
城市場景中車聯網時空數據分析及其通達性方法
2021-07-16 13:04:56程久軍原桂遠崔杰周愛國呂博李光耀
通信學報 2021年6期
程久軍,原桂遠,崔杰,周愛國,呂博,李光耀
(1.同濟大學嵌入式系統與服務計算教育部重點實驗室,上海 200092;2.安徽大學計算機科學與技術學院,安徽 合肥 230601;3.同濟大學機械與能源工程學院,上海 200092;4.上海師范大學天華學院,上海 201815;5.同濟大學電子與信息工程學院,上海 200092)
1 引言
車聯網是一種可以實現車輛與其他網絡通信的動態網絡。在車聯網中,車輛通過傳感器收集自身及周圍車輛、道路和環境信息,對采集的時空數據進行分析和發布,為用戶提供各種應用服務,例如車輛遠程診斷[1]、視頻下載[2]、隱私保護[3-4]、數據傳輸[5-6]等功能。因此,車聯網時空數據分析及其通達性至關重要。
隨著傳感器技術的發展,車輛可以在運動過程中獲取自身狀態并感知周圍環境。同時,車輛可以通過車車通信獲取其他車輛的速度、加速度、地理位置等信息。然而,目前缺少統一的車輛數據采集存儲標準,不同傳感器存儲的數據結構可能相差很大。另外,在城市場景中,由于建筑物的遮擋和其他因素干擾,時空數據可能存在噪聲和數據丟失的問題。需要有效的車聯網時空數據分析方法進行數據的整合、噪聲去除和填充,為車聯網應用提供數據支持。
按照有無路邊基礎設施支持,車聯網可分為有基礎設施的車輛網絡和車輛自組織網絡。與車輛自組織網絡不同,在城市場景中車聯網具有路邊基礎設施支持,車輛之間不僅可以通過車車通信實現連通,也可以跨路邊基礎設施實現連通。然而,路邊基礎設施帶寬有限,不能為所有車輛提供數據轉發服務。因此,需要實時準確地檢測車聯網中不能通過車車通信實現連通的子網,并通過路邊基礎設施實現車輛之間的連通,保證拓撲結構發生變化時車聯網的通達性。
與高速公路場景下的車聯網相比,城市場景中的車聯網具有以下特點。1) 車輛運動受到其他車輛和紅綠燈的影響,行車環境更加復雜。2) 車輛數量較多,車聯網規模較大。同時,由于紅綠燈和路網結構的影響,車輛可能存在分布不均勻的現象。3) 由于建筑物的遮擋,距離小于通信范圍的車輛之間可能不能直接建立通信鏈路。同時,受各種干擾因素的影響,車輛之間的通信鏈路會頻繁地斷開重連,預估車輛之間在未來一段時間內保持連通的可能性更加困難。因此,高速公路場景下的車聯網通達性不完全適用于城市場景中的車聯網。
本文提出一種城市場景中車聯網時空數據分析及其通達性方法,主要貢獻包括以下兩點:1) 提出一種車聯網時空數據分析方法;2) 提出一種城市場景中車聯網通達性方法。
2 相關工作
在車聯網時空數據分析方面,文獻[7]總結了當前車聯網時空數據分析面臨的挑戰:找到合適的過濾器提取有價值信息;將無用和冗余信息剔除;利用有效的方式對數據進行表示和分析;建立有效的預測模型進行交通管理。當車聯網網絡負載不足以支撐車輛間數據傳輸時,文獻[8]將路網進行劃分,將車輛映射到劃分出的格子中,以交通密度、帶寬、時延和花費作為指標對車輛的網絡接入進行評價,從而對車輛接入傳統網絡或車聯網以及車聯網中哪個節點進行決策,最終使車輛獲得較好的服務質量。針對傳統的關系型數據庫和數據庫管理系統對給定時間周期和數據維度的查詢支持度不夠的問題,文獻[9]在靜態R 樹結構上使用希爾伯特曲線和HBase 技術,使模型對范圍查詢和k 近鄰查詢都有較好的性能表現。文獻[10]分析了車聯網的特性,將車聯網中的數據流比擬為流體,推導出網絡特性描述方程,然后,基于網絡特性描述方程推導出車聯網網絡容量計算模型,該模型分析了網絡規模和網絡時延對網絡容量的影響,得出了網絡容量下降的原因。文獻[11]提出了一種基于并行數據挖掘的軌跡數據模式發現方法,并構建了知識模型捕捉用戶移動行為。該軌跡數據模式發現方法可用于車輛位置預測、旅行推薦、智能交通管理等應用和服務。針對車輛自組織網絡中網絡拓撲結構多變和時空數據復雜的問題,文獻[12]提出了一種基于貝葉斯聯盟博弈和學習自動機的車輛節點聯合處理時空數據的方法。
車輛快速移動導致車聯網拓撲結構頻繁變化和節點之間通信鏈路不穩定,這些特性使車聯網通達性面臨2 個挑戰:構建準確描述車輛運動的模型;基于車輛運動模型構建車聯網通信協議實現車輛之間的互聯互通。文獻[13]研究了高速公路場景中車聯網的連通性,分析了在特定路段上車輛之間連通概率與連通集直徑、連通集數目、車輛密度和車輛傳輸距離之間的關系。分析結果表明,當車輛進入高速公路是泊松過程時,車聯網中車輛位置滿足伽馬分布。通過統計道路的交通密度、交叉路口和路段等道路信息,文獻[14]提出了一種道路感知路由協議,并研究了路由協議的恢復機制和性能指標。實驗結果表明,即使在交通密度較高的情況下,文獻[14]協議依然無法避免網絡分裂的現象,也不能保證網絡整體連通;要達到減少網絡分裂的目的,可借助反向運動車輛實現信息轉發和增加節點通信距離。文獻[15]分析了高速公路場景中車輛之間的連通性,研究了車輛進入高速公路的速率、車輛速度以及車輛離開高速公路的概率等參數對連通性的影響。針對大規模車聯網互聯互通耦合度低的問題,文獻[16]通過一種車聯網連通基的網絡拓撲結構,提出了分布式連通基構造方法,針對大規模車聯網通達性問題,作者結合平滑高斯?半馬爾可夫移動模型研究了連通基的內部結構屬性和動態特性,對動態環境下車聯網的通達性進行評估。在大規模車聯網中,連通基可用于轉發數據包,進而實現車輛節點之間的連通。針對車輛自組織網絡拓撲結構頻繁變化導致的連通易變問題,文獻[17]提出了一種基于自編碼網絡和循環神經網絡的車輛自組織網絡連通預測方法和一種基于連通預測的動態分簇方法,細化了簇內角色,研究了節點之間數據轉發的代價,給出了車輛之間連通路徑構造方法。
在車聯網時空數據分析方面,大多數研究對車聯網實時性以及拓撲結構變化快的特性考慮不足。另外,在車聯網通達性研究方面,大多數研究集中在網絡整體通達性,只總結各個參數對通達性的影響,缺少對節點間通達性的研究。
3 城市場景中車聯網時空數據分析
3.1 相關定義
定義1城市場景中的車聯網可表示為
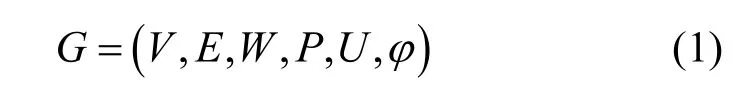
定義2車輛vi在t時刻的特征可表示為

