基于詞嵌入的源碼相似度研究
2021-08-02 07:40:22謝春麗王夢琦
軟件導刊 2021年7期
錢 程,謝春麗,王夢琦,權 雷
(1.江蘇師范大學智慧教育學院;2.江蘇師范大學計算機科學與技術學院,江蘇徐州 221116)
0 引言
隨著Github、StackOverflow 等開源代碼平臺的開放,這些開源代碼的直接獲取不可避免地引發了代碼剽竊,無形中增加了程序漏洞的傳播。高校各種在線判題系統(On?line Judge,OJ)使用過程中,學生作業以源代碼形式提交到OJ 平臺,平臺在線自動完成評測,這種方式使得學生抄襲他人代碼現象泛濫[1]。事實上,商用軟件領域抄襲的現象也愈演愈烈[1],造成了維護程序編寫者知識產權日漸困難的局面。因此,研究代碼克隆并評測代碼剽竊這一問題很有必要。文本相似度度量是解決該類問題的基礎手段,它也適用于其他領域,如文本分類[2]、信息檢索、自動代碼補充[3]等。相關文本相似度計算方法不斷被設計研究出來,比較常見的有N-gram、TF-IDF、LSA 等。
N-gram 模型注重詞數量特征,缺乏對語義的檢測[4]。武永亮等[5]提出的TF-IDF 模型通過計算詞頻權重來比較詞的重要性,但這種方法僅僅只針對文本統計信息,缺乏對詞義、結構的計算。一些其他基于關鍵詞典的方法受詞典大小限制,需要大量詞匯;而基于編輯距離的方法由于應用場景受限制,對長句的檢測、計算存在較大誤差[6]。
針對上述問題,本文選擇基于向量空間的模型,通過TF-IDF 和Word2vec 構建模型。將該模型與基于N-Gram的模型進行對比,以期盡可能考慮到文本相似度的語義因素,并對其計算結果進行比較和分析。實驗結果表明,基于向量空間的模型在檢測C++源碼相似情況的效果要優于基于詞的N-gram 模型。
1 相關工作
1.1 關鍵詞匹配方法
N-gram 是一種語言模型思想,廣泛應用于語音識別、手寫體識別、拼寫糾錯等領域。這種思想基于一個假設:在一個句子中下一個詞的出現僅依賴于前面的一個或幾個詞,而與其他任何詞不相關(即隱含馬爾可夫模型中的假設)[7]。以“好好學習,天天”為例,當出現該句子后,大部分人很容易就會接出之后的“向上”一詞,而不是其他的詞,這表明“向上”一詞的出現依賴于“好好學習,天天”的出現。
在N-gram 模型中,N 表示分解的句子中詞的數量,其中第N 個詞的出現只與前N-1 個詞有關,而與其他詞無關[8]。常用的N-gram模型有Bi-gram模型和Tri-gram模型。
(1)Bi-gram。即N=2 時的N-gram 模型(二元模型),指一個詞的出現只依賴于它前面出現的那一個詞,使用該模型對“我愛學習”這句話進行分解可得:{我,愛}、{愛,學}、{學,習}。
