基于BERT-FLAT-CRF 模型的中文時間表達(dá)式識別
2021-08-02 07:40:12朱樂俊王衛(wèi)民
軟件導(dǎo)刊 2021年7期
朱樂俊,王衛(wèi)民
(江蘇科技大學(xué) 計算機(jī)學(xué)院,江蘇 鎮(zhèn)江 212003)
0 引言
時間表達(dá)式在日常語句中十分常見,在語句理解中扮演著非常重要的角色。在自然語言中,時間是重要的語義載體,揭示事件從發(fā)生、發(fā)展到結(jié)束的過程[1]。有效識別時間表達(dá)式對于后續(xù)時間序列分析、事件抽取、智能對話理解均有重要作用。近年來人工智能的眾多應(yīng)用,包括智能客服、對話機(jī)器人等都離不開對時間信息的理解。比如在客服系統(tǒng)中包含時間信息的問句:“下個星期五暢游天翼活動還有嗎”,又或者在對話機(jī)器人中發(fā)出指令“幫我訂張星期三上午的火車票”,在此類情況中都需要準(zhǔn)確理解時間信息。
文本中時間表達(dá)式識別難點主要在于邊界難以劃分,通常主要采取兩種方式進(jìn)行識別。第一種為基于規(guī)則的方法,利用時間表達(dá)式語法結(jié)構(gòu)特點構(gòu)造一系列規(guī)則進(jìn)行匹配,可解釋性強(qiáng),但維護(hù)難度很大;第二種方式為基于機(jī)器學(xué)習(xí)的方法,一般采用條件隨機(jī)場與隱馬爾可夫模型以及最大熵模型,將時間表達(dá)式識別轉(zhuǎn)變?yōu)樾蛄袠?biāo)注問題。本文利用機(jī)器學(xué)習(xí)方法,在使用條件隨機(jī)場的情況下加入詞向量表達(dá)能力更加強(qiáng)大的預(yù)訓(xùn)練語言模型,并將時間詞匯的特征編碼代入深度學(xué)習(xí)模型中,使時間表達(dá)式識別效果大幅提升。
1 相關(guān)工作
時間表達(dá)式是自然語言處理中的基礎(chǔ)任務(wù),在信息抽取中具有重要地位,國內(nèi)外學(xué)者對此開展了一系列研究。國外相關(guān)評測舉辦較早,最早可追溯到2004 年TERN(TE Recognition and Normalization Challenge)評測活動舉辦,后續(xù)又相繼舉辦了ACE(Automatic Content Extraction Chal?lenge)評測活動,緊接著從2007 開始舉辦了一系列TempE?val 評測活動,產(chǎn)生了一大批性能良好的英文時間表達(dá)式識別方法。例如由德國海德堡大學(xué)Strotgen 等[2]開發(fā)的具有多語言特點的處理系統(tǒng)HeidelTime,該開源系統(tǒng)利用詞性標(biāo)注和手動設(shè)置的規(guī)則進(jìn)行時間表達(dá)式識別與標(biāo)準(zhǔn)化;Chang 等[3]提出一種3 層時間模式語言。