其中,s表示vi的速度,a表示vi的加速度,p表示vi的位置,ρ表示vi所處的路段,u表示vi關聯的路邊基礎設施。
3.2 基于噪聲去除和數據填充的時空數據處理
3.2.1 噪聲去除
假設vi在t時刻的位置為p,在時刻的位置為,如果vi的速度與加速度方向相同,則

然而,車輛的加速度與速度之間可能存在夾角,式(3)估計的車輛位置可能不夠準確。為了判斷傳感器采集的車輛位置是否準確,給出車輛位置可信區域。可信區域的4 個頂點的坐標為

其中,p1、p2、p3、p4分別表示可信區域的左下角、左上角、右下角、右上角坐標,θ表示s與a之間的夾角,ι表示車輛在t時刻與時刻位置之間的距離。
若位置傳感器采集的車輛位置位于可信區域內,則保留數據;否則判定采集的數據為噪聲,將其去除。
3.2.2 時間性自相關數據填充
本文針對噪聲去除導致少量數據丟失的問題,從時間角度分析車輛的數據,對丟失數據進行估計,進而達到數據填充的目的。傳統的指數平滑方法[18]在進行數據填充時僅考慮過去一段時間傳感器的采樣值,沒有考慮未來一段時間傳感器的采樣值。為此,本文改進了指數平滑方法,將其用來填充車聯網數據,填充時不僅考慮填充時間前傳感器采集的數據,而且考慮數據丟失時間后傳感器采集的數據。本文將該數據填充方法定義為時間性自相關數據填充,即

