機械產(chǎn)品專利知識的提取和應(yīng)用*
2021-08-23 10:12:14董文斌戰(zhàn)洪飛余軍合
機械制造 2021年8期
□ 董文斌 □ 戰(zhàn)洪飛 □ 余軍合 □ 王 瑞
寧波大學(xué) 機械工程與力學(xué)學(xué)院 浙江寧波 315211
1 研究背景
企業(yè)機械產(chǎn)品設(shè)計過程中,專利文獻占有很重要的地位。然而,目前專利申請數(shù)量日趨龐大,產(chǎn)品設(shè)計人員需要花費大量時間閱讀和分析專利文獻。隨著專利數(shù)據(jù)的大幅增加,僅依靠人工查閱的方式獲取專利知識與信息越來越顯得力不從心。對此,筆者構(gòu)建了輔助設(shè)計人員進行研發(fā)設(shè)計的專利知識抽取方法與系統(tǒng),實現(xiàn)對專利知識的自動提取,構(gòu)建專利知識圖譜,產(chǎn)品設(shè)計專利知識推送等功能。
關(guān)于從專利文本中提取知識的研究一直是熱點,不同學(xué)者對專利知識提取的認(rèn)識和方法都不盡相同。Park等[1]提出基于主謂賓結(jié)構(gòu)的專利情報系統(tǒng),將從專利文本中提取到的主謂賓結(jié)構(gòu)作為相關(guān)的專利知識,并基于此構(gòu)建專利地圖和專利網(wǎng)絡(luò)。陳憶群等[2]采用支持向量機自動抽取出專利文本中的關(guān)鍵詞,由此挖掘?qū)@R。An等[3]提出一種基于介詞語義分析網(wǎng)絡(luò)確定專利關(guān)鍵詞之間類型的方法,通過確定介詞定義技術(shù)術(shù)語之間的關(guān)系,來描述專利的技術(shù)內(nèi)容。郭潔[4]為了獲取林業(yè)機械專利中的功能結(jié)構(gòu)知識,提出將閉合加權(quán)頻繁模式與林業(yè)機械領(lǐng)域同義詞典相結(jié)合的方法,通過試驗驗證了這一方法的穩(wěn)定性和可靠性。盛卿[5]針對機電產(chǎn)品專利提出了“任務(wù)流”模型,用于提取和重用創(chuàng)新原理知識。于麗婭等[6]研究了機電產(chǎn)品專利設(shè)計知識的特點,通過識別專利文獻中的動名詞短語來獲取創(chuàng)新專利設(shè)計知識。吳正[7]通過文本挖掘手段,從具有相同或相似特征的專利中提取了實現(xiàn)功能和解決問題的關(guān)鍵性術(shù)語,并基于此繪制專利地圖來進一步分析,輔助創(chuàng)新。馬建紅等[8]從創(chuàng)新設(shè)計角度出發(fā),采用基于組合特征和最大熵分類器的方法對目標(biāo)功能、作用原理、位置特征等創(chuàng)新知識進行抽取,這是一種統(tǒng)計機器學(xué)習(xí)的專利知識抽取方法。張盤龍[9]在構(gòu)建專利知識圖譜的過程中,通過分詞、主題分類等方法,同時應(yīng)用改進的基于圖的排序算法,提取專利中的關(guān)鍵詞,作為承載專利知識的實體。薛馳等[10]將專利作用結(jié)構(gòu)知識提取分為技術(shù)對象和技術(shù)關(guān)系兩類提取,采用最大熵原理和專利術(shù)語詞典識別的方法提取技術(shù)對象,采用建立組成類動詞庫識別核心動詞的方法提取技術(shù)關(guān)系,最終實現(xiàn)專利作用結(jié)構(gòu)知識的提取。
以往學(xué)者對專利知識的提取通常以關(guān)鍵詞或術(shù)語的形式來代表專利知識,提取對創(chuàng)新研發(fā)有啟發(fā)作用的知識不全面。筆者在參考總結(jié)前人文獻的基礎(chǔ)上,針對專利文獻中蘊含的有助于創(chuàng)新設(shè)計的知識進行分析,構(gòu)建專利知識結(jié)構(gòu)模型,在實體識別和實體關(guān)系抽取兩項任務(wù)中引入深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)模型,克服傳統(tǒng)方法的缺點,最終實現(xiàn)專利知識的有效提取。
2 專利知識提取服務(wù)框架
