型。
異構并行非結構網格洪水演進模型存在的局限性有:(1)CUDA 編程復雜,會破壞串行程序的代碼結構,代碼維護成本高;(2)CUDA SDK版本進化和GPU硬件設備更新速度快,代碼更新難度大;(3)CUDA程序只能在Nvidia 公司的顯卡上執行,兼容性差;(4)非結構網格模式下,網格單元、節點和邊的連接關系必須顯式給出,這將導致大量的間接尋址訪問,對數據傳輸帶寬要求高,這在同構并行計算中問題不大,因為CPU內存的帶寬為Gb/s 量級,而GPU 顯存的帶寬一般為Mb/s 量級,因此必須使用有利于提高間接尋址訪問效率的數組形式。
針對以上問題,研究者們給出了解決方案,例如Zhang等[37]使用OpenACC指令集的異構并行方法,該方法類似于OpenMP指令的同構線程并行方法,對代碼結構幾乎沒有破壞,但是只能用PGI編譯器編譯。還可采用OpenCL 語言編程,提高模型對硬件的兼容性,如HiPIMS 模型[38]。還有研究者使用特定域語言(DSL)的程序庫,如OP2庫[39],可將串行版本的程序,快速轉換為不同的同構和異構并行化的程序,如BASEMENT 和VOLNA 模型,DSL 轉換可讓科學家和工程人員專注本專業領域的研究,而不必關注并行化編程本身,同時可應對軟件和硬件架構快速更替的問題。數組的排列形式分為Structure of Array(SoA)排列和Array of Structure(AoS)排列兩種,SoA排列和AoS排列對同構并行計算效率的影響不大,但在異構并行計算時,SoA 排列具有顯著優勢,可提高間接尋址訪問效率,同時實施非結構網格編號的重排序。
隱格式的洪水演進模型求解的瓶頸就是求解線性方程組,可調用異構并行的求解器,這樣可利用具有異構并行計算資源的集群系統,如Fluidity[40]和CCHE2D[41]模型。值得關注的是,采用異構并行化的系數矩陣預處理的Krylov 空間求解器(如PETSc 庫)和多重網格求解器(如AMGX 庫[42]),可進一步提高求解效率,已應用于一些計算流體力學商業軟件,但尚未見到用于隱格式洪水演進模擬的研究。
3.3 基于其他并行機制的洪水演進模型
除了基于MPI、OpenMP的同構并行和基于CUDA的異構并行洪水演進模型外,還有基于其他加速硬件設備和并行模式的洪水演進模型,此類并行化模式并未成為主流,但涉及最底層的數據并行或是對主流硬件加速研究的補充,也列于表4[11,34,43-44]。基于特殊處理器(如CELL和Clearspeed處理器)的并行化洪水模型,如SWSolver[34]和LISMIN-CS[11]模型。還有采用單指令多數據(SIMD)指令集(如SSE 和AVX)的數據并行,如CITEEC[43]和NUFSAW2D[44]模型。值得關注的是,NUFSAW2D 模型采用AVX 數據矢量化、MPI 和OpenMP 的混合并行,達到近1 000 倍的加速比,混合并行充分利用了并行計算硬件資源,在今后的洪水演進模型研發中應重視混合并行技術。由表4還可以看出:數據并行的洪水演進模型都采用結構網格,在非結構網格模型的數據并行和混合并行研發方面的加速計算效率還有待進一步研究。
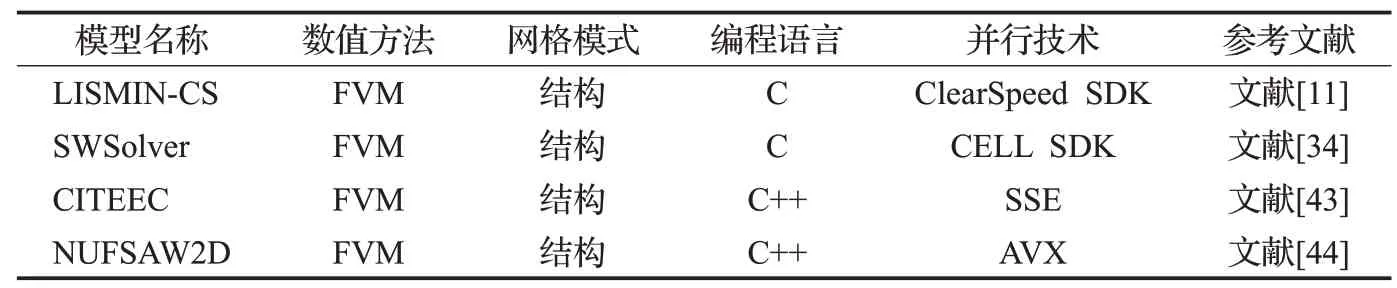
表4 基于其他并行機制的洪水演進模型列表
4 討論
首先,不同并行模式的洪水演進模型的研發技術難度、開發周期和維護成本存在較大差異,見表5,同構線程并行(OpenMP)和異構線程并行(OpenACC)僅需在串行代碼中添加一定的指令即可,編程難度最低,代碼的修改量最小,且不需要第三方程序庫,采用具備一定編譯功能的編譯器即可編譯和運行代碼,其開發周期較短。集群并行模式需要使用第三方的MPI 庫實施計算節點間數據通信,并實施網格分區間的數據收發、進程管理等,非結構網格區域分解還需要實施荷載均衡的第三方程序庫,編程難度中等,且需要在集群系統上運行。GPU異構并行和數據并行,需要特定的SDK,對串行代碼的修改量大,甚至要重新采用CUDA語言編程移植,編程難度最大,代碼維護成本最高。

表5 不同并行化洪水演進模型的總結
