基于級聯(lián)卷積網(wǎng)絡的紅外圖像超分辨率重建
2021-07-20 00:04:50甄有恒
現(xiàn)代計算機 2021年15期
甄有恒
(1.四川大學計算機學院,成都610065;2.中國人民解放軍95876部隊,張掖)
0 引言
紅外成像技術利用目標熱源信息差生成圖像空間數(shù)值,能夠有效克服可見光圖像無法實現(xiàn)穿透檢測的缺陷,已經(jīng)在軍事、工業(yè)、遙感、醫(yī)學等領域有著廣泛應用。然而,受紅外傳感器工藝限制,紅外成像質(zhì)量明顯低于可見光成像,主要表現(xiàn)在成像分辨率低以及各類非均勻性噪聲顯著[1]。因此,提升紅外圖像分辨率具有重要的應用價值。面對硬件性能研發(fā)困難的問題,算法設計更能節(jié)約研發(fā)成本。
圖像超分辨率重建是圖像退化的反過程,其本質(zhì)是回歸問題[2]。從機器學習過程看,超分辨率重建方法可以分為人工傳授、自主學習和半自主學習3種形式。人工傳授基于傳統(tǒng)算法模型設計,需要扎實的學科理論基礎,但是設計過程需要具備豐富的圖像處理先驗知識;自主學習形式以深度學習為典型代表,依靠高維復雜的映射函數(shù)實現(xiàn)端到端的學習,但是往往需要高算力和海量數(shù)據(jù)。半自主學習形式融合人工傳授和自主學習兩種形式的優(yōu)點,通常采用傳統(tǒng)算法優(yōu)化輸入端,然后再自主映射學習,但是對模型設計能力要求高。
利用深度學習技術實現(xiàn)圖像超分辨率重建的模型中,基于重構(gòu)[3]、殘差[4-5]、生成對抗[6]等的卷積神經(jīng)網(wǎng)絡方法處理可見光圖像效果明顯。受此啟發(fā),文獻[7]首次將卷積神經(jīng)網(wǎng)絡用于紅外圖像增強處理,采用4層網(wǎng)絡對圖像進行端到端的重構(gòu)。文獻[8]對MNIST數(shù)據(jù)集進行伽馬變換和高斯濾波方法實現(xiàn)紅外數(shù)據(jù)仿真,利用多尺寸卷積核提取不同規(guī)模特征來實現(xiàn)增強對比度、突出紅外弱小目標和抑制背景雜波。以上兩種方法均采用小型網(wǎng)絡結(jié)構(gòu),有利于低運算量條件下的部署,但是網(wǎng)絡層數(shù)太淺導致模型對特征的非線性映射能力變得較差,無法提取更高頻的紅外圖像特征信息。文獻[9]在可見光圖像亮度域完成特征提取、映射和重建過程的模型訓練,通過遷移學習將訓練模型用于初始化紅外測試模型。
