基于系統調用行為相似性聚類的主機入侵檢測方法研究
2021-08-23 06:03:46羅森林
信息安全研究 2021年9期
李 橙 羅森林
(北京理工大學信息系統及安全對抗實驗中心 北京 100081)(lc_bitsec@foxmail.com)
惡意軟件的數量隨著網絡技術的迅速發展在逐年增多,計算機也面臨越來越多的病毒、木馬和其他惡意軟件攻擊的威脅.賽門鐵克2019年發布的互聯網安全威脅報告中指出,賽門鐵克全球情報網絡日均攔截的威脅數量高達1.42億個.因為收益高、成本低等原因,針對主機的挖礦劫持和勒索軟件仍是網絡犯罪分子首選的攻擊手段[1].基于主機的入侵檢測系統(host-based intrusion detection system, HIDS)用于檢測入侵行為并發出警報,可以阻止惡意軟件的惡意行為[2],從而保護主機的安全.
系統調用序列是由系統調用組成的包含順序關系的序列,系統調用是操作系統實現并提供給應用程序調用的一系列內核函數,應用程序的行為目標幾乎都是通過系統調用實現[3].系統調用表示應用程序的底層行為,是現階段用于入侵檢測的最佳數據粒度[4],并且系統調用可以實時的獲取,從而完整地監視整個系統的行為.誤報率是HIDS的重要衡量指標之一[5],較高的誤報率會影響HIDS的檢測性能,甚至使得HIDS失效[6].Murtaza等人[7]指出引起誤報的其中一個原因是基于n-gram的入侵檢測方法對原始系統調用序列進行特征提取是一種精確匹配方式,導致構建的模型泛化能力較弱,據此本文提出基于內核模塊的系統調用抽象方法.該方法建立系統調用和系統內核模塊的映射關系,根據該映射關系將系統調用序列轉換為用內核模塊表示的抽象系統調用序列,以提升模型的泛化性能,從而降低誤報率.
基于內核模塊的系統調用抽象方法將Linux操作系統中約300個系統調用抽象為8個內核模塊表示,但同一內核模塊的部分系統調用存在較大行為差異,且不同內核模塊也含有行為相似的系統調用.例如系統調用子序列“open,llseek,read”和“chdir,lstat,chmod”使用相同的內核模塊抽象表示,即“Kernel,Kernel,Kernel”,但2個序列表達的行為語義不同,前者每個系統調用的行為分別是打開文件、設置讀取位置、讀取內容,序列表達讀取文件內容的行為語義;后者每個系統調用的行為分別是切換目錄、獲取文件狀態信息、修改文件的權限,序列表達修改文件權限的行為語義,使用相同內核模塊抽象表示不同行為的系統調用會導致系統調用序列的行為語義難以充分表達,影響入侵檢測性能.
通過分析Linux操作系統中的系統調用,發現某些系統調用的行為非常相似,例如“getuid”和“geteuid”都表示獲取用戶ID,“stat”“fstat”“lastat”“fstatat”都表示獲取文件的狀態信息.不同內核模塊的系統調用也存在相似的行為,例如分別屬于“Kernel”和“File System”內核模塊的系統調用“fchown32”和“setfsuid”都表示對文件權限的設置.針對上述問題和分析,本文提出一種基于系統調用行為相似性聚類的系統調用抽象入侵檢測方法.
1 相關工作
受生物體的自然免疫系統啟發,Forrest等人[8]首次提出將系統調用序列用于入侵檢測,提出序列延時嵌入(sequence time delay embedding, STIDE)方法.STIDE通過在正常系統調用序列上滑動一個長度為n的窗口(即n-gram)來建立一個正常序列的數據庫.然后從未知行為的序列中提取長度為n的序列,并將其與數據庫進行比較,如提取的序列不在數據庫中,則將其所在的序列視為異常序列.
