半監督學習的微博謠言檢測分析
2021-07-19 09:37:16陳耿黃取治
電腦知識與技術 2021年15期
陳耿 黃取治

摘要:謠言檢測是社交網絡謠言研究、監測及整治的基礎,其實施情況得到社會的廣泛關注,相伴隨的是微博謠言辨識的研究工作不斷增多。該文把微博謠言作為研究對象,搭建了微博謠言的檢測框架,其主要是由獲取數據、處理數據及謠言檢測三大步驟構成,基于實驗研究過程,對比了差異化數據已標注比例時不同半監督學習的性能和ImCo-Forest算法之間的差異,發現ImCo-Forest在謠言檢測方面更占優勢。希望能和同行共同分享方法與經驗,以期進一步完善微博謠言檢測工作。
關鍵詞:微博謠言;半監督學習;ImCo-Forest算法;謠言檢測系統
中圖分類號:TP311? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)15-0012-02
1 背景
微博憑借自身在即時性、匿名性、廣泛性等方面占據的優勢,從根本上扭轉了傳統媒介下信息傳播的樣態,塑造了去中心化的傳播局勢,成為傳播社會輿論的新載體。
微博平臺上每次只能發布長度為140字符的文字信息,其不具有完整闡述事實的功能,外加微博用戶的草根性,使微博逐漸成為聚集、散播謠言的載體,頻繁轉播、評論虛假信息,不斷拓展負面影響的范圍,使用用戶主觀上生成強烈的“信任危機感”,不利于社會的和諧、平穩發展。謠言檢測隸屬于網絡信息可信度研究的范圍,微博謠言檢測能凈化微博平臺環境,引導平臺健康運作發展,創造出更大的效益。
2 背景分析
微博是現代生活中的一種常用社交網絡平臺,廣大用戶可以利用瀏覽器、智能手機及他類智能聯網的客戶端傳送信息,進而達到分享即時信息的目的。謠言是作為一種特別的語言現象,長期以來是人們關注與研究的熱點之一。伴隨新媒體網絡的蓬勃發展,網絡謠言隨之產生與流傳,在社會上形成較大的影響。近些年中,因微博謠言泛濫引起的危害,使各級政府及學術領域對此給予高度重視,為對虛假話題傳播過程形成抑制,我國政府頒發了相應的懲處法規,針對網絡謠言制造及傳播者,公安機關加大了打擊力度。以上這些治理措施的實施,對維持微博傳播秩序有很大助益,明顯減少了微博謠言。通過觀察謠言數據,不難發現微博內的謠言數目明顯少于非謠言,精準辨識謠言具有很大現實意義。
3 ImCo-Forest算法
Co-Forest是聚集了集成學習算法的一種算法類型,其不僅能處理協同訓練算法中噪聲數據引進相關問題,還通過加強不同分類器之間的合作,對那些價值較高且無標記數據的預測工作發出了挑戰,強化了集成學習算法的分類功能。
半監督學習算法ImCo-Forest就是以Co-Forest算法為基礎提出的,應用該算法的目的需要是通過優化集中訓練中少數類的分布狀態,將偏高的誤分類代價賦予部分感興趣的少數類,進而強化分類器的辨識能力。假定用[L={(x1,y1),……(xl,yc)}]去表示已標注的數據,[yl∈{1,……c}],[U={(x1,yu),……(xj,yu)}]表示沒有標注數據,且有l 該算法應用階段,針對添加的新標記數據的數據集,應用了以正負類為基礎形成的分層抽樣法進行抽樣操作,借此方式使類別平衡性得到更大保障,規避了由于樣本選擇不恰當而引起的分類性能逐漸惡化的問題。 4 檢測框架 從宏觀層面上,可以將微博謠言檢測細化為數據獲得、數據處置及謠言檢測三步驟,本文搭建的微博謠言檢測框架見圖1所示[2]。 4.1 數據獲得 參照新浪微博官方對外發布的數據,到2017年年末時,新浪微博月活躍、日活躍用戶分別是3.92億、1.65億,為現階段國內應用用戶數目最多、社會影響力最大的微博平臺類型。本課題選擇新浪微博作為研究對象去分析謠言檢測相關問題。