隨著專利數(shù)量的日趨龐大,有關(guān)人員需要花費大量時間閱讀和分析專利文獻,獲取專利中蘊藏的設(shè)計知識,這與如今快節(jié)奏時代的高效率目標(biāo)存在矛盾。因此,需要有一種方法,能使計算機自動提取專利中的知識。筆者基于潤桐、soopat等專利檢索網(wǎng)站中的中文專利文獻,研究從摘要等非結(jié)構(gòu)化數(shù)據(jù)中提取與產(chǎn)品設(shè)計相關(guān)的功效、原理、結(jié)構(gòu)知識的方法,并對專利文獻進行知識建模,分為摘要、說明書等專利內(nèi)容和公開號、申請人等專利屬性,從專利內(nèi)容中提取結(jié)構(gòu)、原理、功能知識。基于深度學(xué)習(xí)相關(guān)算法模型,實現(xiàn)實體識別和實體關(guān)系抽取兩大任務(wù),進而完成專利知識的提取。
專利知識提取服務(wù)框架如圖1所示。
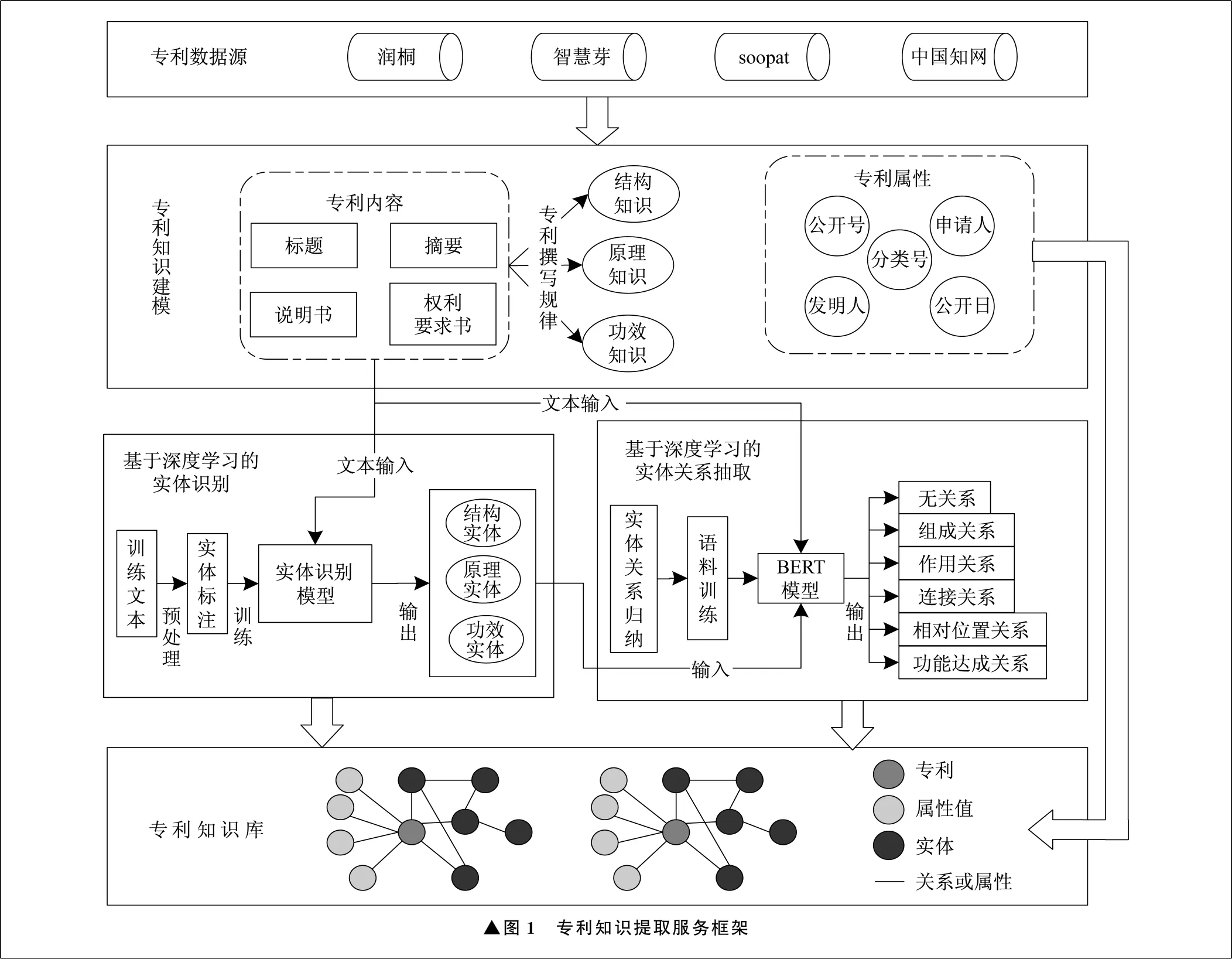
▲圖1 專利知識提取服務(wù)框架
專利數(shù)據(jù)源主要選擇潤桐、智慧芽、中國知網(wǎng)等常用專利檢索網(wǎng)站,并從中獲取專利數(shù)據(jù)。在專利知識建模部分,主要根據(jù)專利文獻的撰寫規(guī)律歸納出專利中蘊含的功效、原理、結(jié)構(gòu)三類知識,并分析其特征。在基于深度學(xué)習(xí)的實體識別模塊中,通過算法模型對專利領(lǐng)域?qū)嶓w進行識別。在實體關(guān)系抽取部分,使用BERT語言預(yù)訓(xùn)練模型,通過分類原理進行實體間關(guān)系的識別。基于抽取出的實體和實體關(guān)系,以實體-關(guān)系-實體的形式表示專利知識,并與專利屬性一同存入專利知識庫。
3 基于深度學(xué)習(xí)的專利知識提取
筆者主要通過解決識別專利文本中承載知識的實體和抽取實體之間關(guān)系的兩項任務(wù)來完成專利知識的提取。通過對專利文本中的知識結(jié)構(gòu)進行建模,分析專利中的實體類型及實體關(guān)系,引入深度學(xué)習(xí)算法模型,使計算機能夠自動識別實體和抽取實體關(guān)系。采用深度學(xué)習(xí)方法,克服了采用傳統(tǒng)自然語言處理方法提取文本特征不能很好地表征文檔語義、語法,容易丟失有用信息的缺陷。應(yīng)用深度學(xué)習(xí)方法,還可以獲取更優(yōu)良的文本特征。
3.1 專利知識建模
筆者主要針對機械產(chǎn)品的發(fā)明和實用新型類專利進行研究。發(fā)明和實用新型類專利文獻中包括公開號、申請人等描述專利屬性的信息,在導(dǎo)出或提取后通常是可以直接儲存和應(yīng)用的結(jié)構(gòu)化數(shù)據(jù)。標(biāo)題、摘要、權(quán)利要求書等是具體描述專利內(nèi)容的文本,其中蘊含著最主要的專利知識。標(biāo)題表述產(chǎn)品或產(chǎn)品組件名稱。摘要是對專利全文的概括性描述,主要涉及功效、結(jié)構(gòu)、原理等內(nèi)容。權(quán)利要求書對所需法律保護的結(jié)構(gòu)進行具體說明。說明書對產(chǎn)品設(shè)計的背景、功效、結(jié)構(gòu)、原理等進行具體描述。
專利說明書的內(nèi)容雖然具體,但是過于煩瑣冗雜,權(quán)利要求書只描述產(chǎn)品的結(jié)構(gòu),摘要則在很大程度上保留專利涉及的主要知識,而且容易獲取。基于此,筆者選擇摘要來提取專利中的相關(guān)知識。專利的功效知識包含專利所能達(dá)到的功能效果,反映產(chǎn)品設(shè)計的需求和目的,如降低噪聲、延長使用壽命等。原理知識指達(dá)到專利所述功效的步驟或方法,如紅外感應(yīng)、紫外線殺菌等。結(jié)構(gòu)知識描述產(chǎn)品的結(jié)構(gòu)組件、結(jié)構(gòu)組件的零部件,以及它們之間的關(guān)系。筆者通過對專利文獻進行分析,將其中的知識表示為實體-關(guān)系-實體或?qū)嶓w-屬性-屬性值,并以節(jié)點-邊-節(jié)點的形式構(gòu)建專利知識結(jié)構(gòu)模型,如圖2所示。此模型包含了專利的基本屬性、結(jié)構(gòu)、原理、功效實體,結(jié)構(gòu)與結(jié)構(gòu)之間的相對關(guān)系,如連接關(guān)系、作用關(guān)系等,以及原理與功效之間存在的實現(xiàn)關(guān)系。