Creech等人[4]提出一種新的基于語義的入侵檢測方法來降低誤報率,使用不同長度的系統調用組成單詞,基于語義的短語字典又由單詞組成,使用極限學習機進行異常檢測,該方法在ADFA-LD[9]數據集上進行實驗,結果顯示當檢測率為100%時,誤報率為20%,但模型訓練需要數周的時間.
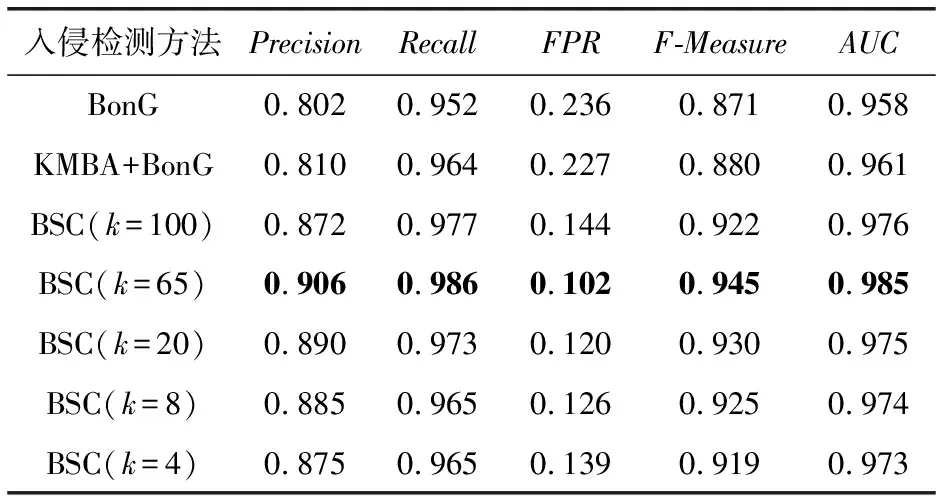
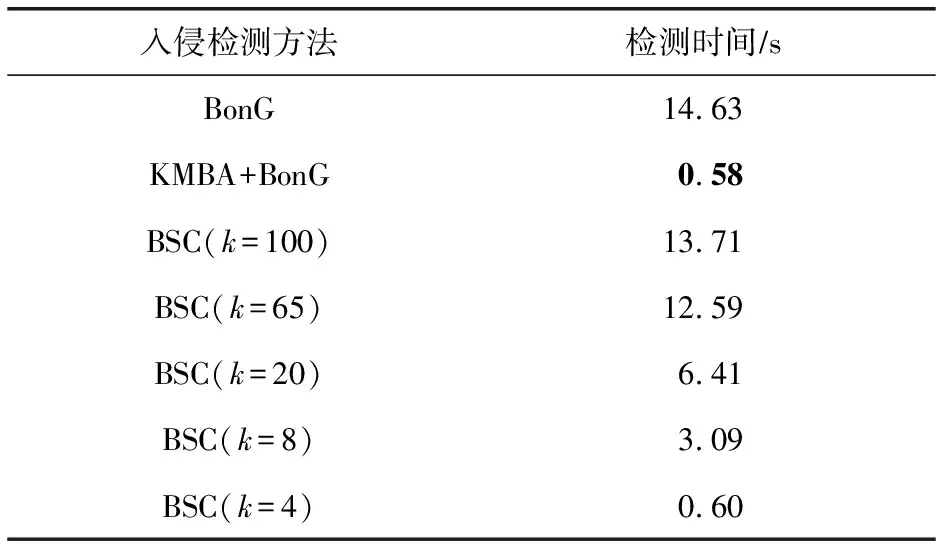
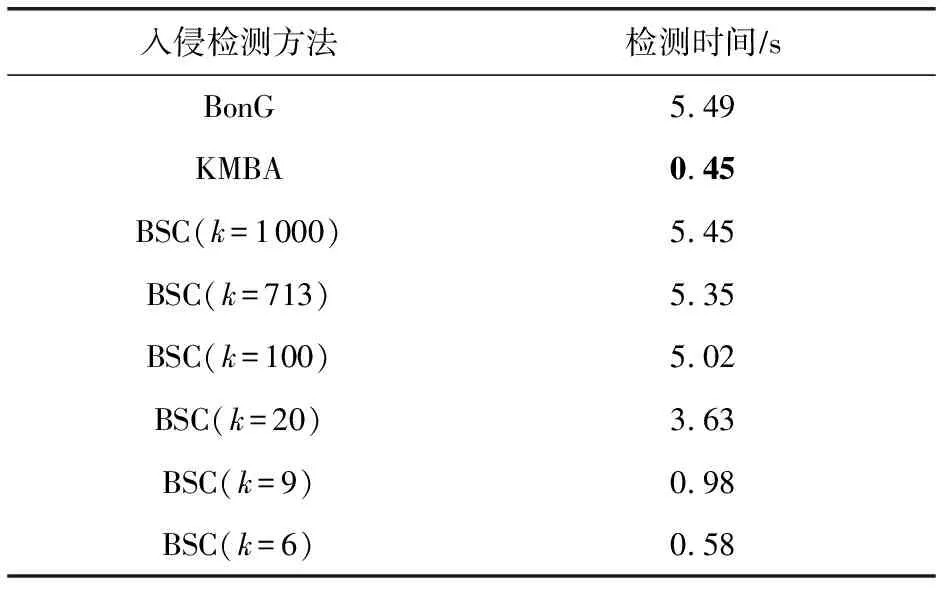
Aghaei等人[10]通過提取正常和惡意系統調用序列上所有的n-gram(1 Zhao等人[11]提出了一種具有連續重疊子序列交叉熵的混合n-gram(H-gram)特征提取方法,該方法實現了對API調用或指令序列的語義分割,提取的API序列的特征維度非常大,于是使用基于聯合熵的特征選擇方法進行降維.實驗結果顯示使用混合n-gram的特征提取方法比使用固定長度的n-gram的特征提取方法能夠得到更高的準確度和更低的誤報率. Murtaza等人[7,12]將系統調用按照其所屬的內核模塊分為8類(Architecture,File System,Inter Process Communications,Kernel,Memory Management,Networking,Security,Unknown),并將系統調用序列使用這8類內核模塊進行抽象表示,然后將抽象的系統調用序列作為STIDE和馬爾可夫模型的輸入,結果表明該方法可以降低誤報率并減少入侵檢測的執行時間. 誤報率是入侵檢測系統重要的衡量指標之一,許多方法被提出用于降低誤報率,基于內核模塊抽象的主機入侵檢測方法通過內核模塊對系統調用行為進行抽象表示,但在同一內核模塊的部分系統調用存在較大行為差異,且不同內核模塊也含有行為相似的系統調用,造成行為抽象映射的混淆,影響檢測效果.針對該問題,本文提出基于系統調用行為相似性聚類的主機入侵檢測方法. 基于系統調用行為相似性聚類的主機入侵檢測方法如圖1所示.系統調用序列作為系統調用抽象步驟的輸入,通過基于系統調用行為相似性聚類的系統調用抽象方法轉換為系統調用抽象序列,然后使用系統調用抽象序列進行模型的構建與分類. 圖1 主機入侵檢測方法原理框架圖 系統調用序列抽象步驟中,首先使用Word2Vec對原始系統調用序列進行詞嵌入得到詞向量,再使用k-means聚類算法對系統調用詞向量進行聚類,得到系統調用抽象映射字典,最后使用抽象映射字典將系統調用序列轉換為系統調用抽象序列. 2.2.1 Word2Vec相似性特征提取 Word2Vec是從大量文本語料中以無監督的方式學習語義知識的一種淺層神經網絡模型,它被大量地用在自然語言處理中,通過學習文本來用詞向量的方式表征詞的語義信息,即通過一個嵌入空間使得上下文相似的單詞在該空間內余弦距離很近. 