通過觀察新浪微博的信息結構,不難發現用戶個人信息、微博文案及傳播信息是一條微博的主要構成。獲得數據是謠言檢測的基礎,以新浪API為基礎的數據獲取方法是常用手段之一,流程可以做出如下概述:首先,創建賬號與運用獲得研發者身份,能獲取專屬型的App Key與App Secret;其次,開發者將授權請求傳送到授權地址,基于OAuth2.0認證過程誘導Request Token授權返回過程,在確認授權成功以后,開發者再獲得Access Token;最后,調取使用接口,便能順利地獲取到JOSN數據流或XML文件,系統化分析后便預示著微博數據采集工作結束。利用該種方法采集數據有研發代價偏低、便于達成等優點,但官方設定的數據獲取頻次與方式會對其形成一定約束,很難保證謠言數據獲取的有效性、整體性。而相比之下,基于微博爬蟲獲取數據的方法在應用階段,能基于網絡抓包工具能構建數據請求過程與各請求URL之間的關系,獲得kie并建立session,實現模擬登陸,利用HTTP協議、GET方法去采集與分析數據。 4.2 數據處置 謠言檢測的宗旨在于從批量化的微博消息內,基于分類算法對其作出合理判斷。處理數據是計算機“理解”數據的前提,這樣方能精準辨別出微博謠言。本文把微博文本表示為向量這些適用于機器學習算法處理的數據[3]。1)過濾噪聲:去噪的目的以解除無用數據為主,這是提升后期檢測工效的基礎,具體是當微博用戶的粉絲數目在給定閾值之下時,就將其微博數據刪除。2)分詞:從本質上分析,對微博文本進行分類就是細化短文本的所屬類型,對文本進行分詞操作這是預處理階段需落實的第一要務,當下可供選擇的分詞方法較多,比如由統計學習形成的,或者以人工智能為基礎形成的分詞法等,合理使用如上方法,能將連貫的字符串序列轉變成組合式的成詞序列,并化繁為簡,獲得簡單容易處理、向量化的文本數據。3)表示向量:即參照一定的特征項,把微博文案信息轉變成特征性向量的方法,當前在該環節中多采用空間向量模型(VSM),其應用思想可以做出如下表述:將文本視為無序詞與其相對應權重的集合體,統一映射至高維空間內,具體操作是把文案內的各詞項作為唯一屬性用t1表示,測算出文檔內各詞項的重要程度進而獲取到權重W1,那么便可以將一個文檔表示成例如(t1,W1;t2,W2;……tn,Wn)的向量形式,而后通過測算文本相似度去對不同內容之間的相關性作出科學判斷。
4.3 選擇微博特征
這是謠言檢測過程中的關鍵一環,影響著檢測效果,當下國內外針對微博謠言檢測的研究主要聚集在選擇分類特征方面。也有人員通過系統分析與科學實驗過程獲取到文本的基本特征,即內容特征、用戶屬性信息與傳播特征,希望據此能提升微博謠言檢測效率,本文以此為基礎,從多個維度分析微博謠言的特點,構建出用于檢測微博謠言的特征向量集合[4]。1)內容特征:是微博消息內的統計特征,可以將其看成是微博內容的延展信息或不同用戶交流中形成的信息,影響著文本的可信度。2)用戶特征:由是否認證、注冊時間、微博數等構成,其呈現出的是廣大微博用戶自身的權威性與影響力。3)傳播特征:看中的主要是用戶上傳的文本信息的轉發及評論數,這種特征主要是能表現出該用戶對其他網絡用戶產生的影響力。
5 實證檢驗
5.1 實驗步驟
1)獲取和標注數據:把官方的辟謠信息及網絡材料作為憑據,選擇5895條微博并進行人工標注處理。
2)提獲特征:在該操作之前需要對獲得的微博數據進行預處理,宗旨在于盡量解除噪聲數據,將無用數據對后續檢測工作形成的負面影響降至最低。具體是刪減到粉絲數<5的用戶信息。預處理后參照特征去提獲數據,構建出微博文本數據的特征向量[5]。
3)鑒于ImCo-Forest算法在微博謠言檢測領域中表現出的有效性,擬定于WEKA平臺上開展謠言檢測的實驗研究。針對各個數據集,通過十折交叉驗證進行測評,把已標注及未標注集作為檢測算法的輸入項,對分類器進行規范訓練后于測試集上進行檢測,獲得真正例、假負例、假正例及真負例。