▲圖2 專利知識結(jié)構(gòu)模型
3.2 實體識別
對機械產(chǎn)品專利知識結(jié)構(gòu)分析建模后,需要對模型中提到的實體和實體之間的關(guān)系進行識別抽取。實體識別指從專利文本中識別出表示功能、結(jié)構(gòu)、原理等知識的領(lǐng)域?qū)嶓w,如從專利文本“本實用新型提供一種電動牙刷,包括刷頭、刷柄和刷柄座”中識別電動牙刷、刷頭、刷柄、刷柄座等表示結(jié)構(gòu)知識的系統(tǒng)和零部件名,作為結(jié)構(gòu)實體。筆者引入雙向長短期記憶神經(jīng)網(wǎng)絡(luò)模型和條件隨機場模型[11],通過序列標(biāo)注的方式對專利領(lǐng)域?qū)嶓w進行識別。用雙向長短期記憶神經(jīng)網(wǎng)絡(luò)模型和條件隨機場模型實現(xiàn)實體識別時,按照實體特征采用標(biāo)簽標(biāo)注一部分?jǐn)?shù)據(jù),模型經(jīng)訓(xùn)練學(xué)習(xí)實體的特征后不斷調(diào)整參數(shù),使訓(xùn)練后的模型針對專利文本能自動計算出對應(yīng)的標(biāo)簽序列,結(jié)合標(biāo)簽找出實體。為提升模型的實體識別性能,筆者在模型上游任務(wù)中引入BERT語言預(yù)訓(xùn)練模型進行預(yù)訓(xùn)練詞向量。
(1) 確定專利文本的領(lǐng)域?qū)嶓w類型。專利文本的領(lǐng)域?qū)嶓w包括三部分:① 零部件名;② 形狀構(gòu)造,如電機、齒輪、凹槽等結(jié)構(gòu)實體;③ 描述實現(xiàn)功效的功效實體,如清潔效率、壽命等。通常在發(fā)明專利中會涉及原理知識,可以提取描述原理的術(shù)語作為原理實體,如紫外線殺菌、太陽能充電等。
專利中的實體類型見表1。