使用Word2Vec對系統調用進行詞嵌入,構建連續稠密詞向量實現多維度系統調用行為語義相似性信息提取.將系統調用視為一個單詞,根據其所要實現的功能來描述這個詞的行為語義,不同的系統調用在不同維度上可能具有行為語義相似性.例如在某一維度上系統調用“chmod”“fchmod”“fchmodat”的功能都是更改文件的權限,在另一維度上系統調用“read”“write”“open”的功能都是對文件的操作.通過Word2Vec模型訓練輸出的連續稠密詞向量可以在多個維度上表達這種行為語義相似性,具有相似行為語義的系統調用的詞向量在空間上的余弦距離相近. 2.2.2k-means聚類 采用k-means算法對系統調用進行聚類.k-means是一種基于距離的無監督學習聚類算法,以歐氏距離作為相似性指標,將輸入的樣本按照指定的聚類簇數k,分為k個簇.算法具體描述如下: 步驟1.隨機選取k個樣本作為初始的聚類中心a=(a1,a2,…,ak); 步驟2.針對數據集中每個樣本xi,通過式(1)計算它到k個聚類中心的距離,并將其分到距離最小的聚類中心所對應的簇中,其中Ci為樣本xi被分到的簇,aj為第j個聚類中心: Ci (1) 步驟3.對每一個簇,通過式(2)重新計算其聚類中心aj,其中Ci為第i個簇. (2) 然后重復步驟2和步驟3,直到達到終止條件(最大迭代次數、誤差平方和局部最小、聚類中心不變或變化很小等). (3) 由于k-means算法無法在計算中確定需要聚類的簇的數量,需要指定聚類的簇數,即聚類k值,在本文中使用輪廓系數法來確定最佳的聚類k值.輪廓系數法是聚類效果好壞的一種評價方式,該方法結合內聚度和分離度2種因素,當輪廓系數越大表示分類效果越好. 2.2.3 抽象映射 使用k-means算法對歸一化后的系統調用詞向量進行聚類,可以得到系統調用Si與其分類后所屬簇Cj(j=0,1,…,k-1)的映射關系,如式(4),該映射關系構成的空間稱為系統調用抽象映射字典. f(Si)=Cj. (4) 對于系統調用序列T={S1,S2,…,Si}(i等于系統調用序列T的最大長度),通過式(4)將其轉換為抽象的系統調用序列AT={f(S1),f(S2),…,f(Si)}. 將抽象后的系統調用序列分為訓練集和測試集,將訓練集用于入侵檢測模型的訓練,測試集用于測試模型的分類性能.使用入侵檢測模型BonG(bag ofn-grams)[13]進行模型構建.該方法提取窗口大小為6的n-gram短序列,然后將得到的所有n-gram按照tf-idf值進行排序,取tf-idf值排名前70%的n-gram作為系統調用序列的特征集.