基于土壤數據廣度與深度模型的作物推薦算法
2021-08-09 09:11:18魏博識
武漢工程大學學報 2021年4期
魏博識,盧 濤*
1.智能機器人湖北省重點實驗室(武漢工程大學),湖北 武漢430205;2.武漢工程大學計算機科學與工程學院,湖北武漢430205
農業大數據是運用大數據理念、技術和方法解決農業或涉農領域數據的采集、存儲、計算與應用等一系列問題的技術,是大數據理論和技術在農業上的應用和實踐[1]。近年來,深度學習方法在農業領域的應用取得巨大成功,廣泛應用于科學施肥、產量預測和經濟效益預估[2]等領域。根據土壤信息進行數據挖掘,并在此基礎上提出區域性作物的種植建議,不僅可以促進農作物生長從而帶來經濟效益,還可以改善土壤肥力,促進可持續發展[3]。根據土壤種類、土地的類型,以及土壤養分元素[如:氮(N)、磷(P)、鉀(K)、有機質(OM)等]的含量建立模型,分析并且給出精準預測,可以形成科學的種植方案。研究表明,氮、磷、鉀在植物根莖的重吸收率分別為63.6%、56.8%、50.7%,是促進作物生長的主要營養元素[4]。現有的作物推薦算法均是基于土壤養分元素等數值域數據來構建模型的[5],這極大地忽略了土壤類型(如:黃綿土、潮土、水稻土等)、地塊類型(如:坡地、平地、梯田等)等文本域數據的作用。這些文本域數據是土壤的基本物理性質,可以反應土壤中不同大小直徑成土顆粒的組成狀況[6]。另外,不同質地土壤的蓄水導水、保溫導熱、耕性、微生物種類及其活動等性能的差異也能影響作物生長[7]。現有數值型作物推薦算法在農業生產決策領域已取得良好成效。例如,隨機森林支持向量機 作 物 推 薦 算 法[8](random forest support vector machine,RFSVM)采用隨機森林方法篩選特征最優子集,然后使用支持向量機進行作物推薦。然而中華土壤數據庫中土壤數據包含了數值域和文本域數據。多域特性的土壤數據導致現有作物推薦方法無法充分挖掘土壤數據之間的內在關聯造成模型精度較低。一般來說,根據所學習數據類型的不同推薦算法[9]可分為學習數值域特征的數值型推薦算法和學習文本域特征的文本型推薦算法。常見數值型推薦算法:深度神經網絡(deep neural networks,DNN)[10]、支 持 向 量 機(support vector machine,SVM)[11]等應用于土壤作物推薦中雖然可以高效的學習土壤數值域高階特征組合,然而由于沒有考慮土壤文本域數據,這些算法的低階特征組合能力通常較弱;現有文本型推薦算法如邏輯回歸(logistic regression,LR)[12]、因子分解機(factorization machines,FM)[13]等應用于作物推薦可以通過低階特征組合學習文本特征之間的相關性,但是沒有結合數值域特征,從而導致高階特征組合能力較弱;除此之外,基于獨熱編碼(one-hot encoding)[14]的文本域數據處理方式會導致樣本特征非常稀疏,這極大的增加了融合土壤數值域與文本域數據進行推薦的難度。傳統推薦算法可以很好地學習文本域特征之間的低階交叉,深度學習推薦算法在高階特征交叉上表現良好,結合二者優點的廣度與深度模型[15]通過組合數值域與文本域模型聯合訓練的方法在具有多域特性的數據上表現出較好的性能。但是應用在作物推薦領域還存在以下問題:一是土壤數據存在殘缺、重復、不平衡的問題,直接利用這些數據訓練推薦模型會降低模型的精度和適用性;二是廣度與深度模型采用二分類激活函數進行決策,無法應用于多分類土壤作物推薦。