表1 專利中實體類型
(2) 訓(xùn)練數(shù)據(jù)語料標(biāo)注。將獲取到的專利文本以“。”和“;”為分隔符,按句進行分割,并隨機選擇一部分作為訓(xùn)練語料進行標(biāo)注。標(biāo)注過程中,使用開始-中間-其它標(biāo)注方法進行標(biāo)注,將每個字符標(biāo)注為B-X、I-X或O,語料標(biāo)注見表2。B-X表示詞語或短語的第一個字符,而且該詞語或短語屬于X類型,是FUNC、STRU、PRIN三種中的一種。表2中,原理實體“紅外感應(yīng)”的“紅”字標(biāo)注為B-PRIN。I-X表示字符屬于X類型詞語或短語第一個字符之后的字符,如“紅外感應(yīng)”的“外”“感”“應(yīng)”都標(biāo)注為I-PRIN。用O標(biāo)注不屬于任何類型的字符,如表2中“通”“過”“方”“式”等。

表2 語料標(biāo)注
(3) 預(yù)訓(xùn)練詞向量。BERT語言預(yù)訓(xùn)練模型預(yù)訓(xùn)練的詞向量融合了句子中的語義特征,有更好的泛化能力[12]。筆者將BERT語言預(yù)訓(xùn)練模型訓(xùn)練的詞向量輸入到下游任務(wù),來提高實體識別的效果,BERT語言預(yù)訓(xùn)練模型結(jié)構(gòu)如圖3所示。BERT語言預(yù)訓(xùn)練模型的輸入初始詞向量w1、w2、…、wn經(jīng)三重向量嵌入融合了詞的歸屬句子、位置等信息,輸出預(yù)訓(xùn)練后的詞向量T1、T2、…、Tn。模型中的亮點機制是掩語模型,類似于完形填空,先隨機遮蓋住句子中的部分詞,通常為15%,再應(yīng)用上下文來預(yù)測遮住的詞。