首先識別單個標(biāo)記,然后將標(biāo)記擴(kuò)展為字符串,最后對字符串進(jìn)行組合和過濾以獲取時間表達(dá)式;Bethard[4]提出使用一系列詞素語法特征與字母數(shù)字子類劃分的時間類型,優(yōu)化時間信息識別;Angeil 等[5]提出了一種通過概率上下文無關(guān)文法識別和解析時間表達(dá)式,定制了專注于時間信息的時間文法對時間表達(dá)式進(jìn)行識別和標(biāo)準(zhǔn)化處理;Lee 等[6]根據(jù)組合范疇學(xué)語法定制時間語法,具有高效定制化的特性,可清晰表達(dá)時間信息,但系統(tǒng)構(gòu)建與維護(hù)存在困難,也不具有較好的移植性;Zhong 等[7]不再使用固定的方法設(shè)計相應(yīng)規(guī)則,而是通過使用一組與時間相聯(lián)系的時間觸發(fā)詞觸發(fā)時間表達(dá)式,并通過通用規(guī)則啟發(fā)式擴(kuò)展邊界;在最新的英文時間表達(dá)式識別中,Ding 等[8]以詞類型序列作為表達(dá)式模式,提出了基于模式的時間表達(dá)式識別方法。
相較于英文時間表達(dá)式識別工作,中文時間表達(dá)式識別因相關(guān)測評語料缺乏而起步相對較晚。賀瑞芳等[9]將依存分析與錯誤驅(qū)動的方式相結(jié)合,通過錯誤驅(qū)動的方式不斷改造模型中時間表達(dá)式的錯誤標(biāo)注,后續(xù)又提出了啟發(fā)式錯誤驅(qū)動方法;鄔桐等[10]在觀察時間表達(dá)式結(jié)構(gòu)特點后,提出“時間基元”概念,將其時間單位細(xì)化并運(yùn)用于規(guī)則構(gòu)造;劉莉等[11]將語義角色特征融合于機(jī)器學(xué)習(xí)模型CRF 中的識別時間表達(dá)式;吳瓊等[12]提出了將條件隨機(jī)場與時間詞庫相結(jié)合的方式進(jìn)行時間識別,為解決時間表達(dá)式識別提供新思路;高源等[13]提出將時間詞典細(xì)分為時間詞詞典和時間單位詞典,優(yōu)化詞典特征與模型融合,最后結(jié)合了依存分析的方式識別時間短語;金博文[14]提出使用BiLSTM-CRF 模型識別時間表達(dá)式;宋國民等[15]通過構(gòu)建時間信息正則表達(dá)式規(guī)則,利用表達(dá)式匹配的方式實現(xiàn)時間信息識別。
本文基于中文時間表達(dá)式現(xiàn)有研究,進(jìn)一步提出基于BERT-FLAT-CRF 模型的中文時間表達(dá)式識別。該方法利用預(yù)訓(xùn)練語言模型BERT 作為字符嵌入的向量表示,有效解決信息長距離依賴問題,可獲取潛在的上下文語義關(guān)系,為下游識別任務(wù)提供豐富的語義特征;利用FLAT 模型將時間詞匯的特征編碼代入深度學(xué)習(xí)模型,將字符特征與詞匯特征融合,增強(qiáng)其邊界信息,可有效提升對時間表達(dá)式邊界的劃分能力。
2 BERT-FLAT-CRF 模型構(gòu)建
