
基于視覺SLAM算法的研究現狀分析
2021-07-30 00:38:06張玉河
新一代信息技術 2021年9期
張玉河
(河北地質大學 信息工程學院,河北 石家莊 050031)
0 引言
SLAM(Simultaneous Localization and Mapping)即同時定位與地圖構建,是指機器人搭載特定的傳感器在沒有環境先驗信息的情況下,在運動過程中根據位置估計進行自身定位并對周圍的環境進行建圖。當搭載的傳感器為相機時,稱為“視覺SLAM”。視覺SLAM的工作流程如圖1所示。
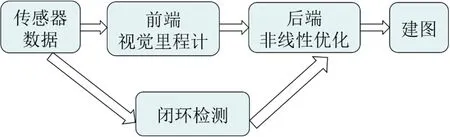
圖1 視覺SLAM工作流程圖Fig.1 The flow chart of Visual SLAM
SLAM問題起源于1986年[1],文獻[1-2]全面回顧了SLAM近些年的發展并探討了SLAM的未來發展趨勢;文獻[3]將SLAM的發展劃分為三個時代:classical age(1986-2004)、algorithmicanalysis age(20014-2015)以及robust-perception age(2015-現在),1986-2004年引入了SLAM的概率公式,包括擴展卡爾曼濾波器和最大似然估計等;2004-2015年主要研究SLAM的基本性質,包括可觀測性、收斂性與一致性;目前這一時期對 SLAM 系統的魯棒性等性能提出了更高的要求。視覺SLAM主要分為兩大類,一是基于圖像特征點的間接法,2007年 Davison[4]提出MonoSLAM,這是第一個實時單目視覺SLAM系統,被認為是許多工作的發源地[5];2015年Raul Mur-Artal和 Juan D.Tardos等人[6]提出 ORBSLAM,在這個系統中,作者首次使用三線程的方法完成 SLAM,而且作者還在對該系統進行完善,分別于2017年和2020年推出ORB- SLAM2[7]和 ORB-SLAM3[8];另一類是根據像素亮度信息直接估計相機運動的直接法,直接法避免了圖像特征的計算,在一定程度上提升了SLAM系統的效率。2014年 J.Engel[9]等人提出 LSD-SLAM(Large Scale Direct monocular SLAM),LSDSLAM的提出標志著單目直接法在SLAM的應用中取得成功,在該系統中實現了半稠密場景的重建且保證了跟蹤的實時性與穩定性。隨著深度學習技術的快速發展,將深度學習技術與視覺SLAM 結合成為一個研究熱點,Gao[10]等人提出通過無監督學習的方式,采用堆疊去噪自動編碼器(Stacked Denoising Auto-encoder,SDA)的方式描述整幅圖像來進行圖像的匹配實現回環檢測,取得了較好的效果[11]。
視覺SLAM技術主要應用于無人機、機器人以及虛擬現實等領域,在水下或惡劣環境中可以發揮巨大作用,方便人們對未知環境進行探索。本文首先對視覺SLAM原理進行介紹,將SLAM問題數學化,然后對具有代表性的特征法與直接法的視覺SLAM算法進行分析討論,再對深度學習與視覺SLAM結合的現狀進行討論,最后對視覺SLAM算法進行總結與展望。
1 視覺SLAM原理
視覺SLAM以多視圖幾何[12]為基本原理,如圖2所示。視覺SLAM主要目的是恢復每幀圖像對應的相機運動參數C1…Cm,同時恢復場景的三維結構X1…Xn。相機運動參數 Ci由3× 3的旋轉矩陣 Ri和一個三維位置變量pi組成,通過Ri、pi可以將世界坐標系下的三維點Xj變換至相機坐標系[13],其表達式為:

圖2 多視圖幾何原理Fig.2 The principle of multi-view geometry
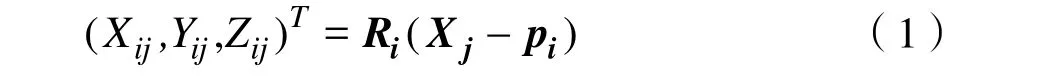
進而投影至圖像中,即變換至像素坐標系:
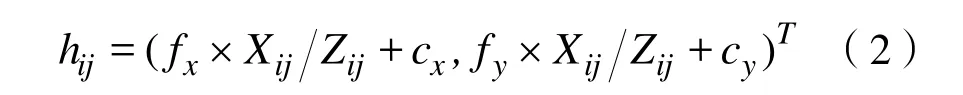
其中,fx、fy分別為沿圖像x、y軸的焦距,(cx,cy)為鏡頭光心在圖像中的位置。由式(1)(2)可知,將世界坐標系下的三維點投影到像素坐標系[13]中可表示為:

其中,hij表示三維點投影在圖像中的位置,h表示由世界坐標系變換至像素坐標系的轉換函數。通過求解目標函數得到最優解:

其中,xij表示觀測到的圖像點位置。通過求解的目標函數得到一組最優解C1…Cm、X1…Xn,使得所有Xj在 Ci圖像中的投影位置 hij與觀測到的圖像點位置xij盡可能靠近[13]。
2 間接法
間接法是指首先提取圖像特征,然后在視覺里程計中根據圖像特征信息估計相機運動。該方法利用圖像特征提供的豐富信息計算相機位姿,性能比較穩定,在視覺 SLAM 中一直占據主導地位。
2.1 MonoSLAM
單目視覺SLAM系統由Davison等人在2003年首次提出[14],2007年提出實時MonoSLAM系統。MonoSLAM證明了用一個可自由移動的攝像機作為唯一數據源,可以實現實時定位和建圖。該系統的設計思路如下:首先給定從初始時刻到當前時刻的控制輸入及觀測數據;然后通過構建聯合后驗概率密度函數來描述攝像機姿態和地圖特征的空間位置,再通過遞歸的貝葉斯濾波方法對此概率密度函數加以估計;最后實現對攝像機定位,同時構建周圍環境地圖[15]。在單目視覺SLAM中常用擴展卡爾曼濾波器實現同時定位和地圖構建。MonoSLAM系統由以下兩部分組成:(1)通過已知的對象完成地圖初始化;(2)使用EKF估計相機運動和特征點的3D位置。
在該系統中計算復雜度隨環境規模增大而成比例的增大,因此,在較大環境中不能實時計算[16]。
2.2 PT AM
為了解決 MonoSLAM 中計算復雜度高的問題,Klein[17]等人在2007年提出PTAM (Parallel Tracking and Mapping)算法。在PTAM中,后端模塊采用非線性優化方法,首次將跟蹤和建圖分到兩個線程中并行執行,同時首次使用 BA[18](Bundle Adjustment)技術處理關鍵幀。PTAM算法主要分為四步:(1)通過五點法[19]初始化地圖;(2)根據地圖點和輸入圖像之間匹配的特征點估計相機位姿;通過三角化估計特征點的 3D位置,利用BA對3D位置優化;通過隨機樹的搜索方法恢復跟蹤過程[20]。
由于PTAM算法在相機快速移動時會產生運動模糊,破壞圖像的角點特征,導致跟蹤失敗,一些研究者對PTAM算法做了擴展,如Castle[21]等人開發出一個多地圖版本的 PTAM,以及Klein[22]等人開發出移動版的PTAM。
PTAM 中首次引入基于關鍵幀建圖的方法并將跟蹤和建圖分離到不同的線程中并行處理,對視覺SLAM的發展具有重大意義。基于PTAM算法發展出許多開源視覺SLAM算法,最具代表性的為2015年提出的ORB-SLAM算法。
2.3 ORB-SLAM
Mur-Artal等人2015年提出的ORB-SLAM系統是當前視覺SLAM系統中最完善且易于使用的系統之一。最初的ORB-SLAM只可以用單目相機作為傳感器,2017年作者對其進行改進得到ORB-SLAM2系統,在ORB-SLAM2中可以利用單目、雙目及RGB-D相機作為傳感器。2020年提出ORB-SLAM3,在ORB-SLAM3中不僅支持單目、雙目和RGB-D相機,同時支持針孔相機、魚眼相機等,ORB-SLAM3是第一個同時具備純視覺數據處理、視覺與慣性傳感器數據處理和構建多地圖功能的SLAM系統。ORB-SLAM系統由PTAM發展而來,將兩線程并行運行改為三線程,三線程分別為Tracking、Local Mapping以及Loop Closing,如圖3所示。
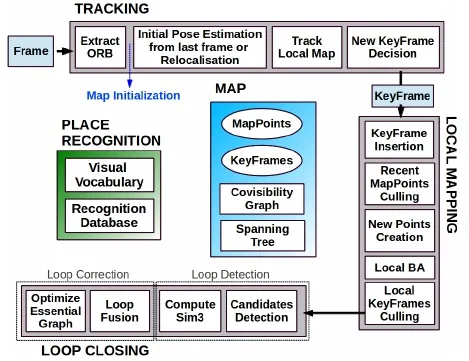
圖3 ORB-SLAM 系統的三線程Fig.3 The three threads of the ORB-SLAM system
在整個ORB-SLAM系統中,均圍繞ORB[23]特征進行計算。ORB特征是非常具有代表性的實時圖像特征,它使得 FAST[24]特征點具有方向性與旋轉不變性,并采用速度極快的BRIEF[25]描述子,相比于SIFT[26]和SURF[27]特征,ORB特征可以在CPU上實時計算,極大的提升了視覺SALM系統的性能。