以上方法均取得了一定的效果,但是在高倍數(shù)重建任務中,網(wǎng)絡模型缺少從低頻特征向高頻特征的信息補充,對細節(jié)特征的處理能力較低。因此,本文在VDSR網(wǎng)絡模型基礎上進行改進,提出一種級聯(lián)重建網(wǎng)絡模型CCNSR(Cascaded Convolutional Network for Super-Resolution)學習全局殘差特征。該模型第一級網(wǎng)絡利用卷積和反卷積操作進行編解碼學習,第二級網(wǎng)絡對編解碼后的特征圖進行遞歸殘差學習,兩個網(wǎng)絡級聯(lián)后,利用全局跳躍連接使得兩級網(wǎng)絡學習端到端的整體殘差。實驗驗證了本文模型在VDSR模型基礎上的改進效果,同時,對其他模型進行性能分析。
1 本文方法
1.1 問題描述
設ILR表示紅外低分辨率圖像,IHR表示高分辨率圖像,ISR表示重建圖像。重建模型描述如下:

其中ILR表示低分辨率圖像,ISR表示超分辨率重建圖像,(F)表示重構(gòu)映射函數(shù),υ表示(F)的參數(shù)集。
全局殘差學習的主要優(yōu)勢在于:網(wǎng)絡模型只需要學習輸入輸出之間的殘差信息,充分利用殘差特征的稀疏性用以實現(xiàn)訓練過程的快速收斂。殘差學習模型描述如下:

其中(R)表示殘差映射函數(shù),ω表示殘差映射參數(shù)集。
模型目標函數(shù)如下:
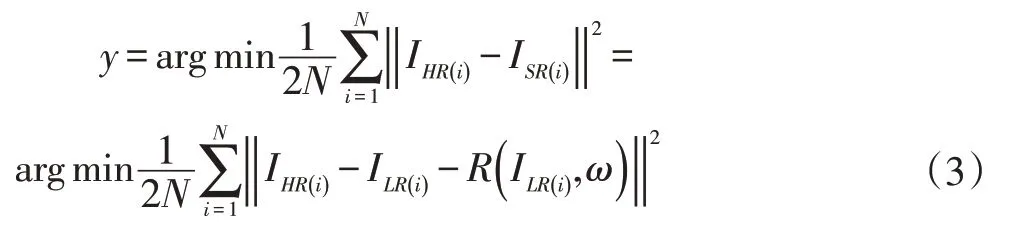
其中N表示樣本容量,通過對參數(shù)集ω的迭代訓練,達到殘差學習模型優(yōu)化的目的。
1.2 網(wǎng)絡結(jié)構(gòu)
本文前饋卷積神經(jīng)網(wǎng)絡結(jié)構(gòu)主要由編解碼子網(wǎng)絡和遞歸殘差子網(wǎng)絡級聯(lián)組成。網(wǎng)絡結(jié)構(gòu)及流程見圖1。

圖1 CCNSR網(wǎng)絡結(jié)構(gòu)及流程圖
編解碼子網(wǎng)絡的設計主要參照UNet模型[10]。該模型在圖像語義分割中有很好的表現(xiàn),有利于快速提取圖像輪廓特征。編解碼結(jié)構(gòu)設計中需要計算卷積操作后的特征圖尺寸,其計算公式:

其中K表示卷積核尺寸,P表示邊緣填充數(shù),S表示卷積核步長;Fx表示卷積前的特征圖尺寸,F(xiàn)y表示卷積后的特征圖尺寸,表示向下取整。反卷積計算公式如下:

在網(wǎng)絡內(nèi)部,卷積核和反卷積核參數(shù)均設為K=3,S=1,P=0。對稱設置確保了特征圖先降采樣后升采樣的編解碼功能。子網(wǎng)絡首位兩端跳躍連接確保了低語義局部殘差特征的快速學習。
遞歸殘差子網(wǎng)絡受DRRN模型[5]啟發(fā),在編解碼子網(wǎng)絡提取的初級殘差特征基礎上深度提取高頻殘差信息。該子網(wǎng)絡內(nèi)部全部采用卷積操作,卷積核統(tǒng)一設為K=3,S=1,P=1,用以保證特征圖在輸入輸出前后始終保持一致。遞歸跳躍連接實現(xiàn)低頻殘差特征逐步向高頻殘差特征做補充,同時豐富的連接數(shù)量有利于反向傳播梯度更新。文獻[11]解釋了批量正則化層(Batch Normalization,BN)對重建任務較為敏感,因此本文去除BN層。同時,取消遞歸部分連續(xù)三層卷積中最后一層的傳遞函數(shù),用以消除網(wǎng)絡結(jié)構(gòu)冗余。
另外,除了兩級子網(wǎng)絡特征融合層卷積核數(shù)量設為1,其余層卷積核數(shù)量均設為15。激活函數(shù)統(tǒng)一采用Leaky ReLU函數(shù),特點是在ReLU激活函數(shù)基礎上對負向輸出添加激勵因子λ,適度更新神經(jīng)元抑制參數(shù)。
1.3 損失函數(shù)和優(yōu)化
本文采用L2損失函數(shù)用以最小化圖像均方誤差。定義如下:
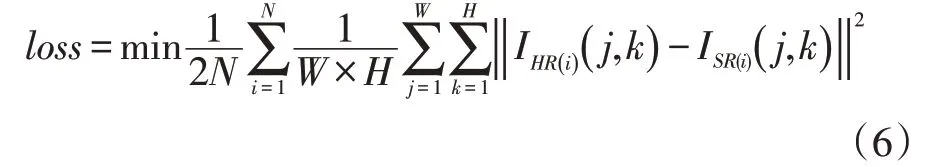
其中W、H分別表示單個樣本的寬和高,I(i)(j,k)Ii(j,k)表示圖像某像素點的值。
參數(shù)優(yōu)化采用目前主流的Adam算法[12],其在梯度更新方向和更新幅度方面很好的做到了自適應性。更新公式如下:
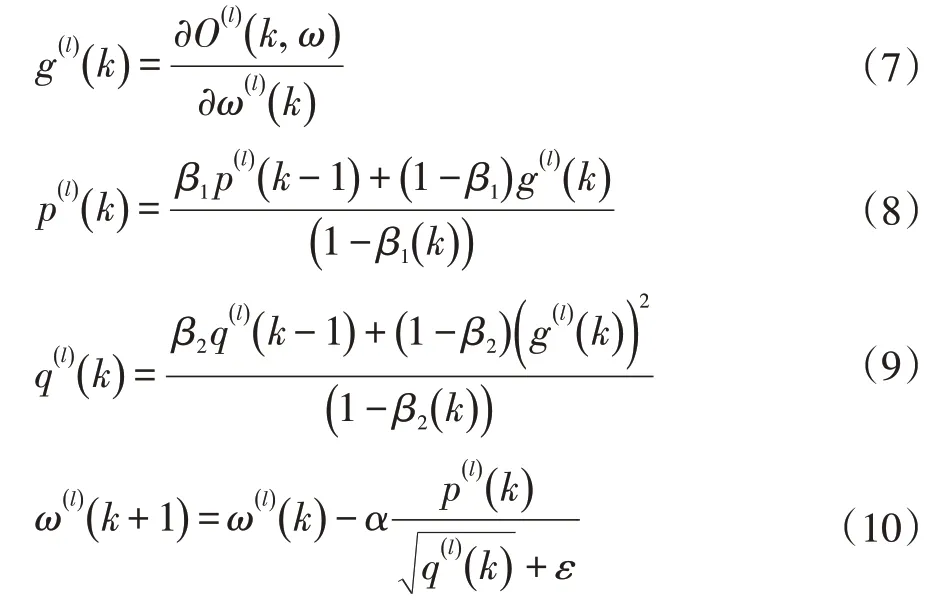
其中l(wèi)表示網(wǎng)絡層序號,k表示迭代次數(shù),α表示學習率,β1(k)、β2(k)表示學習率衰減參數(shù)。
在式(7)中,O(l)(k,ω)表示從輸入層到第l層的映射函數(shù),ω(l)(k)表示第l層參數(shù),g(l)(k)表示迭代計算到k次時O(l)(k,ω) 的梯度,并且當l為輸出層時,O(l)(k,ω)=loss;式(8)表示帶有動量的梯度下降迭代計算,用于控制梯度更新的方向,式(9)表示均方根梯度下降迭代計算,用于控制梯度更新的幅度。式(8)、式(9)分母用于修正數(shù)值;式(10)利用式(8)和式(9)調(diào)整后的新梯度進行權(quán)值參數(shù)更新。根號是對式(9)中各維度的梯度分別求平方根,ε保持分母數(shù)值穩(wěn)定。