針對上述問題,提出了一種基于土壤數據廣度與深度模型的作物推薦算法。首先對殘缺、重復和不平衡的土壤數據進行數據預處理,其次將土壤文本域數據經過獨熱編碼轉化成稀疏的向量特征。然后對文本域向量特征進行向量嵌入,同時采用廣義線性回歸[16]進行特征組合來提取文本域特征相關性,并通過深度神經網絡對級聯的文本域特征和數值域特征進行自動組合提取高階特征關系;最后改進多分類激活函數并通過聯合訓練的方式加權得出預測結果。通過邏輯回歸與深度神經網絡組合的方法訓練多域特性的土壤數據從而提高模型的精度。
1 SWD作物推薦算法
基于土壤數據廣度與深度模型(soil width and depth,SWD)的作物推薦算法的網絡結構如圖1所示,圖中N、P、K、OM分別表示土壤數值域數據中氮、磷、鉀、有機質的含量。LT、SL、PL分別表示土地類型、土壤類型和歷史種植作物的文本域數據。原始多域土壤數據首先在數據增強層進行人工數據預處理并且采用合成少數類過采樣技術[17](synthetic minority oversampling technique,SMOTE)對數據進行增強,然后再通過多域數據編碼層把增強后的數值域數據經過累計分布函數(cumulative distribution function,CDF)映射到(0,1)進行歸一化。文本域數據在獨熱編碼后通過向量嵌入的方法轉化成低維稠密的特征向量,該特征向量在多域數據融合層與數值域向量級聯。級聯向量輸入到深度部分,經過1 024,512,256大小的隱藏層,通過數值域數據與文本域數據的特征自動交叉學習高階的特征組合。在廣度部分把LT、ST分別與PT聯合形成交叉積,學習文本域特征的相關性。采用聯合訓練的方式在反向傳播的同時作用于這兩部分模型,單個模型的權重更新會受到廣度部分和深度部分對模型訓練誤差的共同影響,最后通過Softmax函數實現多分類的作物推薦。
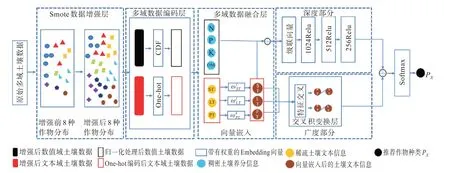
圖1 土壤數據廣度與深度模型圖Fig.1 Width and depth model of soil data
1.1 數據處理
由于土壤數據具有殘缺、重復和不平衡的特性,直接輸入會影響模型的性能。對于殘缺土壤數據,采取均值補齊的方法進行處理,對于重復土壤數據直接刪除,對于不平衡數據,采用一種基于隨機過采樣算法改進的方案進行處理。由于隨機過采樣采取簡單復制樣本的策略來增加少數類樣本,這種方式容易產生模型過擬合的問題,即模型學習到的信息過于特殊而不夠泛化。針對這一問題,采用SMOTE算法對數據進行處理,其基本思想是對少數類樣本進行分析并根據合成新樣本添加到數據集中,具體如圖2所示。
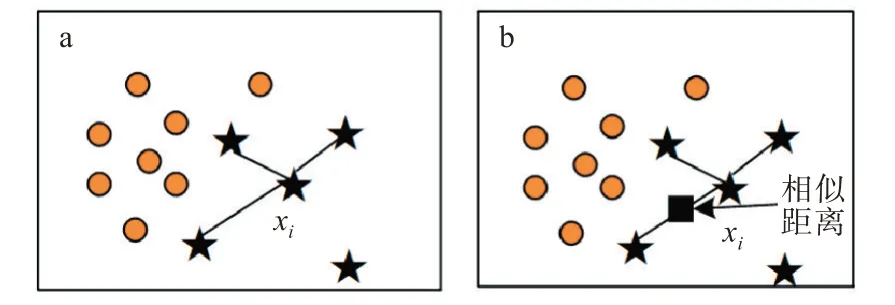
圖2 數據增強過程圖:(a)計算少樣本集,(b)取樣合成新樣本Fig.2 Diagrams of data enhancement process:(a)small sample set by calculation,(b)synthesizing new sample by sampling
算法流程如下:
1)對于少數類中每一個樣本,以歐氏距離為標準計算它到少數類樣本集Smin中所有樣本的距離,得到其k近鄰。
2)根據樣本不平衡比例設置一個采樣比例以確定采樣倍率N。對于每一個少數類樣本,從其k近鄰中隨機選擇若干個樣本,假設選擇的近鄰為xn。
3)對于每一個隨機選出的近鄰xn,分別與原樣本按式(1)構建新的樣本。
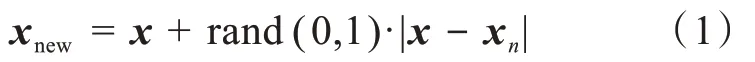
1.2 廣度模型
廣度部分是廣義的線性模型,采用正則化引導方法(follow the regularized leader,FTRL)來優化邏輯回歸模型。FTRL是一種在處理凸優化問題上性能非常出色的梯度下降的模型優化方法。邏輯回歸模型如式(2)所示:

其中y是模型的預測值,即作物被推薦種植的概率。w是d維權重向量,w=[w1,…,wd],表示土壤文本特征與作物關聯權重。x是土壤文本特征,它是一個d維的向量,x=[x1,...,xd]是每個特征對應的向量,d是特征的數量,b是模型的偏差。其目標函數如式(3)所示:
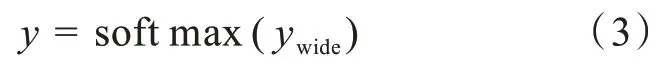
該目標函數表示預測種植的作物。在推薦算法中文本在計算機中的表示一般采用獨熱編碼的方式。例如,土地的類型、土壤類型、作物種類3個文本特征使用獨熱編碼表示,如表1所示。

表1 獨熱表示示例Tab.1 One-hot representation example
獨熱表示法是特征處理的一種稀疏表示方法,均用0、1矩陣表達計算機中的文本特征。當表示水稻種植在梯田上的水稻土中的獨熱編碼為:[[1,0],[0,1,0],[0,0,0,1]]。
廣度模型處理土壤數據的文本特征時,采用交叉積變換來提取土壤數據文本域特征之間的相關性。其定義如式(4)所示:
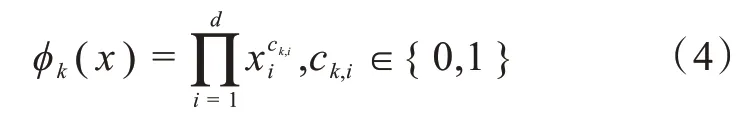
其中,?k(x)表示輸入土壤文本特征x的交叉積特征,表示第i維土壤文本特征x是否參與第k個交叉特征的構造,k表示第k個交叉特征,d表示文本特征x的維度。c k,i是一個布爾型變量,0表示第i維土壤文本特征x未參與第k個交叉特征的構造,1表示參與構造。該公式用于捕獲特征與特征之間的相關性。在線性模型中添加非線性項可以提高模型的精度。通過與深度模型的聯合訓練,經過激活函數輸出最終的作物推薦。
1.3 深度模型
深度部分采用的是AdaGrad[18]優化的深度神經網絡。因為深度神經網絡模型的輸入是連續而稠密的特征,因此需要對土壤數據進行數據編碼處理。對于土壤信息的數值型特征,例如土壤中的養分含量:氮、磷、鉀、有機質的含量通過分布損失函數進行歸一化。而對于土壤類型、地塊類型這些文本域特征,因為其高維稀疏的特點,在訓練時在多域數據融合層嵌入向量將其轉化為稠密的低維向量才能適用于深度學習訓練。稠密的低維向量需要連接土壤數值型特征,作為第一個隱藏層的輸入。在模型訓練階段會根據最終的損失函數反向傳播進行參數更新。嵌入向量被隨機初始化并根據最小化最終的損失函數來學習向量參數。這些低維稠密的向量隨后在神經網絡的前饋通路中被輸入到隱藏層中。每個隱藏層如式(5)所示。

其中l是隱藏層的數量,f是激活函數,通常為Relu函數。a(l),b(l)和w(l)分別為l層的激活值、偏差和模型權重。深度部分利用神經網絡表達能力強的特點進行深層特征交叉來挖掘土壤數值域與文本域數據之間的內在關聯,提高模型的精度。
