基于聯合子空間對齊與極限學習機的無監督領域自適應平臺研究
2021-07-24 07:01:58鮑靈浪
新一代信息技術 2021年1期
關鍵詞:方法
陶 洋,胡 昊,鮑靈浪
(重慶郵電大學 通信與信息工程學院,重慶 400065)
0 引言
傳統分類方法一般是從訓練樣本中學習分類模型,然后直接將其應用于測試樣本分類。當訓練樣本和測試樣本滿足獨立同分布基本假設時,分類模型可以獲得很好的分類效果[1]。但是,在實際應用中,由于各種因素(例如不同的視覺分辨率和照度)不可能保證訓練樣本始終與測試樣本具有相同的分布。當它們具有不同的分布時,獲得的模型通常會失效[2]。如圖 2顯示了不同領域下圖像之間的差異。
本文重點研究無監督領域自適應學習,更符合現實場景應用。在解決源數據與目標數據分布不均的問題方面,具體分為更改數據表示形式和修改訓練分類器方式。這兩類方式的遷移學習單獨執行的效果并不是非常理想,這是因為數據分布不同而導致的。同時在現實應用過程中的噪聲會影響分類器和遷移學習算法的穩定性,導致分類器魯棒性不佳。而且傳統的遷移學習算法僅僅是從單純的改變數據表示進行遷移進行的,而忽略了結合分類器設計,不能使得分類器參數適合領域自適應,提升遷移學習的效果。
為了克服傳統領域自適應方法的弊端,提出了一種分類器聯合子空間學習方法,該方法將數據表示遷移方法和分類器設計相結合。具體來說,首先分解極限學習機分類器輸出層權重,設計一個靈活的極限學習機分類器。然后使得輸入層具備提取共有特征的能力,在分類器的隱含層中利用子空間對齊方法將源數據和目標數據被轉換為一個公共子空間,其中每個目標數據都可以通過源域中的數據線性地重構。本文在重建矩陣上施加低秩約束,以便可以保留數據的全局結構。低秩約束的設計還確保了來自不同域的數據可以很好地交織,這有助于顯著減小域分布的差異[3]。本文同時對噪聲進行建模,用來消除噪聲對模型產生的負面影響,過濾噪聲信息[4]。所提出的方法如圖1所示。該方法稱為聯合子空間對齊與極限學習機無監督領域自適應(Joint Suspace Alignment and Extreme Learning Machine,JSAELM)。
1 極限學習機


式(1)中H∈R,g(·)為激活函數。根據最小二乘法求解極限學習機輸出層權重β的目標函數為:
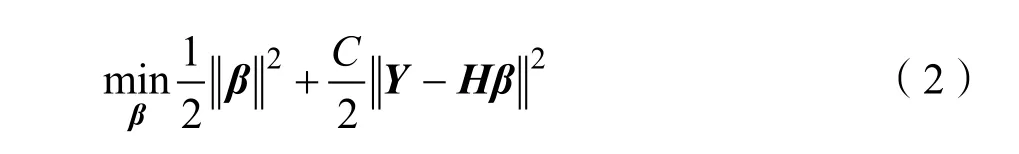
式(2)中C為預測誤差項的懲罰系數,同時為避免參數過擬合對參數β施加正則項,式(3)是經典的嶺回歸正則化最小二乘優化問題,令目標函數對β的梯度為0,可得:
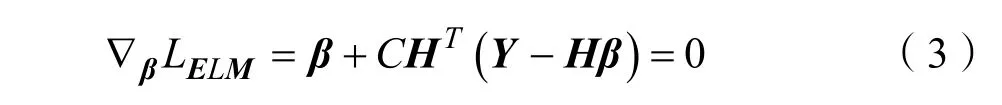
式(4)中的β可以根據Moore-Penrose廣義逆矩陣的方法得到最優解。當訓練樣本數n與隱含層神經元個數L大小不同時,求解β存在兩種情況:

2 聯合子空間對齊與極限學習機無監督領域自適應
2.1 模型結構

圖1 JSA-ELM模型結構圖Fig.1 Structure of JSA-ELM mode
2.2 ELM的領域不變隱含層權重學習
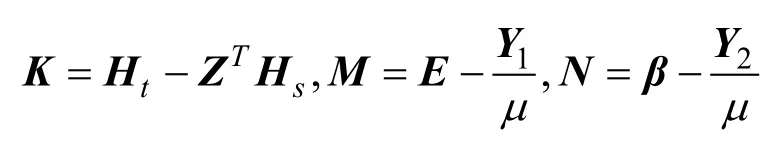
2.3 具有遷移能力的 ELM 輸出層權重學習
根據第2.2節求得的ELM的領域不變隱含層權重W可計算出源域和目標域相應的隱含層特征:

其中,g(·)表示隱含層激活函數。為進一步提升 ELM 分類器的跨領域知識遷移能力,JSA-ELM 將輸出層權重的學習過程中聯合子空間對齊方法,使得輸出層權重具有較好的遷移能力。
2.3.1 極限學習機源域分類損失
在極限學習機源域分類器學習過程中,僅有源域樣本包含標簽信息。因此,跨領域分類器參數通過帶標簽的源域樣本進行訓練。定義源域樣本數據與數據標簽為{xs, ys} ,根據第1節中的極限學習機算法,分類器輸出層權重的損失函數可表示為:

其中,Hs為源域的隱含層特征表達。為了有效的聯合子空間學習,本文采用一種更靈活方法,將輸出權重矩陣β分解為兩個矩陣β和R。因此,將式(7)轉換得到優化模型:
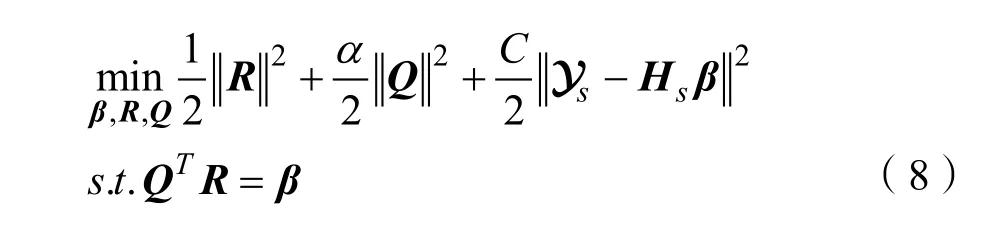
2.3.2 子空間領域對齊
本文使用低秩約束來強制 Z具有這樣的結構。因此本文可以得到:
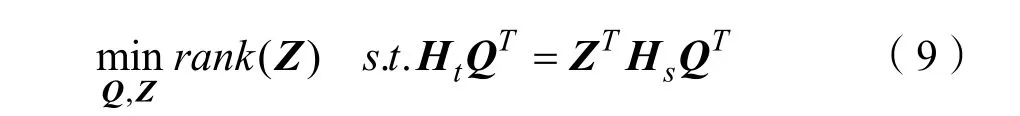
式(9)有利于獲得xs和xt的一致表示,以便源數據和目標數據很好地對齊。由于秩最小化問題是非凸問題,因此式(9)中的問題是 NP-難問題。如果Z的秩不太大,則式(9)等效于:
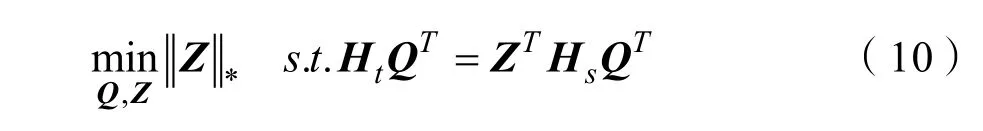
其中Z*是矩陣的核范數。為了減輕噪聲的影響,本文引入矩陣E對噪聲進行建模,并對E施加稀疏約束,然后將式(10)更改為:
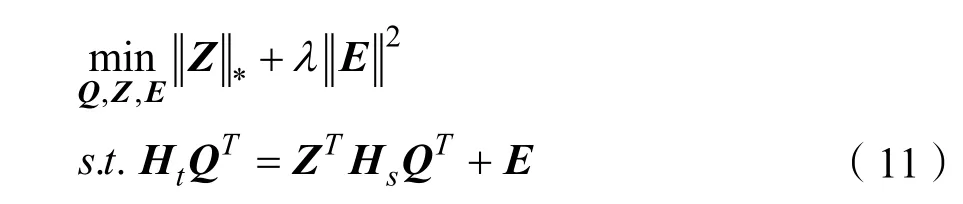
2.3.3 目標函數求解優化
聯合分類器式(8)和子空間對齊式(11),得到求解跨領域分類器輸出層權重的目標函數:

其中α,C,λ為懲罰系數。解決式(12)需要通過固定其他變量來迭代更新每個變量。對目標函數式(12)加入輔助變量Z1轉換為:

式(13)的增廣拉格朗日函數L為:
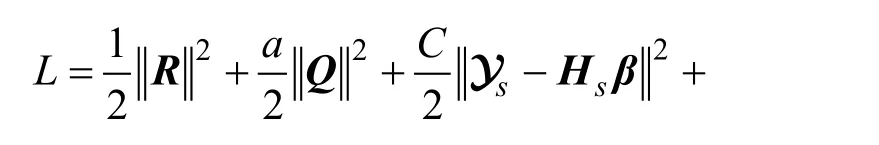

其中Y1,Y2和Y3是拉格朗日乘數,而μ>0是懲罰參數。通過交替更新變量,并固定其他變量來最小化拉格朗日函數L。滿足收斂條件后,迭代將停止。解決式(14)的主要步驟如下:
Step.1更新Q,解決式(15)更新參數Q:


式(17)為西爾維斯特方程(Sylvester Equation),可以采用文獻[7]中的求解方式對式(17)進行求解獲得Q。
Step.2更新Z,解決式(18)更新參數Z

式(16)可進一步轉化為:
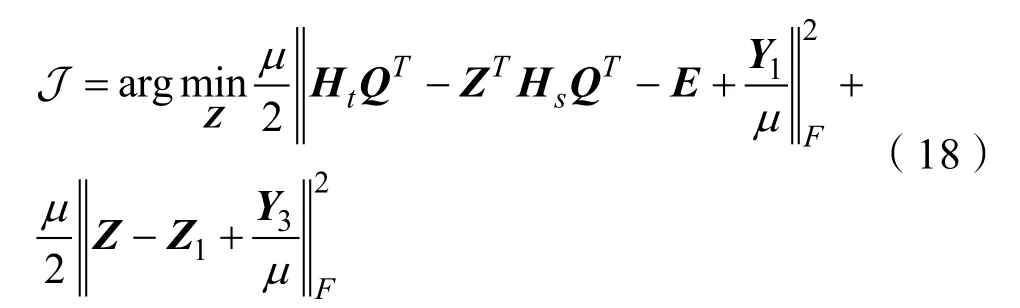
則:

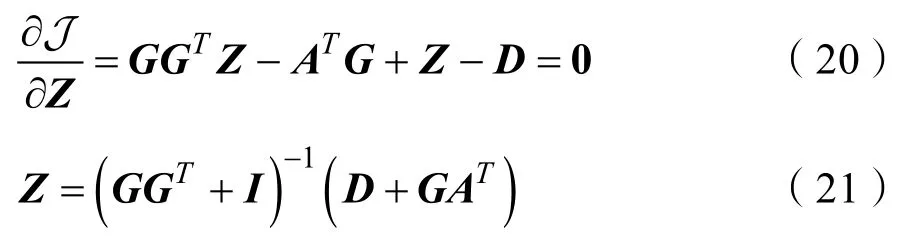
Step.3更新Z1,解決式(22)更新參數Z1:
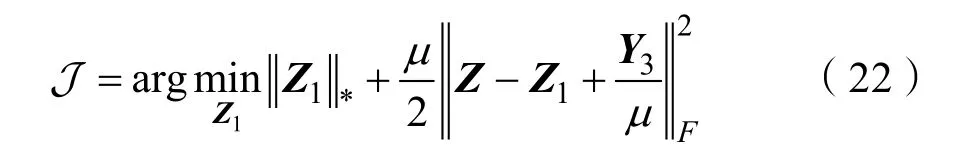
式(22)的閉式解為:


Step.4更新E,解決式(24)更新參數E:


Step.5更新R,解決式(27)更新參數R:
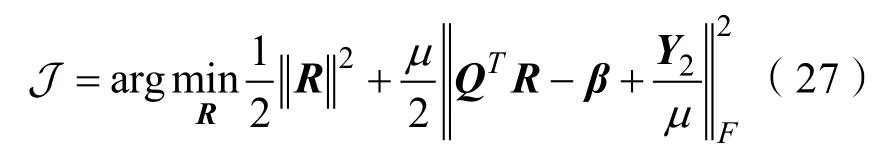

Step.6更新β,解決式(30)更新參數β:
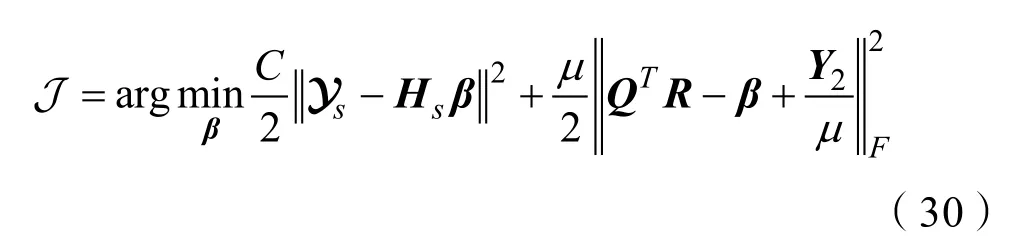


聯合子空間對齊與極限學習機無監督領域自適應算法如算法1所示。
算法1 JSA-ELM執行流程
輸入:
隱藏層輸出矩陣Hs,Ht;標簽矩陣 ys;
平衡參數α,λ,C,; 隱藏子空間? 的尺寸。
初始化:

循環執行:
更新參數Q,根據式(17)
更新參數Z,根據式(21)
更新參數Z1,根據式(23)
更新參數E,根據式(26)
更新參數R,根據式(29)
更新參數β,根據式(32)
收斂則停止
輸出:
輸出具有遷移能力的權重矩陣β
3 實驗結果與分析
3.1 實驗數據集及設置
為了驗證 JSA-ELM 方法的性能及其泛化能力,在4個公開數據集上對JSA-ELM進行驗證。這些數據集已被大多數領域自適應研究學者廣泛采用。表1列出了各個基準數據集的統計數據。

表1 JSA-ELM實驗數據集Tab.1 Experimental dataset
Office數據集是視覺自適應領域中通用的基準數據集,由三個不同對象域組成:Amazon在線商家下載的圖像,Webcam網絡攝像頭拍攝的低分辨率圖像和DSLR高分辨率圖像,共包含31個類,4,652張圖像[8]。
Caltech-256是用于對象識別的標準數據集,包含256個類別的30,607張圖像[9]。在實驗中,本章使用了Gong等人提供的Office和Caltech數據集,該數據集是由三個 Office數據集和一個Caltech數據集中相同的十個對象類別組成的[8]。將四個不同的域命名為 C(Caltech-256),A(Amazon),W(Webcam)和 D(DSLR)。通過源域和目標域的組合,構造了4×3=12個跨域對象數據集C→A,C→W,C→D,A→C,……,D→W。
USPS數據集包含7,291個訓練樣本和2,007個測試樣本,大小為16×16像素。MNIST數據集由 60,000個訓練樣本和 10,000個測試樣本組成,大小為28×28像素[10]。從圖3可以看出USPS和MNIST數據集中樣本之間的分布不同,它們共享10種類型的數字樣本。按照文獻[11]的實驗設置,我們通過隨機選擇 1,800個樣本作為 USPS中的源數據并隨機選擇2,000個樣本作為MNIST中的目標數據來構建 USPS(U)→MNIST(M)數據集。并通過切換源/目標對獲得另一個數據集MNIST(M)→USPS(U)。為了在源數據和目標數據之間共享相同的特征空間,我們將 USPS和MNIST數據集的所有圖像縮放為16×16大小,并且每個圖像都由一個256維特征向量表示,該向量對灰度像素值進行編碼。數據集的示例樣本如圖3所示。