對于每個系統調用序列i,用xi={n1,n2,…,nm}表示n-gram的集合,其中m為系統調用序列進行處理后得到的n-gram的總數,每個n-gram用特征向量nj=(s1s2s3s4s5s6)表示,其中1≤j≤m. BonG在隨機森林算法上取得了最佳結果,因此實驗使用隨機森林對模型進行訓練和分類,隨機森林是一種集成學習分類器,它通過集成學習的思想將多棵決策樹進行集成,相較于單分類器其性能更好.隨機森林結合“bagging”和隨機抽樣的思想,使用bootstrap樣本(從訓練集隨機抽樣產生的訓練子集)構建連續且獨立的決策樹,對于一個輸入樣本,N棵決策樹會有N個分類結果,隨機森林集成所有的分類投票結果,將投票次數最多的類別指定為最終的輸出.與單分類器相比,隨機森林會有更好的分類結果. 為了驗證基于系統調用行為相似性聚類的主機入侵檢測方法(system call abstract intrusion detection method based on system call behavior similarity clustering, BSC)能夠提升檢測效果,本文研究了不同聚類簇數k對入侵檢測效果和入侵檢測時間的影響,并與基于內核模塊的系統調用抽象的方法(kernel module based system call abstraction method, KMBA)[7]和BonG[13]進行對比. 使用ADFA-LD[9], ADFA-WD[14]能代表當前攻擊方法的數據集進行實驗,2個數據集均由訓練集(training data master, TDM)、驗證集(validation data master, VDM)和攻擊集(attack data master)組成,TDM和VDM由良性樣本構成,ADM由惡意樣本構成.ADFA-LD和ADFA-WD數據集的樣本數量如表1所示: 表1 ADFA-LD和ADFA-WD數據集的樣本數量 實驗環境如表2所示: 表2 實驗環境 采用精度(Precision)、召回率(Recall)、誤報率(FPR)、F值(F-Measure)和受試者工作特征(receiver operating characteristic, ROC)曲線的下面積AUC(area under roc curve)的值作為檢測效果的評價指標,采用模型測試所用的時間作為時間效率的評價指標. 惡意的系統調用序列被標記為正樣本,良性的系統調用序列被標記為負樣本.TP表示正樣本被正確分類為正樣本的數量;FP表示負樣本被錯誤分類為正樣本的數量;TN表示負樣本被正確分類為負樣本的數量;FN表示正樣本被錯誤分類為負樣本的數量. Precision的定義如式(5),它表示預測為正樣本的數量中實際為正樣本的比例: (5) Recall的定義如式(6),它表示預測為正樣本的數量與正樣本總數的比值: (6) FPR的定義如式(7),它表示分類器將負樣本錯誤預測為正樣本的比例: (7) F-Measure的定義如式(8),它是一種同時考慮Precision和Recall用于綜合評價模型的指標. (8) ROC曲線通過改變決策閾值得到,ROC曲線的縱坐標為TPR,橫坐標為FPR,當TPR達到100%(所有的惡意樣本都被檢測到)時,FPR的值越小越好,即良性樣本被誤判為惡意樣本的數量越少越好.ROC曲線的下面積AUC是一種獨立于決策閾值,用于評價模型性能的全局度量指標.