面向大規模源代碼的內存安全性動態分析技術
2021-08-02 03:35:28王沖,孫毅,仵俊
計算機技術與發展 2021年7期
王 沖,孫 毅,仵 俊
(南京航空航天大學 計算機科學與技術學院,江蘇 南京 211100)
0 引 言
C語言常用于諸如操作系統、嵌入式軟件系統等對性能要求較高的系統的編寫。然而C語言本身缺乏對內存安全性檢測的相關功能,因此使用其編寫的程序可能存在較為嚴重的內存安全性漏洞[1-5]。動態分析[6-8]是目前常用的對程序進行內存安全檢測的方法,目前常用的實現方法有二進制代碼插樁、中間代碼插樁、源代碼插樁[9-10]等。
二進制代碼插樁是對可執行程序進行插樁,優點是不需要源代碼就可以對程序進行動態分析;中間代碼插樁是對編譯后的代碼插樁,可以利用優化,減少不必要的插樁;源代碼插樁是指對源碼上進行修改,添加行為監代碼,對程序進行檢測,優點是可以獲取源代碼中的位置,準確地報告錯誤信息。
為了能更準確有效地檢測程序的錯誤并能將錯誤的變量信息準確地反饋給用戶,該文采用了源代碼插樁技術進行插樁,并在基于指針技術[11-13]的基礎上,借助開源編譯器Clang和C++語言實現了內存安全分析工具Movec,完成其對大規模C程序的內存安全性檢測,并通過實驗進行了驗證,表明該內存分析工具對大規模程序的內存檢測是有效且高效的。
1 基礎知識
基于指針的內存安全性檢測技術的主要思想是對程序中的所有指針變量構造一個指針元數據,用來記錄該指針的內存狀態、上下界以及指向當前內存的指針的個數。然后,當指針賦值或者以函數參數傳遞的時候,更新這個指針的元數據,用來保持數據的一致性。最后,在對指針進行解引用或者通過指針對內存進行讀寫時,根據指針元數據中記錄的內存狀態信息,來判斷該次內存訪問是否是合法的,從而檢測出內存的安全性。
采用源代碼插樁實現基于指針內存安全性檢測的過程分為三個部分:一是對指針變量定義進行插樁以初始化元數據,對指針變量賦值進行插樁來更新元數據的信息;二是在指針解引用的時候來檢查該指針所引用的對象的元數據;三是對函數定義進行插樁以初始化函數參數的元數據、計算存儲返回值的元數據。然后,對函數定義生成一個包裝函數,該包裝函數用來對程序檢測并傳遞指針元數據。接著,對原函數調用重命名,并插入元數據,然后將原函數調用重定向到其包裝函數來完成檢測。
2 大規模C程序的內存安全性檢測的研究與實現
2.1 項目插樁的改進
目前的源代碼插樁工具對程序的插樁一般有兩種模式,一種是單文件插樁模式,一種是項目插樁模式。單文件插樁模式適用于一些文件數量比較少的情況。對于項目插樁模式,目前常采用的方法是使用搜索后綴的方法將文件中所有的.c和.h文件進行搜索,然后將所有的文件添加到插樁列表中,把每個.c和.h文件都當成一個翻譯單元進行解析插樁,插樁完成后將新的文件生成到目標文件夾中。這種方法在對大規模的程序進行插樁時過于簡單,會導致如下問題:一對每個.c和.h文件進行搜索,會將一些不必要的文件進行搜索并插樁,增加了項目插樁時間;二是當文件編譯命令中使用了-D定義了宏或者使用-I頭文件目錄時,這種項目插樁的方式獲取到的語法樹會和原語法樹完全不同,導致插樁錯誤;三是當項目中的頭文件出現一個不完整文件時,將該文件當作一個完整的翻譯單元處理時,無法獲取其完整的語法樹,導致程序插樁失敗。
對于問題一和問題二,該文利用編譯數據庫的概念,對源代碼插樁工具的項目插樁模式進行改進。編譯數據庫是在項目實際編譯過程中對編譯器調用的監控記錄,其中包含了每個文件在編譯時的編譯選項。利用編譯數據庫獲取待插樁文件的存儲路徑和該文件對應的編譯指令,構造出每個文件的原始編譯命令,從而在對文件進行解析時獲取到的語法樹和原始語法樹是一致的。同時,通過編譯數據庫,可以獲取一個可執行文件的所有的依賴文件,不需要進行.c和.h的搜索,降低了程序插樁的時間。