1.4 協同訓練
協同訓練采用廣度與深度聯合訓練的方式結合二者各自的優點。廣度模塊和深度模塊的組合依賴于對其輸出對數幾率的加權求和作為預測值,然后將預測值輸入到邏輯損失函數中進行聯合訓練。聯合訓練是在訓練環節同時優化廣度模型與深度模型,廣度部分補充深度部分的弱點,通過小批量隨機優化技術同時將輸出的梯度反向傳播到深度和廣度兩部分實現。在實驗中,使用FTRL算法以及正則化來優化廣度部分的模型,并使用AdaGrad優化深度部分。聯合訓練如式(6)所示:

其中,P表示預測作物的精確度,Y是作物分類標簽,σ(.)是Softmax函數,?(x)是特征x的交叉積變換,b是偏差項,wwide是所有wide模型的權重向量,wdeep是最終激活alf的權重。
1.5 多分類損失函數
在廣度與深度模型中激活函數采用的是Sigmoid進行二分類推薦。Sigmoid可以將一個實數映射到(0,1)的區間。其損失函數為二分類交叉熵損失函數,如公式(7)所示。

其中y表示真實標簽的分布,a表示訓練后的模型的預測標簽分布,交叉熵損失函數可以衡量y與a的相似性。然而由于農業場景下的作物種類眾多,導致廣度與深度模型不能適用于多分類的作物推薦場景。Softmax激活函數相對于Sigmoid激活函數具有多分類的特性,可以將K維的實數向量壓縮(映射)成另一個K維的實數向量,其中向量中的每個元素取值都介于(0,1)之間,適用于多分類問題。其損失函數為多類別交叉熵損失函數,如公式(8)所示。

Li表示第i個特征點的交叉熵,pi,j表示第i個特征點是j作物類別的預測概率,ti,j表示該特征點的實際作物類別標簽。即將所有概率分配給每個特征點單個類別的目標,再將整數目標值轉化分類目標值。多類別交叉熵損失函數適用于Softmax激活函數的多分類場景。
2 實驗部分
2.1 數據及實驗設置
算法基于TensorFlow框架,深度學習服務器中 CPU 為 Intel 6700K,GPU 為 NAVIDIA GTX1080Ti。數據來源于中國主要農田生態系統的養分循環試驗數據庫,該數據庫源于中國科學院對中國生態系統規律研究,并且對農田生態系統進行長期養分循環實驗進而收集并且整理的土壤信息數據庫。本文整理了該數據庫中的2 512條土壤數據,其中每條數據包括土壤類型、地塊類型,土壤中液態氮、速效磷、速效鉀、有機質的含量和作物種類。作物種類包含中國中部以及東部常見耕地作物8種:小麥、水稻、玉米、糜子、黃豆、花生、蕎麥、谷子。以6∶2∶2的比例將數據集隨機分為1 884條數據的訓練集、628條數據的驗證集和628條數據的測試集。另外使用本課題組采集的112條土壤數據作為泛化實驗的測試集。設計了4組實驗來驗證本文方法的性能。第1組實驗比較了不同數據增強方法的性能,第2組進行了消融實驗,第3組對比了現有數值型作物推薦方法和經典推薦算法,第4組實驗進行了泛化能力的測試。
2.2 數據預處理
由于實際場景下土壤數據具有殘缺、重復和不平衡的特性,因而在實驗之前需要對土壤數據進行預處理,否則會影響實驗的性能。用SMOTE方法進行數據平衡化處理,將8種常見耕地的實驗數據保持在平均的狀態。
2.3 評價指標
推薦算法的評價指標有精確率P,召回率R和F1值,具體如式(9)所示。其中Tp為準確預測的土壤數據個數,Fp為模型識別到的不相關土壤數據個數,FN為模型沒有檢測到的土壤數據個數。