2 實驗與結(jié)果
2.1 數(shù)據(jù)集
鑒于可見光圖像集訓練紅外圖像超分辨率重建模型的方法較為成熟[7-9],本文采用General-100[13]和Urban-100[13]兩個可見光圖像數(shù)據(jù)集,為紅外圖像提供豐富的細節(jié)特征。同時,高倍數(shù)差能夠為擬合訓練提供更高頻的殘差特征,因此設置高倍數(shù)訓練條件。
構(gòu)建訓練集,首先對數(shù)據(jù)集進行數(shù)據(jù)增強處理,得到1600張圖像,并分割成32×32的圖像塊;然后,利用雙三次插值(Bicubic)對原始高分辨率圖像進行8倍降采樣和升采樣,得到相同尺寸的低分辨率圖像;最后,配對圖像塊后構(gòu)成高-低分辨率訓練集。測試集取自公開的LTIR紅外數(shù)據(jù)集[14]和FLIR熱紅外數(shù)據(jù)集[15],共隨機挑選24張圖像,測試集組成方法同訓練集。
2.2 評價指標
下面介紹兩種常用的評價指標:
峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)從全局衡量圖像重建效果。峰值信噪比公式如下:
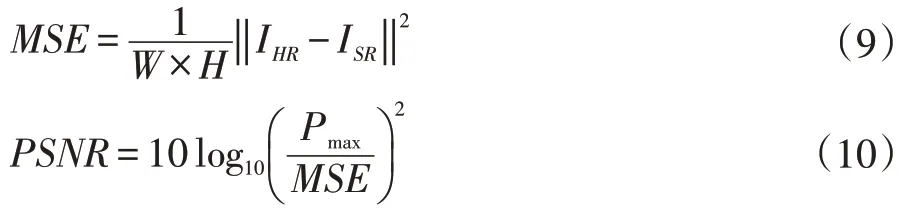
其中MSE表示均方誤差,Pmax表示圖像像素最大值,對于8位圖像取Pmax=255;PSNR值越高,圖像重建質(zhì)量越好。
結(jié)構(gòu)相似性(Structural SIMilarity,SSIM)[16]基于人眼視覺感受,從圖像亮度、對比度和結(jié)構(gòu)三個方面全面評價圖像整體復原質(zhì)量。SSIM值處于0到1之間,越接近1越好.結(jié)構(gòu)相似性公式如下:
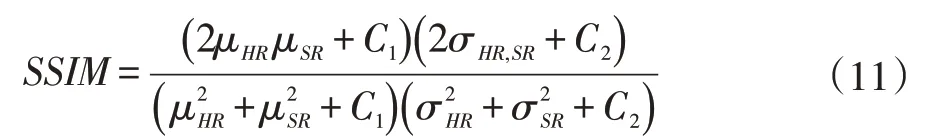
其中μHR表示IHR的平均像素強度;μSR表示ISR的平均像素強度;σHR表示IHR的像素標準差;σSR表示ISR的像素標準差;σHR,SR表示協(xié)方差;C1、C2取常數(shù)用于穩(wěn)定分母。
2.3 實驗流程