對于問題三,該文提供的解決方法是將不完整頭文件擴展到源文件中,不再對該頭文件進行單獨插樁。因此,該文提供了一個頭文件擴展算法,該算法可以將指定的文件進行擴展,當遇到該文件時,不對其插樁,同時將其內容擴展到所有引入該頭文件的文件中。當對程序進行內存安全性檢測時,由于系統庫文件中的接口是編譯器提供的標準接口,不需要對其進行插樁檢測,所以該文提供的頭文件擴展算法對所有的系統庫文件不進行擴展,這不僅減少了對程序的插樁時間,也減少了代碼的膨脹率。同時,該文提供的算法還支持不擴展用戶指定的頭文件。
該算法的主要思想是:首先,創建一個文件輸出流,然后利用Clang前端接口創建一個原始詞法解析器,該解析器只解析當前主文件中的內容,然后當解析到#include指令時,在頭文件列表中查找該include的文件標識,然后判斷該文件是否是系統庫文件,若不是,則將其內容寫入到輸出流,同時遞歸地調用本方法去繼續擴展頭文件中引入的頭文件。若是系統庫文件則保持不變,繼續解析下一個#include命令。其中,頭文件列表是當讀取的文件發生切換時記錄的,它通過Clang提供的PPCallbacks中的FileChanged()回調函數記錄,每當文件發生切換,記錄該文件的ID、類型等信息。當一個文件中所有的#include指令的內容擴展完成后,再將#include指令后的內容寫入到輸出流,最后寫回到原文件中,從而實現對頭文件的擴展。具體實現如圖1所示。

圖1 頭文件擴展算法
2.2 包裝函數插樁改進算法
基于指針的內存安全性動態分析技術對包含指針參數或返回值為指針類型的函數,需要對其插樁包裝函數,用來初始化函數參數和返回值變量的指針元數據。對函數定義生成其包裝函數定義,然后在其函數調用中重命名該方法,將其定位到包裝函數以完成內存檢測。但是由于庫函數的定義在系統頭文件中,無法根據其定義生成包裝函數。通常,內存分析工具會提供常用庫函數的包裝函數,但是當程序調用的庫函數較多或者使用了第三方庫時,內存分析工具無法提供所有的庫函數的包裝函數。若沒有提供包裝函數的庫函數,則會對其進行插樁,此時會因為找不到包裝函數定義而導致編譯失敗。針對這類問題,該文提供的解決方法是:首先,對于一個函數,判斷其是否是庫函數,然后判斷該函數的包裝函數工具是否提供,若提供了其包裝函數,則對該庫函數進行插樁,若不提供,則不對該庫函數進行插樁。
因此該文給出一個庫函數判斷算法,該算法的思想根據是庫文件是存儲在系統特定位置下,通過判斷一個函數所引用的聲明的文件是否在當前工作目錄中,來判斷該函數是否為庫函數。具體的實現如圖2所示。

圖2 庫函數判斷算法
當判斷一個函數是庫函數后,此時需要判斷函數是否需要插樁,該文利用Clang獲取用戶文件語法樹,然后通過函數聲明與定義訪問函數VisitFunctionDecl記錄下每一個函數名,將其傳遞給插樁模塊,配合系統提供的包裝函數列表,完成函數是否需要插樁的判定。
2.3 匿名結構體插樁改進
對于結構體指針解引用,需要獲取該指針指向區域的上界和下界。對于指向命名結構體的指針變量如struct st *ptr,它指向區域的上界和下界分別為ptr和ptr+sizeof(struct st)。但是對于匿名結構體,無法獲取它的名字,所以sizeof的括號中缺少結構體名字,導致插樁后的程序出現編譯錯誤,如:struct {int a; int b;} *ptr;對*ptr插樁后獲取的下界ptr+sizeof(struct(anonymous struct at /home/a.c:3:1)。