在ORB-SLAM系統中,加入閉環檢測模塊是一大亮點。閉環檢測模塊通過判斷當前設備之前是否到過當前位置來消除位姿累積誤差形成的軌跡漂移,且可以在跟蹤丟失后快速找回,從而構建全局一致性地圖。ORB-SLAM的不足之處在于跟蹤、建圖等過程都要用到ORB特征,雖然提取圖像的ORB特征速度較快,但對每一幅圖像都提取ORB特征,當場景非常大時將特別耗時,而且三線程同時執行會加重CPU的負擔,很難將其嵌入到移動設備中。
3 直接法
與上文所述的間接法相比,直接法在視覺SLAM系統中直接使用輸入的圖像,不使用圖像的任何抽象特征。G.Silveira[28]等人于 2008年提出將直將接法用于視覺SLAM系統,因其忽略了圖像特征點的提取與描述子的計算過程而節省了時間,基于直接法的視覺SLAM系統得到快速發展,隨后出現了 DTAM[29]、LSD-SLAM[30]以及DSO[31]等使用直接法的開源項目,使得直接法逐漸成為主流算法。
3.1 DT AM
DTAM(Dense Tracking and Mapping)是Newcombe等人2011年提出的直接法視覺SLAM系統。它是一個實時跟蹤和重建的系統,不使用提取的圖像特征,而是依賴于圖像中的每個像素。文獻[29]指出基于直接法的DTAM系統與基于特征法的SLAM系統相比,DTAM系統在設備快速移動的情況下具有更好的跟蹤性能。DTAM系統由三部分組成:(1)通過立體測量完成地圖初始化;(2)根據重建的地圖估計相機運動;(3)先對每個像素的深度信息進行估計,再通過空間連續性對其優化。
DTAM算法在實時幾何視覺方面取得了重大進展,在增強現實、機器人等領域具有潛在應用價值,但DTAM算法在跟蹤和重建的過程中,需假設亮度恒定不發生變化,對周圍環境有較高的要求。
3.2 LSD-SLAM
LSD-SLAM (Large Scale Direct monocular SLAM)是J.Engel等人在2014年提出的直接法SLAM系統。在LSD-SLAM系統中,可以在較大規模的環境中構建一致性地圖,并且利用基于圖像對齊的高精度位姿估計方法,將三維環境實時重建為基于關鍵幀的位姿圖。在該算法中,主要包含兩個創新點:一是創新的提出一種直接跟蹤算法,可以明確的檢測尺度漂移;另一個是通過概率的方法解決噪聲值對跟蹤的影響。
LSD-SLAM算法包括三個模塊:跟蹤、深度圖估計及地圖優化。跟蹤模塊持續跟蹤相機拍攝的圖像;深度圖估計使用跟蹤幀來完善或替換當前關鍵幀,如果相機移動太快,則通過現有距離較近的關鍵幀中的投影點重新初始化一個新的關鍵幀;當關鍵幀被跟蹤幀替換后,它的深度圖不被進一步完善,而是通過地圖優化模塊將其添加到全局地圖中。完整的LSD-SLAM算法流程圖如圖4所示[30]。
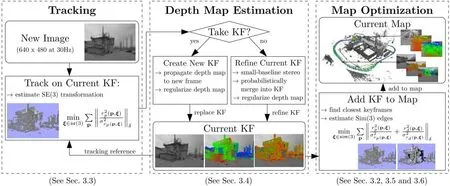
圖4 LSD-SLAM 算法流程圖Fig.4 The flowchart of LSD-SLAM algorithm
與其它直接法相比,LSD-SLAM算法可以在全局地圖上維護和跟蹤,包括關鍵幀的位姿圖和相關的概率半稠密深度地圖。通過考慮移動設備的CPU架構[32],對LSD-SLAM算法做進一步優化,將LSD-SLAM算法遷移到移動設備上,獲得不錯的效果。在單目相機的基礎上,J.Engel等人在2015年將LSD-SLAM算法擴展到雙目[33]和全方位相機[34]。
4 視覺SLAM與深度學習
近幾年深度學習技術發展迅速,在圖像識別、圖像分類以及目標檢測等領域表現突出。視覺SLAM同樣以圖像為處理對象,將深度學習技術用到視覺 SLAM 系統中可以極大的促進視覺SLAM的發展。
目前主要是將深度學習技術用于視覺 SLAM系統中的視覺里程計模塊和閉環檢測模塊。
4.1 深度學習與視覺里程計
視覺里程計通過分析關聯圖像間的幾何關系確定機器人的位姿信息,將位姿信息傳遞到后端優化模塊進行優化,從而構建全局一致性地圖。基于深度學習的視覺里程計無需特征提取、特征匹配及復雜的幾何運算,使得整個過程更加直觀簡潔。