隨著深度學(xué)習(xí)的快速發(fā)展,在自然語言處理領(lǐng)域內(nèi)出現(xiàn)了預(yù)訓(xùn)練的語言模型,其強(qiáng)大的詞向量表達(dá)能力在多個自然語言處理任務(wù)中達(dá)到了最優(yōu)效果,因為其訓(xùn)練語料龐大,即使在小樣本中也有非常不錯的效果,因此將其引入到時間表達(dá)式識別中,并且在預(yù)訓(xùn)練模型中引入時間詞匯特征,最后使用BERT 與FLAT 及條件隨機(jī)場模型識別時間表達(dá)式。BERT-FLAT-CRF 整體網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示。模型整體分為BERT 層、FLAT 層和CRF 層,BERT 層可有效獲得上下文相關(guān)向量表示,F(xiàn)LAT 層融合時間詞匯特征,CRF層能有效聯(lián)合標(biāo)簽序列,使其輸出正確的標(biāo)簽序列。
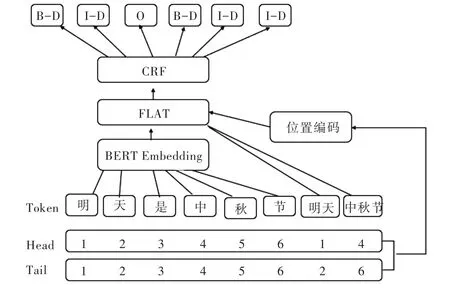
Fig.1 Structure of the BERT-FLAT-CRF model圖1 BERT-FLAT-CRF 模型結(jié)構(gòu)
2.1 Bert 層
Word2Vec[16]是深度學(xué)習(xí)技術(shù)在自然語言領(lǐng)域的一項成功應(yīng)用。作為一種詞嵌入方式,Word2Vec 將一個基于詞典長度的one-hot 編碼映射到低維語義空間,從而語義空間相似的詞能夠獲得相近距離,以便用余弦相似度等方法直接度量。但該方法無法獲得更多上下文信息,不具有詞的多義性,例如“蘋果”可以指水果,也可以指美國高科技公司。針對該問題,有研究者提出ELMO 模型[17],該模型利用雙向LSTM 抽取結(jié)構(gòu),通過動態(tài)調(diào)整雙向網(wǎng)絡(luò)結(jié)構(gòu)構(gòu)造詞向量,有效提取上下文表示,預(yù)訓(xùn)練得到具有上下文語義動態(tài)變化的詞向量,并使多個自然語言處理任務(wù)達(dá)到最優(yōu)水平。隨后Radford 等[18]提出了GPT 模型,該模型改進(jìn)了ELMO 使用的特征抽取器,LSTM 特征抽取器訓(xùn)練收斂較慢,且獲取長距離信息的能力不強(qiáng),因此GPT 使用Trans?form 特征抽取器,并將模型改造為單向,在生成任務(wù)中效果明顯改進(jìn)[19]。Devlin等[20]綜合了以上模型優(yōu)點,提出BERT模型,該模型使用雙向Transform 結(jié)構(gòu),利用MaskLM與NSP 的方式對模型進(jìn)行訓(xùn)練,在11 項任務(wù)中取得了最優(yōu)結(jié)果,證明其詞向量包含豐富的語義特征,因此本文引入該模型,其網(wǎng)絡(luò)結(jié)構(gòu)如圖2 所示。
2.1.1 BERT 輸入表示層
Bert 輸入層主要由詞嵌入、句子嵌入和位置嵌入三者向量直接相加得到輸入的序列表示。其結(jié)構(gòu)如圖3 所示。
從圖3 可以分別看到Token Embeddings 表示的單詞向量。單詞CLS 標(biāo)志具有句子向量的表示,可作為下游分類任務(wù)使用,Segment Embedding 表示該詞屬于哪個句子,可區(qū)分句子,Position Embeddings 表示模型學(xué)習(xí)到的位置向量,在Transform 中位置向量為硬編碼的加入,在BERT 模型中進(jìn)行改造,可以在訓(xùn)練中學(xué)到位置表示。