(2)Tri-gram。即N=3 時的N-gram 模型(三元模型),指一個詞的出現只依賴于它前面出現的那兩個詞,使用該模型對“我愛學習”這句話進行分解可得:{我,愛,學}、{愛,學,習}。
如何使用N-gram 模型對代碼進行相似度計算就要引入N-gram 距離概念。N-gram 距離通過衡量兩個句子之間的差異來實現相似度計算。按長度N 對原句進行分詞處理,得到所有長度為N(單詞數量為N)的字符串。對于兩個句子S 和T,通過計算他們公共子串的數量得到兩者的相似度。N-gram 距離計算公式如下:
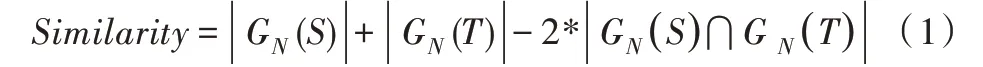
1.2 向量空間方法
本文的向量空間指將源碼文本向量化,一般通過對文本分詞、去停用詞、編碼、向量化這幾個步驟完成對文本中詞的向量化,再通過權重疊加法或模型法獲取文本(句子、段落、文章)的向量,這實際上是一種將源碼文本表示成低維、稠密、實數向量的方法。
1.2.1 TF-IDF 方法
TF-IDF 是一種統計方法,用以評估某個字詞對于一個文件集或一個文件的重要程度,其思想是:在一篇文章中,某個詞的重要性與該詞在這篇文章中出現的次數正相關,與語料庫中出現該詞的文章數負相關。
TF(Term Frequency):詞頻,指一個詞在文章中出現的頻率,表示這個詞與該文章的相關性。這個數字是對詞數的歸一化,以防止它偏向長文件。TF 值計算公式如下:

IDF(Inverse Document Frequency):逆向文件詞頻,表示一個詞語出現的普遍程度。一個詞的IDF 值可以通過文章總數除以包含該詞的文章數,再將得到的商取以10 為底的對數。但是可能存在沒有任何一篇文章包含這個詞的情況,這會導致分母為0,為了防止該情況發生,分母通常會加上1。最終的IDF 值計算公式如下:

一篇文章中某個詞的重要程度,可以標記為詞頻和逆向文件詞頻的乘積,某個詞對文章的重要性越高,它的TFIDF 值也就越大,就認為其具有很好的類別區分能力。TFIDF 值計算公式如下:
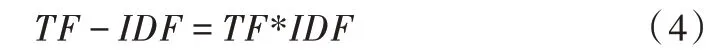
余弦相似度通過測量兩個向量夾角的余弦值確定兩個向量大致指向是否相同從而來度量它們之間的相似性,該結果與向量的長度無關,與向量的指向相關。余弦相似度常用于高維正空間,例如在信息檢索中,每個詞項被賦予不同的維度,而一個維度由一個向量表示,其各個維度上的值對應于該詞項在文檔中出現的頻率。余弦相似度因此可以給出兩篇文檔在其主題方面的相似度,計算公式如下:
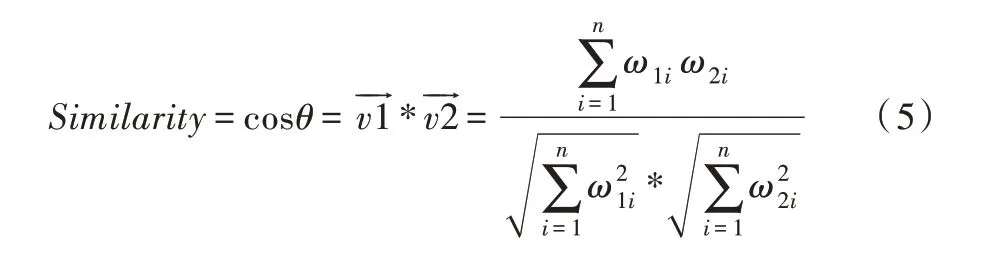
1.2.2 基于Word2vec 的代碼相似性
