基于先驗信息的圖像逆問題研究
2021-08-06 08:23:06張登銀
計算機工程與應用 2021年15期
陳 燦,周 超,張登銀
1.南京郵電大學 物聯網學院,南京 210003
2.南京郵電大學 通信與信息工程學院,南京 210003
從數學上講,成像系統可以刻畫為一個函數F(?):X→Y,該函數將圖像空間域X映射到觀測空間域Y。因此,經由給定成像系統觀測而來的退化圖像或測量值y∈Y可以通過下式進行表示:

其中,ε為噪聲,∈X為原始圖像。圖像逆問題聚焦于從經由給定系統觀測而來的退化圖像或測量值y中重構原始圖像,即y→,是圖像信號處理領域的研究熱點之一,被成功應用于諸如圖像去噪、圖像超分辨率和圖像壓縮感知等低級視覺應用。
原始圖像與重構圖像x*之間的誤差一般可以通過某種衡量標準H(,x*)來度量。然而,由于無法獲得原始圖像,故H(,x*)實際無法求得,因此退而求其次,將H(,x*)弱化為H(x*),通過測量域的誤差間接度量:

值得注意的是,公式(2)采用了最小二乘構建度量標準,這只是諸多度量標準之一。通過最小化重構誤差即可獲得重構圖像:

然而,該最小化問題為欠定問題,即一個問題對應著多個解,并且對輸入數據尤為敏感。傳統求解方法通過引入先驗信息,將上述無約束最優化問題轉化為帶約束的優化問題,再通過迭代求解重構信號,該類方法也被稱為基于分析模型的方法。近年來,人工智能的發展推動了該領域從基于分析模型的方法到基于深度學習的方法的演變,深度學習已被成功應用于圖像逆問題。然而,無論是基于分析模型的傳統方法還是基于深度學習的非傳統方法,充分利用先驗信息是成功求解圖像逆問題的關鍵。
信號或其特征的某些固有性質被稱為先驗信息。研究者圍繞先驗信息進行了廣泛的探索,提出多種手動設計的先驗信息,例如,稀疏先驗[1-4]和去噪先驗[5-6]等。然而,這些手動設計的先驗信息在表征具體應用場景時過于籠統。為了更好地表征具體應用場景的先驗信息,研究者提出利用深度學習的方法,從具體任務的訓練數據中自適應地學習先驗信息。
在過去的幾十年中,研究者對圖像逆問題進行了廣泛的探索,取得了一定的成果,但仍面臨著諸多挑戰[7-9]。本文創新性地從如何利用先驗信息求解圖像逆問題的角度出發,將領域的研究過去、現狀總結歸納為以下三類(如圖1 所示):基于分析模型的方法、基于深度學習的方法和混合分析模型和深度學習的方法。然后,對三類方法進行簡潔的分析對比,展望未來的研究方向。
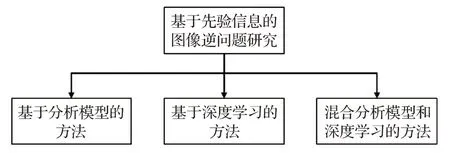