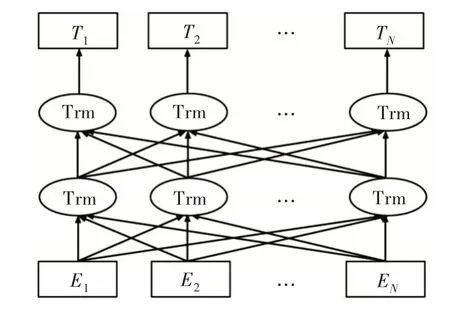
Fig.2 Bert model structure圖2 Bert 模型結(jié)構(gòu)

Fig.3 Bert input vector representation圖3 Bert 輸入向量表示
2.1.2 BERT 預(yù)訓(xùn)練任務(wù)
BERT 預(yù)訓(xùn)練任務(wù)主要包含兩個任務(wù),一個是遮蔽語言模型(Masked Language Model),另一個是下一句預(yù)測(Next Sentence Prediction),兩者分別從詞級別和句子級別中進(jìn)行向量表示。
遮蔽語言模型基于GPT 單向模型進(jìn)行改進(jìn),使模型能夠有效進(jìn)行雙向編碼,但在模型預(yù)測過程中可通過雙向編碼看到待預(yù)測詞,因此需遮蔽待預(yù)測詞,隨機(jī)遮蔽輸入中的n 個詞,然后利用雙向LM 預(yù)測這些詞,遮蔽的詞匯數(shù)量需謹(jǐn)慎考慮,如數(shù)量太少,則每次目標(biāo)函數(shù)包含的詞太少,訓(xùn)練時需迭代多次;若遮蔽過多,將導(dǎo)致背景信息丟失過多,與預(yù)測場景不符。因此BERT 提出隨機(jī)遮蓋15%的詞,利用模型預(yù)測遮蓋的部分詞匯中只有80% 的詞會被masked token 取代,還有10%會隨機(jī)用詞匯替代,剩下10%保持不變,依舊使用原來位置的詞。
下一句預(yù)測主要目的是為了學(xué)習(xí)兩個句子之間的關(guān)系,BERT 策略是在模型中訓(xùn)練一個二分類模型,在分類任務(wù)中為模型設(shè)置50%的概率,從相應(yīng)語料庫中抽取上下文連續(xù)的兩句話,利用剩下50%的概率從語料庫中抽取上下文不相關(guān)的兩句話,然后使模型預(yù)測這兩句話是否上下文相關(guān),通過該方式BERT 可學(xué)習(xí)到句子級別的向量表示。
2.2 FLAT 層
隨著命名實體識別的快速發(fā)展,需要將詞匯信息融入到深度學(xué)習(xí)模型。BERT 是基于字符的嵌入編碼,無法有效融合詞匯特征。在中文實體識別中,由于分詞錯誤將擴(kuò)大誤差,因此一般基于字符的編碼形式優(yōu)于基于詞匯編碼的序列標(biāo)注的建模方法。但同時如果不引入詞匯信息,由于樣本較小,基于序列標(biāo)注的方法效果欠佳。引入詞匯信息可大幅強(qiáng)化實體邊界,有效捕捉較長的時間表達(dá)式邊界。詞匯信息引入方式主要有兩種:一種為設(shè)計動態(tài)的抽取框架,可以兼容詞匯信息輸入;另一種與框架無關(guān),只需在嵌入層融合詞匯信息。
本文模型采用第一種方式,通過設(shè)計相應(yīng)結(jié)構(gòu)融入詞匯信息。這種方式最早可追溯到Zhang 等[21]提出的一種融合詞匯信息的Lattice LSTM 模型,通過詞匯信息匹配輸入的句子時,會獲得一個網(wǎng)狀式結(jié)構(gòu)。Lattice 實際上是一個有向的無環(huán)圖,通過詞匯開始和結(jié)束字符有效界定格子位置。但由于Lattice LSTM 自身結(jié)構(gòu)原因,存在部分信息損失、計算性能較低。