Word2vec 是2013 年Google 研發的一款用于訓練詞向量的工具,它將詞語用向量表示,然后映射到向量空間進行處理,其核心架構主要有CBOW 模型和Skip-gram 模型[9-10]。本文采用CBOW 模型,該模型特點是可以通過上下文來預測當前單詞,如圖1 所示。
2 模型構建
2.1 基于TF-IDF 的模型
本文結合TF-IDF 模型構建基于詞向量的模型。模型通過數據預處理器,將送入的源碼集處理成一個文本矩陣,矩陣每一行代表一篇源碼,一行中任一元素代表一個詞。隨后將文本矩陣送入TF-IDF 生成器,輸出一個TFIDF 矩陣,其中每一行同樣代表一篇源碼,一行中的每一個元素為詞的TF-IDF 值。最后送入相似度矩陣生成器得到一個相似度矩陣,每一行即為一篇源碼的文本向量。模型結構如圖2 所示。
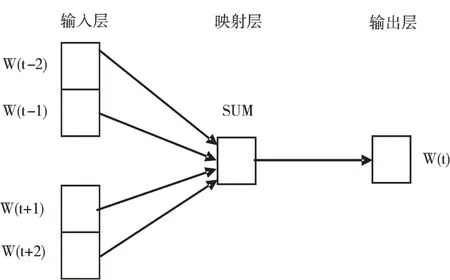
Fig.1 CBOW model圖1 CBOW 模型
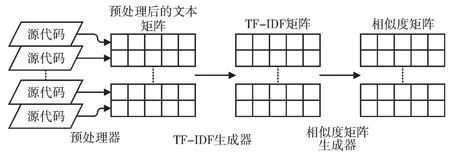
Fig.2 TF-IDF model圖2 TF-IDF 模型
2.2 基于Word2vec 的模型
Word2Vec 將每一個詞都映射成向量,同時不斷訓練向量,從而提取出詞與詞之間的語義特征[11],最后根據某些規則計算出詞向量的文本向量。本文將數據集送入gensim庫中的Word2vec 模型,獲取所有詞的詞向量。通過對每一篇源碼進行分詞、去停用詞處理后對所有詞的詞向量求和取平均,從而獲得每一篇代碼的向量,最后通過計算向量間的余弦值獲得源碼與源碼之間的相似度(即余弦相似度)。模型結構如圖3 所示。
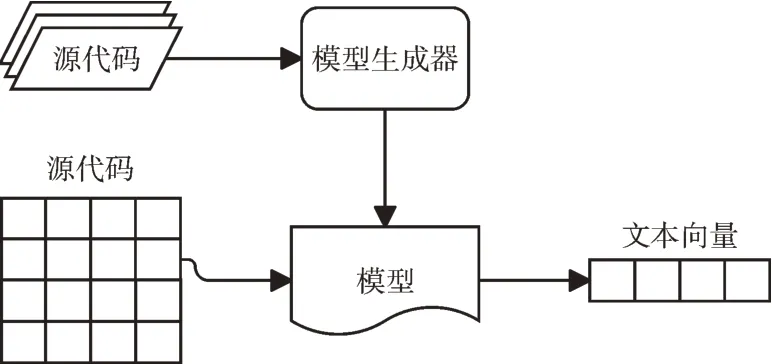
Fig.3 Word2vec model圖3 Word2vec 模型
3 實驗結果與分析
3.1 數據集
本文將江蘇師范大學教學科研輔助平臺(http://cstlab.jsnu.edu.cn)學生提交的課程作業作為數據集,包括35 個種類共905 篇C++源碼,每個種類都代表一種功能實現(包含但不止于計算最大公約數、歐幾里得算法、冒泡排序),每個種類的文件夾內包含數量不等的源代碼文件。
3.2 實驗過程
3.2.1 TF-IDF 實驗過程
圖4 為該實驗的實驗過程,第一個步驟是數據預處理,首先對所有C++源碼使用jieba 庫進行分詞處理,然后保留需要的詞,本文使用兩種方法選擇需要保留的詞。實際上,這兩種方法正好是相反的:

Fig.4 Experiment process of TF-IDF圖4 TF-IDF 實驗過程
(1)去停用詞,去除如‘return’、‘define’、‘include’、‘main’、‘int’、‘bool’、‘{’、‘}’、‘;’等這類詞,保留以外的詞。