2.4 實驗結果與比較
為了驗證所提算法的性能,分別從以下幾方面進行實驗:增廣數據對比實驗、消融實驗、現有作物推薦算法對比實驗。
對比算法分為兩類:一類是現有數值型作物推薦算法;另外一類是處理交叉特征能力較強的經典推薦算法,分別是乘積神經網絡[19](productbased neural networks,PNN)和深度交叉神經網絡[20](deep crossing networks,DEEPCROSS)。
1)RFSVM:現有數值型作物推薦算法,利用隨機森林篩選特征得到一個最優子集然后采用SVM算法進行作物預測。
2)PNN:是一種經典推薦算法,對不同特征域采用內積、外積等多積操作在深度學習框架上提高模型特征交叉的能力從而提高模型的精度。
3)DEEPCROSS:是一種經典深度學習推薦模型框架,采用深度多層特征交叉提高模型的精度。
2.4.1 增廣數據對比實驗 分別以中華土壤數據庫采集的2 512條原始數據、采用隨機過采樣技術(oversampling,OS)增強的數據以及用SMOTE方法增強的數據進行對比實驗。隨機過采樣是對較少的類按一定比例進行一定次數的隨機抽樣,然后將每次隨機抽樣所得到的數據集疊加。圖3為實驗數據分布圖。

圖3 實驗數據分布圖:(a)原始數據圖,(b)隨機過采樣增強圖,(c)SMOTE增強圖Fig.3 Diagrams of experimental data distribution:(a)original data,(b)random oversampling enhancement,(c)SMOTEenhancement
在數據增強前,8種作物的種類分布不平衡并且數據量少,如圖3(a)所示。采用隨機過采樣方法進行增強的數據本質上沒有添加新數據,抽取了少數類并且將數據疊加在樣本空間的分布不變,但是每個少數類的樣本變多了,在圖3(b)中從淺紅色變成深紅色。采用SMOTE方法增強的數據,在樣本空間內的分布變多并且更加均衡,適合模型的訓練,如圖3(c)所示。對樣本增強數量與模型準確度實驗,實驗結果如圖4所示。

圖4 不同增強方法本文模型性能圖Fig.4 Model performance diagram of different enhancement methods
其中,NO-SWD、OS-SWD、SWD分別表示未增強、隨機過采樣增強、SMOTE增強后的本文模型。橫軸代表作物增強的數量,縱軸表示在增強后數據上本文模型的準確度。從實驗結果可以看出,當作物種類的數量在1 300條時趨于穩定并且達到最好的效果,經過隨機過采樣和SMOTE方法增強后的模型達到91.2%和92.1%。經過隨機過采樣方法增強的數據在本文模型上提升0.4%,相較于未增強數據,采用SMOTE方法增強的方法提高了1.3%,對預測的精準度的提升更優。這是因為實際土壤數據不平衡的特點會影響模型的精確度和適用性,隨機過采樣技術會導致嚴重過擬合效果欠佳,而SMOTE平衡后的數據在模型上有更優的表現。
2.4.2 消融實驗 以6∶1的比例隨機將中華土壤數據庫提取的土壤數據分為訓練集和測試集,分別在LR、DNN以及本文方法上進行測試。實驗結果如表2所示。