其中,Δt表示傳感器采樣的時間間隔,η表示數據填充窗口的大小,α(α∈(0,1))表示平滑系數,f(vi,t?jΔt)表示數據丟失時間t之前傳感器采集的數據,f(vi,t+jΔt)表示數據丟失時間t之后傳感器采集的數據。
3.2.3 時空性協同過濾數據填充
路網匹配[19]將前后軌跡數據映射到路網中,對可能的軌跡進行評價,從而選取概率最大的一條作為填充數據,但存在對應時間點的參數預測困難的問題。雖然節點狀態變化頻繁,拓撲結構每時每刻都在更新,但由于路網的存在,最佳路線選取的策略幾乎一致,在某時間點連通的兩輛車在過去和未來都可能存在相似的軌跡和狀態。尤其是在高速路段以及工作日早晚高峰,車輛的目的地極其相近,所以可以借助這些軌跡相似的車輛對目標車輛的空值數據段進行填充。協同過濾[20]的核心思想是用向量描述用戶的歷史信息,然后計算用戶之間的相似性,再通過與目標用戶相似性較高的鄰居對其產品的評價,從而得到目標用戶對特定產品的潛在需求程度,系統根據計算到的結果進行針對性推薦。將協同過濾的思想用到車聯網數據填充上,關鍵是對車輛之間的相似性進行計算。針對傳感器故障等問題導致大量數據丟失的問題,本文提出一種基于路網匹配的時空性協同過濾數據填充方法。
假設vi在t到之間的特征需要進行填充,時刻vi的鄰近節點集為

vi與在時刻的相似度為

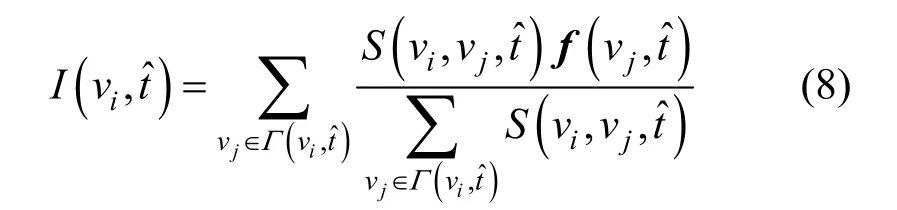
3.3 基于特征壓縮的時空數據降維
1) 特征無量綱轉化
假設f(vi,t)中的第j個特征為fj(vi,t),使用max-min 方法將fj(vi,t)縮放至[0,1],即

2) 基于主成分分析的特征降維
假設所有車輛在t時刻的特征為,其協方差矩陣為


將車輛特征向量與協方差矩陣特征向量相乘后,選擇值最大的m個維度作為車輛的特征向量,即可實現特征降維。
3.4 基于張量因子聚合的神經網絡構建
張量神經網絡[21]結合了單層模型和潛在因子模型,是一種將兩者特點結合在一起擴展產生的模型。數據抽取過程及基于張量因子聚合的神經網絡結構如圖1 所示。
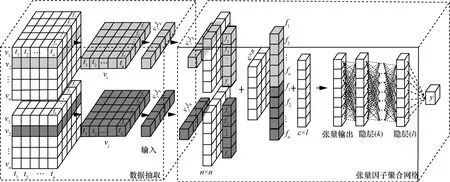
圖1 數據抽取過程及基于張量因子聚合的神經網絡結構
通過改進張量神經網絡,給出適用于車聯網的張量因子聚合層,張量因子聚合的輸出為

基于張量因子聚合構建神經網絡,用于預測車輛之間的連通強度,其目標函數為

對時空數據去噪、填充和降維后,整合存儲為訓練數據集。使用訓練數據集和梯度下降優化目標函數,通過梯度下降迭代求解目標函數,得到最小化的目標函數和基于張量因子聚合的神經網絡的參數值。
4 城市場景中車聯網通達性
4.1 相關定義
定義3一個路邊基礎設施ul覆蓋范圍內的車聯網可表示為