▲圖3 BERT語言預(yù)訓(xùn)練模型結(jié)構(gòu)
(1)
式中:Pi,yi為第i個位置歸一化后輸出標(biāo)簽序列中標(biāo)簽yi的概率;Ayi-1,yi為從標(biāo)簽yi-1到標(biāo)簽yi的轉(zhuǎn)移概率。

▲圖4 專利領(lǐng)域?qū)嶓w識別模型
(5) 對實體識別結(jié)果進行評估。通過準(zhǔn)確率C、召回率R、綜合評價指標(biāo)F三個指標(biāo)對各類實體識別的結(jié)果進行評估[13]。準(zhǔn)確率C為正確識別出的實體數(shù)與識別出的實體總數(shù)的比值,召回率R為正確識別出的實體數(shù)與訓(xùn)練集中的實體總數(shù)的比值,綜合評價指標(biāo)F為:
(2)
3.3 專利領(lǐng)域?qū)嶓w關(guān)系抽取
通過前文介紹的實體識別模型識別出專利摘要文本中的各類實體后,需要對識別出的實體之間的關(guān)系進行識別抽取。實體關(guān)系抽取任務(wù)的目標(biāo)是預(yù)測兩個實體在句子中的語義關(guān)系,如給定文本序列“電動牙刷包括手柄和刷頭”,給定實體“電動牙刷”和“刷頭”,目標(biāo)是預(yù)測出兩個實體之間的關(guān)系為組成關(guān)系。實體關(guān)系的抽取在自然語言處理領(lǐng)域內(nèi)實質(zhì)上屬于文本的多分類,筆者依然采用BERT語言預(yù)訓(xùn)練模型來完成實體關(guān)系抽取任務(wù)。
總結(jié)專利文本中實體關(guān)系的類型,并定義編號,見表3。組成關(guān)系指一個組件包含若干部件或零件,代表詞有“包括”“設(shè)有”等。相對位置關(guān)系描述零部件之間的位置關(guān)系,如A位于B之上、A嵌于B之內(nèi)等。作用關(guān)系描述零部件之間的動態(tài)關(guān)系,如A帶動B等。連接關(guān)系描述零件之間的連接配合關(guān)系,如A與B相連接等。功能達(dá)成關(guān)系描述通過技術(shù)方案實現(xiàn)功效的關(guān)系,如通過A實現(xiàn)B功能等。
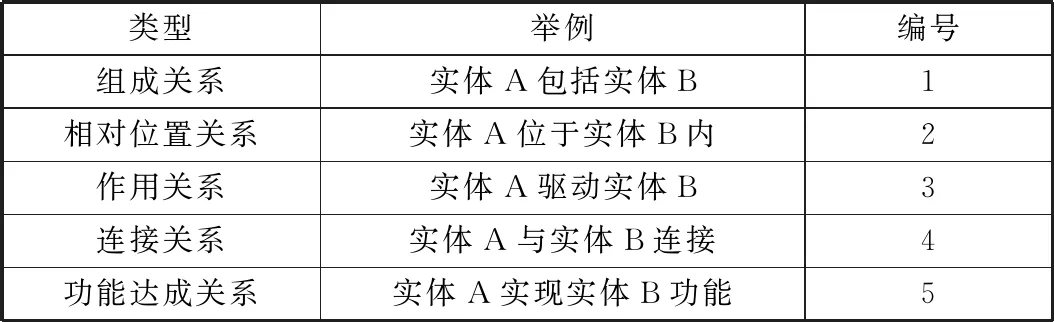
表3 專利文本中實體關(guān)系類型