從實驗結果可以看出,本文提出的方法在土壤數據集上的表現達到91.8%,比LR高7.3%,比DNN高5.1%。因為LR依賴人工選擇特征和先驗信息,無法進行高階特征組合導致模型精度降低。DNN可以很好地通過特征自動交叉學習高階的土壤數值域特征關系,但卻無法融合土壤文本域信息從而造成模型精度較低。本文方法融合文本域數據與數值域數據進行作物推薦,并且使用聯合訓練的方法,使Wide部分訓練文本特征關系反作用于Deep部分從而提高模型的精度。
2.4.3 現有作物推薦算法對比實驗 為了驗證本文方法的性能,本小節與現有作物推薦算法以及經典推薦模型進行對比,實驗結果如表3所示。

表3 現有作物推薦算法對比Tab.3 Comparison of existing crop recommendation algorithms
由表3可以看出,所提模型的精確度比RFSVM提高了5.1%。相比于RFSVM,本文方法融合了多域土壤數據,并且進行數值域與文本域數據間的特征交叉,從而使得模型的精度更高。本文方法分別比PNN、DEEPCROSS高出了1.6%和3.7%。因為本文算法結合了傳統推薦算法優秀的低階特征學習能力和深度學習推薦算法優秀的高階特征學習能力,因而在土壤數據上的表現優于主流推薦模型。
通過RFSVM以及經典深度學習推薦模型進行對比驗證本文算法的優越性。首先相比于RFSVM,本文算法引入土壤文本域數據,并且通過挖掘土壤文本域特征之間的相關性提升預測精度。其次,RFSVM屬于傳統機器學習算法,在高階特征交叉性能上有所欠缺,而本文通過傳統算法與深度神經網絡模型結合的方法,可以同時使模型在低階和高階的特征交叉上表現優秀。最后本文選取了經典深度學習推薦模型PNN、DEEP CROSS作為對比算法,在本文數據集上進行實驗,實驗結果表明在多域土壤數據的特征處理上,本文算法表現更佳。
2.4.4 不同測試集對比實驗 實驗以6∶1的比例隨機將中華土壤數據庫提取的土壤數據分為訓練集和測試集1(Test1)以及武漢工程大學采集的土壤數據作為測試集2(Test2)分別在RFSVM以及本文方法進行測試。實驗結果如表4所示。
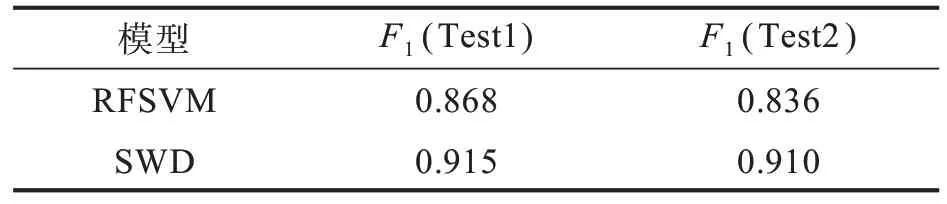
表4 不同數據集測試結果Tab.4 Test results on different data sets
從測試結果可以看出,RFSVM方法推薦作物種類時的效果在Test1與Test2相差3.2%,而本文方法在Test1與Test2僅相差0.5%。這是因為現有RFSVM方法不能通過多層的特征交叉來提高模型的泛化能力,因此在本課題組采集的數據集上測試表現較差。
3 結 論
針對常見的推薦模型無法充分地挖掘多域土壤特征以及其特征關系的問題,提出基于土壤數據廣度與深度模型的作物推薦算法。1)對土壤數據進行增強,獲得更為均衡的土壤數據作為模型的輸入;2)融合多域的土壤數據進行作物推薦,同時學習了土壤數值域數據與文本域數據的特征關系,并分析了該關系對作物推薦的作用;3)改進了多分類的激活函數,使二分類推薦模型能應用于土壤作物推薦領域。但是由于推薦任務的單一性,可能造成不能滿足復雜的實際推薦場景,在后續的研究中,將綜合推薦評估方法以及動態土壤數據進行多任務的推薦。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
電子制作(2018年18期)2018-11-14 01:48:06
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