針對LatticeLSTM存在的問題,李孝男等[22]提出了FLAT(Flat-Lattice Transformer)模型,能夠無損地引入詞匯信息,通過使用位置編碼的方式融合Lattice 結(jié)構(gòu),對于每一個字符和詞匯都為其構(gòu)建頭位置編碼與尾位置編碼形式。該方式可使建模字符與所有匹配詞匯信息有效交互,并設(shè)計了字符和詞匯之間的3 種關(guān)系:交叉、包含、分離,然后將其表示為一個稠密的向量,利用head[i]和tail[i]表示字符和詞匯頭尾位置,從4 個不同的角度計算xi和xj的距離。
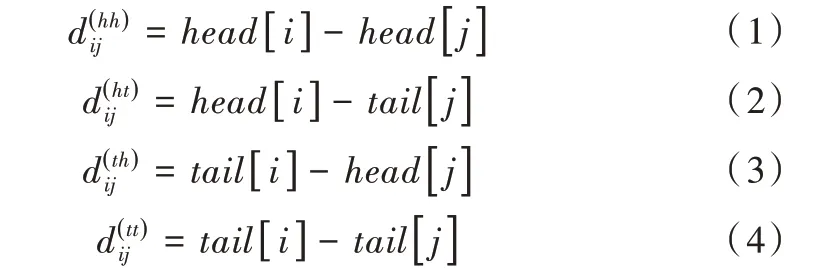
從式(1)—(4)得到4 個相對距離矩陣,其中表示xi開始位置與xj開始位置的距離,其余三者與此類似,然后將這4 個距離進(jìn)行拼接再作一個非線性變換,得到xi與xj的位置編碼向量Rij,如公式(5)所示。
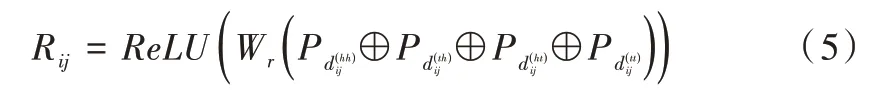
其中Pd采用的是Transformer 中絕對位置編碼。
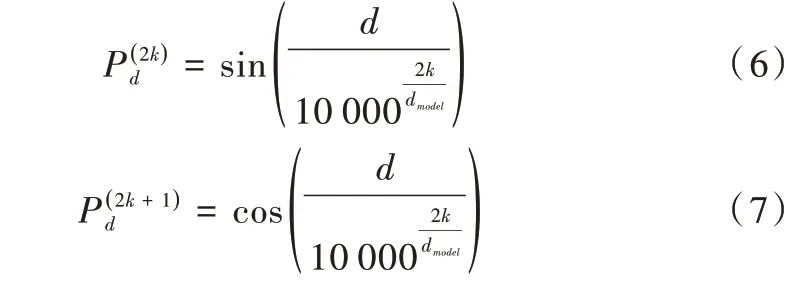
因此字符與詞匯之間可以充分且直接交互,使用Transformer-XL[23]中基于相對位置編碼的self-attention 機(jī)制完成編碼,最后取出字編碼表示,將其輸入CRF 層進(jìn)行解碼得到預(yù)測的序列標(biāo)簽。
2.3 CRF 層
針對該層網(wǎng)絡(luò)結(jié)構(gòu)引入序列標(biāo)注模型中常用的條件隨機(jī)場算法。利用BERT 與FLAT 模型尋找時間表達(dá)式邊界問題,針對相鄰標(biāo)簽之間的關(guān)系,可用條件隨機(jī)場確定并進(jìn)行約束,取得全局最優(yōu)標(biāo)記序列。
首先需將輸入X=(x1,x2,…,xm)輸入CRF 層,大小為n的全連接層得到詞語標(biāo)簽分?jǐn)?shù)矩陣sc ∈Rn*n,si j代表詞語序列第i個字預(yù)測為標(biāo)簽j的分?jǐn)?shù),假設(shè)X的正確標(biāo)簽序列為Y=(y1,y2,…,ym),計算正確標(biāo)簽序列的分?jǐn)?shù)S(X,Y)為:
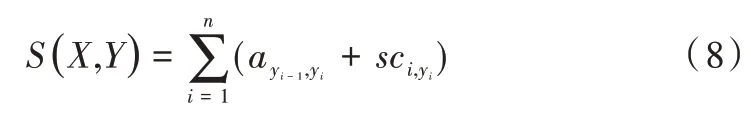
然后通過Softmax 函數(shù)歸一化得到y(tǒng)序列標(biāo)簽的最大概率,如式(9)所示。
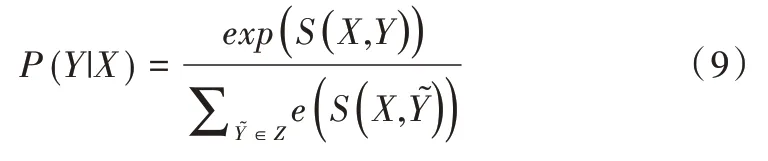
其中,Z代表X所有可能的標(biāo)簽序列。最后取得最大化正確標(biāo)簽序列的似然概率。
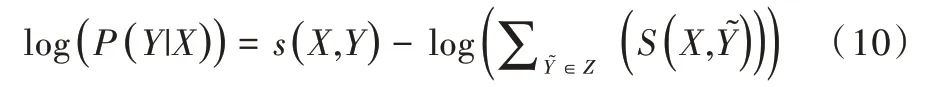
