農業車輛雙目視覺障礙物感知系統設計與試驗
2021-08-04 05:48:18魏建勝潘樹國田光兆孫迎春
農業工程學報 2021年9期
魏建勝,潘樹國※,田光兆,高 旺,孫迎春
(1. 東南大學儀器科學與工程學院,南京 210096;2. 南京農業大學工學院,南京 210031)
0 引言
由于農業環境的復雜多樣性,農業機械為實現其自主導航[1-5]需要可靠的障礙物感知系統。障礙物感知系統主要包括障礙物檢測[6-7]和深度估計[8-9]2部分。傳統的障礙物檢測是基于人為設計的淺層目標特征[10-12],如SIFT特征、HOG特征、局部二值特征等。由于農業環境結構復雜,光照強度不均勻等,此類特征的檢測效果不夠穩定。隨著人工智能的發展,農業機械的自主導航逐漸應用深度卷積神經網絡[13-16](Convolutional Neural Network,CNN)來完成檢測任務。相比于原有基于人為設計特征的檢測方式,深度卷積神經網絡對環境特征的檢測更加豐富和多層次,且能夠從大規模數據集中不斷學習當前任務的特征表達,從而獲得更優的檢測效果。在障礙物的深度估計中,普遍采用激光雷達[17-18]、深度相機[19-20]和雙目相機[21-22]等作為測距傳感器。激光雷達測距范圍廣、精度高,但二維激光雷達無法檢測掃描線以外的障礙物,不能適應農田等顛簸路面的情況,而三維激光雷達造價昂貴,嚴重制約了其在農業障礙物檢測中的應用[23];深度相機能夠獲得圖像中每個像素的深度信息,但測量結果受外界環境干擾較大,難以在室外環境中應用;雙目相機能夠獨立完成對目標的深度估計,但窄基線的雙目相機測距范圍有限,需不斷提高基線的寬度以適應大規模的場景。
為適應農業環境的復雜多樣性,選用雙目相機作為系統的視覺感知傳感器,并采用深度卷積神經網絡進行障礙物的檢測。由于深度卷積神經網絡對圖像處理的計算量巨大,需要圖形處理器(Graphics Processing Unit,GPU)來加速處理,僅中央處理器(Central Processing Unit,CPU)配置的工控機已不能滿足計算要求,而工作站等高計算量設備體積和質量過大,嚴重占用機械空間資源,因而本文選用NVIDIA Jetson TX2[24-27]型嵌入式人工智能(Intelligent Artificial,AI)計算機作為深度卷積神經網絡的計算載體。
在傳統的障礙物感知中,通常將障礙物檢測和深度估計作為2個獨立的任務進行處理,2個任務之間信息不能共享,造成了計算資源的浪費。基于此,本文提出一種基于改進YOLOv3的深度估計方法,將傳統障礙物感知任務中的障礙物檢測和深度估計2個任務進行融合,利用障礙物檢測中的部分信息進行深度估計,實現系統對障礙物檢測和深度估計端到端處理。
1 視覺感知系統設計
1.1 硬件組成
系統選用東方紅SG250型拖拉機作為移動載體,Jetson TX2作為運算核心,搭載本文所設計的障礙物視覺感知系統。系統硬件由拖拉機、導航控制模塊和視覺感知模塊組成。
視覺傳感器選用MYNTAI公司S1030-120型雙目相機,基線120 mm,焦距2.1 mm,分辨率752×480像素。主控制器Jetson Tx2的GPU配有256個NVIDIA CUDA核心,其CPU為雙核Denver 2 64位CPU和四核ARM A57 Complex的組合。視覺感知模塊如圖1所示。