(2)在閉區間內選擇需要保留下來的詞,僅保留以下詞,而去除其他詞:

步驟(2)生成的文本向量,將每一篇源碼TF-IDF 值相應設置為特征值,其余位置設置為0,這樣形成一種類似于one-hot 編碼的編碼方式,為每一篇源碼生成專屬向量。
(3)將已生成的文本向量利用余弦相似度計算出任何兩篇源碼的相似度。
該實驗的向量矩陣生成的部分偽代碼如下:


3.2.2 Word2vec 實驗過程
該實驗步驟分為:數據準備、模型構建和模型評估三大步驟,如圖5 所示。
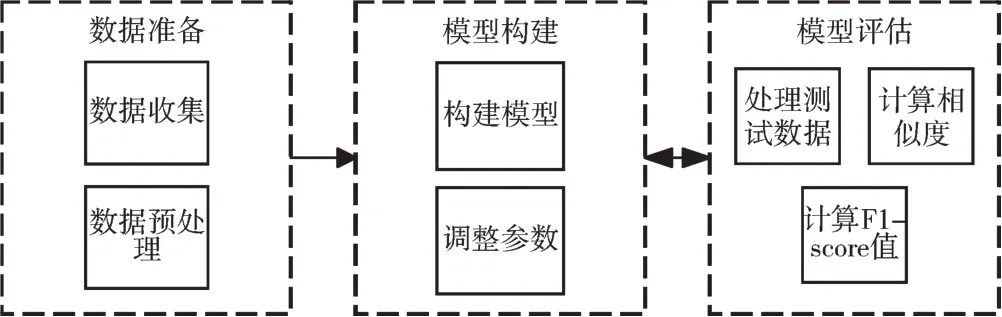
Fig.5 Experiment process of Word2vec圖5 Word2vec 實驗過程
讀取數據集中所有的數據,然后將其存入一個列表,隨后將這個列表送入第二個過程中——模型構建,首先設置好模型訓練的參數,然后開始構建模型。在第三個過程中,讀取測試數據的源碼內容進行分詞處理,并通過模型獲取分詞后詞的向量,將這些向量求和取平均處理后得到源碼的特征向量,最后計算源碼向量間的相似度并計算模型的F1-score。完成一次上述操作后,返回第二個過程,對模型構建的參數進行修改,重新構建模型,計算F1-score值。
計算兩篇源碼之間相似度的部分偽代碼,輸入值的前5 項皆為模型參數,最后兩項為需要計算相似度的兩篇源碼,輸出內容即為兩者的相似度。

3.3 模型評判
閾值是一個分界線,用于判斷兩篇源碼是否可以判定為相似:
(1)在N-gram 方法下,源碼間的相似程度與N-gram 距離反相關,所以當相似度小于或等于閾值時,兩篇源碼相似;反之則兩者不相似。
(2)在TF-IDF 和Word2vec 方法下,源碼間的相似程度與余弦相似度正相關,因此當相似度大于或等于閾值時,認為兩篇源碼相似;反之則認為兩者不相似。
確定任意兩篇源碼是否為相似的標記,選擇實現同一功能(即在同一文件夾下的)源碼標記為相似,標記為1;實現不同功能(即在不同文件夾下的)源碼標記為不相似,標記為0。
每一篇源碼與數據集中所有源碼一一進行相似度計算,得到一個由相似度構成的二維矩陣。通過計算不同閾值下的F1-score 值并獲取其中最大的F1-score 值然后根據該值來衡量一個模型相似度計算效果的優劣。F1-score 值取值范圍為0 到1,數值越大認為模型的計算效果越佳。
F1-score 計算公式如下:
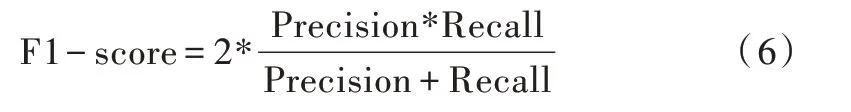
3.4 實驗結果