5.2 實驗結果
比較了不同數據已標注比例時不同半監督學習的性能和ImCo-Forest算法。對比分析后發現,和其他半監督學習算法相比較,在已標注比例下ImCo-Forest算法的F-measure值和G-mean值更高,這表明ImCo-Forest算法在檢測微博謠言方面優越性更大。并且通過讀圖發現,在已標注數據占比達到40%時Co-Forest算法的性能最優,當數據占比為60%、80%時算法的性能卻有降低趨勢,這主要是由Co-Forest算法自身的特點決定的,與既往很多研究形成的結論一致。
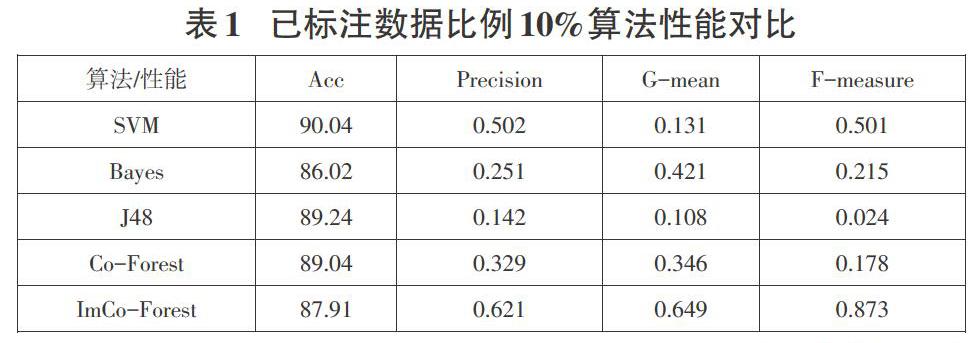
為了能進一步證實本文所設計的ImCo-Forest算法和現有研究所應用的監督學習算法更占據優勢,本文基于L[?]U,在μ=0%狀態對應的數據集上對SVM、Bayes和J48分類器進行系統化訓練,將他們和已經標注數據比例為10%情景下的ImCo-Forest算法持有的性能進行對比分析,選擇了“少女遭毀容”語料,統計了評價指標,實驗結果見表1[6]。
對表1內的數據進行比較分析,不難發現在"少女遭毀容"語料上,ImCo-Forest算法的與F-measure指標都較好,提示該種算法在處理非平衡數據問題方面和其他算法相比較表現出較好效能。在這里需另外關注的問題是,SVM算法盡管在整體準確率指標上相對較高,達到了90.04%,但其G-mean和F-measure指標數值均處于較低的水平,提示該算法對少數類的辨識性能偏差,說明其不能精準辨識出微博謠言[7]。
還需要關注的內容是,本次實驗中對選用的三種監督學習算法均采用了100%完全性標注的理想化數據集進行訓練,統計結果后發現,在整體準確率指標上,只有SVM、J48算法比ImCo-Forest更優秀,提示為了獲得相對較高的總體準確率,和ImCo-Forest算法相比較,其他算法需要數目更龐大的標注數據,這在很大程度上削弱了其在現實運用領域中的可執行性。
6 結束語
綜合分析以上實驗過程產出的結果,可以認定ImCo-Forest算法能在標注數據少量的情景下,較好的檢測出謠言,這樣便能在微博謠言辨識階段明顯減少數據標注過程中付出的代價。但是回顧研究歷程,筆者自知還存在著一定不足,比如沒有考慮到微博文本語義等因素形成的影響,故而后續工作中應重視專研分析語義特征、傳播過程中用戶主體行為對信息可信度形成的影響,參照語義技術拓展對微博文本特征挖掘的深度性,借此方式進一步提升半監督學習算法在檢測微博謠言方面的精準度,將自身價值發揮到最大化。
參考文獻:
[1] 劉彤,魏靜,倪維健,等.基于半監督學習與CRF的應急預案命名實體識別[J].軟件導刊,2020,19(3):35-38.
[2] 馮雨庭,張錦,肖斌.基于半監督SVM的交通方式特征分析和識別[J].綜合運輸,2019,41(9):57-63.
[3] 金志剛,楊洋.基于用戶關聯度的半監督情感分析模型[J].哈爾濱工業大學學報,2019,51(5):50-56.
[4] 董哲瑾,王健,錢凌飛,等.一種用戶成長性畫像的建模方法[J].山東大學學報(理學版),2019,54(3):38-45.
[5] 陳珂,黎樹俊,謝博.基于半監督學習的微博情感分析[J].計算機與數字工程,2018,46(9):1850-1855.
[6] 李澤魁,李雪婷,趙妍妍.中文微博熱點事件情感分布的原因分析[J].中文信息學報,2018,32(1):131-138.
[7] 劉桂鋒,汪滿容,劉海軍.基于概率超圖半監督學習的專利文本分類方法研究[J].情報雜志,2016,35(9):187-191,173.
【通聯編輯:謝媛媛】