根據(jù)公式(10)求得的損失計算梯度,不斷優(yōu)化,將損失降到最小,使其預(yù)測正確標(biāo)簽的概率盡可能大以調(diào)整參數(shù)、優(yōu)化目標(biāo)。在模型訓(xùn)練后,使用維特比算法求出概率最大的一條標(biāo)簽序列作為最終預(yù)測標(biāo)簽,即可得到標(biāo)簽序列識別時間表達(dá)式。
3 實驗及評估標(biāo)準(zhǔn)
3.1 實驗語料
本文使用2010 年SemEval-2010 評測TempEval-2 任務(wù)中的中文語料數(shù)據(jù)集。在TempEval-2 的任務(wù)語料中共有44 篇訓(xùn)練文檔和15 篇測試文檔,作為與其他實驗方法的對比語料。
同時由于TempEval-2 語料較少,本文從中文百度百科中隨機(jī)爬取文檔并利用斯坦福分詞器對文檔進(jìn)行詞性標(biāo)注工作,獲得所有具有時間詞標(biāo)注的句子,并人工修正標(biāo)注相應(yīng)標(biāo)簽,共獲得3 352 條帶有時間表達(dá)式的句子,時間表達(dá)式數(shù)量為3 646 個,以此驗證本文模型在深度學(xué)習(xí)模型中同樣具有非常好的效果。本文數(shù)據(jù)集按照8∶2 的方式劃分為訓(xùn)練集和測試集。將2 681 條句子劃分為訓(xùn)練集,
671 條句子為測試集。
3.2 標(biāo)注體系
在用序列標(biāo)注的方法進(jìn)行命名實體識別時,最常用的兩種標(biāo)簽體系分別為BIO 和BIOES,本文采用較為簡潔的BIO 標(biāo)簽方式,在時間類別方面依舊采用SemEval2010(Se?mantic Evaluations)task 13 中的方法,將時間表達(dá)式類別分為Duration、Set、Time、Date,時間類型說明如表1 所示。BIO標(biāo)注模式中的B 表示實體開始,I 表示實體中間與結(jié)尾,O表示非實體部分,時間表達(dá)式類型可劃為4 種類別,因此需將標(biāo)簽的體系分為9 種,分別為B-T,I-T 表示時間,B-D,ID 表示日期,B-S,I-S 表示重復(fù)時間,B-U,I-U 表示持續(xù)時間,O 為非時間表達(dá)式部分。本文時間表達(dá)式識別使用的數(shù)據(jù)標(biāo)注示例如表2 所示。

Table 1 Type description of time表1 時間類型說明
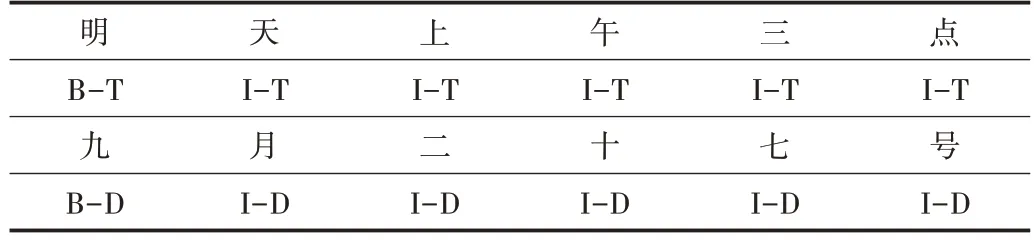
Table 2 Time expression annotation examples表2 時間表達(dá)式標(biāo)注示例
3.3 評估標(biāo)準(zhǔn)
采用正確率P、召回率R 以及F 值作為本文實驗評測標(biāo)準(zhǔn)。

3.4 實驗環(huán)境
本文實驗操作系統(tǒng)為Ubuntu,實驗詳情如表3 所示。
Table 3 Experimental environment表3 實驗環(huán)境
3.5 實驗參數(shù)