該值越大越好,AUC=1代表理想模型,該模型可以實現100%的檢測率和0%的誤報率.AUC=0.5表示隨機模型,AUC<0.5表示模型比隨機模型更差,檢測率低且誤報率高. 將數據集對應的所有詞向量經過歸一化處理后作為k-means算法的輸入進行聚類,使用輪廓系數法評價不同聚類簇數的聚類效果.圖2表示ADFA-LD和ADFA-WD數據集不同聚類簇數對應的輪廓系數,橫坐標表示聚類簇數k,縱坐標表示輪廓系數,輪廓系數越大表示對應聚類簇數k的聚類效果越好.ADFA-LD數據集中共使用175個系統調用,當k=65時輪廓系數最大,ADFA-WD數據集共使用1 308個系統調用,當k=713時輪廓系數最大,故選取k=65和k=713分別作為ADFA-LD和ADFA-WD數據集由輪廓系數法確定的最佳聚類簇數.此外我們還選取k=100,k=20,k=8,k=4對ADFA-LD數據集的系統調用進行聚類,選取k=1 000,k=100,k=20,k=9,k=6對ADFA-WD數據集的系統調用進行聚類. 圖2 ADFA-LD和ADFA-WD數據集不同聚 類簇數k對應的輪廓系數 對比方法中,基于內核模塊的系統調用序列抽象方法[12]僅提出針對Linux操作系統進行抽象的方法,而ADFA-WD是基于Windows操作系統的數據集.為了將基于內核模塊的系統調用序列抽象方法用于ADFA-WD數據集,我們根據基于內核模塊的系統調用序列抽象方法的思想,將ADFA-WD數據集中的系統調用抽象表示為其所在的動態鏈接庫(dynamic link Library, DLL),Linux操作系統中的內核模塊與Windows操作系統中的動態鏈接庫有相似的意義.實驗中將ADFA-LD數據集和ADFA-WD數據集的TDM和VDM合并為正常樣本(負樣本)集,ADM為惡意樣本(正樣本)集,分別將正常樣本集和惡意樣本集按照7∶3的比例分為訓練集和測試集,分別用于模型的訓練和測試. 表3列出不同入侵檢測方法在ADFA-LD數據集上取得的檢測效果評價指標,結果顯示BSC(k=65)在所有評價指標上取得最佳結果,召回率為98.6%,誤報率為10.2%,相比KMBA+BonG,召回率提高2.2%,誤報率降低12.5%;相比于BonG,召回率提高3.4%,誤報率降低13.4%.BSC(k=8)和KMBA以不同的式將Linux系統調用分為8類,BSC(k=8)和KMBA+BonG的召回率幾乎相同,但BSC(k=8)的誤報率更低,相比KMBA+BonG降低了10.1%. 