基于組合神經網絡模型的球磨機數據插補方法研究
2021-08-23 01:06:22王智強鄭麗巖任世杰
現代礦業 2021年7期
關鍵詞:模型
孟 巍 王智強 葉 茂 鄭麗巖 任世杰
(1.鞍鋼集團礦業有限公司信息中心;2.沈陽中科奧維科技股份有限公司;3.東北大學資源與土木工程學院)
電鏟、球磨機、旋流器等大型礦業設備作為礦山運行的核心一直是企業重點關注的對象[1],這些設備出現故障,勢必導致生產停滯,甚至造成安全問題[2]。為了減少設備故障帶來的損失,企業通常會對這些設備進行監控[3]。對設備的運行監控通常是按照時間序列進行的,然而在數據采集的同時,仍然難以避免出現數據缺失的現象,而數據的丟失往往會造成預警信息的錯誤,因此通常需要對缺失的數據進行適當的處理,從而完成對設備運行狀態的正確評估[4]。
缺失數據的處理方法包括刪除法、插補法、加權法和參數似然法等,而在各種處理缺失數據的方法中,插補方法由于簡單且效果好被普遍使用[5]。隨著機器學習和深度學習的快速發展,神經網絡技術被廣泛應用于數據缺失值的處理并取得了較好的結果[6]。缺失數據的插補在一定程度上可以看成是對一些未知數據的預測[7],而利用BP神經網絡等模型對已有數據進行訓練學習,然后利用訓練好的模型輸入參數獲得預測值即可很好地解決數據缺失的插補問題。除了傳統的BP神經網絡外,循環神經網絡(簡稱RNN)將時序的概念引入到網絡結構設計中,使其在數據的分析預測中取得了更好的結果。長短期記憶(簡稱LSTM)模型作為RNN的優秀變體也被應用于各種數據的預測中[8]。為了更準確地完成缺失值的插補過程,本文利用BP神經網絡和LSTM模型相結合的方式對球磨機的缺失數據進行預測。
1 神經網絡概述
磨礦是礦石破碎的后續工序。球磨機是磨礦的主要設備。為了實時監控球磨機的運行狀態,需要采集球磨機的多項運行參數,如給礦量、給水量、壓力、電流值、給礦濃度、給水濃度、排水量等。這些參數在某種程度上存在著一定的復雜聯系,單憑經驗公式很難對因故丟失的數據進行預測補充,而神經網絡的“黑箱”特性可以解決該問題。
BP神經網絡是一種多層前饋型神經網絡,其學習過程由信號的正向傳播與誤差的反向傳播兩個過程組成。在信號正向傳播的過程中,樣本是由輸出層傳入,經過各個未顯露的隱含層內部計算后傳入輸出層,最終經輸出層處理后產生預測結果,將網絡預測值與實際值對比,計算出神經網絡的預測誤差,接著進入誤差的反向傳播階段(圖1)。誤差反向傳播時,預測誤差從輸出層傳入,經過各個隱含層處理傳入輸入層。在預測誤差的傳遞的同時,也將預測誤差分給各層,當各層獲得作為修正該層的神經元權值依據的誤差信號時,由學習信號正向傳播與誤差信號反向傳播不斷調整各層權值,當神經網絡輸出的誤差減少到設定的期望誤差或滿足當前設置的迭代次數時,終止權值的調整。

傳統的BP神經網絡不考慮數據之間的時間相關性,只將上一層的輸出作為當前層的輸入。現實中的很多數據都具有時序上的關聯性,即某一時刻網絡的輸出除了與當前隱含層的輸入相關之外,還與之前某一隱含層或某幾個隱含層的輸出有關。針對這些問題,循環神經網絡RNN模型應運而生(圖2)。在許多序列問題中,例如文本處理、語音合成及機器翻譯等,循環神經網絡都表現出了不凡的性能。然而RNN模型隨著時間序列的不斷深入,會出現“梯度消失”和“梯度爆炸”的現象。
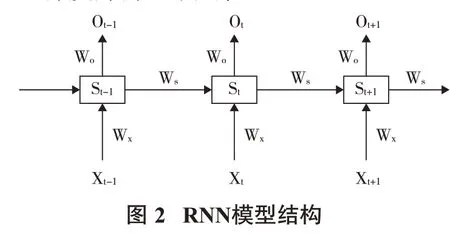
圖3中,LSTM模型作為RNN的變種,既擁有RNN在分析時序數據時的高適應性,又彌補了RNN的梯度消失和梯度爆炸問題,能有效地利用長距離的時序信息。對于球磨機的監控數據,利用好時序信息可以更有效地解決數據的缺失與插補問題。

2 組合模型方法
單一的預測模型總會有各自的優點和缺陷,如BP神經網絡的優點是具有很強的非線性映射能力和柔性的網絡結構,缺點是學習過程耗費的時間多及不易找到全局極小值點。LSTM模型的優點是在序列建模問題上有一定優勢,具有長時記憶功能,缺點是并行處理上存在劣勢。為了充分利用不同模型各自的優勢,不同模型的組合應用是一種常用的辦法,新模型將不同模型的優勢組合應用,可以使組合模型的預測結果更加接近真實值。由于球磨機的監控數據本身是關于時間的數據,可以看作時間序列,因此本文選擇LSTM模型與BP神經網絡相結合的方式對缺失數據進行預測。本文設計了基于權重分配方式的組合預測模型(圖4)。該方法的主要思路是分別使用BP神經網絡和LSTM模型對球磨機的某項缺失數據進行訓練預測,然后根據預測的準確率賦給每個算法的結果1個權重系數,將每個模型預測的結果乘以權重系數后做和,形成最終的預測結果。

