基于K- Means 聚類算法的數(shù)據(jù)分析
2021-08-23 07:15:44邵小青賈鈺峰章蓬偉
科學(xué)技術(shù)創(chuàng)新 2021年23期
邵小青 賈鈺峰 章蓬偉 丁 娟
(新疆科技學(xué)院信息科學(xué)與工程學(xué)院,新疆 庫爾勒 841000)
1 概述
機(jī)器學(xué)習(xí)中有兩類大問題:一個是聚類,另一個是分類。聚類是統(tǒng)計學(xué)的概念,屬于非監(jiān)督機(jī)器學(xué)習(xí)(unsupervised learning),應(yīng)用中數(shù)據(jù)挖掘,數(shù)據(jù)分析等領(lǐng)域,根據(jù)數(shù)據(jù)不同特征,將其劃分為不同的數(shù)據(jù)類,屬于一種無監(jiān)督學(xué)習(xí)方法。它的目的是使得屬于同一類別個體之間的密度盡可能的高,而不同類別個體間的密度盡可能的低[1]。分類是用已知的結(jié)果類別訓(xùn)練數(shù)據(jù),對預(yù)測數(shù)據(jù)進(jìn)行預(yù)測分類,屬于有監(jiān)督學(xué)習(xí)(supervised learning),常見的算法如邏輯回歸、支持向量機(jī)、深度學(xué)習(xí)等。聚類也是對數(shù)據(jù)進(jìn)行歸類,不過聚類算法的訓(xùn)練數(shù)據(jù)只有輸入,事先并不清楚數(shù)據(jù)的類別,通過特征的相似性對文本進(jìn)行無監(jiān)督的學(xué)習(xí)分類。聚類試圖將數(shù)據(jù)集中的樣本劃分為若干個通常不相交的子集,每個子集稱為一個簇(cluster)[2]。K-means 屬于經(jīng)典聚類算法,根據(jù)樣本間的距離或者相異性進(jìn)行聚類,把特征相似的樣本歸為一類,相異的樣本歸為不同的簇。
2 理論基礎(chǔ)

While(t) t 為迭代次數(shù)
For i in range(n+1): #n 為樣本點(diǎn)個數(shù)。
For j in range(k+1): #k 為簇的數(shù)目。
For i in range(k+1): #計算樣本i 到每個簇質(zhì)點(diǎn)j 的距離。
找出屬于這個簇中的所有數(shù)據(jù)點(diǎn),計算這類的質(zhì)心。重復(fù)以上步驟,直到每類質(zhì)心變化小于設(shè)定的閾值或者達(dá)到最大的迭代次數(shù)。設(shè)置最大特征數(shù),設(shè)置分類的組K 值,訓(xùn)練特征數(shù)據(jù)進(jìn)行數(shù)據(jù)分析。
本文將數(shù)據(jù)過濾清洗,去除停用詞轉(zhuǎn)化為向量模型,使用TF-IDF 算法對詞頻進(jìn)行權(quán)重計算,TF 是詞頻,IDF 是逆文檔頻率,TF-IDF 反應(yīng)了一個詞在文本中的重要性它的值是TF×IDF。 使 用 Python 中 的 sklearn 模 塊 的 TfidfTransformer、CountVectorizer 方法計算TF-IDF 值,轉(zhuǎn)化為空間向量模型,選用K-means 聚類算法對數(shù)據(jù)進(jìn)行挖掘與分析。
3 實(shí)驗(yàn)結(jié)果與分析
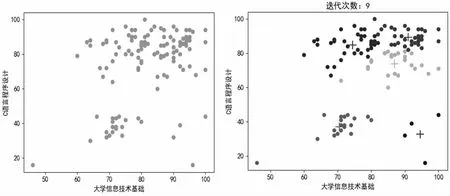
本文選擇新疆科技學(xué)院某專業(yè)期末作為分析對象,選取大學(xué)信息技術(shù)基礎(chǔ)和C 語言程序設(shè)計成績作為實(shí)驗(yàn)數(shù)據(jù)。利用Python 聚類模塊K-means 構(gòu)建聚類模型并實(shí)例化,設(shè)置分類K=5 值。其中K 值選取直接影響K-means 算法的準(zhǔn)確性,選取K值常見的方法有手肘法、Gap statistic 方法。下一步訓(xùn)練特征數(shù)據(jù),查看聚類結(jié)果labels,對數(shù)據(jù)進(jìn)行聚類分析,部分代碼如下。


4 結(jié)論與不足
通過對數(shù)據(jù)聚類分析表明成績可以大致分為4 類,其中大學(xué)信息技術(shù)基礎(chǔ)學(xué)生成績較好,C 語言程序設(shè)計對學(xué)生有一定難度,想要提高總體成績,需要重點(diǎn)放到在C 語言程序設(shè)計這門課上,建議優(yōu)化教學(xué)設(shè)計,采取任務(wù)驅(qū)動式教學(xué),分層次因材施教,培養(yǎng)好學(xué)生的計算思維能力,為后面的專業(yè)課打好基礎(chǔ)。
K-means 具有實(shí)現(xiàn)簡單,應(yīng)用廣泛等優(yōu)點(diǎn),但由于需要指定K 值簇,直接影響分類的準(zhǔn)確性,聚類結(jié)果可能會收斂到局部最小值。對于不規(guī)則形狀的數(shù)據(jù)效果差。在現(xiàn)實(shí)生活中,簇并不總是均勻分布的,并且特征的權(quán)重很少相等。本文對期末成績數(shù)據(jù)進(jìn)行聚類分析是cluser 設(shè)置成5,有一定的滿目性,通過迭代9 次各組數(shù)據(jù)達(dá)到收斂。下一步要提高數(shù)據(jù)集的數(shù)量,選擇學(xué)生所有的成績數(shù)據(jù),合理選擇K 值,高維映射等,優(yōu)化K-means 算法,更客觀地進(jìn)行數(shù)據(jù)分析。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