表3 不同入侵檢測方法在ADFA-LD數據集取得的檢測效果評價指標 在選取的不同聚類簇數k中,BSC(k=65)在所有檢測效果評價指標上取得最佳結果,其他聚類k值(k=100,k=20,k=8,k=4)的BSC評價指標較BSC(k=65)稍有下降,其中BSC(k=4)相比BSC(k=65)召回率降低了2.1%,誤報率上升了2.6%,檢測效果評價指標下降較小;相比KMBA+BonG召回率幾乎相同,但誤報率降低了8.8%;相比BonG召回率提高了1.3%,誤報率降低了9.7%. 表4列出不同入侵檢測方法在ADFA-WD數據集取得的檢測效果評價指標,結果顯示BSC(k=713)在所有評價指標上取得最佳結果,召回率為98.0%,誤報率為5.5%,相比KMBA+BonG,召回率提高2.2%,誤報率降低32.0%;相比于BonG,召回率提高1.1%,誤報率降低15.5%. 在選取的不同聚類簇數k中,BSC(k=713)在所有檢測效果評價指標上取得最佳結果,其他聚類簇數k(k=1000,k=100,k=20,k=9,k=6)的BSC評價指標較BSC(k=713)稍有下降,其中BSC(k=9)相比BSC(k=713)召回率降低了1.7%,誤報率上升了4.6%,檢測效果評價指標下降較小;與以不同方式將Windows系統調用分為9類的KMBA+BonG相比,召回率幾乎相同但誤報率降低了27.4%;相比BonG建模方法召回率幾乎相同但誤報率降低了11.2%. 表5顯示不同入侵檢測方法在ADFA-LD數據集上的檢測時間.BonG的檢測時間為14.63 s,KMBA+BonG的檢測時間為0.58 s. BSC的檢測時間隨著聚類簇數k的減小而減少,其中檢測效果最佳的BSC(k=65)檢測時間為12.59 s,BSC(k=100)檢測時間最長,為13.71 s,BSC(k=4)檢測時間最短,為0.60 s. 表5 不同入侵檢測方法在ADFA-LD數據集上的檢測時間 表6顯示不同入侵檢測方法在ADFA-WD數據集上的檢測時間.BonG的檢測時間為5.49 s,KMBA+BonG的檢測時間為0.45 s. BSC的檢測時間隨著聚類簇數k的減小而減少,其中檢測效果最佳的BSC(k=713)檢測時間為5.35 s,BSC(k=100)檢測時間最長,為5.45 s,BSC(k=6)檢測時間最短,為0.58 s. 表6 不同入侵檢測方法在ADFA-WD數據集上的檢測時間 通過對實驗結果分析發現,在ADFA-LD數據集和ADFA-WD數據集的實驗中,BSC(k等于輪廓系數法確定的最佳聚類簇數)的所有檢測效果評價指標均為最佳,與KMBA+BonG相比,在將系統調用聚類為相同簇數進行抽象表示時,BSC檢測效果更好,說明BSC能夠有效降低行為抽象表征的混淆,提升檢測效果. 