對于該問題,該文提供的解決方法是:對匿名結構體添加一個唯一的ID,在使用sizeof獲取匿名結構體變量類型的時候,使用該ID構造函數的名字,通過該名字確定結構體類型的大小。使用AST上該結構體定義節點的地址作為ID。在結構體定義時添加有該ID構造的名字,然后在訪問該結構體變量時獲取該變量的結構體定義節點,并獲取其地址,從而保證了構造的ID是唯一的并且是一致的。具體的實現算法如圖3所示。

圖3 匿名結構體插樁算法
2.4 循環結構和switch分支結構的改進
當一個指針無效時,需要對該指針的元數據進行清除,以節省空間和時間。在循環結構中包含break語句和continue語句,switch分支結構中包含break語句,這些語句會改變程序的執行流程,所以需要對break語句和continue語句進行重寫,來實現對程序的指針元數據的清除,具體重寫的規則如下:
循環中的break替換為:{bc_flag_LOOP_BLOCK_ID=1;goto PRFlbl_THIS_BLOCK_ID;}。
continue語句替換為:{bc_flag_LOOP_BLOCK_ID=2;goto PRFlbl_THIS_BLOCK_ID;}。
switch中的break替換為:{bc_flag_SWIT_BLOCK_ID=1;goto PRFlbl_THIS_BLOCK_ID;}。
其中bc_flag_LOOP_BLOCK_ID值為1時表示循環中的break語句,值為2時表示continue語句,bc_flag_SWIT_BLOCK_ID表示switch語句中的break語句。LOOP_BLOCK_ID表示該循環語句塊的ID,SWIT_BLOCK_ID表示語句switch語句塊的ID,lbl_THIS_BLOCK_ID插入在該語句塊最后用來清除在該語句塊內定義的元數據,然后再根據bc_flag判斷執行流程。
在對break的替換的時候,需要考慮一些復雜結構,如循環中嵌套switch結構或switch語句中嵌套循環結構,此時插樁時需要對該break語句進行判斷來實現不同的替換。針對該問題,該文提出的解決方法是:對于一個break語句,在插樁前需要記錄它的父語句塊PBS,在進行函數插樁時記錄循環結構語句塊LBS和switch語句塊SBS,如果不存在循環結構或switch結構體,則LBS和SBS為空。然后通過比較break語句父語句塊PBS和LBS、SBS的關系,判斷出break語句是屬于循環結構還是屬于switch分支結構,從而根據對應的方法對break語句替換,以保證程序在清除完元數據之后能正常運行。具體的算法如圖4所示。

圖4 break語句插樁算法
3 工具實現
該文所述的對大規模C程序的應用理論在內存動態分析Movec上進行了實現。該工具實現采用的是基于Clang編譯器來對源代碼進行檢測邏輯的插樁,插樁過后的代碼仍然是標準C程序。同時,保證了改進過的Movec能正常地插樁和檢測大規模C程序。其架構如圖5所示。

圖5 Movec架構
在對大規模程序內存安全性進行分析時,Movec的輸入是待檢測項目和一個編譯數據庫文件,即JSON文件,輸出是插樁完整的項目Movec對該JSON進行解析,并構造出完整的文件編譯規則,將其傳遞給C解析器,構造每個文件的抽象語法樹。最后通過AST visitor對語法樹進行訪問,在語法樹上獲取需要插樁的節點位置,通過Clang提供的SourceManager接口和Rewriter接口實現內容的獲取和重寫,完成對包裝函數的插樁改進實現,對匿名結構體的插樁實現以及對break語句改進的實現,完成對項目的源代碼插樁。將該文提出的插樁改進規則應用到Movec工具上,使其能有效地對大規模C程序進行插樁,并對其進行動態內存分析。