其次,采用MPI+OpenMP 和MPI+CUDA 的混合并行技術,充分挖掘洪水演進模型的細粒度和粗粒度并行潛力[45],可更進一步提高并行計算效率,見表5。MPI+CUDA 的異構并行稱為GPU 集群并行,涉及多個加速器之間的數據交換,如何實現荷載均衡條件下多個設備間的數據交換速度,是近年來的研究熱點,實現方法有兩種:(1)通過CPU 主機實現多GPU 設備間的數據通信,稱為三路數據通信;(2)多GPU 設備間直接數據通信,稱為雙路數據通信。后一種方式的數據交換速度最快,可使用Nvidia公司開發的GPUDirect技術來實現。
最后,使用類似FORTRAN 和C/C++這樣的靜態編程語言開發洪水演進模型,盡管具有很高的計算效率,但需要大量的代碼編寫,且容易出錯,開發效率低;盡管FORTRAN或C++語言的面向對象編程可大大降低編程量[46],但仍無法實現像FEM這樣復雜模型的快速建模。使用動態編程語言(如Python),可快速實現FDM、FVM和FEM模型的建立[47-48],結合Python語言的MPI、CUDA和OpenCL 等庫的接口程序[49-50],實現并行化計算。另外,由于FEM 算法易于形成抽象化范式,例如FEniCS項目建立了使用FEM,求解弱形式偏微分方程的統一形式語言(UFL)[51],見表5,應用UFL建立了Python語言編程的Firedrake模型[52],Firedrake模型實現了具有Python 語言接口的MPI、CUDA 和OP2 程序庫[53]、具有SSE和AVX指令集優化的COFFEE庫[54]、有限元自動組建的FIAT 庫[55]、用于線性和非線性問題求解的PETSc庫和非結構網格數據管理和編號的DMPlex庫[56]之間的無縫耦合,使用FEM 建立了模擬洪水演進的Fluids 模型[57]和模擬海嘯波傳播的Thetis模型[58],包括前處理、計算主程序和后處理,僅需要300 行Python 代碼。使用DSL 和UFL 可快速實現對串行代碼的并行化以及快速實施新的算法,上述不同并行洪水演進模型的優缺點及適用場景的具體總結見表5。
5 結論及展望
本文對具有代表性和實用性的并行化洪水演進模型進行了綜述,獲得以下幾點結論:
(1)基于線程并行(OpenMP)、基于進程并行(MPI)和基于GPU 異構并行(CUDA)的洪水演進模型具有很好的實際應用價值,不同的混合并行模式(如MPI+OpenMP以及MPI+CUDA)將更能充分利用不同層級的計算資源,達到更高的并行加速計算效率。
(2)并行化非結構網格模式的洪水演進模型開發是發展趨勢,但存在數據結構復雜、荷載均衡的區域分解以及數據結構對異構并行計算效率的影響較大等問題,可采用相關算法針對不同問題給出解決方案。
(3)使用特定域語言(DSL)和動態編程語言(如Python)開發并行化的洪水演進模型,可快速實施不同并行模式的洪水模擬加速效率的科學比較和新的洪水演進模擬算法,應該是今后的發展方向。
基于對并行化洪水演進模型的綜述,對今后并行化洪水演進模型研發提出幾點展望:
(1)非結構網格模式下的并行化洪水演進模型研發應成為著力點,應重點研究混合并行機制(如MPI+OpenMP+CUDA)、多GPU 間的數據直接交換技術(如GPUDirect技術)、解決并行化中自適應非結構網格加密的荷載不均衡問題(如使用Zoltan庫)。
(2)針對GPU架構特點,研發適合于GPU異構并行的網格形式,如Block Uniform Quadtree(BUG)網格[59],BUG網格的數據結構具有連續存儲、結構緊致的特點,特別是結合BUG 網格和變時間步長技術[60],可高速求解具有內邊界[61]和復雜河網的洪水演進過程。探討適于GPU加速的網格形式和數據結構仍有很大空間。
(3)基于計算機圖形庫OpenGL的實時洪水演進可視化和交互式計算是未來的發展趨勢[62],但如何實現并行計算(包括CPU集群并行和GPU集群并行)環境下的實時可視化和交互式計算,仍是有待解決的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年14期)2020-09-11 07:57:42
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
時代英語·高二(2015年1期)2015-03-16 00:08:11
現代企業(2015年9期)2015-02-28 18:56:50