本文采用Caffe深度學習框架下的CPU訓練模式,借助MATLAB和MatConvNet對實驗結(jié)果進行分析。選取TEN、VDSR和DRRN三種典型超分辨率重建模型進行對照實驗,具體操作如下:
(1)按照網(wǎng)絡結(jié)構(gòu)編寫*.prototxt文件,將訓練batch_size設為128,測試batch_size設為2,數(shù)據(jù)集保存成HDF5數(shù)據(jù)格式。
(2)編寫Caffe網(wǎng)絡訓練配置*_solver.prototxt文件并初始化訓練參數(shù)。卷積層權(quán)值參數(shù)初始化采用MSRA方法,初始學習率α=10-4,Leaky ReLU激活函數(shù)負向激勵因子λ=0.2。參數(shù)優(yōu)化選擇Adam方法,其中學習率衰減參數(shù)β1=0.9、β2=0.999,衰減系數(shù)ε=10-8,最大迭代訓練次數(shù)Iteration=50000。
(3)訓練模型,迭代訓練50000次后讀取Blobs數(shù)據(jù)塊并保存權(quán)值參數(shù)。輸入測試集,使用MatConvNet框架讀取訓練好的權(quán)值參數(shù)并按照前饋流程生成重建圖像,計算評價指標。
(4)對TEN、VDSR和DRRN模型分別按照(1)到(3)依次操作。調(diào)整VDSR和DRRN的卷積核數(shù)量為每層15個,得到VDSR(15)和DRRN(15),用以保證實驗相對公平。
2.4 結(jié)果分析
實驗重點測試本文模型在VDSR基礎上改進后的性能提升,并對實驗中各個模型的網(wǎng)絡結(jié)構(gòu)屬性進行了相關統(tǒng)計,見表1。
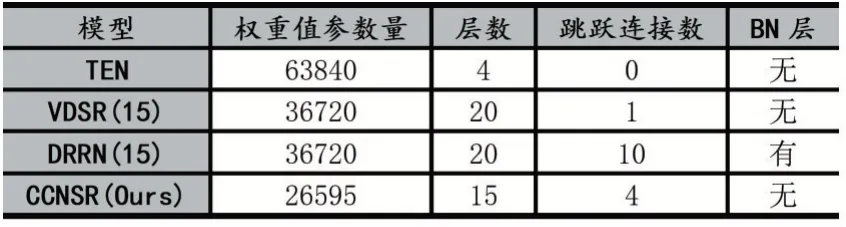
表1 各模型網(wǎng)絡結(jié)構(gòu)主要參數(shù)
其中TEN是基于重構(gòu)的紅外圖像超分辨率重建代表模型;VDSR算法是本文方法的模型基礎;DRRN算法用于驗證BN層對重建任務的影響。本文模型的網(wǎng)絡權(quán)值參數(shù)量是TEN的42%,是VDSR(15)和DRRN(15)的72%,網(wǎng)絡結(jié)構(gòu)參數(shù)量少。
實驗分別對兩組測試集進行測試,分別得到4倍和8倍放大倍數(shù)下的平均評價指標值,統(tǒng)計結(jié)果見表2,其中橫向最優(yōu)值加粗顯示。圖2、圖3分別表示對應重建倍數(shù)的性能變化曲線。
