結合深度神經網絡與內容轉錄的語音識別研究
2021-08-02 07:40:04鄭磊
軟件導刊 2021年7期
關鍵詞:模型
鄭 磊
(山東青年政治學院信息工程學院,山東濟南 250103)
0 引言
隨著數字時代的到來,信息爆炸式增長,傳統的以文本形式保存信息的方式已經不能滿足現代人對知識的需求[1]。聲音作為一種直接記錄和掩飾信息的媒介,在實時傳遞信息的同時,將情感傳遞給信息,對信息的記錄更有價值[2]。隨著多媒體文件的大量應用,基于多媒體數據的信息檢索技術已成為信息學研究的熱點[3-5]。如何像檢索文本一樣快速、準確地從各種多媒體文檔中查找最重要的信息成為當前關注的熱點。
本文介紹了語音識別原理和相關算法。在此基礎上將深度神經網絡算法(Deep Neural Network,DNN)應用于大詞匯量連續識別系統,建立基于深度神經網絡的聲學模型關鍵詞檢測系統。在對比實驗中,將所提出的深度神經網絡模型應用于構建聲學模型,與傳統GMM-HMM 進行對比,深入分析了算法對識別系統性能的影響。
1 相關研究
關鍵詞檢測技術起源于20 世紀70 年代,最早研究是基于“給定詞”概念。語音識別作為關鍵字檢索的一項關鍵技術受到廣泛關注。2006 年,Mustafamk 等[6]提出深度學習概念。微軟研究人員將受限的Boltzmann machime(REM)和深度信念網絡(DBN)引入到語音識別聲學模型訓練中,在大詞匯量語音識別系統中取得成功[7]。
我國語音識別研究起步較晚。在國家的大力支持下,中國科學院自動化研究所、中國科學院聲學研究所等科研機構在語音識別方面進行了廣泛研究并取得顯著進展。目前,微軟、1BM、谷歌等國外公司相繼開發了中文語音識別系統[8-9],中國的公司如百度訊飛、搜狗也推出了相應的中文連續語音識別項目。語音識別技術與關鍵字檢測系統在未來有著非常廣闊的發展前景。但是,語音識別技術仍然面臨著各種挑戰,如無法有效避免語音識別錯誤等[10]。本文希望通過對基于DNN 的語音識別算法進行研究,為提高語音關鍵字檢索系統語音識別性能提供新的思路。
2 研究方法
2.1 語言識別流程和原則
一個完整的語音識別系統包括語音預處理、語音特征提取、語音模型庫構建、語音模式匹配等功能。對于錄制的語音信號,首先進行語音預處理操作。預處理包括采樣、量化、濾波、預加重、窗口加幀和端點檢測等步驟,然后進行語音信號特征提取,目的是提取能夠表征語音信號性質的特征參數,去除不相關的噪聲信號,獲得用于聲學模型或語音識別的輸入參數。語音識別和語音預處理流程如圖1 所示。