對拖拉機進行并聯電控液壓油路改造,控制器選用STM32,與模擬量輸出模塊、電液比例控制器和比例換向閥等共同構成系統的導航控制模塊,如圖2所示。
1.2 技術流程
障礙物視覺感知系統的運行環境為Ubuntu16.04 LTS,基于ROS(Robot Operating System)完成信息的傳遞和通信,實現拖拉機對其導航控制路徑上障礙物的準確識別、定位和深度估計,并將結果傳給決策中心,系統的技術流程如圖3所示。
拖拉機點火并切換至電控轉向狀態,然后視覺感知模塊開啟進行左右相機的抓圖,接著將左右圖像分別輸入至改進的障礙物檢測模型進行檢測。檢測到障礙物類別、定位信息后進行目標匹配和視差計算,并估計出深度值,若其超過預警深度值則會觸發電控轉向。
2 基于改進YOLOv3的深度估計
為了準確估計障礙物到拖拉機的實時深度,本文提出一種基于改進YOLOv3的深度估計方法,將障礙物檢測和深度估計進行融合,一次性完成對障礙物類別、定位和深度信息的全部輸出。首先將雙目相機抓取的左右圖像分別輸入改進的YOLOv3模型中進行障礙物檢測,輸出農業環境下障礙物的類別和定位信息并進行目標匹配,得到障礙物在左右圖像中的對應關系。最后根據障礙物的對應關系計算像素視差,并輸入至雙目成像模型進行深度估計,算法流程如圖4所示。
2.1 改進YOLOv3模型
本文選用YOLOv3模型[28-30]作為深度估計的前端框架,并針對雙目成像模型和農業環境目標的特殊性進行錨框聚類和邊界框損失函數的改進。
2.1.1 YOLOv3
YOLOv3是目前為止最先進的目標檢測算法之一,其在YOLOv2的基礎之上進一步融合多尺度檢測和多尺度訓練等改進措施,使用更深的darkNet53作為特征提取網絡,并加入殘差模塊解決深層網絡梯度問題。圖5是YOLOv3的網絡結構,它從3個不同的尺度(32×32、16×16和8×8)提取特征至YOLO層進行檢測。
2.1.2 數據集聚類
由于沒有公開的農業障礙物數據集,本文在農業環境中設置人、農具和樹樁等作為障礙物,從2020年開始通過網絡爬蟲和相機抓圖自建數據集開展研究工作,并利用LabelImg進行類別和檢測框標注,包括訓練集2 400張和測試集270張。由于農業環境中的障礙物形態多變,原COCO數據集中的先驗框尺寸難以滿足該數據集。為獲得合適的先驗框,本文采用K-means算法對農業障礙物數據集進行聚類分析,并針對特征金字塔在52×52、26×26和13×13特征圖上分別應用先驗框(16,28)、(25,42)、(39,43),(69,75)、(99,80)、(88,113),(92,123)、(155,149)、(199,236)。
2.1.3 lossD損失函數
原始YOLOv3模型的損失函數中,針對檢測框x、y、w和h坐標的誤差權值是相同的,但在雙目成像模型中深度估計的精度取決于視差,即左右圖像目標檢測框質心的u軸坐標差,使得YOLOv3模型對檢測框的橫向偏差特別敏感。因此,在深度估計的邊界框損失函數lossD中獨立出x坐標的誤差權值項并提高,同時降低其他3項的權值。