由表2統(tǒng)計數(shù)據(jù),結(jié)合圖2、圖3曲線分析可以得出:①本文方法在參數(shù)量減少的訓練條件下,擬合PSNR和SSIM比VDSR模型稍有提升,但是在泛化能力上表現(xiàn)不足,這與編解碼子網(wǎng)絡中的卷積和反卷積操作過多有關,使得邊緣分割嚴重。②傳統(tǒng)的雙三次差值方法和基于重構(gòu)的TEN算法對低倍數(shù)下的圖像重建效果較好,但是隨著重建倍數(shù)的上升,重構(gòu)方法的性能下降明顯;基于殘差學習的方法在不同倍數(shù)的重建任務中的影響,因此殘差學習可以有效克服對模型參數(shù)量的需求。③帶有BN層的DRRN模型在本文實驗條件下的重建能力不太突出,原因之一是訓練數(shù)據(jù)量少導致模型欠擬合,并從側(cè)面印證了添加BN層的操作不一定適用于圖像重建任務。

表2 各模型分別在4倍、8倍重建下迭代訓練50000次的平均PSNR/SSIM值
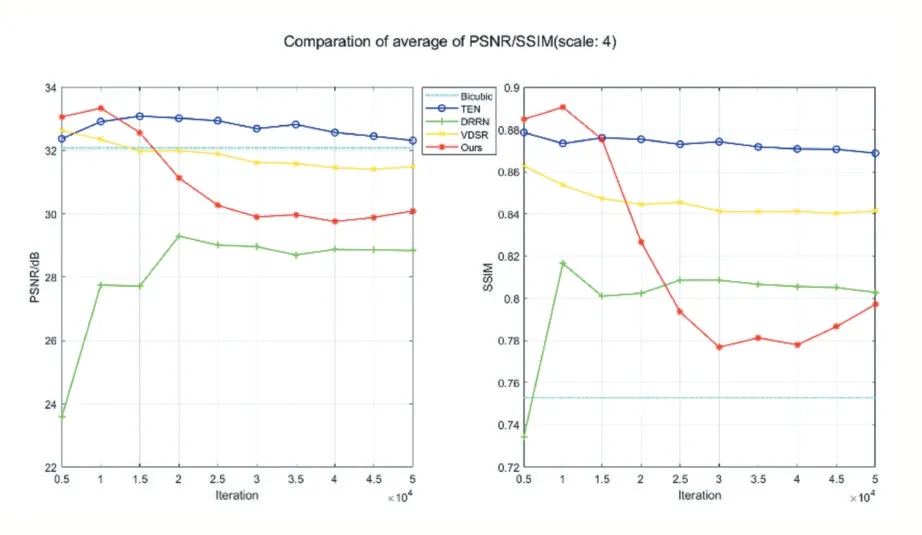
圖2 各模型對4倍重建的性能測試曲線
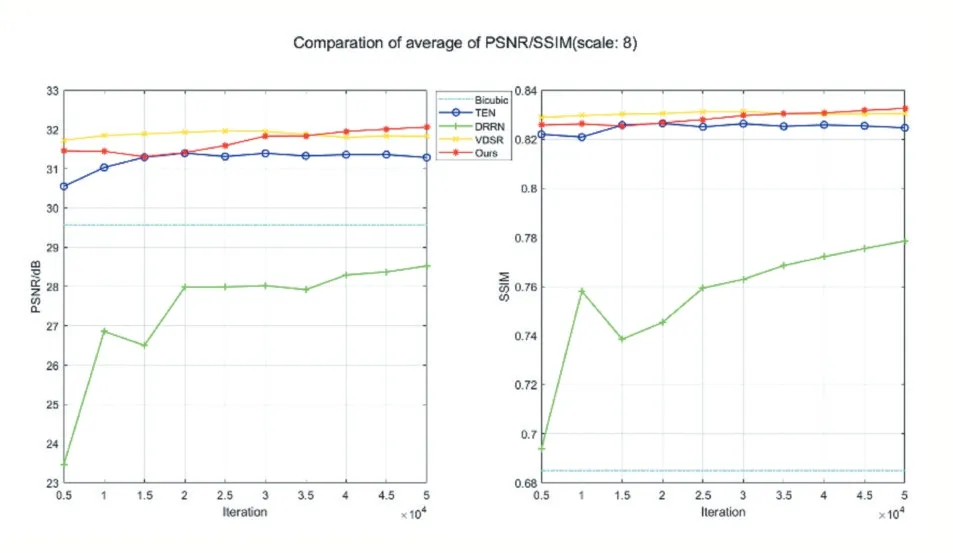
圖3 各模型對8倍重建的性能測試曲線
圖4展示了LTIR測試集中13號圖像的局部重建效果。可以看出,對于8倍重建測試,本文模型的重建效果與其他較優(yōu)模型相比性能相當;在4倍重建測試中,本文模型重建能力不太理想,說明參數(shù)量對網(wǎng)絡模型的表達能力影響明顯。
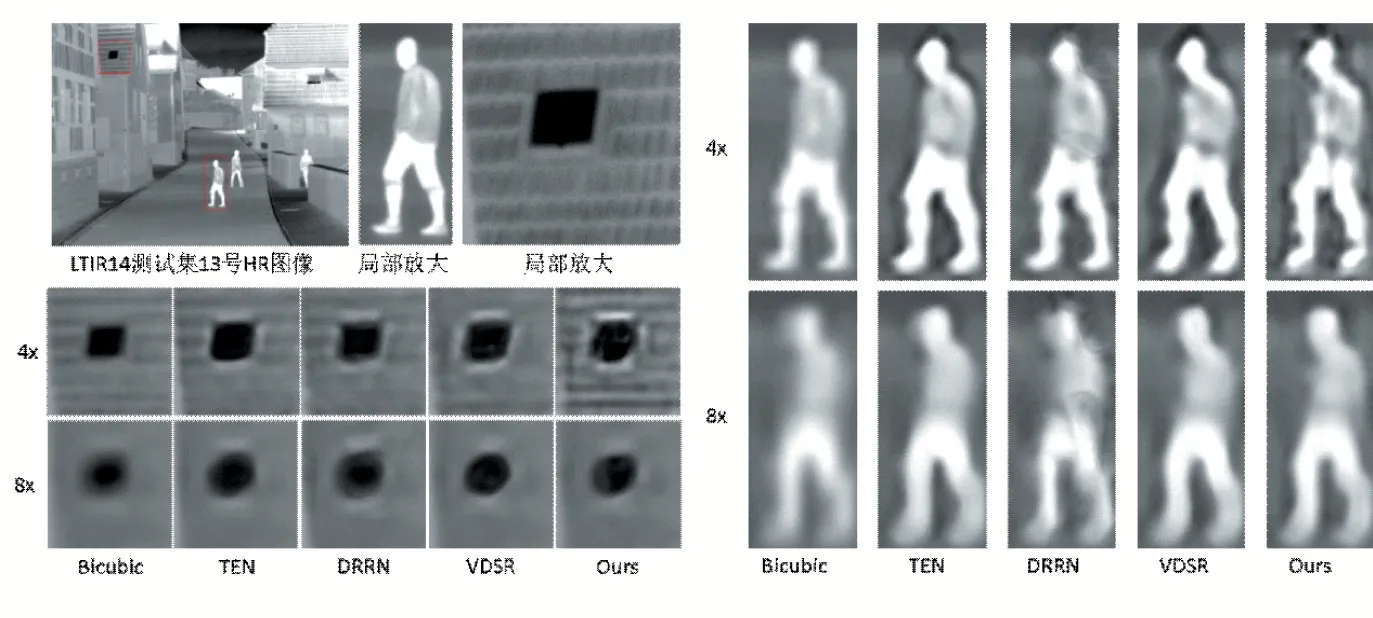
圖4 重建效果展示
3 結(jié)語
本文提出一種級聯(lián)卷積神經(jīng)網(wǎng)絡的紅外圖像超分辨率重建模型。該模型利用典型模型的優(yōu)勢,通過將整體重建任務拆分為輪廓特征重建和紋理特征重建兩部分,在VDSR模型的基礎上對網(wǎng)絡結(jié)構(gòu)進行了改進,實現(xiàn)了網(wǎng)絡結(jié)構(gòu)的優(yōu)化。實驗在低數(shù)據(jù)量訓練條件下進行,本文模型能夠在參數(shù)量較少的情況下實現(xiàn)PSNR和SSIM指標以及擬合能力的提升,達到了相應的實驗目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