在不同聚類簇數k的BSC中,使用輪廓系數法確定的最佳聚類簇數的BSC在ADFA-LD和ADFA-WD這2個數據集上檢測效果最佳,其他聚類簇數的BSC檢測效果評價指標較BSC(k等于輪廓系數法確定的最佳聚類簇數)稍有下降,當k<輪廓系數法確定的最佳聚類簇數時,BSC各項檢測效果評價指標隨著k的減小而小幅度下降,但相比BonG和KMBA+BonG在誤報率評價指標上仍有不小的改善.在ADFA-LD數據集的實驗中,BSC(k=4)與BonG相比,檢測時間取得了95.9%的增益(檢測時間分別為0.60 s和14.63 s).在對ADFA-WD數據集的實驗中,BSC(k=9)與BonG建模方法相比,檢測時間取得了82.1%的增益(檢測時間分別為0.98 s和5.49 s).在檢測效果各項指標下降幅度較小的情況下,使用較小聚類簇數的BSC能夠大幅減少入侵檢測時間,提高檢測時間效率. 綜上所述,BSC能夠有效降低行為抽象表征的混淆,提升檢測效果.在檢測效果各項指標下降幅度較小的情況下,使用較小聚類簇數的BSC能夠大幅減少入侵檢測時間,提高檢測時間效率. 基于內核模塊抽象的主機入侵檢測方法將Linux操作系統中約300個系統調用抽象為8個內核模塊表示,旨在提升模型的泛化性能,減少誤報率,但在同一內核模塊的部分系統調用存在較大行為差異,且不同內核模塊也含有行為相似的系統調用,造成行為抽象映射的混淆,影響檢測效果.針對該問題,本文提出基于系統調用行為相似性聚類的主機入侵檢測方法.首先利用Word2Vec構建連續稠密詞向量實現多維度系統調用行為語義相似性信息提取,再使用聚類算法對系統調用進行抽象表征,從而將系統調用序列轉換為系統調用抽象序列,最后使用BonG[11]方法構建入侵檢測模型.基于ADFA-LD和ADFA-WD數據集的實驗結果表明,基于系統調用行為相似性聚類的主機入侵檢測方法分別取得了召回率98.6%、誤報率10.2%和召回率98.0%、誤報率5.5%的最佳結果.基于系統調用行為相似性聚類的主機入侵檢測方法有效降低行為抽象表征的混淆,提升檢測效果.在檢測效果各項指標下降幅度較小的情況下,使用較小聚類簇數的BSC在2個數據集上分別實現了95.9%和82.1%的檢測時間增益,大幅提高了檢測時間效率.2 基于系統調用行為相似性聚類的主機入侵檢測方法
2.1 原理框架
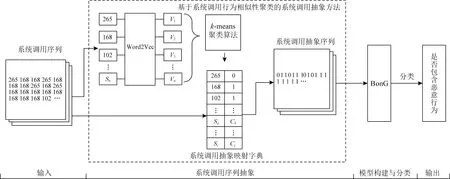
2.2 系統調用序列抽象
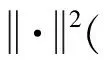
2.3 模型構建與分類
3 實驗分析
3.1 實驗目的
3.2 實驗數據與實驗環境


3.3 評價方法
3.4 實驗過程
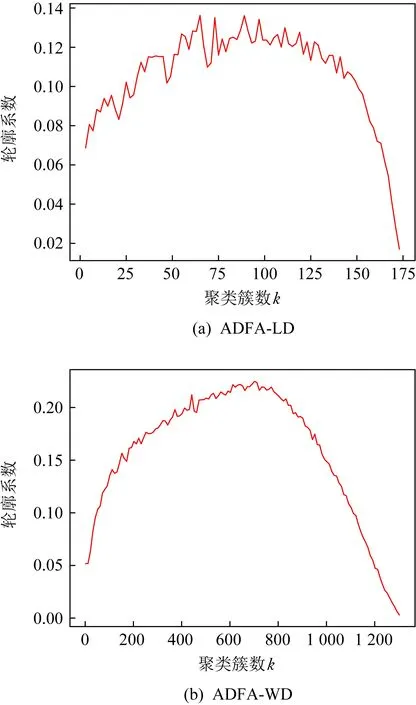
3.5 實驗結果
4 討 論
5 結 論
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