定義4的拉普拉斯矩陣為

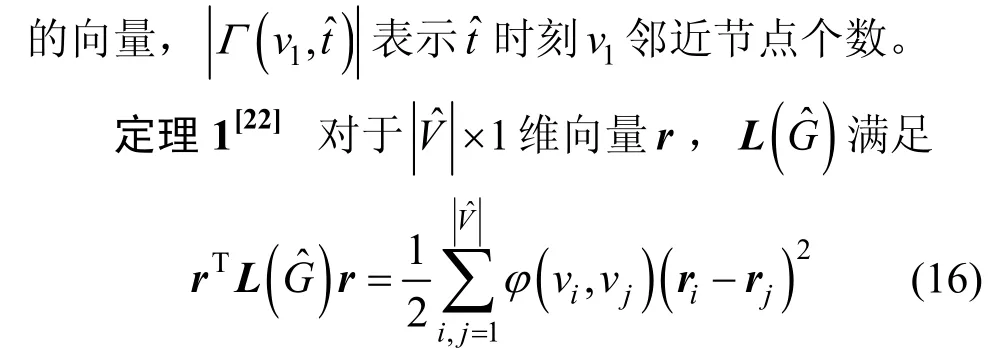
4.2 基于拉普拉斯矩陣的弱連接檢測

所以,最小化特征值z并找到其對應的特征向量即可找到車聯網中的弱連接。根據之前提到的性質,的最小特征值z對應特征向量為→。根據Rayleign-Ritz 理論[22],不符合→條件,故取第二小特征值。如果將劃分為l組,則變成取前l個特征值及其特征向量。
小班化教學給實踐活動提供了極大的便利,教師要在實踐活動中關注學困生,通過實踐活動磨煉學困生的意志,陶冶學困生的情操,為學困生的成長提供廣闊的天地。很多學困生雖然學習成績不佳,但是他們的實踐能力較強,在實踐活動中十分活躍。教師應縮短與學困生的心理距離,鼓勵他們積極參與實踐活動,在潛移默化中向學生滲透學習思想和道德品質等。聯系生活實際,講述學科知識在實際生活中的應用,為學困生創設與教學資料有關的情境,引發他們的好奇與思考。同時,分層活動是幫助學困生體驗成功的有效方法,可開展分層學科競賽,達到人人都有發展的目的。
4.3 連通候選節點集構建
弱連接檢測可以發現車聯網中容易斷開的邊。為了解決弱連接檢測的邊斷開而導致整個網絡出現不連通的問題,本文提出一種連通候選節點集構建方法。首先,給出當前不連通的2 個車輛在未來時刻可能連通的度量方法,即

其中,Γmax表示車輛鄰近節點的最大個數。
在弱連接檢測的邊斷開后,一個路邊基礎設施下的車聯網劃分為若干不連通的子網,從不連通的子網中選擇最大的2 個節點作為連通候選節點。
4.4 基于啟發式搜索的通達性算法
本節給出一種基于啟發式搜索的通達性(HA,heuristic-search-based accessibility)算法,在通達性路徑搜索過程中,消耗函數、未完成度函數和評價函數分別為

其中,C(P) 表示消耗函數,B(P) 表示未完成度函數,K(P) 表示評價函數,P表示連通路徑,表示連通路徑的最后一個路段與數據接收節點所處路段之間的距離。
HA 算法的具體過程如算法1 所示。首先,遍歷數據發送節點周圍的連通候選節點,若它周圍沒有連通候選節點,則使用路邊基礎設施進行數據轉發(步驟5)~步驟6));否則,將連通候選節點加入連通路徑集合(步驟7)~步驟8))。然后,重復選擇連通路徑集合中的節點,使用評價函數選擇連通路徑的下一跳節點(步驟11)~步驟21))。最后,基于連通路徑集合構建發送節點到接收節點的連通路徑(步驟23)~步驟26))。
算法1HA 算法
輸入發送節點v1,接收節點v2


5 仿真實驗與結果分析
5.1 仿真實驗環境
仿真實驗采用NGSIM 項目采集的數據集[23]。該數據收集位于美國加利福尼亞州洛杉磯的Lankershim Boulevard 路段的車輛行駛軌跡數據。仿真實驗使用2005 年6 月16 日8:28—8:45 時間段的車輛及道路信息。仿真實驗參數如表1 所示。

