基于Python 與MATLAB 混合編程的文本分類應(yīng)用案例設(shè)計
2021-08-02 07:40:14劉衛(wèi)國
軟件導(dǎo)刊 2021年7期
劉衛(wèi)國,陳 斌
(1.中南大學(xué) 計算機(jī)學(xué)院;2.中南大學(xué) 自動化學(xué)院,湖南 長沙 410083)
0 引言
Python 和MATLAB 是當(dāng)今較為流行的兩種編程工具,并各具特點(diǎn)。Python 語言簡潔優(yōu)雅、具有獨(dú)特的功能特征[1],且作為開源語言,擁有許多功能強(qiáng)大的第三方函數(shù)庫,開發(fā)效率高;MATLAB 以矩陣運(yùn)算為基礎(chǔ),具有科學(xué)計算、圖形繪制、數(shù)據(jù)分析等功能[2],且擁有大量學(xué)科性工具箱以及Simulink 仿真工具。很多學(xué)者也對其進(jìn)行了研究,如文獻(xiàn)[3]設(shè)計了基于Python 的機(jī)器學(xué)習(xí)教學(xué)案例;文獻(xiàn)[4]利用Python 實(shí)現(xiàn)網(wǎng)絡(luò)爬蟲案例并將其應(yīng)用于教學(xué)中;文獻(xiàn)[5]利用MATLAB 設(shè)計了概率論課程教學(xué)案例。MAT?LAB 語言有別于傳統(tǒng)意義上的通用程序設(shè)計語言,通常應(yīng)用于學(xué)科層面,具備與學(xué)科結(jié)合的天然優(yōu)勢[6]。在Python或其他語言中,通過調(diào)用MATLAB 引擎執(zhí)行MATLAB 程序可以擴(kuò)展語言功能。
在Python 與MATLAB 教學(xué)中,結(jié)合兩種語言混合編程,可以靈活設(shè)計適合各學(xué)科應(yīng)用的教學(xué)案例,使學(xué)生在案例實(shí)現(xiàn)過程中深刻體會兩種語言各自特點(diǎn)。本文以文本分類為例,介紹利用混合編程設(shè)計教學(xué)案例的方法。
1 Python 與MATLAB混合編程
實(shí)現(xiàn)Python 與MATLAB 混合編程,需要在Python 中啟動MATLAB 引擎,從而在Python環(huán)境中調(diào)用MATLAB 函數(shù)。
1.1 MATLAB 引擎啟動
啟動MATLAB 引擎之前,必須給Python 安裝MATLAB引擎。通過針對Python 的MATLAB 引擎API,可在Python中將MATLAB 作為計算引擎來調(diào)用。需要注意的是,不同版本的MATLAB 引擎分別支持不同版本的Python 環(huán)境,本文使用MATLAB R2016a 和Python 3.4 實(shí)現(xiàn)混合編程。
MATLAB 提供了Python 腳本文件setup.py 用于編譯與安裝MATLAB 引擎。以Window 操作系統(tǒng)為例,首先在命令提示符下將當(dāng)前目錄切換至MATLAB 軟件所在磁盤,再使用cd 命令進(jìn)入MATLAB 安裝文件夾的setup.py 所在文件夾,例如cd D:matlab2016extern enginespython,最后使用python setup.py install命令安裝MATLAB 引 擎。
安裝好MATLAB 引擎后,需要在Python 中啟動MAT?LAB 引擎,具體代碼如下:

1.2 MATLAB 函數(shù)調(diào)用
利用MATLAB 引擎對象名在Python 環(huán)境中調(diào)用MAT?LAB 函數(shù),調(diào)用格式為:
引擎對象名.函數(shù)名(函數(shù)參數(shù))
在Python 中使用MATLAB 引擎調(diào)用MATLAB 的gcd 函數(shù),求兩個數(shù)的最大公約數(shù),具體命令如下:
e1.gcd(30,56)#調(diào)用MATLAB 函數(shù)gcd 求30 與56 的最大公約數(shù),返回值為2
2 樸素貝葉斯文本分類算法
樸素貝葉斯算法(Naive Bayes,NB)是基于貝葉斯定理與特征條件獨(dú)立性假設(shè)的分類方法[7]。使用NB 進(jìn)行文本分類,首先提取各文本中能體現(xiàn)內(nèi)容的單詞組成詞匯集合,并將每個單詞出現(xiàn)次數(shù)作為一個特征,然后把每個文本表示成一個單詞的數(shù)字向量,其值為文本中該單詞出現(xiàn)次數(shù),接著使用數(shù)值計算條件概率,計算公式如下[8]:
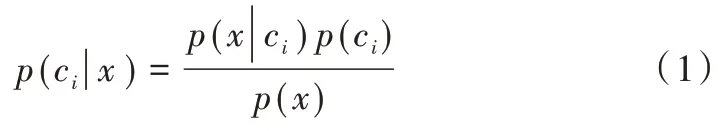
其中,x表示單詞的數(shù)字向量,ci表示第i種類別的文本。使用該公式計算文本屬于各類別的概率,并選擇概率最大的一種類別作為文本分類結(jié)果。概率p(ci)等于第i類文本數(shù)除以所有文本數(shù);條件概率p(x|ci)表示在已知文本類別的條件下,向量x中的單詞出現(xiàn)概率[9]。由于假設(shè)向量x中各特征量相互獨(dú)立,所以可使用p(x0|ci)p(x1|ci)p(x2|ci)…p(xn|ci)計算得到條件概率p(x|ci)[10]。
3 利用混合編程實(shí)現(xiàn)文本分類算法
本文以SMSSpamCollection數(shù)據(jù)集[11]中50篇不同短信文本作為分類對象,其中有25篇文本屬于垃圾短信,剩下的25 篇屬于合法短信。以文本中的英文單詞作為特征,1 表示垃圾短信,0 表示合法短信。
主要算法流程用Python 結(jié)合NLTK 第三方庫加以實(shí)現(xiàn),其中的分類器訓(xùn)練及文本分類函數(shù)用MATLAB 語言編寫。首先提取所有文本中的英文單詞詞干,生成一個涵蓋所有文本的單詞集合;然后依據(jù)該單詞集合,以單詞出現(xiàn)頻率為特征生成描述各文本的單詞向量集;將向量集隨機(jī)分為訓(xùn)練集和測試集,使用訓(xùn)練集訓(xùn)練文本分類器,再使用交叉驗證方法隨機(jī)選取10 個文本作為測試集,測試訓(xùn)練所得分類器的性能。文本分類過程如圖1 所示。
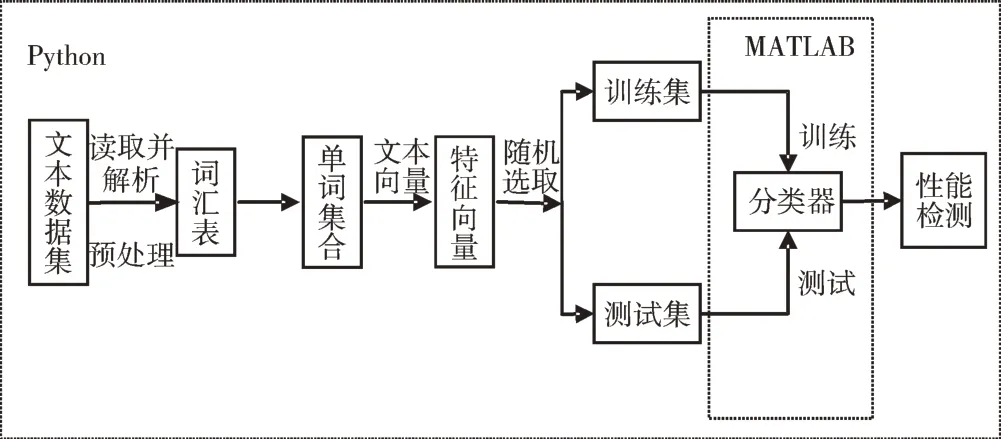
Fig.1 Process of text classification by Naive Bayes圖1 樸素貝葉斯文本分類過程
3.1 文本讀取與解析
讀取并解析文本是將文檔中的文本導(dǎo)入Python 中,以便于后續(xù)操作。使用Python 的open()和read()函數(shù)并結(jié)合for 循環(huán)結(jié)構(gòu),依次打開并讀取存放在spam 和ham 文件夾下的短信文檔。同時使用自定義文本預(yù)處理函數(shù)conten?tHandle 對讀取的文檔進(jìn)行預(yù)處理,再使用append()函數(shù)將處理后的文檔擴(kuò)展至contentList 列表中,并使用列表classList 依次記錄擴(kuò)展文檔類型。具體程序如下:


3.2 文本預(yù)處理
文本預(yù)處理是為了從每篇文檔中選出合適的單詞構(gòu)成詞匯表,本文的預(yù)處理過程包括文本切分、單詞規(guī)范化與過濾以及單詞詞干提取。
調(diào)用Python 的read()方法讀取文件內(nèi)容時,會返回一個涵蓋整個文本內(nèi)容的字符串。要想得到文本中的單詞,需要使用split()方法配合正則表達(dá)式切分文本字符串。切分之處為非字母和數(shù)字字符的任意字符串,切分后可得到由單詞構(gòu)成的詞表。
文本中單詞大寫字母的出現(xiàn)位置有時會不同,對構(gòu)建詞表和去除停用詞將有所影響,需調(diào)用lower()方法把詞表中的單詞全部轉(zhuǎn)換成小寫[12]。同時為避免空格和切分產(chǎn)生碎小單詞,只保留長度大于2 的單詞。導(dǎo)入NLTK 模塊中的英文停用詞表,返回不在停用詞表中的單詞[13],以提高詞表的文本內(nèi)容代表性。
英文中的有些單詞是由一個詞干衍變而來的,所以把單詞轉(zhuǎn)換成相應(yīng)詞干,利用詞干建立單詞集合,使單詞向量能更精準(zhǔn)地反應(yīng)出文本類型,從而降低文本分類的錯誤率。具體程序如下:

3.3 單詞集合創(chuàng)建
單詞集合是指涵蓋全部文本的單詞總和,且各單詞在集合中有且只有一個[14],可利用Python 集合(set)數(shù)據(jù)類型消除重復(fù)元素的功能加以實(shí)現(xiàn)。首先創(chuàng)建一個空集合,然后依次求每篇文本單詞集合與已有單詞集合的并集,并不斷更新至已有單詞集合,從而得到全部文本的單詞集合。具體程序如下:

3.4 文本向量化
文本向量化是把每篇文本的單詞變成單詞集合的向量形式,向量每個元素為對應(yīng)單詞在該篇文本中的出現(xiàn)次數(shù)[15]。先創(chuàng)建與單詞集合同形且值為0 的向量,循環(huán)遍歷文本中的單詞時,如果文本中單詞出現(xiàn)在單詞集合中,則對應(yīng)單詞出現(xiàn)次數(shù)加1,最后函數(shù)返回包含各單詞在文本中出現(xiàn)次數(shù)的向量。具體程序如下:

3.5 分類器訓(xùn)練函數(shù)
分類器訓(xùn)練函數(shù)采用MATLAB 語言實(shí)現(xiàn),該函數(shù)使用訓(xùn)練集產(chǎn)生分類所需的相關(guān)數(shù)據(jù)。函數(shù)輸入?yún)?shù)為訓(xùn)練集文本單詞向量(trainSet)、訓(xùn)練集文本類型(trainClasses),輸出數(shù)據(jù)為文本屬于垃圾短信的概率(pSpam)、單詞集合詞匯分別屬于垃圾短信和合法短信的條件概率(p1V、p0V)。
在Python 環(huán)境中調(diào)用本函數(shù)時,需要在函數(shù)中對Py?thon 類型的輸入?yún)?shù)進(jìn)行轉(zhuǎn)換,使輸入?yún)?shù)可參與MAT?LAB 運(yùn)算。該函數(shù)的輸入?yún)?shù)為嵌套列表,即列表中的每個元素都為一個數(shù)字列表,MATLAB 會把該嵌套列表自動轉(zhuǎn)換為一個元胞數(shù)組,需要用cell2mat 函數(shù)把元胞數(shù)組中的每個元素轉(zhuǎn)換為MATLAB 矩陣。
輸入?yún)?shù)數(shù)據(jù)類型轉(zhuǎn)換完成后,先計算文本屬于垃圾短信的概率,再使用for 循環(huán)遍歷所有訓(xùn)練集中的文本。當(dāng)某單詞出現(xiàn)在某一類型文本中時,則更新該單詞在對應(yīng)類型文本中的出現(xiàn)次數(shù),并同時更新該類型文本單詞出現(xiàn)的總次數(shù)。最后用每個單詞出現(xiàn)在相應(yīng)類型文本中的次數(shù)除以該類型文本單詞出現(xiàn)總數(shù),即可得到各單詞分別屬于垃圾和合法短信的條件概率。具體程序如下:


3.6 分類函數(shù)
分類函數(shù)用MATLAB 語言編寫實(shí)現(xiàn),該函數(shù)用于分類測試集中的文本。函數(shù)的輸入?yún)?shù)為分類器訓(xùn)練函數(shù)返回的數(shù)據(jù)(p0V、p1V、pSpam)和待分類文本的單詞集合向量(wordsV);輸出參數(shù)為文本分類結(jié)果(result),1 表示垃圾短信文本,0 表示合法短信文本。分類函數(shù)使用樸素貝葉斯分類器在訓(xùn)練集上訓(xùn)練所得參數(shù),通過對比待分類文本屬于各類別的概率判定待分類文本類別。具體程序如下:

4 利用Python 實(shí)現(xiàn)分類器訓(xùn)練及分類函數(shù)
NumPy 是Python 的第三方庫,支持多類型矩陣的創(chuàng)建與矩陣運(yùn)算,可用來存儲與處理大型矩陣。作為對比實(shí)現(xiàn)方法,下面通過Python 調(diào)用NumPy 庫實(shí)現(xiàn)樸素貝葉斯文本分類器訓(xùn)練與文本分類。安裝NumPy 庫后使用import 語句導(dǎo)入NumPy 中的所有函數(shù)定義,命令如下:
4.1 Python 實(shí)現(xiàn)分類器訓(xùn)練函數(shù)
在Python 中編寫trainclassifier 函數(shù)實(shí)現(xiàn)樸素貝葉斯分類器訓(xùn)練,實(shí)現(xiàn)步驟和輸入?yún)?shù)與3.5 節(jié)相似。具體程序如下:

4.2 Python 實(shí)現(xiàn)分類函數(shù)
分類函數(shù)classifier 利用在訓(xùn)練集上訓(xùn)練所得參數(shù)判定文本類別,實(shí)現(xiàn)步驟和輸入?yún)?shù)與3.6 節(jié)相似。具體程序如下:
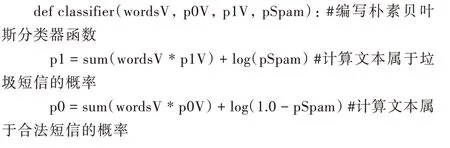