圖2 數據集示例圖Fig.2 Example samples of datasets
3.2 實驗結果分析
3.2.1 物體目標識別

表2 Offce+Caltech10數據集的分類準確率(%)Tab.2 Classification accuracy of Offce+Caltech10 datasets

圖3 JSA-ELM參數敏感度分析Fig.3 Parameter sensitivity analysis of JSA-ELM
為了驗證本章提出方法的有效性,本文在物體圖像數據集上做了9個自適應分類實驗。包括經典的主成分分析算法(PCA);遷移成分分析算法(TCA)和聯合分布適配法(JDA)的概率分布適配法;遷移聯合匹配算法(TJM)為代表的特征選擇的方法;子空間學習法則選擇子空間對齊法(SA)和測地線流式核算法(GFK)算法進行實驗;同時還對比了基礎的極限學習機(ELM)和最新的極限學習機領域自適應模型(UDACELM)[12]。
實驗中所有比較方法的最佳參數都是根據其原始論文來設置。對于本章提出的方法,本文設置了隱含層維度為 256,C為 0.1,μ為 0.1。選擇全部源域作為訓練數據,在訓練前做相應歸一化處理。選擇所有目標域樣本作為測試數據,重復進行10次實驗并取平均值,實驗結果如表3所示。
從表3可以看出,本章提出的聯合子空間對齊與極限學習機方法(JSA-ELM)平均分類準確率優于其他對比方法。JSA-ELM 的平均分類準確率為52.06%,與其基本的ELM和SA相比平均精度提高了5.12%和7.24%。單純的ELM分類器算法、分布對齊方法(TCA、JDA和TJM)和子空間學習方法(SA和GFK)的性能普遍比JSA-ELM差。這表明參與對比的傳統分類器和領域自適應方法都有一定的局限性,導致領域偏差對分類器影響較大。UDAC-ELM在流形學習之后,仍然存在較大的域偏移。在不同圖像數據集上進行驗證表明 JSA-ELM 能夠顯著減少領域自適應問題中的分布差異。
3.2.2 手寫數字識別
在手寫體數字識別實驗中,本文選擇極限學習機(ELM)、遷移成分分析算法(TCA)、聯合匹配算法(TJM)、子空間對齊法(SA)、測地線流式核算法(GFK)和無監督域自適應極限學習機(UDAC-ELM)作為對比方法。所有對比算法都是根據其原始論文來設置的最佳參數。對于本章提出的方法,設置隱含層維度為32,C為0.1,μ為0.1,選擇全部源域圖像作為訓練數據,并做相應歸一化處理。選擇所有目標域樣本作為測試數據,重復進行10次實驗并取平均值,實驗結果如表3所示。