表1 仿真實驗參數
5.2 時空數據分析仿真實驗結果
為了評價車聯網時空數據分析方法,本文對比了使用原始數據與處理后數據的網絡性能。從傳統反向傳播(BP,back propagation)神經網絡和基于張量因子聚合的神經網絡的數據體積、平均錯誤率、訓練速度3 個指標進行評價,結果分別如圖2和圖3 所示。與使用原始數據相比,BP 神經網絡使用處理后的數據可以降低18%的數據體積和21%的平均錯誤率。在對比神經網絡訓練速度時,保持網絡的優化方法、學習率、批處理規模等參數不變,對比神經網絡使用原始數據與處理后數據的訓練速度。由圖2 可知,BP 神經網絡使用處理后的數據可以提高12%的訓練速度。與使用原始數據相比,基于張量因子聚合的神經網絡使用處理后的數據可以降低20%的數據體積和30%的平均錯誤率,可以提高40%的訓練速度。

圖2 時空數據處理前后BP 神經網絡的性能對比

圖3 時空數據處理前后基于張量因子聚合的神經網絡的性能對比
基于張量因子聚合的神經網絡輸出2 個車輛之間的連通強度,1 000 對車輛的誤差分布如圖4 所示。橫坐標表示連通強度預測值與實際樣本值的誤差,縱坐標表示落在相應誤差范圍內的樣本占比。可以看出,基于張量因子聚合的神經網絡在測試集實驗結果中,有81%的輸出結果誤差在10%內,90%的結果誤差小于20%。

圖4 誤差分布
5.3 車聯網通達性方法仿真實驗結果
圖5 展示了路段劃分方法。圖6 展示了路網中車輛數目變化情況,橫坐標為時間,縱坐標為車輛數目。由圖6 可知,車輛數目在30~100 輛波動。圖7 展示了不同路段車輛數目變化。由圖7可知,不同路段之間車輛分布不均勻,同一路段不同時刻的車輛數目變化也非常大。圖8 展示了不同路段車輛密度變化。由圖8 可知,車輛分布是不均勻的。

圖5 Lankershim Boulevard 路段

圖6 路網中車輛數目變化

圖7 不同路段車輛數目變化

圖8 不同路段車輛密度變化
為了評價本文所提出的車聯網通達性方法,本節對比了貪婪周邊無狀態路由(GPSR,greedy perimeter stateless routing)算法[24-26]和路邊基礎設施轉發(RT,RSU transmission)算法。在RT 算法中,一個路邊基礎設施負責轉發其覆蓋范圍內車輛的數據,而車輛間不直接通信。
仿真實驗選取路段3 車輛數目變化最頻繁的200 s 數據。弱連接檢測的準確性如圖9 所示。不同時間的車輛連通數目如圖10 所示。3 種通達性算法中車輛之間的平均時延如圖11 所示。

圖9 弱連接檢測準確率

圖10 連通數目

圖11 平均時延
HA 算法的弱連接檢測準確率和平均時延成反相關,即弱連接檢測準確率越高,平均時延越低。弱連接檢測后連通候選節點集構建可以減少由于連接斷開導致網絡割裂,進而解決車輛依賴路邊基礎設施進行數據中轉導致時延上升的問題。
由圖10 和圖11 可知,HA 算法和GPSR 算法的平均時延在某些情況下高于直接利用路邊基礎設施轉發的RT 算法。然而,路邊基礎設施帶寬有限,當車輛所需帶寬大于路邊基礎設施帶寬時,路邊基礎設施不能為所有車輛提供數據轉發服務。因為HA 算法考慮了車輛之間的連通強度,能夠檢測弱連接并構建連通候選節點集,避免了因為車輛間連接斷開所造成的路邊基礎設施重新調度及通信帶來的時延,因此HA 算法效果要優于GPSR 算法。
6 結束語
本文研究了城市場景中車聯網時空數據分析及其通達性方法,提出了基于噪聲去除和數據填充的時空數據分析方法,構建了基于張量因子聚合的神經網絡預測車輛之間的連通強度;提出了基于連通強度預測的車聯網通達性方法。仿真結果表明,本文所提出的車聯網時空數據分析及其通達性方法具有較好的性能。