5 結(jié)果對比分析
前文分別使用混合編程方法和Python 方法實(shí)現(xiàn)文本分類算法,兩種實(shí)現(xiàn)方法的文本分類錯誤率如圖2 所示。
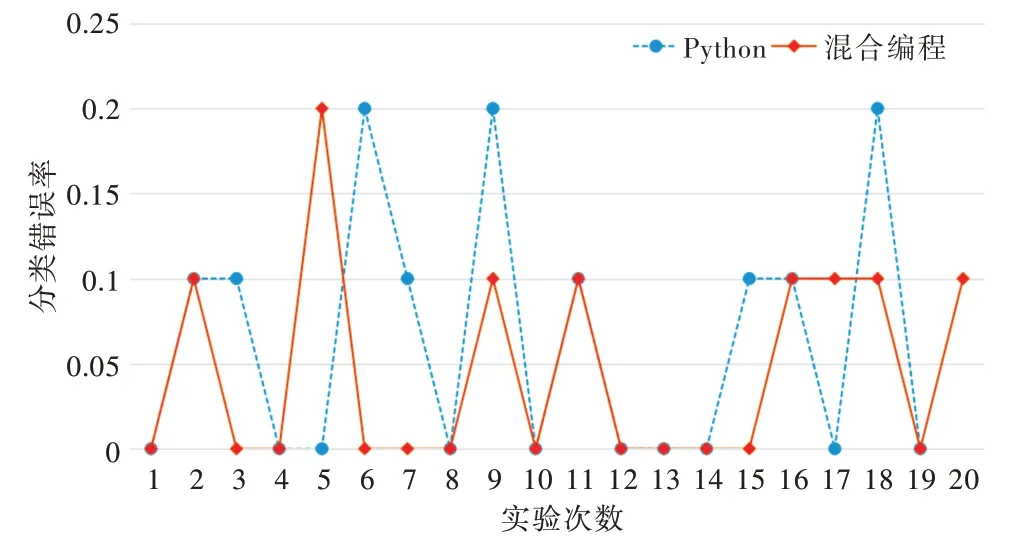
Fig.2 Comparison of classification error rate by two different methods圖2 兩種實(shí)現(xiàn)方法文本分類錯誤率
圖2 中的橫坐標(biāo)代表測試分類器次數(shù),縱坐標(biāo)代表分類器分類錯誤率,菱形代表使用混合編程方法實(shí)現(xiàn)文本分類器的分類錯誤率折線,圓形代表使用Python 實(shí)現(xiàn)文本分類器的分類錯誤率折線。由于本文采用隨機(jī)選取的短信文本測試分類器的分類錯誤率,所以每次分類錯誤率可能不一樣。重復(fù)測試兩種方法各20 次,計算其算術(shù)平均分類錯誤率,得到混合編程方法錯誤率為4.5%,Python 方法為6%,表明使用混合編程方法實(shí)現(xiàn)的文本分類器性能更穩(wěn)定,分類錯誤率更低,當(dāng)然錯誤率估計也與文本的隨機(jī)選擇及內(nèi)容有關(guān)。此外,由于Python 調(diào)用第三方庫的執(zhí)行效率高于在Python 環(huán)境中使用MATLAB 引擎調(diào)用MATLAB函數(shù),因此混合編程方法的程序運(yùn)行時間比Python 方法長。
6 結(jié)語
本文利用Python 與MATLAB 語言混合編程實(shí)現(xiàn)樸素貝葉斯文本分類算法,并與Python 調(diào)用NumPy 第三方庫實(shí)現(xiàn)方法進(jìn)行對比,分析了兩種實(shí)現(xiàn)方法的特點(diǎn)。Python 和MATLAB 語言各具特點(diǎn),混合編程是解決問題的一種重要途徑,盡管在Python 的很多應(yīng)用場景下可以借助于第三方庫的支持,但將Python 和MATLAB 的功能(如學(xué)科性工具箱)配合使用,可使問題求解方法更加靈活多樣。結(jié)合應(yīng)用案例進(jìn)行Python 或MATLAB 課程教學(xué),能使學(xué)生更深入地理解相關(guān)概念及其應(yīng)用場景,促進(jìn)課程教學(xué)與學(xué)科應(yīng)用的進(jìn)一步融合,提高學(xué)生的應(yīng)用能力。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
商周刊(2017年22期)2017-11-09 05:08:31
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
河南電力(2015年5期)2015-06-08 06:01:46
皖西學(xué)院學(xué)報(2015年5期)2015-02-28 17:52:46
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