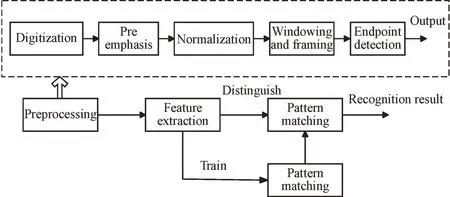
Fig.1 Speech recognition structure and speech preprocessing flow圖1 語音識別結構和語音預處理流程
2.2 語音識別算法模型基礎
語音識別的核心是聲學模式,目前主要采用隱馬爾可夫模型對語音信號的時間變化建模。HMM 每一種狀態下的觀測概率估計方法可分為離散型、半連續型和連續型。目前,語音識別系統主要是連續或半連續的。通過HMM描述聲學層模型時,隱藏狀態對應于聲學層相對穩定的語音狀態,可以描述語音信號的動態變化。
圖2 中HMM 模型有6 種狀態,其中4 種是啟動狀態,第1 種狀態表示開始狀態。每個隱藏狀態會根據概率分布向外發射一個狀態,然后轉到右邊的狀態。最右邊的結束狀態表示HMM 已經結束。在某個時間節點模型有一系列狀態。在t+1 時,模型的每個狀態都會轉到一個新的狀態,表示一個新的狀態序列。這一過程最重要的特征是T 時刻狀態只與t-1 時刻的狀態相關,這被稱為馬爾科夫。HMM 基本組成包括:①狀態集S={s1,s2,...,sN},其中N 表示音素的個數;②狀態轉移矩陣A;③表示每種狀態初始概率的輸出分布B={bj(x)} 。
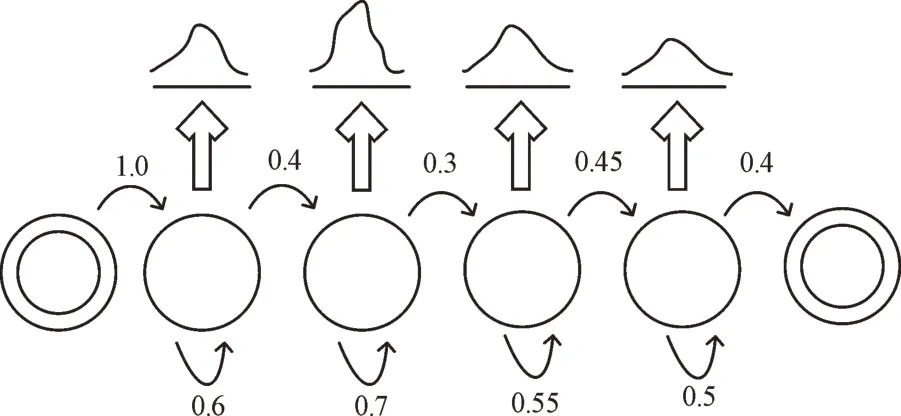
Fig.2 HMM model structure圖2 HMM 模型結構
2.3 DNN 與傳統聲學模型結合
關鍵字檢測系統通常基于大詞匯量連續語音識別器。在語音關鍵字檢索系統中,采用GMM 與HMM 相結合的GMM-HMM 模型作為LVCSR 的聲學模型,但該模型對語音信號識別率較低。隨著深度學習技術在語音識別領域的發展,利用DNN 代替GMM 形成DNN-HMM 聲學模型引起廣泛關注。DNN 模型是一種具有多層隱含層的前饋神經網絡模型。DNN 模型共有L+1 層,其中0 層為輸入層,1 到L-1 層為隱藏層,L 層是輸出層,相鄰層由前饋權值矩陣連接。
大多數情況下DNN 模型激活函數為Sigmoid 函數:

σ(z)的輸出范圍是(0.1),這有助于獲得稀疏表達式,但它使得激活值不對稱。對于多分類任務,每個輸出神經元代表一類i∈{1,2,…,C},其中C=NL是類的數量。給定訓練準則可使用眾所周知的誤差反向傳播算法提取模型參數C=N,并利用鏈式規則進行推導。模型參數采用一階導數信息,按下式進行優化:
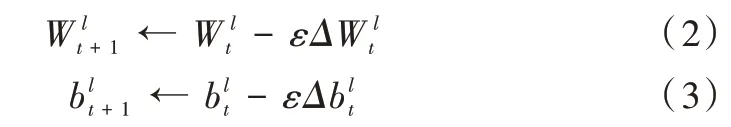
式中:和分別為第t 次迭代更新后第1 層的權值矩陣和偏差向量。
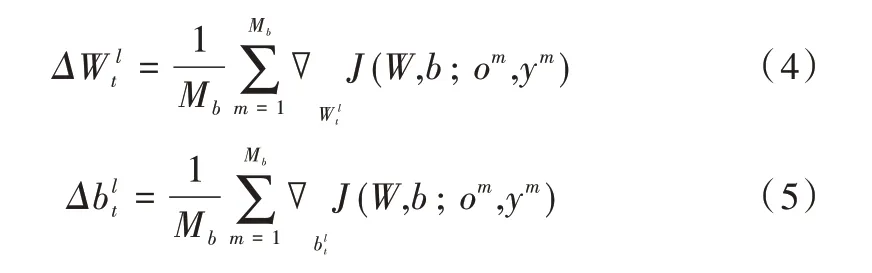
式(4)和式(5)分別為第t 次迭代后得到的平均權重矩陣梯度和平均偏差向量梯度,其中ε為學習速率,?XJ為J 相對于x 的梯度。
對于每個任務,DNN 的模型參數需要由訓練樣本S={(om,ym)|0 ≤m≤M} 進行訓練。式中M 為訓練樣本個數,om為第M 個觀察向量,ym為對應的輸出向量。這個過程稱為訓練過程或參數估計過程,需要給出一個訓練標準和一個學習算法,在語音識別任務中,通過聲學模型訓練完成這一過程。對于相鄰層間完全連通的DNN,權值初始化為一個較小的隨機值,以避免在一個擁有相同梯度的層中由于隱藏層太多而難以優化所有隱藏單元。DNN 可能需要擴展到測試數據集之外。語音符號是時間序列信號,DNN 不能直接對其建模。利用HMM 對語音信號的動態變化進行建模,利用DNN 估計觀測概率。DNN-HMM 模型結構如圖3 所示。
DNN-HMM 訓練步驟如下:①將訓練集與常規訓練的DNN-HMM 模型進行對齊,得到對齊信息;②建立上下文敏感狀態到語音ID 的映射;③根據訓練DNN 所需的輸入和輸出標簽生成信息;④獲取DNN 中需要的HMM 模型結構;⑤基于輸入和輸出標簽估計語音的先驗概率,利用反向傳播算法調整網絡參數得到DNN-HMM 模型。
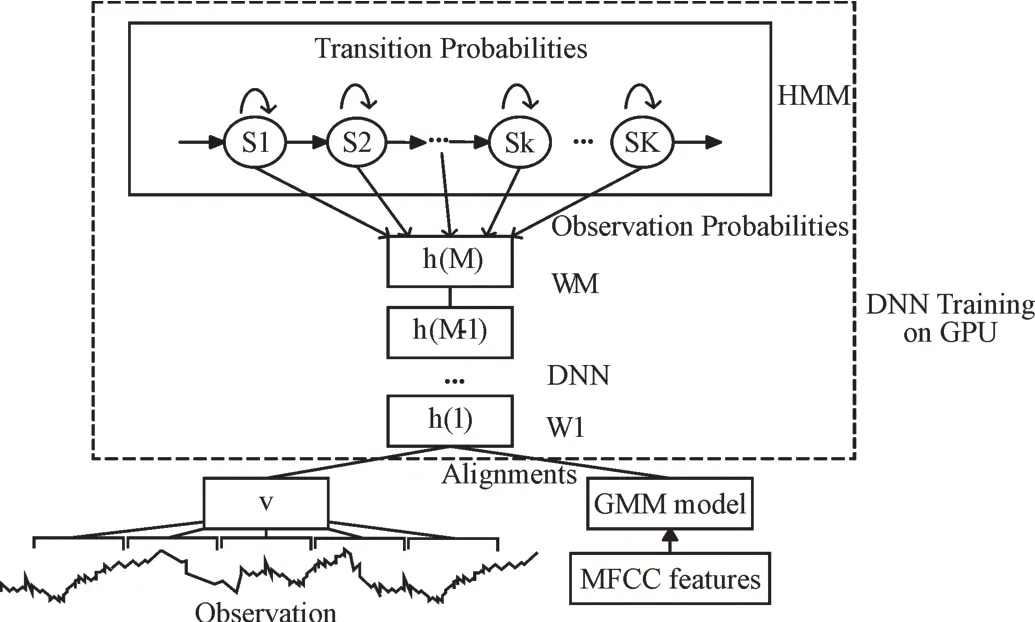
Fig.3 DNN-HMM model structure圖3 DNN-HMM 模型結構
3 實驗結果
3.1 實驗數據
本實驗選擇開源中文普通話語音數據庫aishell,對同一揚聲器的測試集執行數據庫中的語音材料。在安靜環境下使用電腦錄音軟件Cool Edit Pro 錄制語音信息,挑選8名演講者依次閱讀20 個教育詞匯,每個單詞讀10 次。采樣頻率設置為8kHz,每個采樣點被量化16 位并存儲在單聲道中,共獲得1 600 個語音樣本作為訓練和識別語料庫。以前3 道和后3 道作為訓練集,共有960 個樣本,使用中間4個樣本作為同一揚聲器測試集,共640 個樣本。