圖1 圖像逆問題研究現狀總覽Fig.1 Overview of state-of-the-art methods in image inverse problems
1 基于分析模型的方法
基于分析模型的方法通過分析物理過程設計該領域明確的先驗信息S(x),以正則化的方式引入S(x),將式(3)轉化為一個帶約束的優化問題:

通過迭代求解該優化問題,從退化圖像或測量值中重構原始圖像。從貝葉斯的角度理解,式(4)等價于求解一個最大后驗估計問題:
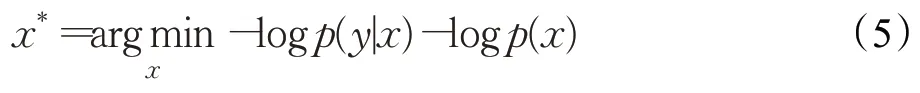
其中,p(y|x)為y在給定x情況下的條件概率,通常也被稱為似然概率,p(x)為x的先驗概率。在實際應用中,通常在式(4)的基礎上引入正則化參數λ>0 來平衡H(x)和S(x)對解的影響:
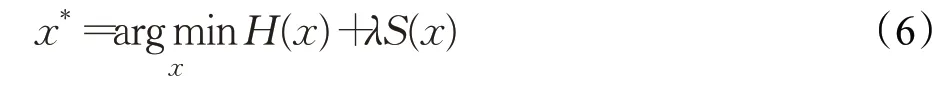
值得注意的是,H(x) 獨立于S(x),且僅與成像系統F(x)有關,而S(x)僅與具體應用場景的明確先驗信息有關。求解式(6)主要有兩類算法,直接求解法和變量分離求解法。
如圖2 所示(I(?)代表一次迭代求解),直接求解法通過迭代求解式(6)直接進行重構。基于梯度下降的思想,文獻[10]提出迭代閾值收縮算法(Iterative Shrinkage Thresholding Algorithm,ISTA),該算法在每次迭代中采用閾值進行Landweber 迭代。文獻[11]在ISTA 算法的基礎上,結合Nesterov 加速策略,提出了快速迭代閾值收縮算法(Fast Iterative Shrinkage Thresholding Algorithm,FISTA),進一步提升了算法的收斂速度。相類似的,文獻[12]基于概率圖思想,通過狀態演化預測下次迭代,并通過軟閾值迭代進行相關去噪,提出近似消息傳遞算法(Message Passing Algorithm,AMP)。在AMP算法的基礎上,文獻[13]提出D-AMP算法,該算法在迭代過程中通過利用適當的Onsager 校正項,迫使每次迭代中的信號擾動接近白高斯噪聲,再利用去噪器進行去噪。
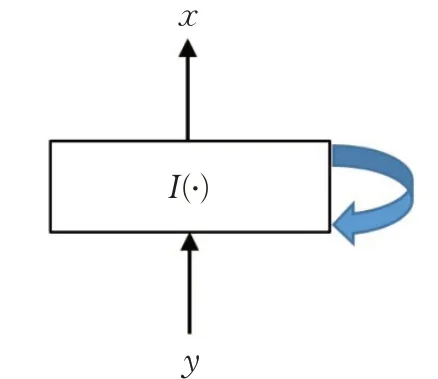
圖2 直接求解法Fig.2 Direct methods
為了進一步加速算法的收斂,研究者提出利用分離變量算法將單變量的優化問題轉化為多變量的優化問題,再利用直接求解法迭代求解子優化問題獲得重構圖像,該類方法被稱為變量分離求解法。以文獻[14]為例,首先將式(6)進行改寫,將單變量的優化問題轉化為兩個變量的優化問題:
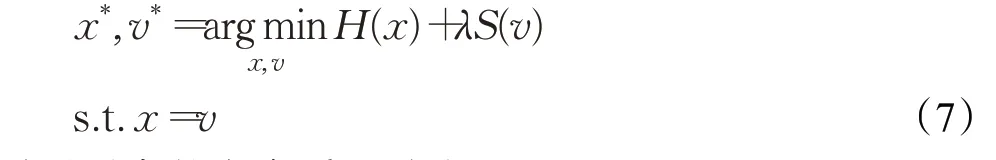
再利用交替方向乘子法(Alternating Direction Method of Multipliers,ADMM)[15]將上述優化問題轉化為兩個子優化問題:
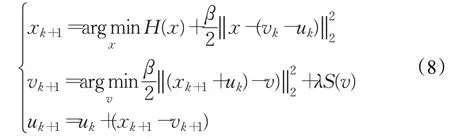
其中,β為懲罰參數,u為對偶變量。相類似的,文獻[16]和文獻[17]分別提出NLR-CS 算法和TVAL3 算法用于解決圖像壓縮感知問題。除了采用ADMM算法劃分子優化問題之外,文獻[18]和文獻[19]分別提出利用半二次方分裂算法(Half Quadratic Splitting,HQS)和分離布雷格曼迭代算法(Split Bregman Iteration,SBI)[20]將原優化問題轉化為兩個子優化問題,最后利用直接求解法迭代求解兩個子優化問題獲得重構圖像。
基于分析模型的方法具有可解釋的先驗信息,但是由于需多次迭代求解才能獲得較為理想的重構結果,重構效率較低。除此之外,這些手動設計的先驗信息并沒有利用潛在的訓練數據,在表征具體應用場景時過于籠統,效果有限。
2 基于深度學習的方法
得益于優化算法,硬件和大數據的發展,過去十年見證了深度學習的革命。隨著深度學習在計算機視覺任務上的成功應用,研究者開始致力于利用深度學習解決圖像逆問題。與基于分析模型的方法不同,基于深度學習的方法無需利用明確的先驗信息建立模型,而是將重構問題建模成一個帶參數的網絡,通過最小化損失函數L(?),優化目標參數,從訓練數據中自適應挖掘先驗信息。根據優化目標參數的不同,可以將基于深度學習的方法分為基于判別模型的方法和基于生成模型的方法兩類。
如圖3所示,基于判別模型的方法旨在直接構造一個判別網絡,將輸入退化圖像或測量值y直接映射到輸出原始圖像x,是對條件概率p(x|y)直接進行建模,以網絡的參數θ作為優化對象:

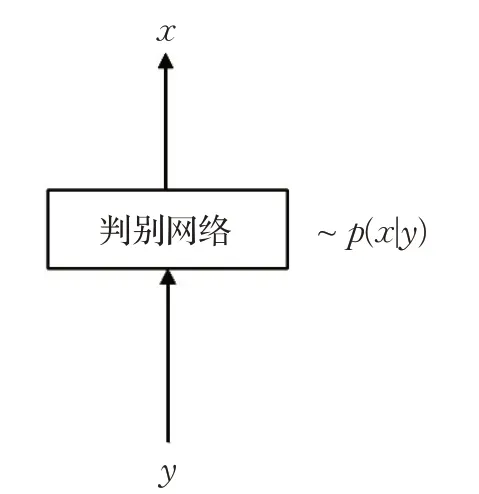
圖3 基于判別模型的方法Fig.3 Discriminative model-based methods
如何構建具體的網絡框架,優化參數θ,是該類方法的研究重點。文獻[21]首次提出利用多層感知器(Multilayer Perceptron,MLP)進行圖像去噪,獲得了與傳統方法相當的性能。相類似的,文獻[22]首次提出利用堆疊去噪自編碼器(Stacked Denoising Autoencoder,SDA)作為無監督的特征學習器,讓網絡自適應地從訓練數據中學習信號的結構信息,進行圖像壓縮感知重構。