▲圖5 實體關(guān)系抽取架構(gòu)
文本序列經(jīng)過BERT語言預(yù)訓(xùn)練模型后,得到實體的隱藏向量Ht。對每個實體的所有隱藏向量進行求平均,添加激活函數(shù)后連接全連接層。實體的最終隱藏向量H′1、H′2和第一個標(biāo)記[cls]的最終隱藏向量H′0分別為:
(3)
(4)
H′0=W0(tanhH0)+b0
(5)
式中:W0、W1、W2為權(quán)重矩陣,大小為BERT語言預(yù)訓(xùn)練模型隱藏層的大小,W1=W2;b0、b1、b2為偏置向量,b1=b2;h、j為實體A在句子中的開始和結(jié)束位置;k、m為實體B在句子中的開始和結(jié)束位置。
h″=W3[concat(H′0,H′1,H′2)]+b3
(6)
p=softmaxh″
(7)
式中:h″為綜合向量;W3為綜合權(quán)重矩陣;b3為綜合偏置向量;p為輸出概率;concat為組合函數(shù);softmax為歸一化函數(shù)。
4 專利知識服務(wù)系統(tǒng)
筆者基于構(gòu)建的機械產(chǎn)品專利知識圖譜設(shè)計了相關(guān)的專利知識服務(wù)系統(tǒng)。設(shè)計人員輸入需求,根據(jù)知識圖譜的最短路徑查詢,自動輸出相對應(yīng)的知識節(jié)點,并通過余弦相似度計算相關(guān)的知識節(jié)點進行推送。這一系統(tǒng)的目標(biāo)是通過獲取專利知識構(gòu)建專利知識圖譜,給予設(shè)計人員恰當(dāng)?shù)闹R推送,輔助進行產(chǎn)品創(chuàng)新設(shè)計。這一系統(tǒng)能夠?qū)崿F(xiàn)專利知識的自動提取,專利知識圖譜的構(gòu)建和可視化,專利知識的快速精準(zhǔn)查詢,創(chuàng)新設(shè)計知識的推送,系統(tǒng)功能模塊框架如圖6所示。根據(jù)上述專利知識抽取研究,設(shè)計了專利知識服務(wù)系統(tǒng)的知識抽取模塊,主要子模塊有實體標(biāo)注、實體識別、實體關(guān)系抽取等。系統(tǒng)整體運行框架采用瀏覽器/服務(wù)器模式,基于開放源代碼的網(wǎng)絡(luò)應(yīng)用框架,使用Python語言作為主要業(yè)務(wù)和界面開發(fā)語言,圖數(shù)據(jù)庫采用Neo4j數(shù)據(jù)庫,整體在Eclipse軟件集成開發(fā)環(huán)境中進行。
5 實例分析
5.1 實例概況
筆者選擇電動牙刷的專利作為試驗數(shù)據(jù),分別從潤桐、智慧芽等專利數(shù)據(jù)庫中獲取。在輸入關(guān)鍵詞“電動牙刷”“智能牙刷”“聲波牙刷”等后,篩選從2011年到2020年的數(shù)據(jù),并剔除失效專利。編寫爬蟲程序獲取專利共3 840篇,獲取信息包括題目、摘要、申請日、公開日、申請人等。對數(shù)據(jù)進行預(yù)處理,以“。”“;”等為分隔符對摘要文本進行分句處理。
5.2 專利摘要文本實體識別
為了使模型能自動學(xué)習(xí)實體特征,需要對一部分摘要文本進行人工語料標(biāo)注。筆者從獲取的3 840篇專利摘要中隨機選擇384篇進行語料標(biāo)注,并以8∶2的比例劃分為訓(xùn)練集和測試集。在討論完標(biāo)注標(biāo)準(zhǔn)后,由三位碩士研究生分別獨立完成語料標(biāo)注任務(wù)。
將標(biāo)注后的語料經(jīng)實體識別模型訓(xùn)練,得到實體識別結(jié)果,見表4。實體識別結(jié)果各項數(shù)據(jù)都較為理想,其中結(jié)構(gòu)實體和功效實體的識別效果要明顯優(yōu)于原理實體,這是因為結(jié)構(gòu)知識和功效知識在專利文本中通常以比較規(guī)范和明確的語言來表述,所以識別的結(jié)果相比原理實體較好。原理知識的表述通常比較復(fù)雜,而且在專利中描述原理的語句不多,導(dǎo)致訓(xùn)練樣本中原理實體相對較少,得到的結(jié)果也較差。