在語音信號特征提取中,從訓練集和同一說話人測試集的每個預處理語音樣本中提取24 維Mel-frequency Ceps?trum(MFC)系數特征,并采用均值方差對其進行正則化,該功能窗口大小為25ms,重疊時間為10ms。比較傳統的神經網絡模型和DNN 模型的語音識別性能,以語音識別正確率作為評價標準,數值均為統計平均值。
3.2 基于語音識別的語音關鍵字檢索系統構建
語音關鍵字檢索系統包括系統索引和關鍵字檢索。其中,索引由索引語音識別、后處理語音識別、索引構建組成。關鍵字檢索由關鍵字檢查和置信度評估兩部分組成,如圖4 所示。語音識別錯誤和外來詞嚴重影響系統的查全率,模糊匹配方法能有效提高召回率,但增加了查詢時間。在關鍵字查詢過程中,可以在超類數據庫中執行初始快速查找以縮小搜索范圍,然后在音節序列數據庫中執行精確的查詢以加快搜索速度。
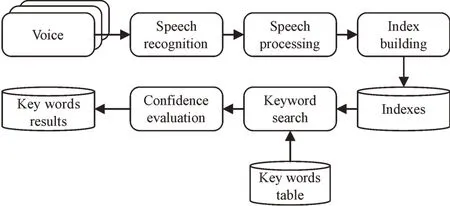
Fig.4 Composition of voice keyword retrieval system圖4 語音關鍵字檢索系統組成
語音關鍵字檢索系統依賴于識別結果,因此語音識別的性能對系統的檢索性能有著至關重要的影響。語音識別系統性能通常是通過識別錯誤率和實時率來評價的。在語音關鍵字檢索系統中,語音數據的識別過程可以離線進行而不必考慮實時指標。識別結果表明,錯誤類型包括插入錯誤、刪除錯誤和替換錯誤。將識別最佳結果與參考文本進行比較,可以得到識別錯誤率。
3.3 語音識別結果比較
語音信號特征參數的幀數設置為23,選取非線性tanh函數作為激活函數。輸出為30 個神經元,使輸出神經元的數目與待分類神經元數目相同。以估計概率分布與實際概率提取之間的高斯熵作為目標函數,當語音識別精度提高到0.2%以下時停止迭代。不同語音識別算法的識別準確率結果如表1 所示。

Table 1 Recognition accuracy of different speech recognition algorithms表1 不同語音識別算法的識別精度 (%)