4 實驗與分析
基于上面介紹的算法,將其在Movec上進行了實現。本節將介紹優化后的Movec對大規模程序分析的有效性和高效性。
4.1 有效性實驗
為了驗證改進部分插樁規則后工具的有效性,將Movec應用到Mibench標準測試集上。實驗平臺為64位的Ubuntu16.04操作系統,處理器為Intel(R) Core(TM) i5-7200U CPU 2.70 GHz,內存是8.00 GB,編譯器為gcc4.8.2。
選取了其中8個大規模的測試集進行實驗,并與SoftBoundCets[14]、ASan[15]、Valgrind[16]進行了對比。通過實驗表明,Movec可以正確地對這8個大規模的測試集進行安全檢測。Movec和ASan在blowfish、jpeg、rijndael和rsynth中檢測出了錯誤,但是Movec還檢測出了ASan未檢測出的錯誤,如在blowfish中的數組訪問越界錯誤:
void BF_set_key(key, int len, unsigned char* data){
unsigned char * end=&(data[len]);}
unsigned char ukey[8];
BF_set_key(&key,8,ukey);
而SoftBoundCets則對5個測試集無法正常插樁,并且其余三個沒有檢測出錯誤。Valgrind正常對程序檢測,但未發現任何錯誤。
通過結果表明,Movec對大規模程序的檢測是有效的,且沒有發生漏報和誤報。
4.2 性能實驗
本節將Movec與內存檢測工具SoftBoundCets、ASan、Valgrind進行性能對比。從Mibench中選取了規模較大的8個測試集進行對比驗證,考慮到誤差,選用了三次實驗結果去平均值的方式。實驗結果如表1所示。
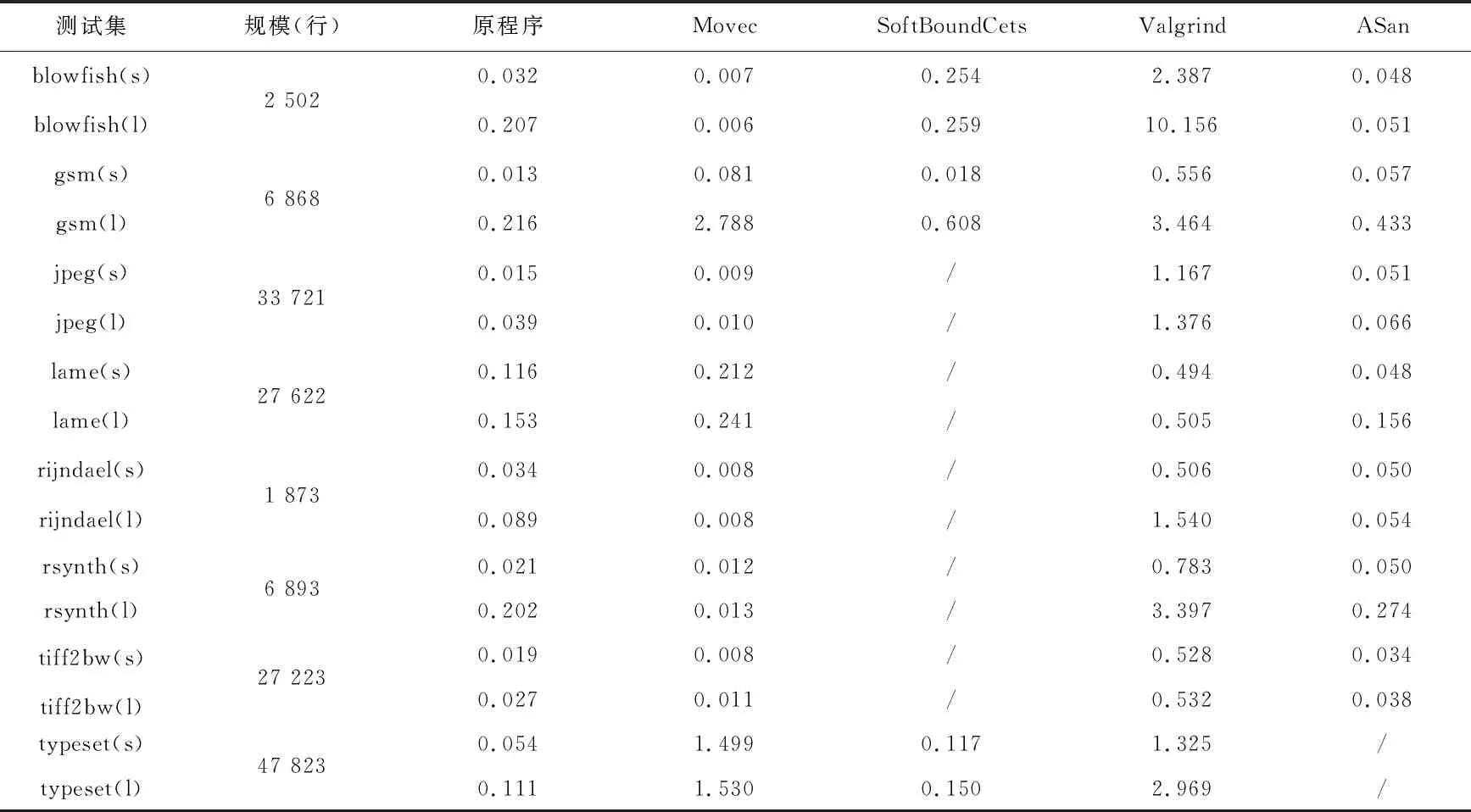
表1 運行時間對比結果
綜合表中數據可以看出,SoftBoundCet由于使用了靜態分析,其在gsm和blowfish(l)優于Movec,但它僅僅只能在其中三個測試集中運行成功;Valgrind采用的二進制代碼插樁,雖然可以成功運行在大規模C程序上,但運行時間遠遠超過Movec;ASan在gsm和lame上的性能優于Movec,但是當在檢測出錯誤的測試集中(如blowfish、jpeg、rijndael、rsynth),Movec的性能是好于ASan的。Movec還可以設置在發現錯誤后繼續運行,可以檢測出整個程序中可能存在的內存錯誤,而ASan和SoftBoundCets在發生錯誤后立即終止,導致后面的錯誤無法正常檢測。
由以上分析結果可以看出,改進后的Movec不僅能夠正確地在所有Mibench上運行,而且在有效性和高效性上都是優于其他工具的,是一個可靠的大規模C程序內存安全分析工具。
5 結束語
對大規模C程序進行動態內存分析時可能出現的問題進行了描述,并給出了相應的解決方法,然后將其在內存動態分析工具Movec上進行了實現,使其能對大規模C程序進行內存安全性檢測。通過實驗,表明Movec不僅能有效地對大規模C程序進行檢測,同時在綜合性能上是更優的。在接下來的工作中,將繼續優化其對大規模程序檢測的運行時間,例如結合靜態分析,以減少對程序不必要的插樁和檢測。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