針對大小目標對目標檢測框精度的影響不一致,YOLOv3原文采用反向賦權的方式來控制精度,即目標越大x、y、w和h坐標的誤差權值越小。針對機械在農業環境下自主導航的需求,要求遠處目標深度估計誤差偏大而近處誤差偏小,在損失函數lossD中對x誤差項正向賦值,其余項固定賦值。改進后的損失函數如式(1)所示。
式中K為輸入層網格數;M為單個網格預測的錨框數;為目標的判斷標志;w、h、(x,y)和分別為目標檢測框寬、高、質心坐標的真值和預測值,像素;n目標類別數;r為當前類別索引;truthclass、truthconf和predictclassr、predictconf分別為類別和置信度的真值和預測值;(·)?1:0表示括號內判斷條件為真則為1,反之為0。
2.2 深度估計過程
2.2.1 目標匹配
相機抓取的圖像中有些物體是拖拉機的作業目標,如:果實、莊稼和果蔬等;另一些物體是障礙物,如:行人、農具、樹樁等。目標匹配是改進模型檢測出選定的障礙物后,進一步在左右圖像中確定同一障礙物的對應關系,具體過程如下:1)將左右相機圖像PL、PR輸入改進YOLOv3模型,輸出各自的目標檢測框BBOXL、BBOXR及其類別CLASSL、CLASSR;2)計算目標檢測框的像素面積SL、SR和目標檢測框質心的像素坐標CL、CR;3)得到目標檢測框的像素面積之差SE和目標檢測框質心的v軸坐標之差VE;4)判斷CLASSL、CLASSR是否相同,且SE、VE是否小于閾值A、B;若同時滿足,則匹配成功,反之匹配失敗。
2.2.2 像素視差計算
若左右圖像中2個目標檢測框匹配成功,即表示其為某一障礙物在左右相機的成像位置,反之則繼續抓圖進行目標匹配。如圖6所示,目標檢測框BBOXL、BBOXR為某一障礙物在左右相機的像素平面成像位置,選用目標檢測框的質心代表障礙物,左右質心的坐標分別為(uL,vL)、(uR,vR),則障礙物在左右相機的像素視差D為
式中uL、uR分別為像素平面上左右質心的u軸坐標。
2.2.3 深度估計
立體視覺中,記OL、OR為左右相機光圈中心;XL、XR為成像平面的坐標;f為焦距,m;z為深度,m;b為左右相機的基線,m;空間點P在左右相機中各成一像,記PL、PR,左右圖像橫坐標之差(XL-XR)為視差d,m;根據三角相似關系有:
目標邊界框質心在左右視圖中的像素坐標uL、uR分別為
式中α為物理成像平面坐標系的橫向縮放系數,像素/m;cx為原點橫向平移量,像素。
進一步得視差d為
將式(5)代入式(3)得深度z為
3 視覺感知系統試驗
3.1 模型訓練與測試試驗
針對訓練集,本文選用DELL T7920型圖形工作站(12G內存TITAN V型顯卡)對YOLOv3模型和改進YOLOv3模型分別進行相同的迭代訓練,2種模型的訓練損失函數如圖7所示。
表1是YOLOv3模型和改進YOLOv3模型結果。由表1可知,相較于YOLOv3模型,改進YOLOv3模型的準確率和召回率分別下降0.5%和0.4%。原因是本文對模型的改進側重于目標檢測框x軸上的精度,而適當降低對y軸和寬高的精度,提高了目標的深度估計精度。同時,模型改進前后在深度學習工作站和嵌入式終端TX2上的速度測試結果基本一致。