表1 為N-gram 模型不同N 值的情況,它顯示了模型在何閾值下能得到最大F1-score 值以及最大F1-score 值的具體數值。結果顯示當N=2 時,該模型可以得到最大的準確值、召回值以及F1-score 值,具體數值分別為56.06%、69.67%和62.12%。
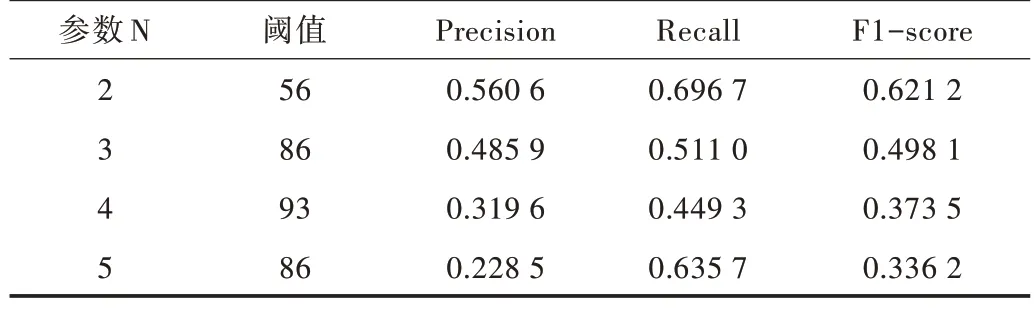
Tabel 1 Experimental result of N-gram model表1 N-gram 模型試驗結果
表2 為選擇保留詞的兩種不同方式下TF-IDF 模型的實驗結果,結果表明在閉區間內選擇保留詞能夠得到更高的F1-score 值和更高的準確度、召回值。從原理上分析可知,選擇閉區間保留了源碼的結構信息,而開區間僅保留語義、單詞,并沒有保留結構信息。

Table 2 Experimental result of TF-IDF model表2 TF-IDF 模型試驗結果
圖6 展示了Word2vec 模型不同參數下的實驗結果,其參數數值從左往右分別是workers、size、sample 參數。在實驗中,將參數min_count 和參數window 分別設置為1 和10除需要測試的參數和指定的參數之外,其他參數均為默認值,實驗得到最高的F1-score 值為0.658 8。
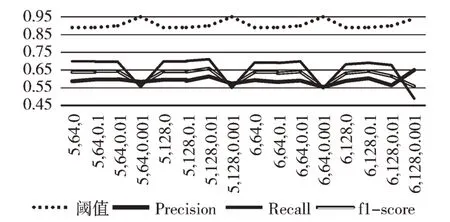
Fig.6 Results of Word2vec models with different parameters圖6 Word2vec 模型參數下的數據值
根據以上數據,可以得到N-gram、TF-IDF、Word2vec三個模型的最大F1-score 分別為0.621 2、0.775 9、0.658 8。
從方法原理上看,N-gram 方法只考慮到了詞數量上的關系,而Word2vec 和TF-IDF 在考慮詞數量的基礎上還考慮到了結構、語義。因此基于空間向量的方法能夠考慮的范圍更廣,對于C++代碼相似檢測更有效。實驗結果表明,基于空間向量的方法在檢測相似度方面效果確實比基于關鍵詞的方法好。
4 結語
本文采用基于關鍵詞的N-gram 方法、基于向量空間并通過結合TF-IDF 和Word2vec 的方法完成對C++源碼的相似度計算。反復實驗后的結果表明,基于空間向量的方法可以更加全面、準確反映代碼之間的結構關系、語義關系。但實驗還存在以下缺陷:①模型準確度不是很高;②各模型整體結構單一;③在識別粒度更小的結構上存在不足。
對于相似度計算,后續將在關鍵詞、語義、語法、結構等方面設計更全面的檢測方法。同時,使用基于CNN 的方法對C++源碼進行相似度計算,以期解決相應不足并取得更好的效果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