如表1 所示,基于LSTM-HMM 和DNN-HMM 模型的語音識別準確率明顯高于傳統的GMM-HMM 模型,同時LSTM-HMM 模型的語音識別準確率達到96.5%,表明該模型具有更好的性能。LSTM 訓練參數大小為436 570,DNN訓練參數大小為698 100,GMM 訓練參數大小為1 226 700。在訓練集語音樣本有限的情況下,訓練模型的過擬合會導致訓練模型過擬合問題。因此,基于DNN 的語音識別可以減小訓練參數大小,有效避免訓練模型的過擬合。
語音信號具有很強的隨機性,同一語音單元擴展的語音特征參數及幀數可能不同,規則幀數對不同算法識別性能的影響如圖5 所示。隨著規則幀數的增加,輸入與原始特征參數的距離越來越近,兩種網絡模型的識別精度不斷提高。模型是通過隨機梯度下降法計算均方誤差,然后通過調整網絡參數減小均方誤差來實現。因此,網絡模型的收斂性直接反映了整體性能是否優越。
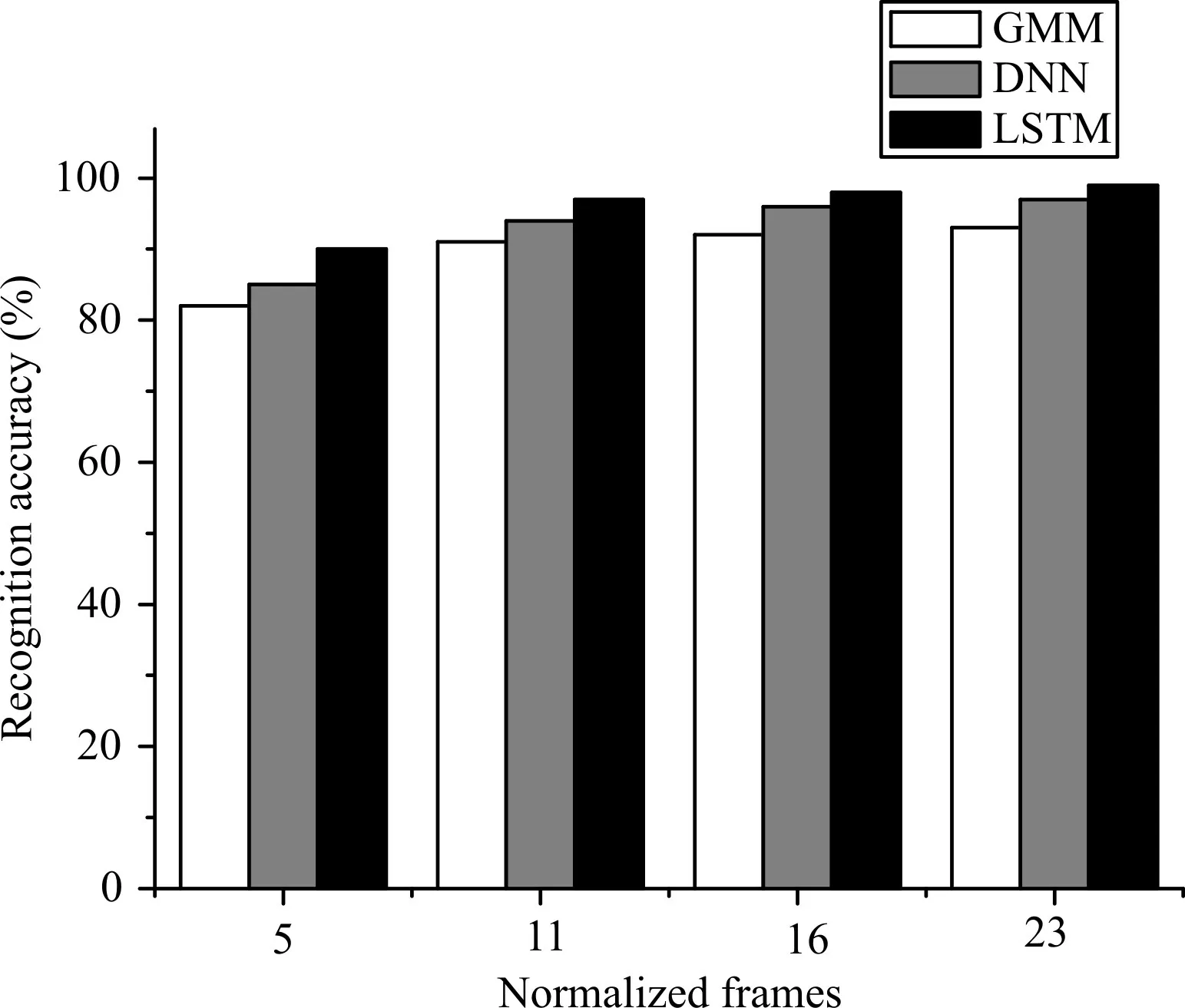
Fig.5 Influence of regular frame number on recognition performance of different algorithms圖5 規則幀數對不同算法識別性能的影響
4 結語
為解決傳統關鍵字檢測系統中GMM-HMM 聲學模型的低識別率問題,本文將基于DNN 的語音識別算法應用于關鍵字檢測。使用DNN-HMM 聲學模型代替原系統中的GMM-HMM 模型,并在此基礎上對關鍵字檢測進行研究。通過對比實驗選擇一個開源普通話語音數據庫——aishell,它是在同一個揚聲器的測試裝置上播放的。在安靜環境下,使用電腦錄音軟件Cool Edit Pro 錄制語音信息。實驗表明,基于LSTM-HMM 模型和DNN-HMM 模型的語音識別準確率分別為96.5% 和91.6%,顯著高于GMMHMM 的78.5%,說明本文提出的LSTM-HMM 模型性能更好。在訓練集語音樣本有限的情況下,會產生訓練參數尺度過大、訓練模型過擬合問題。基于DNN 的語音識別算法可以減小訓練參數尺度,從而有效避免訓練模型過擬合問題。
基于LSTM-HMM 的語音識別技術具有較高的準確率,更適合于語音關鍵字檢索。但在復雜語音環境下,關鍵字檢測的魯棒性仍有很大的提升空間。因此,后續研究可以探索提取更魯棒的聲學特征方向,在有噪聲干擾的情況下準確檢索所需的語音信息。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