表4 實體識別結(jié)果

▲圖6 專利知識服務(wù)系統(tǒng)功能模塊框架
由數(shù)據(jù)回歸到文本,從實際識別出實體的效果來看,結(jié)構(gòu)實體和功效實體識別的泛化能力較好,能識別出訓(xùn)練集中未標(biāo)注的實體,如標(biāo)注“清潔”可以識別出“清潔衛(wèi)生”“潔凈”等未遇到過但語義類似的詞。原理實體的識別效果不如結(jié)構(gòu)實體和功效實體,因為專利中表述原理的語句較少,而且有些隱藏在其它句子中。應(yīng)用所述方法識別專利領(lǐng)域?qū)嶓w的效果見表5,由此驗證了專利領(lǐng)域三類實體識別的結(jié)果。

表5 專利領(lǐng)域?qū)嶓w識別效果
通過向訓(xùn)練后的模型輸入一段摘要文本來展示實體識別的結(jié)果,采用專利CN209422143U“一種紅外感應(yīng)充電健美電動牙刷”來具體展示,實體識別界面如圖7所示。

▲圖7 實體識別界面
5.3 專利摘要文本實體關(guān)系抽取
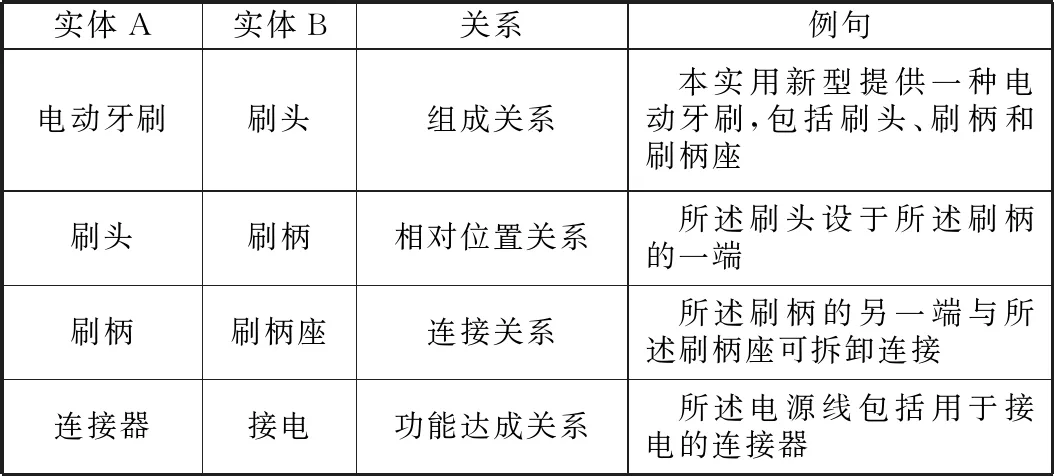
表6 部分專利實體關(guān)系樣本
經(jīng)BERT語言預(yù)訓(xùn)練模型訓(xùn)練后實體關(guān)系抽取結(jié)果見表7。表7表明,模型在專利實體關(guān)系抽取方面有不錯的效果,其中作用關(guān)系和連接關(guān)系效果相對較差,原因是兩者的語義特點較為接近,如句子“所述刷柄的另一端與所述刷柄座可拆卸連接”中實體“刷柄”和“刷柄座”兩者既有連接關(guān)系又有作用關(guān)系,而經(jīng)模型預(yù)測的結(jié)果為作用關(guān)系。組成關(guān)系、功能達(dá)成關(guān)系、相對位置關(guān)系在文本中表達(dá)規(guī)范,有明顯的線索詞,而且語義特點分明,所以取得了較為理想的結(jié)果。