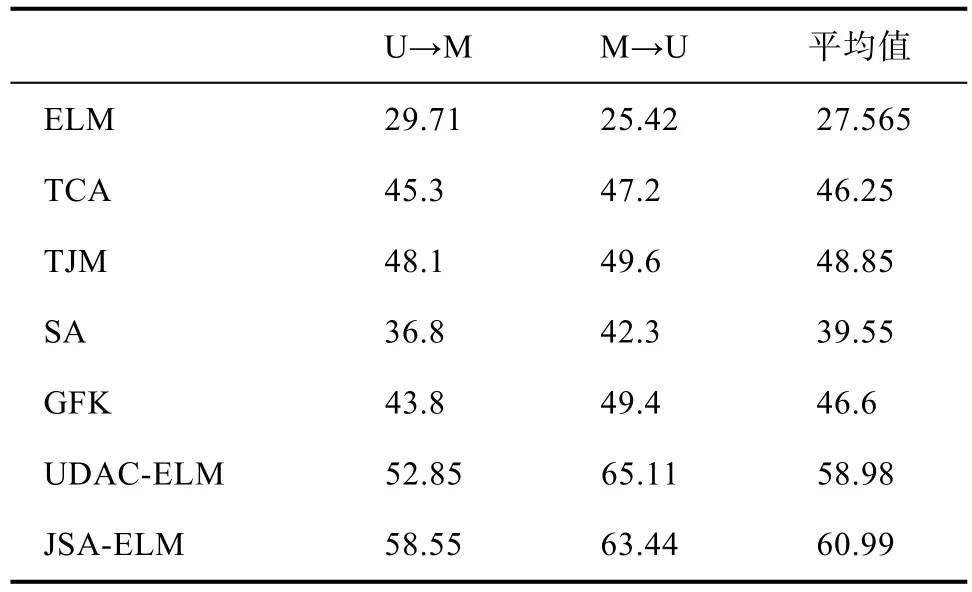
表3 USPS和MNIST數據集的分類準確率(%)Tab.3 Classification accuracy of digital datasets
從表 2中可以看出,本章提出聯合極限學習機和子空間對齊(JSA-ELM)在平均分類準確率上優于其他對比方法。JSA-ELM在分類性能上遠遠高于SA和ELM算法,比最新的UDAC-ELM提高了2.01%。這表明SA-ELM能充分利用子空間對齊方法提升分類器對領域偏差的魯棒性,有效地減小領域間的分布差異,提高算法的分類性能。
3.3 參數分析
本節分析 JSA-ELM 在不同類型數據集上的參數敏感性。在不同類型的數據集上的結果已證實,固定的C=0.1和μ=0.1并將所有學習率設置為0.001,對于所有任務都是足夠的。因此,我們僅評估其他三個參數α,λ和隱藏層數。我們在USPS→MNIST和 A→D數據集上進行實驗,如圖3所示。實線是使用不同參數在JSA-ELM上的準確度,虛線表示在每個數據集上通過最佳基線方法獲得的結果。在其他數據集上也觀察到類似趨勢。從圖 3(a)和(b)可以看出,與最佳基準方法相比,可以選擇大范圍的α和λ獲得更好的結果。圖 3(c)顯示出了隱藏層參數h與精度之間的關系,可以看出本模型僅需較少的隱藏層數就可以達到較好的效果,表示只需較少的計算資源消耗。
4 總結
本文主要針對領域自適應問題進行了深入研究,并結合子空間學習、極限學習機提出了聯合極限學習機和子空間對齊的無監督領域自適應方法。該方法將更改數據表示方法和分類器設計相結合。針對 ELM 的輸出層參數進行了自適應學習,進一步增強其遷移能力。首先通過利用ELM-AE獲取用于提取域不變性特征權重替代ELM初始化隨機權重;然后拆分ELM輸出層權重使其更加的靈活;聯合極限學習機分類器拆分后的輸出層中利用子空間對齊方法將源數據和目標數據轉換為一個公共子空間,其中每個目標數據都可以通過源域中的數據線性地重構。在重建矩陣上施加低秩約束,以便可以保留數據的全局結構,同時低秩約束的設計還確保了來自不同域的數據可以很好相互表示,這有助于顯著減小域分布的差異。并且在公開數據集上的實驗驗證了該算法的可行性。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