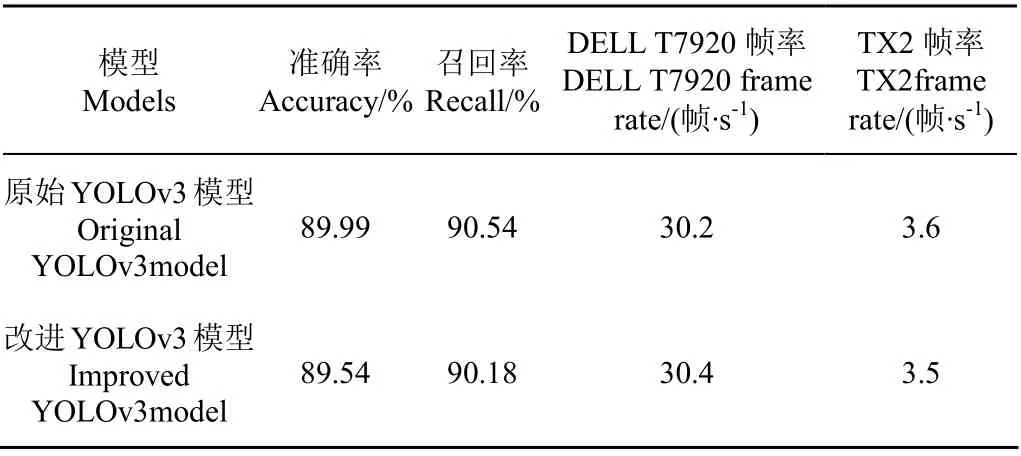
表1 訓練集測試結果 Table 1 Test results on training set
3.2 深度估計試驗
3.2.1 參數標定與評價指標
試驗在南京農業大學農田試驗場進行,分別將Hog+SVM模型、YOLOv3模型和改進YOLOv3模型部署至嵌入式終端并對點火駐車狀態下拖拉機前方1.6~3.4 m距離段上的靜止障礙物進行深度估計。試驗過程中,保持雙目相機與障礙物的圖像質心在同一水平面上,且雙目相機左右光心的中點與圖像質心的連線垂直于相機基線方向。對障礙物進行多組深度估計試驗,獲得障礙物的深度估計值,并將UT393A型測距儀的測量值(精度±1.5 mm)作為距離真值進行誤差分析。試驗中采用誤差均值em和誤差比均值erm作為深度估計精度的指標,其定義分別如下:
式(7)~(8)中zi為深度估計值,n為測量次數,本文試驗取n=3。
利用MYNTAI相機自帶的軟件開發工具包(Software Development Kit,SDK)對系統視覺感知模塊中的雙目相機參數進行標定,并獲得去畸變的雙目圖像,結果如表2所示。
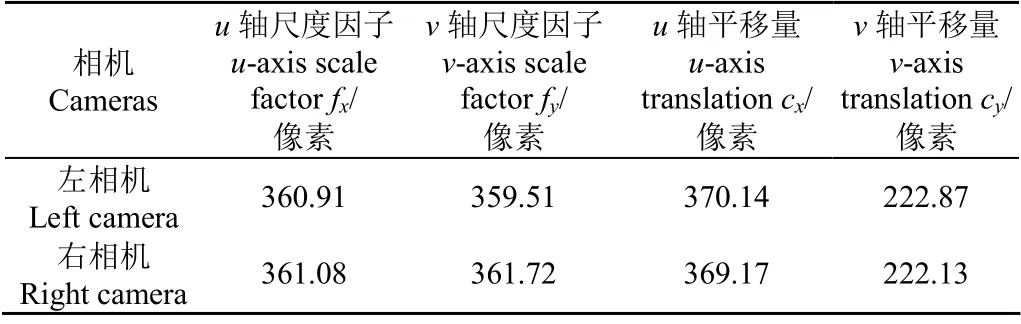
表2 雙目相機標定結果 Table 2 Calibration result of binocular camera
3.2.2 深度估計
圖8是不同障礙物(人、農具和樹樁)在不同1.6~3.4 m距離段上的檢測結果,其中像素面積差SE的閾值A和v軸坐標差VE的閾值B分別設為經驗值60和4。圖8a障礙物目標為人,目標深度真值為2.8 m,檢測框質心視差為15.47像素;圖8b障礙物目標為農具,目標深度真值為2.6 m,檢測框質心視差為16.66像素;圖8c障礙物目標類別為樹樁,目標深度真值為2.9 m,檢測框質心視差為14.94像素。由圖8可知,YOLOv3模型和改進YOLOv3模型的檢測精度高且魯棒性強,而Hog+SVM模型的檢測精度和魯棒性均較差。
圖9為不同障礙物(人、農具和樹樁)在其深度估計范圍內1.6~3.4 m距離段內的深度誤差結果。由圖9可知,3種障礙物應用改進YOLOv3模型的深度估計誤差均值em和誤差比均值erm相對于YOLOv3模型和Hog+SVM模型均有降低。改進YOLOv3模型對行人的誤差均值em和誤差比均值erm相較于YOLOv3模型分別降低38.92%、37.23%,比Hog+SVM模型分別降低53.44%、53.14%;改進YOLOv3模型對農具的誤差均值em和誤差比均值erm相較于YOLOv3模型分別降低26.47%、26.12%,比Hog+SVM模型分別降低41.9%、41.73%;改進YOLOv3模型對樹樁的誤差均值em和誤差比均值erm相較于YOLOv3模型分別降低25.69%、25.65%,比Hog+SVM模型分別降低43.14%、43.01%;隨著障礙物目標與相機之間距離增大,3種模型的深度估計誤差均值em和誤差比均值erm均無明顯變化規律。
3.3 動態避障試驗