在文獻[21]的基礎上,文獻[23]提出在去噪網絡之前進行線性均值平移處理,能夠有效增強去噪網絡的魯棒性。MLP 理論上具有逼近任意函數的能力,但是往往需要建立足夠大的網絡,高維的參數給優化和存儲帶來了巨大的挑戰。卷積神經網絡(Convolutional Neural Network,CNN)利用卷積層替換全連接層,能夠有效減少參數規模,捕獲圖像的局部相似性,被廣泛應用于視頻圖像處理。針對圖像壓縮感知問題,文獻[24]提出一種名為ReconNet的網絡,先利用該網絡進行初始重構,再利用去噪器進行后處理得到最終的重構結果。在此基礎上,文獻[25]結合殘差模塊,提出一種名為DR2-Net的深度殘差卷積神經網絡,進一步提升了重構質量。自編碼器(Autoencoders,AE)作為另一種網絡框架,由編碼器和解碼器兩部分組成,能夠通過自監督訓練,學習信號的特征表示。文獻[26]首次提出利用AE獲得的信號特征表示進行圖像去噪。在此基礎上,文獻[27]通過堆疊多個AE,并對參數進行稀疏約束,進一步提高了圖像去噪的效果。相類似的,文獻[28]利用AE 進行壓縮感知的醫學圖像重構,有效提高了重構效率。相比于MLP、CNN 和AE,循環神經網絡(Recurrent Neural Network,RNN)更適合于處理順序信號。針對多測量向量問題,文獻[29]提出利用RNN捕獲稀疏向量之間的未知依賴關系。相類似的,文獻[30]將CNN 和RNN 進行結合,構建了一個端到端的網絡,充分挖掘視頻圖像序列的時空相關性。
基于判別模型的方法盡管重構圖像具有較高的峰值信噪比,但缺乏自然真實感。研究者結合判別模型和生成模型提出了生成對抗網絡(Generative Adversarial Network,GAN)[31],該網絡利用對抗博弈思想進行訓練。訓練結束后,生成模型就能夠將其輸入空間中的任何點轉換為一張真實可信的圖像。因此,基于生成模型的方法成為研究的熱點。如圖4所示,基于生成模型的方法旨在構造一個生成網絡,將隱變量的分布映射到目標數據的分布。值得注意的是,區別于基于判別模型的方法,基于生成模型的方法將研究重點從優化網絡參數θ轉移至優化隱變量z,往往采用預訓練好的現有網絡模型,以隱變量為優化目標參數:
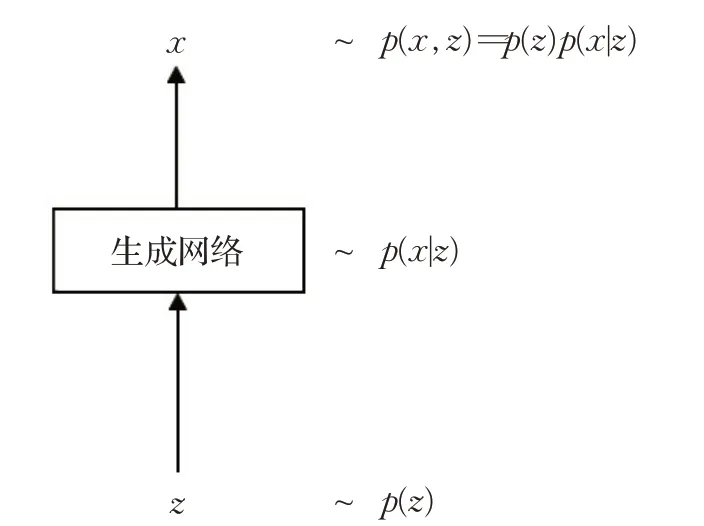
圖4 基于生成模型的方法Fig.4 Generative model-based methods