表7 實體關(guān)系抽取結(jié)果
從摘要中抽取幾個包含兩個實體的句子,使用訓(xùn)練后的模型抽取實體關(guān)系,實體關(guān)系抽取測試結(jié)果見表8。實體關(guān)系抽取界面如圖8所示。

表8 實體關(guān)系抽取測試結(jié)果

▲圖8 實體關(guān)系抽取界面
對抽取出的實體與實體關(guān)系進行整合,形成實體-關(guān)系-實體的形式表示專利知識,存入專利知識庫,并以節(jié)點-邊-節(jié)點的圖譜形式進行可視化。專利知識圖譜如圖9所示。

▲圖9 專利知識圖譜
5.4 專利知識推送服務(wù)
筆者設(shè)計的專利知識服務(wù)系統(tǒng)能很好地滿足設(shè)計者的知識需求。通過輸入需要了解的內(nèi)容,系統(tǒng)會自動查詢和推送相關(guān)知識及相關(guān)專利。如設(shè)計電動牙刷時,設(shè)計人員想要查閱能夠達(dá)到防水這一功效的相關(guān)知識,只需要在系統(tǒng)創(chuàng)新知識推薦板塊的文本框中輸入“防水”,并點擊查詢,系統(tǒng)即會自動推送實現(xiàn)防水功效的相關(guān)結(jié)構(gòu)或原理,包括硅膠密封圈、防水槽、防水電池、防水介質(zhì)等內(nèi)容。創(chuàng)新知識推送界面如圖10所示。

▲圖10 創(chuàng)新知識推送界面
6 結(jié)束語
筆者根據(jù)專利文獻的特點,構(gòu)建了專利知識結(jié)構(gòu)模型,將專利知識提取的任務(wù)分為實體識別和實體關(guān)系抽取,并且基于深度學(xué)習(xí)的方法進行了抽取,并構(gòu)建了產(chǎn)品專利知識圖譜,設(shè)計了輔助產(chǎn)品創(chuàng)新設(shè)計的專利知識服務(wù)系統(tǒng),取得了不錯的效果。當(dāng)然,筆者使用的方法仍有許多不足之處,如實體標(biāo)注標(biāo)準(zhǔn)屬于最簡單的標(biāo)注標(biāo)準(zhǔn),可以使用劃分更細(xì)的標(biāo)注標(biāo)準(zhǔn)來提升識別結(jié)果的準(zhǔn)確率。另外,實體識別和實體關(guān)系抽取是分開的,屬于流水線式工作,實體識別中的誤差可能會傳入實體關(guān)系抽取,從而使抽取結(jié)果的整體誤差增大,后期將考慮采用聯(lián)合抽取的方法進行實體識別和實體關(guān)系抽取。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