試驗于2020年5月在南京農業大學農機試驗場進行,對動態場景下視覺感知系統的深度估計精度和避障效果進行測試。由于行駛中的拖拉機與障礙物行人之間的深度真值無法用測距儀實時測得,試驗中在拖拉機車尾部署一個GPS接收機,同時行人手持一個GPS接收機,并用2個GPS定位坐標之間的距離除去拖拉機GPS接收機至車頭的距離(289 cm)作為實時的深度真值,自主導航試驗裝置如圖10所示。
由于計算機處理有效數字長度有限,將坐標原點從117°E 與赤道的交點向東平移159 000 m,向北平移3 557 000 m,并以平移后的點為參考原點。試驗中拖拉機按導航基線AB由A向B直線行駛,起點A坐標(227.198 6,176.401 6),平均速度0.31 m/s,障礙物行人沿導航基線由B向A行走,起點B坐標(227.173 9,182.225 8),平均速度0.18 m/s。為保證行人安全,將深度預警值設為2.4 m,相機抓圖的頻率設置為1 Hz,電控液壓轉向模塊轉角為18°。本次試驗從拖拉機點火啟動開始,至拖拉機轉向避障后障礙物離開相機視角結束,共耗時9 s。拖拉機啟動時深度值為5.22 m,之后每秒輸出1次深度估計值,在行駛6 s后深度估計結果為2.14 m,小于試驗設置的預警值并觸發電控液壓轉向模塊以固定右轉角18°進行安全避障,執行避障動作3 s后障礙物離開相機視角同時系統停止深度估計,試驗結果如圖11所示。
表3為動態試驗中深度估計精度的誤差統計,深度真值用GPS坐標間的歐氏距離除去車載GPS到相機的距離289 cm進行表示,深度估計值為本文基于改進YOLOv3的深度估計結果。
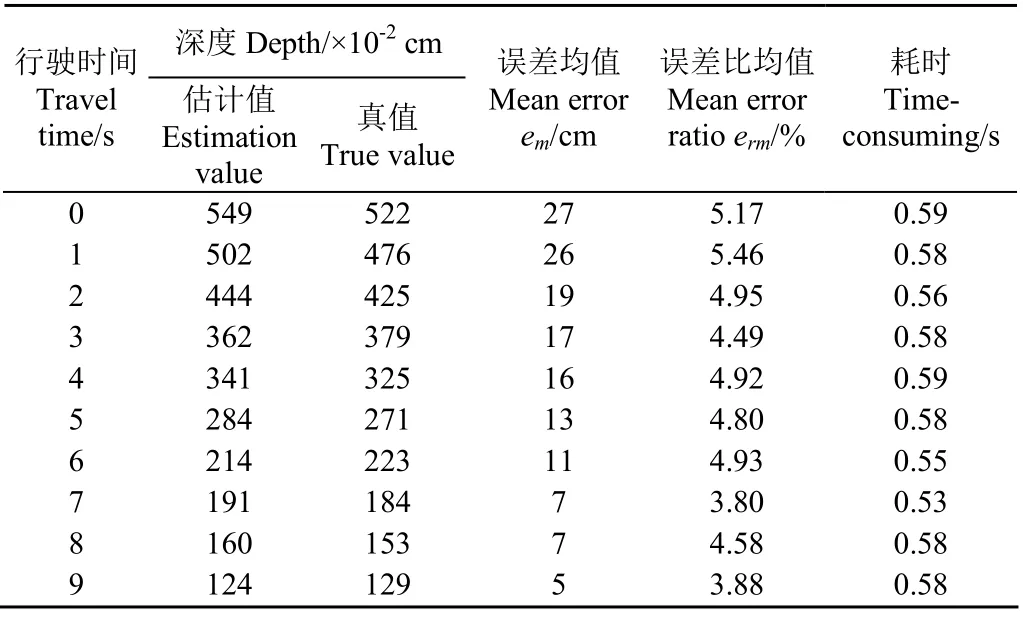
表3 動態場景深度估計 Table 3 Depth estimation in dynamic scene
由表3可知,隨著自主導航時間的增加,拖拉機與障礙物之間的深度真值和深度估計值不斷減小且變化趨勢一致;同時,誤差均值em從初始的27 cm不斷減少至5 cm,但平均誤差比均值erm為4.66%,無明顯變化規律,維持在6%以下,比靜態深度估計的誤差比均值降低7.19%,算法平均耗時為0.573 s。
4 結 論
1)本文設計了一套基于農業機械的障礙物視覺感知系統,系統將嵌入式AI計算機作為控制核心,極大節省了機械的空間資源,能夠對障礙物的類別和深度信息進行準確檢測。
2)本文提出一種基于改進YOLOv3模型的深度估計方法,通過增大模型對圖像x軸的敏感程度來提高深度估計精度,相對于YOLOv3模型和傳統檢測方法Hog+SVM其深度估計的誤差均值、誤差比均值均有較大改善。動態避障試驗結果表明,隨著行駛過程的進行,誤差均值從初始的27 cm不斷減少至5 cm,誤差比均值無明顯變化規律,但始終維持在6%以下,比靜態深度估計的誤差比均值降低7.19%,成功避障。
由于YOLOv3模型的網絡結構深參數量大,在嵌入式終端的實時推理速度有限。后續研究中將選用更加輕量級的YOLOv3-tiny模型和運算力更高的終端xavier,進行動態障礙物的深度估計試驗,不斷提高平臺的實時推理幀率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