文獻[32]首次提出利用生成模型解決圖像壓縮感知問題,并驗證該模型相比于分析模型更能準確地表征數據的分布,并且其可微性能夠允許快速重構。在此基礎上,文獻[33]將測量過程整合進生成對抗網絡中,提出一種名為AmbientGAN的生成對抗網絡。文獻[34]提出深度網絡在未經過任何學習之前就能捕獲先驗信息,也就是說,先驗信息可能并不是從大量的訓練數據中學習而來,而是存在于網絡的架構中,該種先驗信息被稱為深度圖像先驗。因此,文獻[35]首次提出同時優化網絡參數與隱變量進行圖像重構:

相類似的,文獻[36]提出同時優化網絡參數與隱變量進行視頻重構,并提出一種正則化策略,有效提高了重構質量。
通常情況下,深度網絡具有多層結構,包含大量參數,因此能夠學習難以明確建模的復雜映射。當具有足夠的訓練數據和足夠大的模型規模時,這種深度網絡能夠建模難以表征的應用場景。值得注意的是,深度網絡將重構復雜度轉移到了訓練階段,因此重構效率較高,能夠滿足實時應用需求。隨著現代平臺針對諸如卷積之類的特殊運算進行了高度優化,該類方法的流行程度達到了一個新的高度。然而,該類方法的可解釋性較差。
3 混合分析模型和深度學習的方法
盡管基于深度學習的方法能夠從訓練數據中自適應挖掘先驗信息,但是這種自適應的先驗信息可解釋性較差,而可解釋性不論在理論還是實踐中都十分重要,是推進概念理解和網絡框架發展的關鍵。因此,相比于基于分析模型的方法,缺乏可解釋性限制了基于深度學習的方法的發展。如何將領域先驗信息轉移至深度網絡至今仍是一個非常具有挑戰性的開放問題。為了提高網絡的可解釋性,充分挖掘先驗信息,研究者提出混合分析模型和深度學習的方法。該類方法分為直接展開法和黑盒法兩類。
如圖5所示,直接展開法將分析模型方法中的每次迭代求解過程展開為網絡的一層,再堆疊這些層構建一個深度網絡,最后利用訓練數據自適應地學習其參數。展開后的深度網絡等效于執行有限次數的迭代求解。文獻[37]首次提出將ADMM 算法的迭代求解過程(即式(8))進行展開,在此基礎上,文獻[38]提出一種名為ADMM-CSNet的網絡用于核磁共振壓縮感知重構。相類似的,文獻[39]將ISTA 算法的迭代求解過程進行展開,提出一種名為LISTA的網絡。區別于基于分析模型的方法,該類方法將預先設定的參數(例如,正則化參數)轉化為深度網絡的參數,從實際的訓練數據中直接學習獲得。并且,相比于傳統的深度網絡,該種深度網絡的參數更少,更易學習。
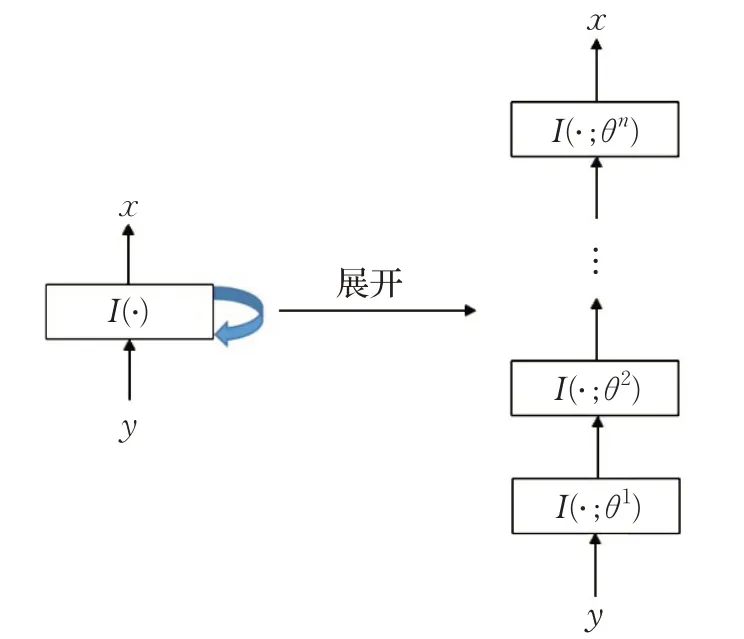
圖5 展開法Fig.5 Unrolling methods