基于深度學習的視覺里程計中運動估計的準確性和魯棒性依賴于神經網絡估計器的設計和訓練的圖像是否涵蓋待測場景的全部變化[35]。2015年,Konda[36]等人通過提取視覺運動和深度信息實現基于深度學習的視覺里程計;Kendall[37]等人利用 CNN(卷積神經網絡)實現了輸入為 RGB圖像,輸出為相機位姿的端到端定位系統,該系統提出了 23 層深度卷積網絡的 PoseNet網絡模型,利用遷移學習將分類問題的數據用于解決復雜的圖像回歸問題,其訓練得到的圖像特征相較于傳統的手工特征,對光照、運動模糊以及相機內參等具有更強的魯棒性。2017年,Wang[38]等人使用 RCNN(遞歸卷積神經網絡)提出一種新的端到端的單目視覺里程計框架,在該框架中可以利用CNN為視覺里程計問題提供特征表示,也可以利用RCNN模型對運動模型和數據關聯模型建模,實驗結果表明該算法具有非常好的性能[35]。Costante G[39]等人構建了一個自編碼深度網絡模型,用來學習產生光流的非線性潛在空間描述,將此自編碼網絡與其它神經網絡模型聯合訓練,從而估計相機的運動。
與傳統的視覺里程計相比,基于深度學習的視覺里程計更加直觀簡潔,無需構建復雜的幾何模型,但當訓練場景發生變化時,視覺里程計會產生錯誤的結果。隨著深度學習技術的不斷發展,以及對視覺里程計更加深入的研究,將會進一步提升各種網絡模型的泛化能力。
4.2 深度學習與閉環檢測
閉環檢測即檢測機器人是否經過同一位置,通過檢測機器人獲取的當前幀圖像與歷史幀圖像的相似性來實現。閉環檢測主要用于消除視覺里程計中機器人位姿累積誤差所造成的軌跡漂移,從而得到全局一致的軌跡和地圖。傳統的閉環檢測方法大多是基于詞袋模型來實現,使用人工設計的特征描述圖像,不能充分利用圖像的深層信息,而基于深度學習的閉環檢測則通過神經網絡學習圖像的深層特征,以獲得更高的準確率。
基于深度學習的閉環檢測主要利用預訓練的神經網絡模型對圖像進行特征提取,充分利用圖像深層次的特征信息。2015年國防科技大學[40]提出將深度學習用于閉環檢測模塊,將AlexNet[41]遷移到閉環檢測問題中,用中間層的輸出作為特征來描述整幅圖像,通過二范數進行特征匹配來確定是否存在回環。Gao[42-43]等使用無監督學習的方式,采用自編碼網絡提取圖像特征,并使用相似度矩陣檢測閉環,在公開的數據集上取得了很好的效果[44];2019年Liu[45]等人提出基于改進的混合深度學習結構的閉環檢測方法,利用該網絡模型生成高層次的語義圖像特征,從而提高閉環檢測的準確率和效率,利用該網絡模型進行檢測閉環的過程如圖5所示。

圖5 利用改進的混合深度學習模型檢測閉環的過程Fig.5 An improved hybrid deep learning model is used to detect the closed-loop process
對于第 k個關鍵幀,首先對其進行預處理,然后利用訓練好的網絡模型提取特征,將提取的高層次語義特征作為圖像向量輸出,最后將提取的圖像向量與關鍵幀特征向量庫比較,計算相似矩陣檢測閉環。實驗結果表明,該方法具有較高的準確率。
基于深度學習的閉環檢測利用神經網絡提取圖像特征,獲取的圖像信息更豐富。當光照、季節等因素變化時,提取的特征信息仍然具有較好的魯棒性。
5 總結與展望
隨著機器人、虛擬現實等領域的快速發展,視覺SLAM技術發展迅速。最初由利用圖像特征的間接法占主導,但隨著直接法的不斷發展完善,兩種方法相互促進,共同發展,提升了視覺SLAM系統的性能。基于深度學習的視覺SLAM方法當前正處于快速發展階段,將深度學習技術用于SLAM系統中,不僅能推動視覺SLAM技術的發展,也可以促進深度學習技術的發展。
多傳感器融合是視覺SLAM未來發展的一個重要方向,將視覺與慣性傳感器結合可以得到更完善的視覺SLAM系統,目前深度學習技術只是應用在視覺SLAM系統的中局部模塊,隨著深度學習技術的不斷發展,研究人員對視覺SLAM技術的深入研究,將會進一步促進深度學習與視覺SLAM的融合。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