預測結果公式為

式中,R為總的預測結果;Rlstm為LSTM模型的預測處理結果;Rbp為BP模型的預測處理結果。
為了使預測結果更加接近真實值,引入修正誤差方法,即誤差權重乘以訓練集平均誤差,各模型修正結果計算公式為
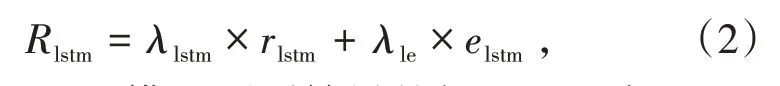
式中,λlstm為LSTM模型預測結果的權重;rlstm為LSTM模型的原始預測結果;λle為LSTM模型預測結果的誤差權重;elstm為LSTM模型在訓練集上的平均誤差。
同理,BP模型修正公式為

式中,λbp為BP模型預測結果的權重;rbp為LSTM模型的原始預測結果;λbpe為BP模型預測結果的誤差權重;ebp為BP模型在訓練集上的平均誤差。
預測權重λlstm和λbp,計算公式為

式中,acclstm為LSTM模型上預測集的準確率;accbp為BP模型上預測集的準確率。
誤差權重λle和λbpe計算公式為

式中,erlstm為LSTM模型上預測集的誤差率;erbp為BP模型上預測集的誤差率。
3 數據處理過程
試驗選取電流值、排水量、給礦量、給礦濃度、壓力、泵池高、給水量、給水濃度和給旋流器量9個球磨機監控數據,數據每隔5s采集1次,共計10萬條。將數據按9∶1分為訓練集和測試集,在給礦量數據中隨機選取10個數據刪除后作為缺失值進行預測比較。試驗采用的深度學習框架為tensorflow,具有運行速度快,結構簡潔,高層API豐富等優勢。該試驗的實現過程在jupyter編譯器上實現,試驗步驟如下。
(1)第1步引入外部包。引入tensorflow機器學習框架用以搭建模型,引入numpy庫用以處理數據,引入xlrd庫用以從數據庫中讀入數據,引入matplotlib庫用以實現繪圖。
(2)第2步導入并處理數據。從數據庫中導入數據,并對數據進行處理以便輸入模型進行學習。其中數據按9∶1分為訓練集與驗證集,從驗證集中隨機取10個數據作為測試集用來檢驗模型預測結果的好壞。其中,LSTM模型的輸入數據以給礦量的11個連續數據作為1組,依次類推直至數據全被分配完畢。BP模型的輸入數據為除去時間的其余9個相關數據。
(3)第3步構建模型。LSTM模型構建為2個LSTM塊順次相連,最后添加1個全連接層輸出預測結果。值得一提的是,LSTM模型輸入的數據維度為三維,其中第一維代表每次輸入模型的數據組個數,即訓練中的batch_size。第二維代表用來預測結果需要的參數的個數。第三維代表輸出的特征數的個數,本文中輸出的特征值只有給礦量的預測值,故本文中各個模型輸出的特征值數目為1。
LSTM模型中采用均方差作為損失函數,Adam作為優化函數,訓練過程中觀察模型中每個epoch的損失值。訓練過程中迭代次數為136次,batch_size為100。不同神經網絡預測結果見圖5。

BP模型的結構為2個全連接層順次相連,其中第1個全連接層的隱藏節點數為10,激活函數為Relu,第2個全連接層的節點數為1,即輸出的特征值的個數。BP模型的輸入數據維度為二維,其中第一維代表每次喂入模型的數據組的個數,即訓練中的batch_size,第二維代表每個數據組中參數的個數。
BP模型同LSTM模型一樣采用均方差作為損失函數,采用Adam作為優化函數,訓練過程中觀察每個epoch的損失值。訓練過程中迭代次數為100,batch_size為10。經過長時間訓練后,得到模型權重,并記錄損失值不下降時每個模型在訓練集上的誤差絕對值的平均值用來計算預測時的修正誤差。
(4)第4步結果預測。將測試集的10個數據組分別輸入LSTM模型以及BP模型中,得到的預測值經過公式(1)處理后得到最終預測值。將得到的3種預測結果分別與真實值比對發現,組合模型得到的預測結果優于單一模型得到的預測結果。其中,使用BP模型預測準確度為92%,使用LSTM模型預測準確度為96%,使用BP-LSTM組合模型預測準確度為98%。
4 結 論
為了更好地對球磨機缺失數據進行預測插補,利用BP和LSTM 2種神經網絡對缺失數據進行預測,結果表明,使用2種神經網絡的組合模型可以使預測結果達到更優,證明該方法是切實可行的,也為缺失值的預測插補提供了新的思路。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