除此之外,研究者提出利用深度網絡作為“黑盒”嵌入基于分析模型的方法中執行某些功能。文獻[40]提出利用深度網絡替代FISTA 算法中的近似投影。文獻[41]將預訓練的生成網絡作為先驗信息切入分析模型的迭代優化求解。相類似的,文獻[42]提出利用生成網絡替代正則化的近似投影。文獻[43]將D-AMP 算法進行展開,并用卷積神經網絡替代D-AMP 算法中的去噪器,提出一種名為L-DAMP的網絡。
混合分析模型和深度學習的方法可以自然地解釋為基于分析模型的方法,從而解決了深度網絡缺乏可解釋性的問題。
4 方法的對比分析
基于分析模型的方法通常由預設的先驗信息構成,可解釋性較強。預設的先驗信息使得基于分析模型的方法能夠在預設的場景中具有較好的表征能力,但在其余場景中的表征性能有限。并且,由于需多次迭代求解才能獲得較為理想的重構結果,重構效率較低。
基于深度學習的方法通常由大量的可訓練參數組成,跨越了函數搜索空間中很大的子集,理論上具有最強的表征能力。并且,該類方法將重構復雜度轉移到了訓練階段,重構效率較高,能夠滿足實時應用需求。盡管該類方法通常被認為能夠從數據中或者網絡框架中挖掘先驗信息,但是依舊缺乏可解釋的先驗信息。
混合分析模型和深度學習的方法屬于上述兩類方法的折中,同時具備較好的可解釋性和重構效率。該類方法通常由相對少量的可訓練參數組成,跨越了函數搜索空間中相對較小的子集,具有一般的表征能力。
綜上所述,表1 歸納總結了三類方法在表征能力、重構效率和可解釋性三個方面的對比。表2 展示了TVAL3 算法[17]、NLR-CS 算法[16]、SDA 網絡[22]、ReconNet網絡[24]、L-DAMP網絡[43]和ADMM-CSNet網絡[38]在圖像壓縮感知的應用場景中的實驗性能對比。該結果從近期發表的文獻中選取,更多信息詳見文獻[38]。不難看出,在重構效率方面,相比于基于分析模型的方法,基于深度學習的方法和混合分析模型和深度學習的方法具有更高的重構效率,其原因在于該兩類算法將重構時間復雜度轉移至了訓練階段,在測試階段直接利用前向模型即可獲得重構信號。然而,盡管理論上基于深度學習的方法具有最高的表征能力,相比于其余兩類方法,該類方法的性能優勢并未充分展現,其原因主要有:(1)缺乏可解釋的先驗信息和網絡框架設計;(2)現有設備難以支持大規模網絡的訓練與部署;(3)現有網絡泛化性較低;(4)網絡魯棒性較低難以訓練。

表1 方法的特征比較Table 1 Feature comparison
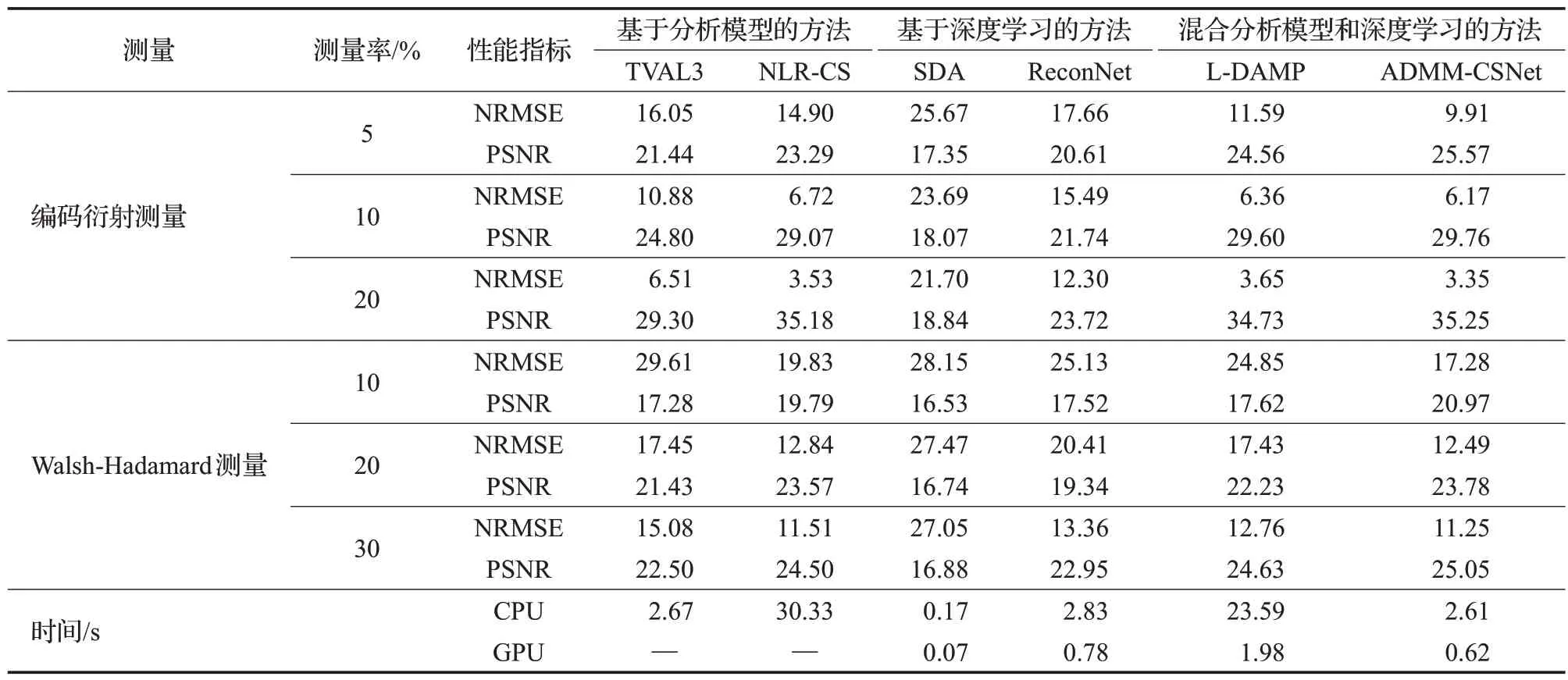
表2 圖像壓縮感知方法對比Table 2 Comparison of image compressive sensing
5 未來的研究方向