在Bert 模型中本文選擇中文預(yù)訓(xùn)練BERT-Base 中文版本進(jìn)行實驗,模型共有12 層,隱含層有768 維度,12 個注意力頭,有110M 參數(shù),最大序列長度選擇128,batch-size選擇16,學(xué)習(xí)率為5e-5,為防止過擬合采用dropout 為0.5。
3.6 實驗結(jié)果與分析
在TempEval-2 語料下,本文與文獻(xiàn)[10]基于語義角色標(biāo)注的識別、文獻(xiàn)[11]基于“時間基元”的時間表達(dá)式識別以及文獻(xiàn)[13]基于詞典特征優(yōu)化和依存關(guān)系的中文時間表達(dá)式識別進(jìn)行比較,這些方法多為規(guī)則和傳統(tǒng)機(jī)器學(xué)習(xí)方式,本文通過引入深度學(xué)習(xí)預(yù)訓(xùn)練語言模型、融合時間詞匯特征,有效提升模型識別精度。比較結(jié)果如表4 所示。

Table 4 Comparison with the traditional time expression recognition method表4 與傳統(tǒng)時間表達(dá)式識別方法比較
如表5 所示,在深度學(xué)習(xí)模型中本文方法同樣具有較好的效果。
基于IDCNN-CRF、BiGRU-CRF、BiLSTM-CRF、LSTMCNN-CRF 等模型的實際效果相差不大,因為沒有引入自然語言處理中的預(yù)訓(xùn)練語言模型,其詞向量表達(dá)能力有限,且捕捉長距離依賴的能力不強(qiáng),基于Bert-CRF 的模型雖然引入了Bert 模型,較好地解決了長距離依賴與詞向量表達(dá)局限性,但因為基于字符嵌入,并沒有融合時間詞匯特征,而本文基于BERT-FLAT-CRF 的模型融合了時間詞匯特征,進(jìn)一步提高了對時間表達(dá)式的識別能力。
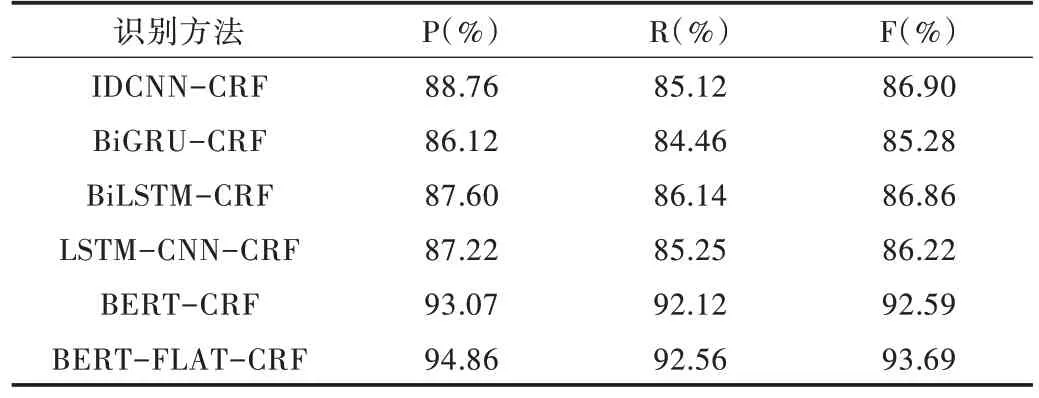
Table 5 Comparison with deep learning model recognition methods表5 與深度學(xué)習(xí)模型識別方法比較
4 結(jié)語
本文針對時間表達(dá)式在傳統(tǒng)機(jī)器學(xué)習(xí)方法中需構(gòu)造大量規(guī)則且標(biāo)注數(shù)據(jù)集較少、識別困難的問題,提出了一種基于BERT-FLAT-CRF 深度學(xué)習(xí)網(wǎng)絡(luò)架構(gòu)的識別方法。在TempEval-2 數(shù)據(jù)集中,本文方法可獲得更高的正確率93.12%和召回率92.25%,在基于自建數(shù)據(jù)集的實驗中與其它深度學(xué)習(xí)模型進(jìn)行比較,證明本文模型在加入時間詞匯特征后表現(xiàn)最佳,為中文時間表達(dá)式識別問題提供了新的解決方案。下一步將繼續(xù)挖掘中文時間表達(dá)式特點,探索在標(biāo)簽上采用成分標(biāo)簽方案的可行性,使時間表達(dá)式結(jié)構(gòu)特點得到充分利用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