基于深度學習的方法因具有最高的表征能力受到了研究者的廣泛關注。針對上述問題,在近幾年的頂級會議上,例如,CVPR、ICCV和ECCV等,每年都有10篇以上的研究發表,指引了未來的研究方向。
5.1 融合先驗信息的深度網絡設計
充分利用先驗信息是成功求解圖像逆問題的關鍵。基于深度學習的方法通常被認為能夠從訓練數據中自適應地挖掘先驗信息,然而文獻[34]提出先驗信息可能并不是從大量的訓練數據中學習而來,而是存在于網絡的架構中。盡管混合分析模型和深度學習的方法提供了一種融合先驗信息的網絡設計方式,該類方法易受分析模型的誤導,收斂至局部最優。因此,如何進一步融合先驗信息設計具體的深度網絡是未來的研究方向之一。并且,針對特定深度網絡的性能界限理論分析有待進一步探索。
5.2 輕巧高效的深度網絡設計
基于深度學習的方法通常由大量的可訓練參數組成,理論上具有最強的表征能力。然而,大量的參數不僅增加了訓練的難度,更對存儲空間提出了更高的要求,限制了其在資源受限的場景中的應用。因此,如何設計輕便高效的深度網絡,促進深度網絡的具體應用部署,是未來的研究方向之一[44-46]。
5.3 泛化性的深度網絡設計
在實際應用中,基于深度學習的方法即使面對同一應用場景,參數的改變(例如,圖像超分辨率應用中的退化系數),都需要單獨設計對應的深度網絡,并重新進行訓練,需要花費很高的學習成本。因此,對于泛化性深度網絡設計的研究必不可少[47-48]。
5.4 魯棒性的深度網絡設計
盡管基于深度學習的視頻壓縮感知重構方法能挖掘訓練數據中潛在的信息,該類方法易受模型假設、訓練崩塌和訓練數據偏差的影響,重構魯棒性較差,進而導致重構圖像包含錯誤的特征,嚴重影響圖像的重構質量。針對這個問題,研究者提出了一些解決方法[34-35,49-50],然而這些方法在測試時仍需迭代優化網絡的參數或者隱變量,重構效率相對較低。因此,如何在提高視頻重構魯棒性的同時,保證視頻的重構效率,是一個重要的研究問題[51-52]。
6 結束語
隨著國家將人工智能提升為國家戰略并發布《新一代人工智能發展規劃》,人工智能的研究迎來了新的熱潮。深度學習的發展推動了圖像逆問題領域從基于分析模型的方法到基于深度學習的方法的轉變。在近幾年的頂級會議,例如,CVPR、ICCV 和ECCV 等,每年都有10篇以上的研究發表。現有相關綜述研究側重于介紹具體的深度網絡,而忽略了如何利用先驗信息。因此,本文創新性地從如何利用先驗信息求解圖像逆問題的角度出發,歸納總結了該領域的研究現狀,并對不同方法進行對比分析,最后展望了未來的研究方向。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
